从理论到实战:彻底攻克缓存三大难题(穿透、击穿、雪崩)的终极指南

从理论到实战:彻底攻克缓存三大难题(穿透、击穿、雪崩)的终极指南

果酱带你啃java
发布于 2026-04-14 13:12:06
发布于 2026-04-14 13:12:06
引言:缓存困境背后的性能与稳定性博弈
在高并发系统设计中,缓存是提升性能的 "银弹",却也可能成为系统崩溃的 "暗雷"。根据 Amazon 的技术报告显示,合理使用缓存可使系统响应时间降低 90% 以上,吞吐量提升 10 倍以上。然而,同样来自 Netflix 的故障分析表明,约 34% 的生产事故与缓存异常直接相关。
缓存穿透、击穿、雪崩这三大问题,如同悬在系统架构师头顶的 "达摩克利斯之剑"。当每秒数万次的请求绕过缓存直击数据库,当热点 Key 在缓存失效瞬间引发流量洪峰,当缓存集群在同一时刻大规模失效,任何一个场景都可能让精心设计的系统在瞬间崩塌。
本文将从底层原理出发,结合实战案例,提供一套经过验证的完整解决方案。无论你是初入职场的开发者,还是资深架构师,都能从中找到适合自己的实践指南。
一、缓存穿透:当请求 "绕过" 缓存直击数据库
1.1 缓存穿透的本质与危害
缓存穿透是指查询一个根本不存在的数据,由于缓存中没有对应的键,所有请求都会穿透到数据库。这种场景下,缓存完全失效,所有流量直接冲击后端存储。
危害表现:
- 数据库连接耗尽,正常查询无法执行
- 响应时间从毫秒级飙升至秒级甚至超时
- 可能引发级联故障,导致整个服务集群不可用
根据 Google SRE 实践指南,当数据库 QPS 超过设计阈值的 3 倍时,有 80% 的概率发生服务降级或宕机。
1.2 缓存穿透的典型场景
- 恶意攻击黑客构造大量不存在的 Key 进行查询,如用户 ID 为负数或超大范围的随机数
- 业务误操作前端传递错误参数,如查询不存在的订单号
- 数据同步延迟新生成的数据尚未同步到缓存,而此时已有查询请求
1.3 解决方案详解
方案一:空值缓存(缓存空对象)
核心思想:对于查询结果为空的数据,也将其缓存起来,设置一个较短的过期时间(通常几分钟),避免相同请求重复穿透到数据库。
实现示例:
首先,需要在项目中添加必要的依赖,pom.xml 配置如下:
<dependencies>
<!-- Spring Boot Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- 工具类 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.14.0</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>6.1.2</version>
</dependency>
<!-- Swagger3 -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-boot-starter</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
缓存配置类 RedisConfig.java:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* Redis配置类
* 配置RedisTemplate的序列化方式,确保缓存数据正确序列化和反序列化
*/
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
// 使用Jackson2JsonRedisSerializer序列化值
GenericJackson2JsonRedisSerializer jackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置key的序列化规则
template.setKeySerializer(new StringRedisSerializer());
// 设置value的序列化规则
template.setValueSerializer(jackson2JsonRedisSerializer);
// 设置hash的key和value的序列化规则
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
用户实体类 User.java:
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.io.Serializable;
/**
* 用户实体类
*/
@Data
@TableName("t_user")
@ApiModel(value = "User对象", description = "用户信息")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@ApiModelProperty(value = "用户ID")
@TableId(type = IdType.AUTO)
private Long id;
@ApiModelProperty(value = "用户名")
private String username;
@ApiModelProperty(value = "用户年龄")
private Integer age;
@ApiModelProperty(value = "用户邮箱")
private String email;
}
Mapper 接口 UserMapper.java:
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.cacheproblem.entity.User;
import org.apache.ibatis.annotations.Mapper;
/**
* 用户Mapper接口
*/
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
Service 实现类 UserServiceImpl.java:
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.cacheproblem.entity.User;
import com.example.cacheproblem.mapper.UserMapper;
import com.example.cacheproblem.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
import java.util.Objects;
/**
* 用户服务实现类
* 演示空值缓存解决缓存穿透问题
*/
@Service
@Slf4j
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
private final RedisTemplate<String, Object> redisTemplate;
private final UserMapper userMapper;
// 缓存前缀
private static final String CACHE_KEY_PREFIX = "user:";
// 正常数据缓存时间:30分钟
private static final long NORMAL_CACHE_EXPIRE = 30L;
// 空值缓存时间:5分钟(较短,避免缓存过多无效数据)
private static final long EMPTY_CACHE_EXPIRE = 5L;
public UserServiceImpl(RedisTemplate<String, Object> redisTemplate, UserMapper userMapper) {
this.redisTemplate = redisTemplate;
this.userMapper = userMapper;
}
/**
* 根据ID查询用户信息
* 使用空值缓存解决缓存穿透问题
*
* @param id 用户ID
* @return 用户信息,不存在则返回null
*/
@Override
public User getUserById(Long id) {
// 参数校验
Objects.requireNonNull(id, "用户ID不能为空");
String cacheKey = CACHE_KEY_PREFIX + id;
// 1. 先查询缓存
User user = (User) redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存命中
if (Objects.nonNull(user)) {
log.info("缓存命中,用户ID:{}", id);
// 如果是空对象(特殊标记),返回null
if (isPlaceholder(user)) {
return null;
}
return user;
}
log.info("缓存未命中,用户ID:{},查询数据库", id);
// 3. 缓存未命中,查询数据库
user = userMapper.selectById(id);
// 4. 数据库查询结果处理
if (Objects.nonNull(user)) {
// 4.1 数据库存在该数据,写入缓存,设置正常过期时间
redisTemplate.opsForValue().set(cacheKey, user, NORMAL_CACHE_EXPIRE, TimeUnit.MINUTES);
log.info("数据库查询到数据,写入缓存,用户ID:{}", id);
} else {
// 4.2 数据库不存在该数据,写入空值占位符,设置较短过期时间
redisTemplate.opsForValue().set(cacheKey, createPlaceholder(), EMPTY_CACHE_EXPIRE, TimeUnit.MINUTES);
log.info("数据库未查询到数据,写入空值缓存,用户ID:{}", id);
}
return user;
}
/**
* 创建空值占位符
* 使用一个特殊的User对象作为空值标记
*
* @return 空值占位符对象
*/
private User createPlaceholder() {
User placeholder = new User();
// 设置一个特殊的ID作为标记,表明这是一个空值占位符
placeholder.setId(-1L);
return placeholder;
}
/**
* 判断对象是否为空值占位符
*
* @param user 待判断的用户对象
* @return 如果是空值占位符则返回true,否则返回false
*/
private boolean isPlaceholder(User user) {
return Objects.nonNull(user) && Objects.equals(user.getId(), -1L);
}
}
Controller 类 UserController.java:
import com.example.cacheproblem.entity.User;
import com.example.cacheproblem.service.UserService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Objects;
/**
* 用户控制器
*/
@RestController
@RequestMapping("/api/users")
@Api(tags = "用户管理接口")
@Slf4j
public class UserController {
private final UserService userService;
public UserController(UserService userService) {
this.userService = userService;
}
/**
* 根据ID查询用户
*
* @param id 用户ID
* @return 用户信息
*/
@GetMapping("/{id}")
@ApiOperation(value = "根据ID查询用户", notes = "查询指定ID的用户信息")
public ResponseEntity<User> getUserById(
@ApiParam(value = "用户ID", required = true, example = "1")
@PathVariable Long id) {
log.info("接收到查询用户请求,用户ID:{}", id);
User user = userService.getUserById(id);
if (Objects.nonNull(user)) {
return ResponseEntity.ok(user);
} else {
return ResponseEntity.notFound().build();
}
}
}
空值缓存的优缺点:
优点:
- 实现简单,无需额外组件
- 对于恶意攻击有一定防御作用
- 适合数据命中不高,但查询频繁的场景
缺点:
- 占用额外的缓存空间存储空值
- 可能导致短期的数据不一致(缓存空值期间,数据真实插入)
- 对于随机生成的大量不同无效 Key,依然可能耗尽缓存空间
方案二:布隆过滤器(Bloom Filter)
核心思想:在缓存之前设置一道布隆过滤器,存储所有可能存在的 Key。当请求进来时,先经过布隆过滤器判断 Key 是否可能存在,若不存在则直接返回,避免穿透到数据库。
布隆过滤器的原理是通过多个哈希函数将 Key 映射到一个位数组中,通过检查这些位置是否为 1 来判断 Key 是否可能存在。存在一定的误判率(False Positive),但不会漏判(False Negative)。
实现示例:
首先,添加布隆过滤器依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>
布隆过滤器配置类 BloomFilterConfig.java:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.example.cacheproblem.entity.User;
import java.nio.charset.StandardCharsets;
/**
* 布隆过滤器配置类
* 初始化布隆过滤器并预加载数据
*/
@Configuration
public class BloomFilterConfig {
/**
* 预计数据量
*/
private static final long EXPECTED_INSERTIONS = 1000000L;
/**
* 误判率,默认0.03(3%)
*/
private static final double FPP = 0.03;
/**
* 用户ID布隆过滤器
* 用于过滤不存在的用户ID查询,解决缓存穿透问题
*
* @return 布隆过滤器实例
*/
@Bean
public BloomFilter<Long> userBloomFilter() {
// 创建布隆过滤器
BloomFilter<Long> bloomFilter = BloomFilter.create(
Funnels.longFunnel(),
EXPECTED_INSERTIONS,
FPP
);
// 这里应该从数据库加载所有已存在的用户ID到布隆过滤器
// 实际应用中可能需要异步加载或定时更新
// 示例:bloomFilter.put(userId);
return bloomFilter;
}
}
使用布隆过滤器的 Service 实现类 UserBloomFilterServiceImpl.java:
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.cacheproblem.entity.User;
import com.example.cacheproblem.mapper.UserMapper;
import com.example.cacheproblem.service.UserService;
import com.google.common.hash.BloomFilter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
import java.util.Objects;
/**
* 用户服务实现类
* 演示布隆过滤器解决缓存穿透问题
*/
@Service("userBloomFilterService")
@Slf4j
public class UserBloomFilterServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
private final RedisTemplate<String, Object> redisTemplate;
private final UserMapper userMapper;
private final BloomFilter<Long> userBloomFilter;
// 缓存前缀
private static final String CACHE_KEY_PREFIX = "user:";
// 缓存时间:30分钟
private static final long CACHE_EXPIRE = 30L;
public UserBloomFilterServiceImpl(RedisTemplate<String, Object> redisTemplate,
UserMapper userMapper,
BloomFilter<Long> userBloomFilter) {
this.redisTemplate = redisTemplate;
this.userMapper = userMapper;
this.userBloomFilter = userBloomFilter;
}
/**
* 根据ID查询用户信息
* 使用布隆过滤器解决缓存穿透问题
*
* @param id 用户ID
* @return 用户信息,不存在则返回null
*/
@Override
public User getUserById(Long id) {
// 参数校验
Objects.requireNonNull(id, "用户ID不能为空");
// 1. 先通过布隆过滤器判断ID是否可能存在
if (!userBloomFilter.mightContain(id)) {
log.info("布隆过滤器判断ID不存在,直接返回,用户ID:{}", id);
return null;
}
String cacheKey = CACHE_KEY_PREFIX + id;
// 2. 布隆过滤器判断可能存在,查询缓存
User user = (User) redisTemplate.opsForValue().get(cacheKey);
// 3. 缓存命中
if (Objects.nonNull(user)) {
log.info("缓存命中,用户ID:{}", id);
return user;
}
log.info("缓存未命中,用户ID:{},查询数据库", id);
// 4. 缓存未命中,查询数据库
user = userMapper.selectById(id);
// 5. 数据库查询结果处理
if (Objects.nonNull(user)) {
// 5.1 数据库存在该数据,写入缓存
redisTemplate.opsForValue().set(cacheKey, user, CACHE_EXPIRE, TimeUnit.MINUTES);
log.info("数据库查询到数据,写入缓存,用户ID:{}", id);
} else {
// 5.2 数据库不存在该数据(布隆过滤器误判)
log.info("布隆过滤器误判,数据库未查询到数据,用户ID:{}", id);
}
return user;
}
/**
* 创建用户并将ID加入布隆过滤器
*
* @param user 用户信息
* @return 创建成功的用户
*/
@Override
public User createUser(User user) {
Objects.requireNonNull(user, "用户信息不能为空");
// 保存用户到数据库
int rows = userMapper.insert(user);
if (rows > 0) {
log.info("用户创建成功,ID:{},将ID加入布隆过滤器", user.getId());
// 将新创建的用户ID加入布隆过滤器
userBloomFilter.put(user.getId());
// 同时写入缓存
String cacheKey = CACHE_KEY_PREFIX + user.getId();
redisTemplate.opsForValue().set(cacheKey, user, CACHE_EXPIRE, TimeUnit.MINUTES);
return user;
}
log.error("用户创建失败");
return null;
}
}
布隆过滤器的优缺点:
优点:
- 空间效率极高,存储海量 Key 只需很少的空间
- 查询时间快,时间复杂度为 O (k),k 为哈希函数数量
- 对于恶意攻击和大量无效 Key 有很好的过滤效果
缺点:
- 存在误判率,无法 100% 准确判断 Key 是否存在
- 删除困难,通常不支持删除操作
- 需要预加载数据,初始化成本较高
- 数据变更时需要同步更新布隆过滤器
方案三:接口层校验与限流
核心思想:在接口层对请求参数进行合法性校验,过滤掉明显不合理的参数;同时对接口进行限流保护,防止大量恶意请求冲击系统。
实现示例:
使用 Spring Cloud Gateway 实现接口限流:
import org.springframework.cloud.gateway.filter.ratelimit.KeyResolver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import reactor.core.publisher.Mono;
/**
* 网关限流配置
*/
@Configuration
public class GatewayRateLimitConfig {
/**
* 根据用户ID限流
* 对于未登录用户,使用IP地址
*/
@Bean
public KeyResolver userKeyResolver() {
return exchange -> {
// 从请求头获取用户ID
String userId = exchange.getRequest().getHeaders().getFirst("X-User-Id");
if (StringUtils.hasText(userId)) {
return Mono.just(userId);
}
// 否则使用IP地址
String ipAddress = exchange.getRequest().getRemoteAddress().getAddress().getHostAddress();
return Mono.just(ipAddress);
};
}
}
在 application.yml 中配置限流规则:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://user-service
predicates:
- Path=/api/users/**filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 10 # 令牌桶填充速率
redis-rate-limiter.burstCapacity: 20 # 令牌桶总容量
key-resolver: "#{@userKeyResolver}" # 使用自定义的KeyResolver
接口参数校验示例:
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Objects;
/**
* 带参数校验的用户控制器
*/
@RestController
@RequestMapping("/api/users")
@Api(tags = "用户管理接口")
@Slf4j
public class ValidatedUserController {
private final UserService userService;
public ValidatedUserController(UserService userService) {
this.userService = userService;
}
/**
* 根据ID查询用户,带参数校验
*
* @param id 用户ID
* @return 用户信息
*/
@GetMapping("/{id}")
@ApiOperation(value = "根据ID查询用户", notes = "查询指定ID的用户信息")
public ResponseEntity<User> getUserById(
@ApiParam(value = "用户ID,必须为正整数", required = true, example = "1")
@PathVariable Long id) {
log.info("接收到查询用户请求,用户ID:{}", id);
// 参数合法性校验
if (id <= 0) {
log.warn("无效的用户ID:{},直接返回400", id);
return ResponseEntity.badRequest().build();
}
User user = userService.getUserById(id);
if (Objects.nonNull(user)) {
return ResponseEntity.ok(user);
} else {
return ResponseEntity.notFound().build();
}
}
}
接口层防护的优缺点:
优点:
- 从源头过滤无效请求,减轻后端压力
- 可以针对不同接口设置不同的防护策略
- 实现灵活,可结合多种验证方式
缺点:
- 无法完全过滤所有无效请求
- 对于业务上合法但实际不存在的 Key 无能为力
- 可能影响正常用户的体验(如限流过严)
1.4 缓存穿透解决方案对比与选择
方案 | 实现复杂度 | 空间消耗 | 误判率 | 适用场景 |
|---|---|---|---|---|
空值缓存 | 简单 | 中 | 无 | 数据更新不频繁,无效 Key 有限 |
布隆过滤器 | 中等 | 低 | 有(可配置) | 数据量大,查询频繁,能容忍一定误判 |
接口校验 | 简单 | 低 | 无 | 有明显参数规则的场景 |
组合方案 | 复杂 | 中高 | 可控制 | 高并发、高安全要求的核心系统 |
最佳实践:
- 中小规模系统:接口校验 + 空值缓存
- 大规模高并发系统:接口校验 + 布隆过滤器 + 空值缓存
- 安全敏感系统:上述方案 + 限流熔断
二、缓存击穿:热点 Key 失效引发的流量风暴
2.1 缓存击穿的本质与危害
缓存击穿是指一个热点 Key 在缓存中过期的瞬间,大量并发请求同时访问这个 Key,导致所有请求都穿透到数据库,造成数据库瞬间压力骤增。
与缓存穿透不同,缓存击穿的 Key 是真实存在的,只是在某个时间点缓存失效,导致并发请求直击数据库。
危害表现:
- 热点数据对应的数据库表被大量请求冲击
- 数据库连接池耗尽,其他正常查询受阻
- 可能引发数据库锁竞争,导致查询超时
根据 LinkedIn 的技术博客,一个热点商品的缓存失效曾导致其数据库集群 QPS 瞬间飙升 200 倍,引发 15 分钟的服务不可用。
2.2 缓存击穿的典型场景
- 热门商品详情如电商平台的爆款商品,在缓存过期瞬间有大量用户访问
- 热点新闻突发新闻事件,相关内容的缓存过期
- 促销活动限时折扣活动的商品在缓存过期时迎来访问高峰
2.3 解决方案详解
方案一:互斥锁(Mutex Lock)
核心思想:当缓存失效时,不是所有请求都去查询数据库,而是只有一个请求获得锁去查询数据库并更新缓存,其他请求则等待锁释放后从缓存中获取数据。
流程图如下:
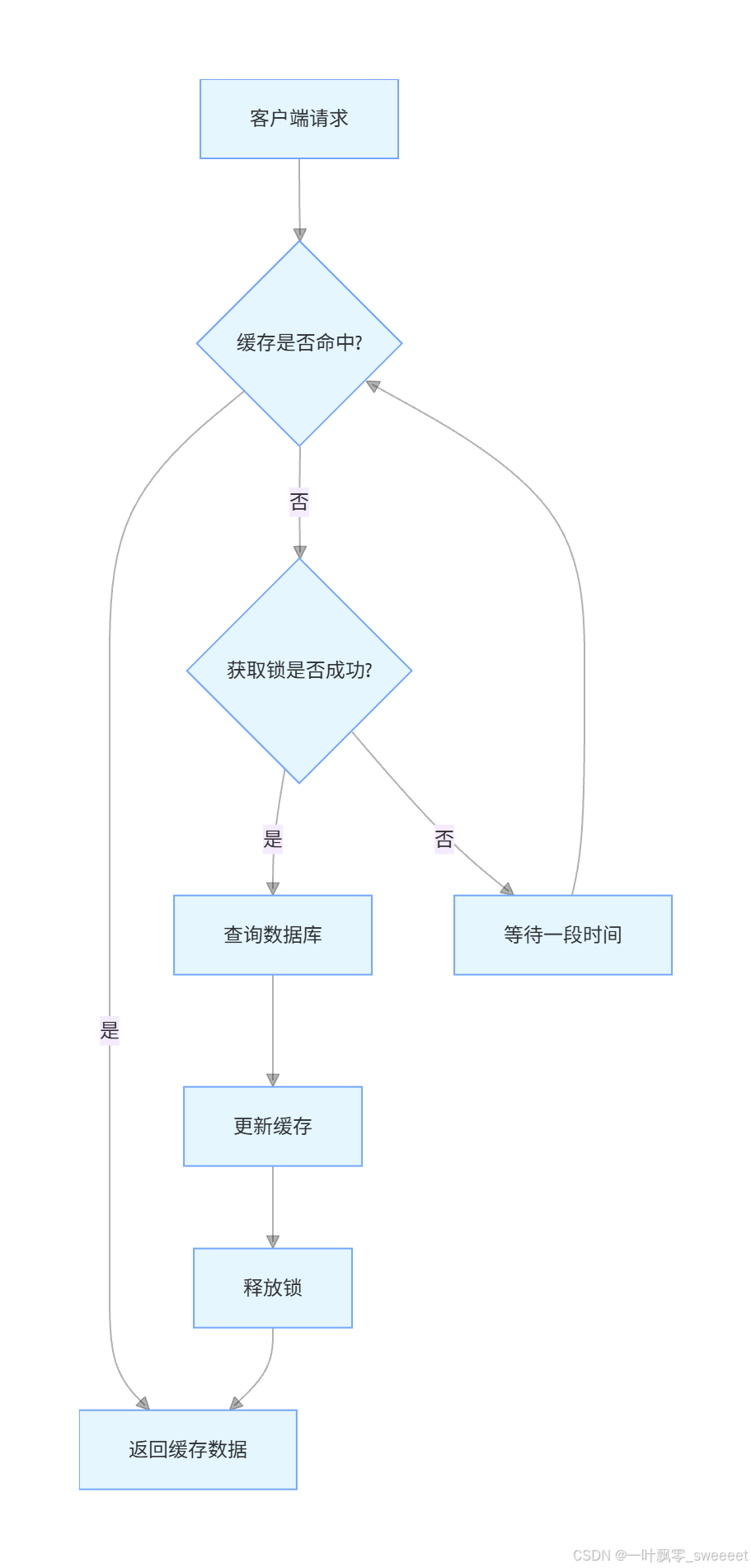
实现示例:
基于 Redis 的分布式锁工具类 RedisLockUtil.java:
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.stereotype.Component;
import java.util.Collections;
import java.util.Objects;
import java.util.concurrent.TimeUnit;
/**
* Redis分布式锁工具类
* 用于实现缓存击穿的互斥锁方案
*/
@Component
public class RedisLockUtil {
private final RedisTemplate<String, Object> redisTemplate;
// 锁的默认过期时间:5秒
private static final long DEFAULT_LOCK_EXPIRE = 5000L;
// 尝试获取锁的间隔:100毫秒
private static final long ACQUIRE_INTERVAL = 100L;
// 释放锁的Lua脚本,确保原子性
private static final String UNLOCK_SCRIPT = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
private final RedisScript<Long> unlockScript;
public RedisLockUtil(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
this.unlockScript = new DefaultRedisScript<>(UNLOCK_SCRIPT, Long.class);
}
/**
* 获取分布式锁
*
* @param lockKey 锁的Key
* @param requestId 请求ID,用于标识当前锁的持有者
* @param expireTime 锁的过期时间(毫秒)
* @param timeout 获取锁的超时时间(毫秒)
* @return 成功获取锁返回true,否则返回false
*/
public boolean tryLock(String lockKey, String requestId, long expireTime, long timeout) {
Objects.requireNonNull(lockKey, "锁的Key不能为空");
Objects.requireNonNull(requestId, "请求ID不能为空");
long start = System.currentTimeMillis();
try {
// 循环尝试获取锁
while (true) {
// 尝试获取锁
Boolean success = redisTemplate.opsForValue().setIfAbsent(lockKey, requestId, expireTime, TimeUnit.MILLISECONDS);
if (Boolean.TRUE.equals(success)) {
// 成功获取锁
return true;
}
// 判断是否超时
long cost = System.currentTimeMillis() - start;
if (cost >= timeout) {
// 获取锁超时
return false;
}
// 等待一段时间后重试
TimeUnit.MILLISECONDS.sleep(ACQUIRE_INTERVAL);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
}
}
/**
* 获取分布式锁,使用默认参数
*
* @param lockKey 锁的Key
* @param requestId 请求ID
* @return 成功获取锁返回true,否则返回false
*/
public boolean tryLock(String lockKey, String requestId) {
return tryLock(lockKey, requestId, DEFAULT_LOCK_EXPIRE, DEFAULT_LOCK_EXPIRE);
}
/**
* 释放分布式锁
*
* @param lockKey 锁的Key
* @param requestId 请求ID,必须与获取锁时的一致
* @return 释放成功返回true,否则返回false
*/
public boolean unlock(String lockKey, String requestId) {
Objects.requireNonNull(lockKey, "锁的Key不能为空");
Objects.requireNonNull(requestId, "请求ID不能为空");
// 使用Lua脚本执行释放锁操作,确保原子性
Long result = redisTemplate.execute(
unlockScript,
Collections.singletonList(lockKey),
requestId
);
return Objects.equals(result, 1L);
}
}
使用互斥锁解决缓存击穿的 Service 实现类:
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.cacheproblem.entity.User;
import com.example.cacheproblem.mapper.UserMapper;
import com.example.cacheproblem.service.UserService;
import com.example.cacheproblem.util.RedisLockUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import java.util.Objects;
/**
* 用户服务实现类
* 演示互斥锁解决缓存击穿问题
*/
@Service("userMutexService")
@Slf4j
public class UserMutexServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
private final RedisTemplate<String, Object> redisTemplate;
private final UserMapper userMapper;
private final RedisLockUtil redisLockUtil;
// 缓存前缀
private static final String CACHE_KEY_PREFIX = "user:";
// 锁前缀
private static final String LOCK_KEY_PREFIX = "lock:user:";
// 缓存时间:30分钟
private static final long CACHE_EXPIRE = 30L;
// 获取锁的超时时间:1秒
private static final long LOCK_TIMEOUT = 1000L;
public UserMutexServiceImpl(RedisTemplate<String, Object> redisTemplate,
UserMapper userMapper,
RedisLockUtil redisLockUtil) {
this.redisTemplate = redisTemplate;
this.userMapper = userMapper;
this.redisLockUtil = redisLockUtil;
}
/**
* 根据ID查询用户信息
* 使用互斥锁解决缓存击穿问题
*
* @param id 用户ID
* @return 用户信息,不存在则返回null
*/
@Override
public User getUserById(Long id) {
// 参数校验
Objects.requireNonNull(id, "用户ID不能为空");
String cacheKey = CACHE_KEY_PREFIX + id;
// 1. 先查询缓存
User user = (User) redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存命中
if (Objects.nonNull(user)) {
log.info("缓存命中,用户ID:{}", id);
return user;
}
log.info("缓存未命中,用户ID:{}", id);
// 3. 缓存未命中,准备查询数据库,使用互斥锁控制并发
String lockKey = LOCK_KEY_PREFIX + id;
String requestId = UUID.randomUUID().toString();
User result = null;
try {
// 3.1 尝试获取锁
boolean locked = redisLockUtil.tryLock(lockKey, requestId, LOCK_TIMEOUT, LOCK_TIMEOUT);
if (locked) {
log.info("成功获取锁,用户ID:{},开始查询数据库", id);
// 3.2 再次查询缓存,防止其他线程已经更新了缓存
user = (User) redisTemplate.opsForValue().get(cacheKey);
if (Objects.nonNull(user)) {
log.info("二次查询缓存命中,用户ID:{}", id);
return user;
}
// 3.3 查询数据库
user = userMapper.selectById(id);
// 3.4 更新缓存
if (Objects.nonNull(user)) {
redisTemplate.opsForValue().set(cacheKey, user, CACHE_EXPIRE, TimeUnit.MINUTES);
log.info("数据库查询到数据,更新缓存,用户ID:{}", id);
result = user;
} else {
log.info("数据库未查询到数据,用户ID:{}", id);
}
} else {
log.info("获取锁失败,用户ID:{},等待缓存更新后重试", id);
// 3.5 获取锁失败,等待一段时间后重试查询缓存
TimeUnit.MILLISECONDS.sleep(100);
result = (User) redisTemplate.opsForValue().get(cacheKey);
if (Objects.isNull(result)) {
// 重试后仍未获取到缓存,可能数据库中确实不存在该数据
log.warn("重试后仍未获取到缓存数据,用户ID:{}", id);
}
}
} catch (InterruptedException e) {
log.error("处理用户查询时发生中断异常,用户ID:{}", id, e);
Thread.currentThread().interrupt();
} finally {
// 3.6 释放锁
if (redisLockUtil.unlock(lockKey, requestId)) {
log.info("成功释放锁,用户ID:{}", id);
} else {
log.warn("释放锁失败或锁已过期,用户ID:{}", id);
}
}
return result;
}
}
互斥锁方案的优缺点:
优点:
- 有效防止缓存失效时的并发冲击
- 实现相对简单,易于理解
- 适用于大多数热点数据场景
缺点:
- 增加了系统的复杂度
- 存在死锁风险(需设置合理的锁过期时间)
- 获取不到锁的请求会等待,增加了响应时间
方案二:热点数据永不过期
核心思想:对于热点数据,不设置过期时间,从而避免缓存过期导致的击穿问题。同时,通过后台异步线程定期更新缓存数据,保证数据的时效性。
流程图如下:
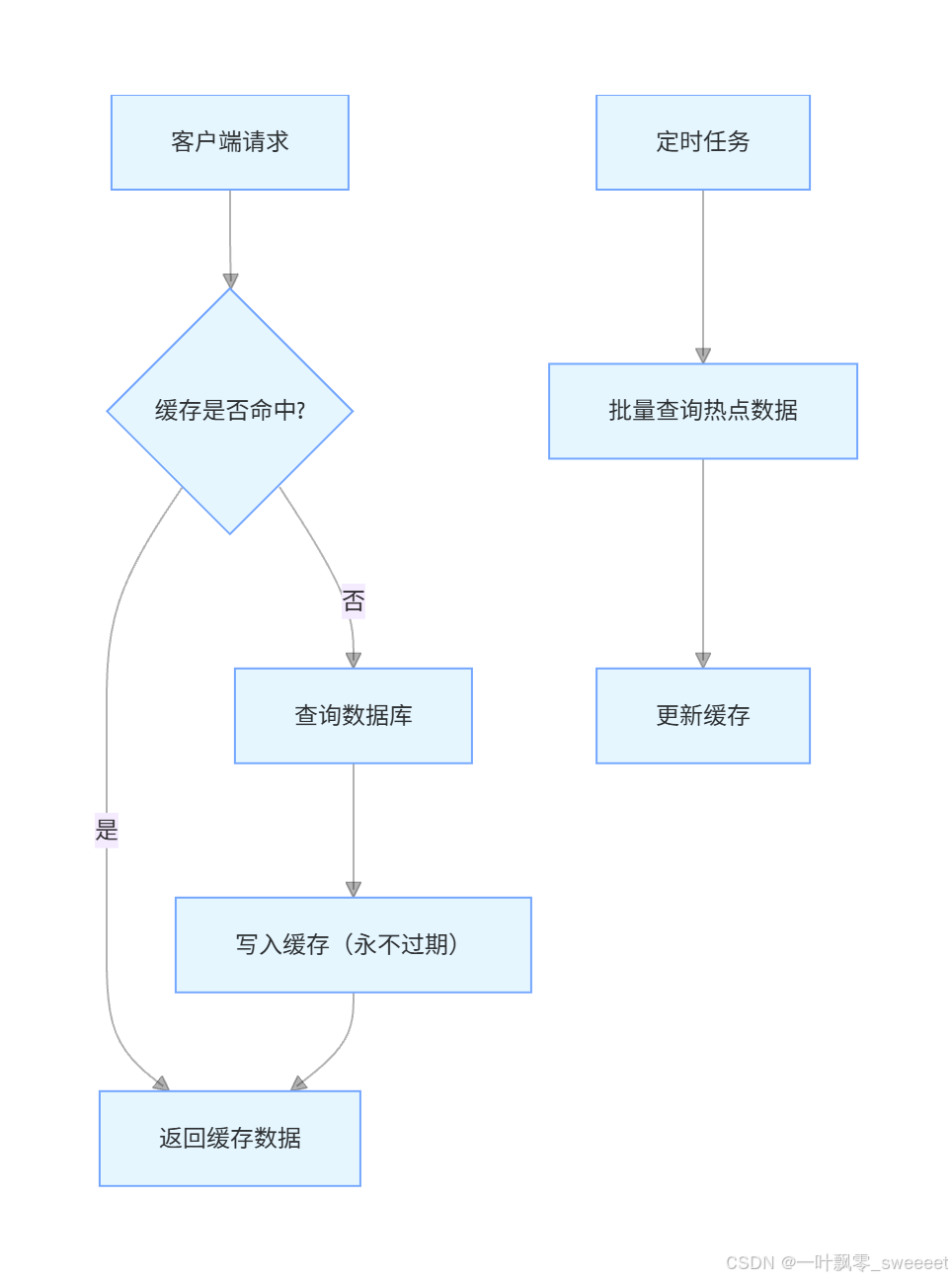
实现示例:
使用定时任务更新热点缓存的 Service 实现类:
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.cacheproblem.entity.User;
import com.example.cacheproblem.mapper.UserMapper;
import com.example.cacheproblem.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Objects;
/**
* 用户服务实现类
* 演示热点数据永不过期方案解决缓存击穿问题
*/
@Service("userNeverExpireService")
@Slf4j
public class UserNeverExpireServiceImpl extends ServiceImpl<UserMapper, UserMapper> implements UserService {
private final RedisTemplate<String, Object> redisTemplate;
private final UserMapper userMapper;
// 缓存前缀
private static final String CACHE_KEY_PREFIX = "user:";
// 热点用户标记前缀
private static final String HOT_USER_PREFIX = "hot:user:";
public UserNeverExpireServiceImpl(RedisTemplate<String, Object> redisTemplate, UserMapper userMapper) {
this.redisTemplate = redisTemplate;
this.userMapper = userMapper;
}
/**
* 根据ID查询用户信息
* 使用热点数据永不过期方案解决缓存击穿问题
*
* @param id 用户ID
* @return 用户信息,不存在则返回null
*/
@Override
public User getUserById(Long id) {
// 参数校验
Objects.requireNonNull(id, "用户ID不能为空");
String cacheKey = CACHE_KEY_PREFIX + id;
// 1. 先查询缓存
User user = (User) redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存命中
if (Objects.nonNull(user)) {
log.info("缓存命中,用户ID:{}", id);
// 标记为热点用户,用于后续定时更新
markAsHotUser(id);
return user;
}
log.info("缓存未命中,用户ID:{},查询数据库", id);
// 3. 缓存未命中,查询数据库
user = userMapper.selectById(id);
// 4. 数据库查询结果处理
if (Objects.nonNull(user)) {
// 4.1 数据库存在该数据,写入缓存(不设置过期时间)
redisTemplate.opsForValue().set(cacheKey, user);
log.info("数据库查询到数据,写入缓存(永不过期),用户ID:{}", id);
} else {
log.info("数据库未查询到数据,用户ID:{}", id);
}
return user;
}
/**
* 标记为热点用户
*
* @param userId 用户ID
*/
private void markAsHotUser(Long userId) {
String hotKey = HOT_USER_PREFIX + userId;
// 设置一个短期过期时间,如5分钟,用于统计这段时间内的热点用户
redisTemplate.opsForValue().setIfAbsent(hotKey, true, 5, TimeUnit.MINUTES);
}
/**
* 定时任务:每10分钟更新热点用户缓存
* cron表达式:0 0/10 * * * ? 表示每10分钟执行一次
*/
@Scheduled(cron = "0 0/10 * * * ?")
public void scheduledUpdateHotUserCache() {
log.info("开始执行热点用户缓存更新任务");
try {
// 1. 获取所有热点用户ID
Set<String> hotUserKeys = redisTemplate.keys(HOT_USER_PREFIX + "*");
if (CollectionUtils.isEmpty(hotUserKeys)) {
log.info("没有需要更新的热点用户缓存");
return;
}
// 2. 提取用户ID
List<Long> userIds = hotUserKeys.stream()
.map(key -> Long.parseLong(key.replace(HOT_USER_PREFIX, "")))
.toList();
log.info("发现{}个热点用户,开始更新缓存", userIds.size());
// 3. 批量查询用户信息
List<User> users = userMapper.selectBatchIds(userIds);
// 4. 批量更新缓存
for (User user : users) {
String cacheKey = CACHE_KEY_PREFIX + user.getId();
redisTemplate.opsForValue().set(cacheKey, user);
log.info("更新热点用户缓存,用户ID:{}", user.getId());
}
log.info("热点用户缓存更新任务完成");
} catch (Exception e) {
log.error("执行热点用户缓存更新任务时发生异常", e);
}
}
/**
* 手动触发热点用户缓存更新
* 可在数据变更时调用
*/
public void manualUpdateHotUserCache() {
log.info("手动触发热点用户缓存更新任务");
scheduledUpdateHotUserCache();
}
}
热点数据永不过期方案的优缺点:
优点:
- 彻底避免了缓存过期导致的击穿问题
- 响应速度快,无需等待锁或重试
- 数据更新由后台线程处理,不影响用户请求
缺点:
- 缓存空间占用较大
- 可能存在数据不一致(缓存更新有延迟)
- 需要合理的热点数据识别机制
- 不适合数据频繁变动的场景
方案三:缓存预热与过期时间错开
核心思想:
- 缓存预热:在系统启动或流量低谷期,主动将热点数据加载到缓存中
- 过期时间错开:为不同的热点 Key 设置不同的过期时间,避免大量 Key 在同一时间过期
实现示例:
缓存预热配置类 CacheWarmUpConfig.java:
import com.example.cacheproblem.entity.User;
import com.example.cacheproblem.mapper.UserMapper;
import com.example.cacheproblem.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.core.RedisTemplate;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import java.util.Objects;
/**
* 缓存预热配置类
*/
@Configuration
@Slf4j
public class CacheWarmUpConfig {
// 基础缓存时间:30分钟
private static final long BASE_CACHE_EXPIRE = 30L;
// 随机过期时间范围:0-10分钟
private static final long RANDOM_EXPIRE_RANGE = 10L;
// 缓存前缀
private static final String CACHE_KEY_PREFIX = "user:";
/**
* 系统启动时执行缓存预热
*/
@Bean
public CommandLineRunner cacheWarmUpRunner(RedisTemplate<String, Object> redisTemplate,
UserMapper userMapper) {
return args -> {
log.info("开始执行缓存预热任务");
try {
// 1. 查询热点用户(这里简化处理,实际应根据业务确定热点用户)
// 例如:查询最近一周活跃的前1000名用户
List<User> hotUsers = findHotUsers(userMapper);
if (CollectionUtils.isEmpty(hotUsers)) {
log.info("没有需要预热的热点用户数据");
return;
}
log.info("开始预热{}个热点用户数据到缓存", hotUsers.size());
Random random = new Random();
// 2. 将热点用户数据写入缓存,并设置随机过期时间
for (User user : hotUsers) {
String cacheKey = CACHE_KEY_PREFIX + user.getId();
// 生成随机过期时间,避免所有缓存同时过期
long randomExpire = random.nextLong(RANDOM_EXPIRE_RANGE);
long expireTime = BASE_CACHE_EXPIRE + randomExpire;
redisTemplate.opsForValue().set(cacheKey, user, expireTime, TimeUnit.MINUTES);
log.info("预热用户缓存,用户ID:{},过期时间:{}分钟", user.getId(), expireTime);
}
log.info("缓存预热任务完成");
} catch (Exception e) {
log.error("执行缓存预热任务时发生异常", e);
}
};
}
/**
* 查询热点用户
* 实际应用中应根据业务规则确定热点用户
*/
private List<User> findHotUsers(UserMapper userMapper) {
// 示例:查询ID小于1000的用户作为热点用户
return userMapper.selectList(new QueryWrapper<User>().lt("id", 1000));
}
}
Service 实现类中使用错开的过期时间:
/**
* 保存或更新用户信息
* 设置错开的过期时间,避免缓存击穿
*/
@Override
public boolean saveOrUpdateUser(User user) {
Objects.requireNonNull(user, "用户信息不能为空");
// 保存或更新数据库
boolean result = saveOrUpdate(user);
if (result) {
log.info("用户信息保存成功,用户ID:{},更新缓存", user.getId());
String cacheKey = CACHE_KEY_PREFIX + user.getId();
// 生成随机过期时间,避免所有缓存同时过期
Random random = new Random();
long randomExpire = random.nextLong(RANDOM_EXPIRE_RANGE);
long expireTime = BASE_CACHE_EXPIRE + randomExpire;
// 更新缓存
redisTemplate.opsForValue().set(cacheKey, user, expireTime, TimeUnit.MINUTES);
log.info("用户缓存更新成功,用户ID:{},过期时间:{}分钟", user.getId(), expireTime);
}
return result;
}
缓存预热与过期时间错开方案的优缺点:
优点:
- 实现简单,无复杂逻辑
- 有效分散缓存过期时间,避免集中失效
- 系统启动时就有缓存可用,减少初期数据库压力
缺点:
- 热点数据识别困难,可能预热了非热点数据
- 依然存在单个 Key 过期时的并发问题
- 预热数据过多会影响系统启动速度
2.4 缓存击穿解决方案对比与选择
方案 | 实现复杂度 | 响应时间 | 数据一致性 | 适用场景 |
|---|---|---|---|---|
互斥锁 | 中等 | 略长(可能等待) | 高 | 热点数据更新频繁,一致性要求高 |
永不过期 | 中等 | 快 | 中(有延迟) | 热点数据相对稳定,更新不频繁 |
预热 + 错峰 | 简单 | 快 | 中 | 可预测的热点数据,如促销商品 |
组合方案 | 复杂 | 快 | 高 | 核心业务,高并发高可用要求 |
最佳实践:
- 一般系统:缓存预热 + 过期时间错开
- 高并发系统:互斥锁 + 过期时间错开
- 数据一致性要求不高的系统:热点数据永不过期 + 定时更新
三、缓存雪崩:缓存集群集体失效的灾难
3.1 缓存雪崩的本质与危害
缓存雪崩是指在某一时间段内,缓存中大量 Key 集中过期失效,或者缓存服务整体不可用,导致大量请求直接穿透到数据库,引起数据库压力骤增,甚至宕机,进而引发整个系统的连锁反应,最终导致系统崩溃。
与缓存击穿不同,缓存雪崩是大规模的缓存失效,影响范围更广,危害更大。
危害表现:
- 数据库服务器 CPU、内存、IO 飙升,响应时间急剧增加
- 数据库连接池耗尽,无法处理新的请求
- 应用服务因等待数据库响应而线程阻塞,最终导致应用服务器崩溃
- 整个分布式系统出现级联故障,服务不可用
根据 Netflix 的故障复盘报告,2021 年的一次缓存集群故障导致全球范围内的服务中断超过 4 小时,直接经济损失超过 1 亿美元。
3.2 缓存雪崩的典型场景
- 集中过期大量 Key 设置了相同的过期时间,在同一时刻集体失效
- 缓存服务宕机Redis 集群因网络、硬件或软件问题整体不可用
- 大规模更新系统发布或数据迁移时,大量缓存被同时更新或清除
- 流量突增在缓存失效的同时,系统迎来突发流量高峰(如秒杀活动)
3.3 解决方案详解
方案一:过期时间随机化
核心思想:为不同的 Key 设置不同的过期时间,避免大量 Key 在同一时刻过期。可以在基础过期时间上增加一个随机值,使过期时间分散开来。
实现示例:
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import java.util.Objects;
/**
* 带随机过期时间的缓存工具类
* 用于解决缓存雪崩问题
*/
@Component
public class RandomExpireCacheUtil {
private final RedisTemplate<String, Object> redisTemplate;
private final Random random = new Random();
// 基础缓存时间(分钟)
private static final long BASE_EXPIRE_MINUTES = 30L;
// 随机时间范围(分钟)
private static final long RANDOM_RANGE_MINUTES = 10L;
public RandomExpireCacheUtil(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
/**
* 设置带随机过期时间的缓存
*
* @param key 缓存Key
* @param value 缓存值
*/
public void setWithRandomExpire(String key, Object value) {
Objects.requireNonNull(key, "缓存Key不能为空");
Objects.requireNonNull(value, "缓存值不能为空");
// 生成随机过期时间
long randomExpire = random.nextLong(RANDOM_RANGE_MINUTES);
long expireTime = BASE_EXPIRE_MINUTES + randomExpire;
redisTemplate.opsForValue().set(key, value, expireTime, TimeUnit.MINUTES);
}
/**
* 设置带随机过期时间的缓存,可指定基础过期时间
*
* @param key 缓存Key
* @param value 缓存值
* @param baseExpire 基础过期时间
* @param randomRange 随机时间范围
* @param unit 时间单位
*/
public void setWithRandomExpire(String key, Object value, long baseExpire,
long randomRange, TimeUnit unit) {
Objects.requireNonNull(key, "缓存Key不能为空");
Objects.requireNonNull(value, "缓存值不能为空");
Objects.requireNonNull(unit, "时间单位不能为空");
if (baseExpire <= 0) {
throw new IllegalArgumentException("基础过期时间必须大于0");
}
if (randomRange < 0) {
throw new IllegalArgumentException("随机时间范围不能小于0");
}
// 生成随机过期时间
long randomExpire = randomRange > 0 ? random.nextLong(randomRange) : 0;
long expireTime = baseExpire + randomExpire;
redisTemplate.opsForValue().set(key, value, expireTime, unit);
}
}
在 Service 中使用:
/**
* 保存用户信息并写入缓存,使用随机过期时间
*/
@Override
public boolean saveUserWithRandomExpire(User user) {
Objects.requireNonNull(user, "用户信息不能为空");
// 保存到数据库
int rows = userMapper.insert(user);
if (rows > 0) {
log.info("用户创建成功,ID:{},写入缓存", user.getId());
String cacheKey = CACHE_KEY_PREFIX + user.getId();
// 使用带随机过期时间的缓存工具类
randomExpireCacheUtil.setWithRandomExpire(cacheKey, user);
return true;
}
log.error("用户创建失败");
return false;
}
过期时间随机化方案的优缺点:
优点:
- 实现简单,几乎无额外成本
- 有效避免大量 Key 集中过期
- 对现有系统改动小
缺点:
- 无法解决缓存服务整体宕机的问题
- 缓存过期时间不可控,可能导致部分数据过期时间过长
- 不适用于有严格过期时间要求的场景
方案二:缓存集群高可用
核心思想:通过搭建缓存集群,实现缓存服务的高可用,即使部分节点失效,整个缓存集群依然可以正常工作。常用的方案有 Redis 主从复制、哨兵模式和 Redis Cluster。
实现示例:
Redis Cluster 配置示例(docker-compose.yml):
version: '3'
services:
# Redis集群节点1
redis-node1:
image: redis:7.2.3
container_name: redis-node1
restart: always
ports:
- "6379:6379"
- "16379:16379"
volumes:
- ./redis-cluster/node1:/data
- ./redis-cluster/redis.conf:/etc/redis/redis.conf
command: redis-server /etc/redis/redis.conf --cluster-enabled yes --cluster-node-timeout 5000 --cluster-config-file nodes.conf --appendonly yes
networks:
- redis-network
# Redis集群节点2
redis-node2:
image: redis:7.2.3
container_name: redis-node2
restart: always
ports:
- "6380:6379"
- "16380:16379"
volumes:
- ./redis-cluster/node2:/data
- ./redis-cluster/redis.conf:/etc/redis/redis.conf
command: redis-server /etc/redis/redis.conf --cluster-enabled yes --cluster-node-timeout 5000 --cluster-config-file nodes.conf --appendonly yes
networks:
- redis-network
# Redis集群节点3
redis-node3:
image: redis:7.2.3
container_name: redis-node3
restart: always
ports:
- "6381:6379"
- "16381:16379"
volumes:
- ./redis-cluster/node3:/data
- ./redis-cluster/redis.conf:/etc/redis/redis.conf
command: redis-server /etc/redis/redis.conf --cluster-enabled yes --cluster-node-timeout 5000 --cluster-config-file nodes.conf --appendonly yes
networks:
- redis-network
# Redis集群节点4(从节点)
redis-node4:
image: redis:7.2.3
container_name: redis-node4
restart: always
ports:
- "6382:6379"
- "16382:16379"
volumes:
- ./redis-cluster/node4:/data
- ./redis-cluster/redis.conf:/etc/redis/redis.conf
command: redis-server /etc/redis/redis.conf --cluster-enabled yes --cluster-node-timeout 5000 --cluster-config-file nodes.conf --appendonly yes
networks:
- redis-network
# Redis集群节点5(从节点)
redis-node5:
image: redis:7.2.3
container_name: redis-node5
restart: always
ports:
- "6383:6379"
- "16383:16379"
volumes:
- ./redis-cluster/node5:/data
- ./redis-cluster/redis.conf:/etc/redis/redis.conf
command: redis-server /etc/redis/redis.conf --cluster-enabled yes --cluster-node-timeout 5000 --cluster-config-file nodes.conf --appendonly yes
networks:
- redis-network
# Redis集群节点6(从节点)
redis-node6:
image: redis:7.2.3
container_name: redis-node6
restart: always
ports:
- "6384:6379"
- "16384:16379"
volumes:
- ./redis-cluster/node6:/data
- ./redis-cluster/redis.conf:/etc/redis/redis.conf
command: redis-server /etc/redis/redis.conf --cluster-enabled yes --cluster-node-timeout 5000 --cluster-config-file nodes.conf --appendonly yes
networks:
- redis-network
networks:
redis-network:
driver: bridge
Spring Boot 中配置 Redis Cluster:
spring:
redis:
cluster:
nodes:
- 127.0.0.1:6379
- 127.0.0.1:6380
- 127.0.0.1:6381
- 127.0.0.1:6382
- 127.0.0.1:6383
- 127.0.0.1:6384
max-redirects: 3 # 最大重定向次数
lettuce:
pool:
max-active: 8 # 连接池最大连接数
max-idle: 8 # 连接池最大空闲连接数
min-idle: 2 # 连接池最小空闲连接数
max-wait: 1000ms # 连接池最大阻塞等待时间
缓存集群高可用方案的优缺点:
优点:
- 提高缓存服务的可用性,单个节点故障不影响整体
- 支持水平扩展,可应对大规模数据和高并发
- 数据有副本,降低数据丢失风险
缺点:
- 部署和维护复杂
- 增加了系统的复杂度和成本
- 无法解决缓存集中过期的问题
方案三:多级缓存架构
核心思想:构建多级缓存架构(如本地缓存 + 分布式缓存),当某一级缓存失效时,还有其他级别的缓存可以提供服务,避免请求直接冲击数据库。
常见的多级缓存架构:
- 本地缓存(如 Caffeine、Guava)
- 分布式缓存(如 Redis Cluster)
- 数据库缓存(如 MySQL 的查询缓存)
架构图如下:
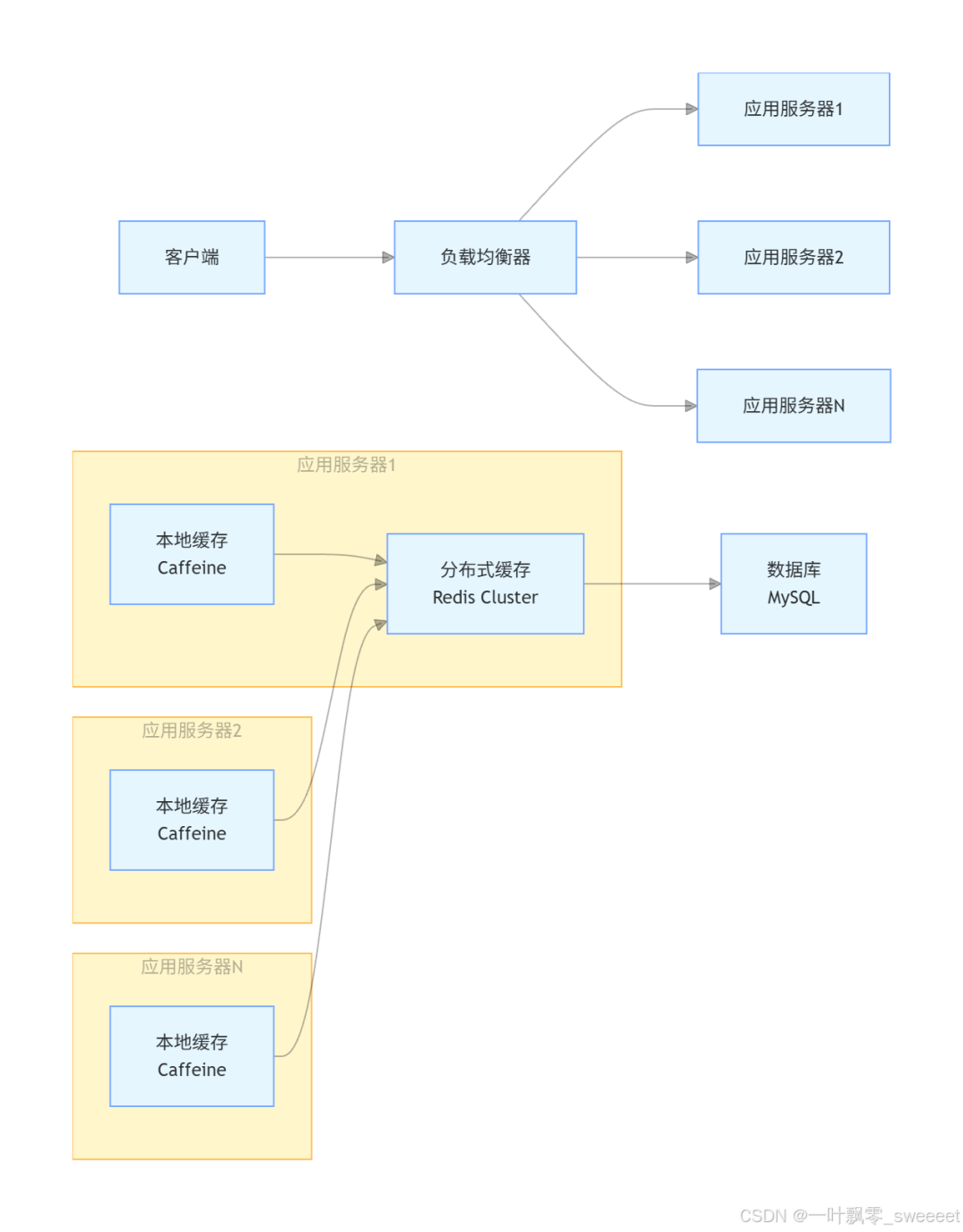
实现示例:
添加 Caffeine 依赖:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>
本地缓存配置类 LocalCacheConfig.java:
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.TimeUnit;
/**
* 本地缓存配置类
*/
@Configuration
public class LocalCacheConfig {
/**
* 用户本地缓存配置
* 最大容量:10000条
* 过期时间:5分钟
*/
@Bean
public Cache<Long, User> userLocalCache() {
return Caffeine.newBuilder()
// 最大缓存数量
.maximumSize(10000)
// 写入后过期时间
.expireAfterWrite(5, TimeUnit.MINUTES)
// 访问后过期时间
.expireAfterAccess(3, TimeUnit.MINUTES)
// 移除监听器
.removalListener((key, value, cause) ->
log.info("本地缓存移除,用户ID:{},原因:{}", key, cause))
.build();
}
}
使用多级缓存的 Service 实现类:
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.cacheproblem.entity.User;
import com.example.cacheproblem.mapper.UserMapper;
import com.example.cacheproblem.service.UserService;
import com.github.benmanes.caffeine.cache.Cache;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.Objects;
/**
* 用户服务实现类
* 演示多级缓存解决缓存雪崩问题
*/
@Service("userMultiLevelCacheService")
@Slf4j
public class UserMultiLevelCacheServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
private final Cache<Long, User> userLocalCache;
private final RedisTemplate<String, Object> redisTemplate;
private final UserMapper userMapper;
private final RandomExpireCacheUtil randomExpireCacheUtil;
// 分布式缓存前缀
private static final String CACHE_KEY_PREFIX = "user:";
public UserMultiLevelCacheServiceImpl(Cache<Long, User> userLocalCache,
RedisTemplate<String, Object> redisTemplate,
UserMapper userMapper,
RandomExpireCacheUtil randomExpireCacheUtil) {
this.userLocalCache = userLocalCache;
this.redisTemplate = redisTemplate;
this.userMapper = userMapper;
this.randomExpireCacheUtil = randomExpireCacheUtil;
}
/**
* 根据ID查询用户信息
* 使用多级缓存解决缓存雪崩问题
*
* @param id 用户ID
* @return 用户信息,不存在则返回null
*/
@Override
public User getUserById(Long id) {
// 参数校验
Objects.requireNonNull(id, "用户ID不能为空");
User user;
// 1. 先查询本地缓存
user = userLocalCache.getIfPresent(id);
if (Objects.nonNull(user)) {
log.info("本地缓存命中,用户ID:{}", id);
return user;
}
log.info("本地缓存未命中,用户ID:{}", id);
// 2. 本地缓存未命中,查询分布式缓存
String cacheKey = CACHE_KEY_PREFIX + id;
user = (User) redisTemplate.opsForValue().get(cacheKey);
if (Objects.nonNull(user)) {
log.info("分布式缓存命中,用户ID:{},更新本地缓存", id);
// 更新本地缓存
userLocalCache.put(id, user);
return user;
}
log.info("分布式缓存未命中,用户ID:{},查询数据库", id);
// 3. 分布式缓存未命中,查询数据库
user = userMapper.selectById(id);
// 4. 数据库查询结果处理
if (Objects.nonNull(user)) {
log.info("数据库查询到数据,更新各级缓存,用户ID:{}", id);
// 4.1 更新分布式缓存,使用随机过期时间
randomExpireCacheUtil.setWithRandomExpire(cacheKey, user);
// 4.2 更新本地缓存
userLocalCache.put(id, user);
} else {
log.info("数据库未查询到数据,用户ID:{}", id);
}
return user;
}
/**
* 更新用户信息,并刷新各级缓存
*/
@Override
public boolean updateUser(User user) {
Objects.requireNonNull(user, "用户信息不能为空");
Objects.requireNonNull(user.getId(), "用户ID不能为空");
// 更新数据库
int rows = userMapper.updateById(user);
if (rows > 0) {
log.info("用户信息更新成功,ID:{},刷新各级缓存", user.getId());
Long userId = user.getId();
String cacheKey = CACHE_KEY_PREFIX + userId;
// 1. 更新分布式缓存
randomExpireCacheUtil.setWithRandomExpire(cacheKey, user);
// 2. 更新本地缓存
userLocalCache.put(userId, user);
// 3. 可以考虑发送消息通知其他节点更新本地缓存
// notifyOtherNodesToUpdateCache(userId);
return true;
}
log.error("用户信息更新失败,ID:{}", user.getId());
return false;
}
}
多级缓存架构的优缺点:
优点:
- 多道防线,某一级缓存失效不影响整体
- 本地缓存响应速度极快,减轻分布式缓存压力
- 有效应对分布式缓存集群故障
- 降低网络开销
缺点:
- 系统复杂度增加,维护成本高
- 缓存一致性难以保证
- 本地缓存占用应用服务器内存
方案四:服务熔断与限流降级
核心思想:当缓存服务不可用或数据库压力过大时,通过熔断和限流机制保护系统,避免系统被压垮。常用的工具有 Sentinel、Hystrix 等。
实现示例:
添加 Sentinel 依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
<version>2022.0.0.0-RC2</version>
</dependency>
Sentinel 配置类:
import com.alibaba.csp.sentinel.annotation.aspectj.SentinelResourceAspect;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Sentinel配置类
*/
@Configuration
public class SentinelConfig {
/**
* 配置Sentinel注解AOP切面
*/
@Bean
public SentinelResourceAspect sentinelResourceAspect() {
return new SentinelResourceAspect();
}
}
使用 Sentinel 进行熔断降级的 Service 实现类:
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.example.cacheproblem.entity.User;
import com.example.cacheproblem.mapper.UserMapper;
import com.example.cacheproblem.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.Objects;
/**
* 用户服务实现类
* 演示服务熔断与限流降级解决缓存雪崩问题
*/
@Service("userCircuitBreakerService")
@Slf4j
public class UserCircuitBreakerServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
private final RedisTemplate<String, Object> redisTemplate;
private final UserMapper userMapper;
private final RandomExpireCacheUtil randomExpireCacheUtil;
// 缓存前缀
private static final String CACHE_KEY_PREFIX = "user:";
// 降级时返回的默认用户(可以是null或默认值)
private static final User DEFAULT_USER = new User();
static {
DEFAULT_USER.setId(-1L);
DEFAULT_USER.setUsername("default");
}
public UserCircuitBreakerServiceImpl(RedisTemplate<String, Object> redisTemplate,
UserMapper userMapper,
RandomExpireCacheUtil randomExpireCacheUtil) {
this.redisTemplate = redisTemplate;
this.userMapper = userMapper;
this.randomExpireCacheUtil = randomExpireCacheUtil;
}
/**
* 根据ID查询用户信息
* 使用Sentinel进行熔断降级,解决缓存雪崩问题
*
* @param id 用户ID
* @return 用户信息,不存在则返回null
*/
@Override
@SentinelResource(value = "getUserById",
blockHandler = "getUserByIdBlockHandler",
fallback = "getUserByIdFallback")
public User getUserById(Long id) {
// 参数校验
Objects.requireNonNull(id, "用户ID不能为空");
String cacheKey = CACHE_KEY_PREFIX + id;
// 1. 先查询缓存
User user = (User) redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存命中
if (Objects.nonNull(user)) {
log.info("缓存命中,用户ID:{}", id);
return user;
}
log.info("缓存未命中,用户ID:{},查询数据库", id);
// 3. 缓存未命中,查询数据库
user = userMapper.selectById(id);
// 4. 数据库查询结果处理
if (Objects.nonNull(user)) {
// 4.1 数据库存在该数据,写入缓存
randomExpireCacheUtil.setWithRandomExpire(cacheKey, user);
log.info("数据库查询到数据,写入缓存,用户ID:{}", id);
} else {
log.info("数据库未查询到数据,用户ID:{}", id);
}
return user;
}
/**
* 限流或熔断时的处理方法
*/
public User getUserByIdBlockHandler(Long id, BlockException e) {
log.warn("用户查询被限流或熔断,用户ID:{},异常:{}", id, e.getMessage());
// 返回降级数据
return DEFAULT_USER;
}
/**
* 业务异常时的处理方法
*/
public User getUserByIdFallback(Long id, Throwable e) {
log.error("用户查询发生异常,用户ID:{}", id, e);
// 返回降级数据
return DEFAULT_USER;
}
}
Sentinel 控制台配置(application.yml):
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8080 # Sentinel控制台地址
port: 8719 # 客户端与控制台通信的端口
eager: true # 饥饿加载
服务熔断与限流降级方案的优缺点:
优点:
- 是系统的最后一道防线,保护系统不被压垮
- 可以根据系统负载动态调整保护策略
- 对缓存和数据库都有保护作用
缺点:
- 配置复杂,需要根据实际情况不断优化
- 降级策略设计不当会影响用户体验
- 无法从根本上解决缓存雪崩问题,只是减少损失
3.4 缓存雪崩解决方案对比与选择
方案 | 解决问题类型 | 实现复杂度 | 系统开销 | 适用场景 |
|---|---|---|---|---|
过期时间随机化 | 集中过期 | 简单 | 低 | 所有使用缓存的系统 |
缓存集群高可用 | 缓存服务宕机 | 复杂 | 中高 | 中大型系统,缓存可用性要求高 |
多级缓存架构 | 全面防护 | 较复杂 | 中 | 高并发系统,响应时间要求高 |
熔断与限流 | 全面防护 | 中等 | 中 | 核心业务系统,可用性要求高 |
最佳实践:
- 基础防护:过期时间随机化 + 缓存集群高可用
- 增强防护:过期时间随机化 + 缓存集群高可用 + 多级缓存
- 全面防护:上述所有方案的组合 + 完善的监控告警
四、综合解决方案与最佳实践
4.1 缓存三大问题的综合解决方案
针对缓存穿透、击穿、雪崩三大问题,需要一套综合的解决方案,而不是孤立地使用某一种方法。下面是一个完整的解决方案架构:
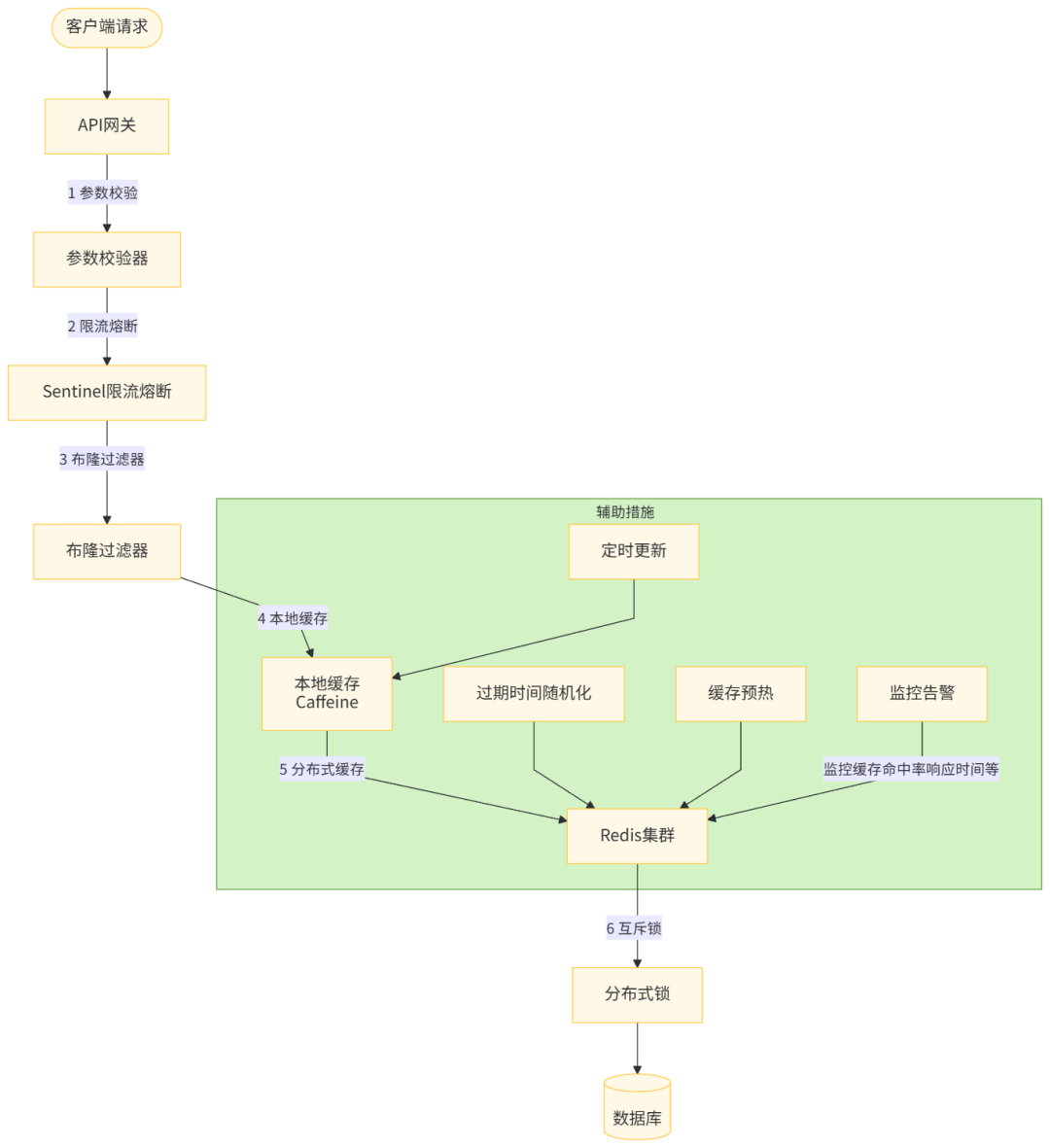
综合解决方案的实现要点:
- 接口层:
- 严格的参数校验,过滤无效请求
- 实现限流和熔断,保护后端服务
- 对敏感操作进行权限验证
- 缓存层:
- 使用布隆过滤器过滤不存在的 Key,解决穿透问题
- 实现多级缓存(本地缓存 + 分布式缓存),提高可用性
- 分布式缓存采用集群部署,保证高可用
- 对热点数据使用互斥锁或永不过期策略,解决击穿问题
- 所有缓存 Key 设置随机过期时间,避免集中过期
- 数据层:
- 数据库主从分离,读写分离
- 实现数据库连接池隔离
- 对热点表进行分表分库处理
- 重要数据定期备份
- 辅助系统:
- 完善的监控告警系统,实时监控缓存命中率、响应时间等指标
- 缓存预热机制,在系统启动或流量低谷期加载热点数据
- 定时任务更新缓存,保证数据时效性
- 故障演练,定期模拟缓存失效场景,检验系统韧性
4.2 缓存设计的最佳实践
- 缓存 Key 设计规范:
- 采用 "业务前缀:主键:字段" 的命名方式,如 "user:1001:info"
- 避免使用过长的 Key,建议不超过 64 个字符
- 避免使用特殊字符,如空格、换行、引号等
- 对集合类型的 Key,建议使用 hash 结构而非多个 Key
- 缓存更新策略:
- 读多写少场景:Cache-Aside Pattern(旁路缓存模式)
- 写多读少场景:Write-Through Pattern(写透模式)
- 高一致性要求场景:Write-Behind Pattern(写回模式)
- 避免使用先更新数据库再删除缓存的方式,推荐先删除缓存再更新数据库,或使用 Canal 等工具监听 binlog 更新缓存
- 缓存数据序列化:
- 推荐使用 JSON 或 Protobuf 序列化,避免使用 Java 默认序列化
- 注意序列化和反序列化的性能和兼容性
- 对大对象考虑压缩存储
- 缓存监控指标:
- 缓存命中率:目标应在 90% 以上
- 缓存穿透率:越低越好,理想为 0
- 平均响应时间:分布式缓存应在 10ms 以内
- 缓存容量使用率:建议不超过 70%
- 缓存服务器 CPU、内存、网络 IO 使用率
- 缓存安全措施:
- 对缓存服务进行网络隔离,只允许应用服务器访问
- 设置合理的密码和访问控制策略
- 定期备份缓存数据,尤其是重要的热点数据
- 避免在缓存中存储敏感信息,如密码、身份证号等
五、总结与展望
缓存是一把双刃剑,使用得当可以显著提升系统性能,使用不当则可能成为系统的隐患。缓存穿透、击穿、雪崩三大问题,本质上都是缓存失效时的流量控制问题。解决这些问题,需要从缓存设计、系统架构、运维监控等多个维度综合考虑。
随着分布式系统的发展,缓存技术也在不断演进。未来,我们可能会看到更多智能化的缓存解决方案,如基于 AI 的热点预测和自动缓存调整,基于区块链的分布式缓存一致性协议等。但无论技术如何发展,理解缓存的本质,掌握解决缓存问题的核心思想,才是应对各种复杂场景的关键。
希望本文能帮助读者深入理解缓存三大问题的本质,掌握实用的解决方案,并在实际工作中灵活应用,构建高性能、高可用的分布式系统。
六、参考
- 缓存穿透解决方案:
- 布隆过滤器原理:基于《Space/Time Trade-offs in Hash Coding with Allowable Errors》论文(Burton H. Bloom, 1970)
- 空值缓存策略:参考 Redis 官方文档推荐方案(https://redis.io/docs/manual/patterns/cache-patterns/)
- 缓存击穿解决方案:
- 互斥锁方案:参考《Redis 设计与实现》(黄健宏著)中的分布式锁实现
- 热点数据永不过期策略:参考 Netflix 技术博客中的缓存最佳实践(https://netflixtechblog.com)
- 缓存雪崩解决方案:
- Redis Cluster 架构:参考 Redis 官方集群文档(https://redis.io/docs/manual/scaling/redis-cluster/)
- 多级缓存架构:参考 Google SRE 实践指南中的缓存策略(https://sre.google/sre-book/caching/)
- 熔断与限流:
- Sentinel 原理:参考阿里巴巴 Sentinel 官方文档(https://sentinelguard.io/zh-cn/docs/introduction.html)
- 限流算法:参考《Guava 官方文档》中的 RateLimiter 实现原理(https://guava.dev/releases/snapshot-jre/api/docs/)
- 缓存设计最佳实践:
- 缓存更新策略:参考 Martin Fowler 的《Patterns of Distributed Systems》
- 缓存 Key 设计:参考 Redis 官方推荐的 Key 命名规范(https://redis.io/docs/manual/patterns/key-naming/)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号