一文击穿 JMM 内存模型:从 CPU 底层到 Java 并发实战,99% 的开发都踩过这些坑

一文击穿 JMM 内存模型:从 CPU 底层到 Java 并发实战,99% 的开发都踩过这些坑

果酱带你啃java
发布于 2026-04-14 14:56:48
发布于 2026-04-14 14:56:48
前言
在Java并发编程领域,JMM(Java Memory Model,Java内存模型)是绝对的核心基石。无论是面试中高频的volatile、synchronized原理,还是生产环境中诡异的并发死循环、半初始化对象空指针、数据不一致问题,本质上都是对JMM规范的理解不到位导致的。
一、为什么需要JMM?并发编程的两大核心矛盾
在理解JMM之前,我们必须先搞清楚:现代计算机架构中,并发编程到底面临什么底层问题?JMM的出现,本质上是为了统一解决这两大核心矛盾。
1.1 CPU与内存的速度鸿沟
现代CPU的运算速度,比主内存(DRAM)的读写速度快了3-4个数量级,相当于火箭和自行车的速度差。如果CPU每次运算都直接和主内存交互,绝大多数性能都会浪费在等待内存响应上。
为了弥补这个速度鸿沟,CPU架构引入了多级高速缓存:每个CPU核心都有自己的L1、L2私有缓存,多个核心共享L3缓存,CPU运算时优先读写高速缓存,仅在必要时和主内存同步数据。
1.2 多核CPU的缓存一致性问题
多核架构下,每个核心都有自己的私有缓存,同一个变量可能在多个核心的缓存中都存在副本。当CPU1修改了变量的缓存副本,CPU2的缓存副本还是旧值,就会出现缓存数据不一致的问题。
硬件层通过MESI等缓存一致性协议解决这个问题,但不同CPU架构(x86、ARM、RISC-V)的缓存协议、内存模型差异极大。而Java作为跨平台语言,必须给开发者提供一套统一的内存访问规范,屏蔽底层硬件和操作系统的差异,保证同一段代码在不同平台上的并发行为一致——这就是JMM诞生的核心原因。
1.3 指令重排序:并发问题的另一大元凶
除了缓存问题,现代CPU和编译器为了提升性能,会对指令进行重排序,分为三类:
- 编译器优化重排序:Java编译器在不改变单线程执行结果的前提下,重新排列代码的执行顺序
- 指令级并行重排序:CPU将多条指令重叠执行,只要不存在数据依赖,就可以改变指令的执行顺序
- 内存系统重排序:CPU的缓存读写队列,可能导致读写操作看起来乱序执行
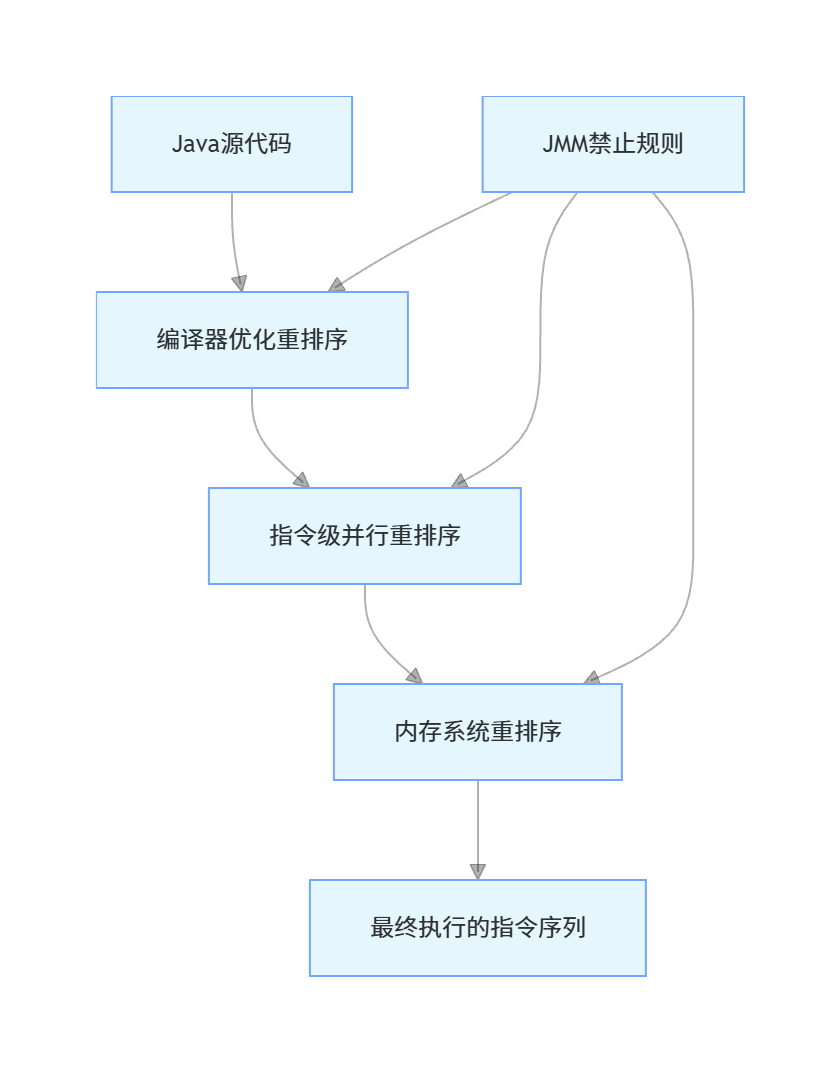
重排序遵循as-if-serial规则:单线程环境下,无论怎么重排序,程序的执行结果不能被改变。但在多线程环境下,重排序会导致线程间的数据可见性、执行顺序出现诡异问题,这也是JMM需要规范的核心内容。
二、JMM的核心定义与抽象结构
2.1 JMM的官方定义
JMM是一套规范,定义了线程和主内存之间的抽象关系,核心目标是:通过规范多线程环境下变量的读写访问规则,解决多线程的原子性、可见性、有序性问题,保证Java程序在所有平台上的并发行为一致性。
这里的变量,指的是线程共享的实例字段、静态字段、数组元素,不包括线程私有的局部变量、方法参数,因为这些不会在线程间共享,不存在竞争问题。
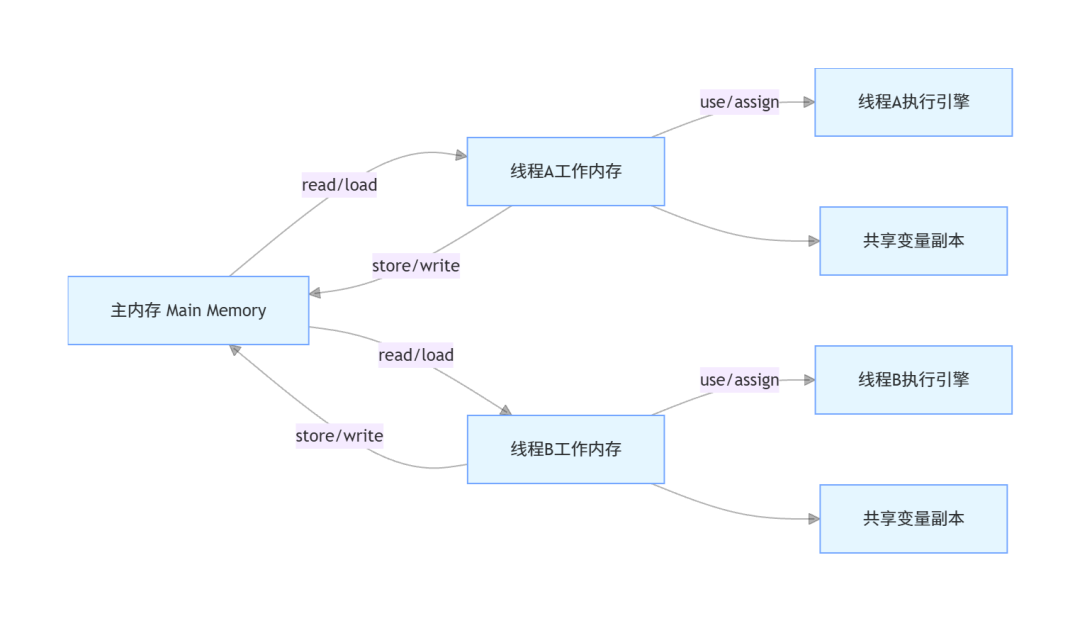
2.2 JMM的抽象内存结构
JMM规定了所有共享变量都存储在主内存(Main Memory)中,每个线程都有自己私有的工作内存(Working Memory),工作内存中保存了该线程使用到的变量的主内存副本,线程对变量的所有读写操作,都必须在工作内存中进行,不能直接读写主内存中的变量。
关键纠正:90%的人都混淆的核心误区
JMM的工作内存≠JVM的栈内存,主内存≠JVM的堆内存,这是两个完全不同的概念:
- JMM是抽象的内存模型,工作内存是对CPU寄存器、高速缓存的抽象,主内存是对物理内存的抽象
- JVM的内存区域划分是运行时数据区的实际划分,堆是所有线程共享的对象存储区域,栈是线程私有的局部变量存储区域
- 两者的唯一关联:共享变量的实际数据存储在堆中,JMM的主内存对应堆中的共享数据区域,工作内存对应CPU缓存和寄存器。
2.3 主内存与工作内存的交互协议
JMM定义了8个原子操作,来完成主内存和工作内存之间的变量同步,每个操作都是不可拆分的原子操作:
- lock:锁定主内存中的变量,将其标记为某个线程独占的状态
- unlock:释放主内存中被锁定的变量,释放后其他线程才能锁定该变量
- read:从主内存中读取变量值,传输到线程的工作内存中
- load:将read操作读取到的变量值,载入到工作内存的变量副本中
- use:将工作内存中的变量值,传递给执行引擎执行
- assign:将执行引擎返回的结果,赋值给工作内存中的变量副本
- store:将工作内存中的变量值,传输到主内存中
- write:将store操作传输过来的变量值,写入到主内存的对应变量中
JMM对这8个操作制定了严格的执行规则,核心规则包括:
- read和load必须成对出现,store和write必须成对出现,不允许单独执行
- 线程执行assign操作后,必须执行store+write操作,将修改同步到主内存
- 不允许线程无原因地(没有assign操作)将工作内存的数据同步到主内存
- 一个变量在同一时刻只能被一个线程执行lock操作,lock操作可以多次执行,必须执行相同次数的unlock操作才能释放变量
- 对一个变量执行unlock操作前,必须先将该变量的修改同步到主内存(执行store+write操作)
三、JMM解决的三大核心特性
并发编程的所有问题,本质上都可以归结为原子性、可见性、有序性这三大特性的问题,JMM的核心价值就是为这三大特性提供明确的保障规则。
3.1 原子性:不可拆分的操作
原子性指的是:一个操作是不可中断的,要么全部执行成功,要么全部执行失败,执行过程中不会被其他线程打断。
JMM的原子性保障规则
- 基础保障:对基本数据类型(除long、double外)的读写操作,具备天然的原子性。JLS规范允许64位的long、double非volatile读写被拆分为两个32位的操作,现代64位JVM普遍实现了long、double的原子读写,但规范并未强制要求,跨平台场景下不建议依赖该特性。
- 扩展保障:synchronized关键字和Lock接口,通过锁机制保证代码块的原子性,锁内的所有操作要么全部执行,要么全部不执行。
- 无锁保障:java.util.concurrent.atomic包下的原子类,通过CAS自旋操作保证单个变量的读写原子性。
经典原子性问题实战:i++的陷阱
package com.jam.demo.jmm;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 原子性问题演示
* @author ken
*/
@Slf4j
publicclass AtomicityDemo {
privatestaticvolatileint volatileCount = 0;
privatestaticfinal AtomicInteger atomicCount = new AtomicInteger(0);
privatestaticint lockCount = 0;
privatestaticfinalint THREAD_COUNT = 10;
privatestaticfinalint LOOP_COUNT = 10000;
public static void main(String[] args) throws InterruptedException {
CountDownLatch volatileLatch = new CountDownLatch(THREAD_COUNT);
for (int i = 0; i < THREAD_COUNT; i++) {
new Thread(() -> {
for (int j = 0; j < LOOP_COUNT; j++) {
volatileCount++;
}
volatileLatch.countDown();
}, "volatile-thread-" + i).start();
}
volatileLatch.await();
log.info("volatile修饰的计数结果:{},预期结果:{}", volatileCount, THREAD_COUNT * LOOP_COUNT);
CountDownLatch atomicLatch = new CountDownLatch(THREAD_COUNT);
for (int i = 0; i < THREAD_COUNT; i++) {
new Thread(() -> {
for (int j = 0; j < LOOP_COUNT; j++) {
atomicCount.incrementAndGet();
}
atomicLatch.countDown();
}, "atomic-thread-" + i).start();
}
atomicLatch.await();
log.info("原子类修饰的计数结果:{},预期结果:{}", atomicCount.get(), THREAD_COUNT * LOOP_COUNT);
CountDownLatch lockLatch = new CountDownLatch(THREAD_COUNT);
Object lock = new Object();
for (int i = 0; i < THREAD_COUNT; i++) {
new Thread(() -> {
for (int j = 0; j < LOOP_COUNT; j++) {
synchronized (lock) {
lockCount++;
}
}
lockLatch.countDown();
}, "lock-thread-" + i).start();
}
lockLatch.await();
log.info("synchronized保护的计数结果:{},预期结果:{}", lockCount, THREAD_COUNT * LOOP_COUNT);
}
}
执行结果说明:
- volatile修饰的计数结果,几乎永远小于预期值100000
- 原子类和synchronized保护的计数结果,永远等于预期值
核心原因:i++不是原子操作,它分为3个步骤:
- 读取count的当前值(use)
- 对count进行+1运算(assign)
- 将结果写回count(store+write)
多线程环境下,多个线程可能同时读取到相同的旧值,分别执行+1运算,然后写回主内存,导致多次+1操作最终只生效一次,这就是原子性缺失导致的数据不一致问题。
3.2 可见性:线程修改的结果对其他线程可见
可见性指的是:当一个线程修改了共享变量的值,其他线程能够立刻感知到这个修改,拿到最新的变量值。
多核CPU架构下,线程的读写操作都是针对自己的工作内存,修改后的变量副本不会立刻同步到主内存,其他线程也不会主动去主内存读取最新值,这就是可见性问题的根源。
JMM的可见性保障规则
JMM规定,所有的变量修改必须同步到主内存,变量读取必须从主内存刷新最新值,通过以下机制实现可见性保障:
- volatile关键字:对volatile变量的修改,会立刻强制刷新到主内存;对volatile变量的读取,会强制清空工作内存中的副本,从主内存读取最新值。
- synchronized关键字:对一个锁执行unlock操作前,必须将变量修改同步到主内存;对一个锁执行lock操作时,会清空工作内存中的变量副本,从主内存读取最新值。
- Lock接口:和synchronized具备完全相同的可见性保障,底层通过AQS的volatile状态变量实现。
- final关键字:正确构造的对象中,final字段的初始化结果对所有线程可见,无需同步操作。
- Happens-Before规则:所有符合Happens-Before规则的操作,都具备可见性保障。
经典可见性问题实战:死循环陷阱
package com.jam.demo.jmm;
import lombok.extern.slf4j.Slf4j;
/**
* 可见性问题演示
* @author ken
*/
@Slf4j
publicclass VisibilityDemo {
privatestaticboolean flag = false;
public static void main(String[] args) throws InterruptedException {
Thread threadA = new Thread(() -> {
int i = 0;
while (!flag) {
i++;
}
log.info("线程A退出循环,i的值为:{}", i);
}, "threadA");
threadA.start();
Thread.sleep(1000);
flag = true;
log.info("主线程已经将flag设置为true");
threadA.join();
}
}
执行结果说明:
- 没有volatile修饰flag时,主线程已经将flag设置为true,但线程A永远不会退出循环,持续死循环
- 给flag加上volatile修饰后,主线程修改flag后,线程A会立刻感知到,退出循环
核心原因: JIT编译器在高频率循环中,发现flag变量没有被当前线程修改,会进行优化,将循环条件优化为while(true),不再读取flag变量的最新值;同时,没有volatile修饰时,主线程对flag的修改不会立刻同步到主内存,线程A也不会主动从主内存刷新flag的值,最终导致死循环。
❝注意:不要在循环中添加System.out.println()来测试,println方法底层有synchronized修饰,会触发内存刷新,导致可见性问题无法复现。
3.3 有序性:禁止指令重排序
有序性指的是:程序的执行顺序,按照代码的逻辑顺序执行,禁止编译器和CPU进行指令重排序。
单线程环境下,as-if-serial规则保证重排序不会改变执行结果,开发者完全感知不到。但多线程环境下,重排序会导致代码执行顺序和预期不符,出现诡异的并发问题。
JMM的有序性保障规则
- 天然有序性:单线程内,程序按照控制流顺序执行,as-if-serial规则保证单线程内的有序性。
- volatile关键字:通过内存屏障禁止指令重排序,保证volatile变量的读写操作不会被重排序。
- synchronized关键字:锁机制保证同一时刻只有一个线程执行锁内代码,相当于单线程执行,天然保证有序性。
- Happens-Before规则:通过8大规则,严格限制操作的执行顺序,保证多线程环境下的有序性。
经典有序性问题实战:DCL单例的陷阱
DCL(Double Check Lock,双重检查锁)是开发中常用的单例实现方式,但如果没有正确使用volatile,就会因为指令重排序出现严重问题。
错误的DCL单例实现
package com.jam.demo.jmm;
/**
* 错误的DCL单例示例
* @author ken
*/
publicclass WrongDclSingleton {
privatestatic WrongDclSingleton instance;
private WrongDclSingleton() {
}
public static WrongDclSingleton getInstance() {
if (instance == null) {
synchronized (WrongDclSingleton.class) {
if (instance == null) {
instance = new WrongDclSingleton();
}
}
}
return instance;
}
}
正确的DCL单例实现
package com.jam.demo.jmm;
/**
* 正确的DCL单例示例
* @author ken
*/
publicclass CorrectDclSingleton {
privatestaticvolatile CorrectDclSingleton instance;
private CorrectDclSingleton() {
}
/**
* 获取单例实例
* @return 单例对象
*/
public static CorrectDclSingleton getInstance() {
if (instance == null) {
synchronized (CorrectDclSingleton.class) {
if (instance == null) {
instance = new CorrectDclSingleton();
}
}
}
return instance;
}
}
核心问题分析:instance = new Singleton() 这个操作,在底层分为3个步骤:
- 分配对象的内存空间
- 初始化对象(执行构造方法,初始化对象的字段)
- 将instance引用指向分配的内存地址(此时instance不再是null)
在没有volatile修饰的情况下,编译器和CPU可能会对步骤2和3进行重排序,执行顺序变为1→3→2。此时会出现以下场景:
- 线程A执行getInstance方法,进入同步块,执行instance = new Singleton(),发生重排序,先执行步骤3,instance已经不为null,但对象还没有初始化完成
- 线程B执行getInstance方法,第一次检查发现instance不为null,直接返回instance对象
- 线程B使用这个未初始化完成的对象,访问其字段时,会出现空指针异常或数据错误
volatile关键字通过内存屏障禁止了步骤2和3的重排序,保证对象初始化完成后,才会将引用赋值给instance变量,彻底解决了这个问题。
四、JMM的底层实现:内存屏障
JMM对原子性、可见性、有序性的保障,底层核心是通过内存屏障(Memory Barrier)实现的。内存屏障是一组CPU指令,它的核心作用有两个:
- 禁止屏障两侧的指令进行重排序
- 强制刷新缓存数据,保证变量的可见性
4.1 内存屏障的四大类型
JMM定义了4种标准的内存屏障,覆盖所有的读写场景:
屏障类型 | 指令示例 | 核心作用 |
|---|---|---|
LoadLoad | Load1; LoadLoad; Load2 | 保证Load1的读操作,先于Load2及后续所有读操作执行 |
StoreStore | Store1; StoreStore; Store2 | 保证Store1的写操作,先于Store2及后续所有写操作执行,刷新到主内存 |
LoadStore | Load1; LoadStore; Store2 | 保证Load1的读操作,先于Store2及后续所有写操作执行 |
StoreLoad | Store1; StoreLoad; Load2 | 保证Store1的写操作,先于Load2及后续所有读操作执行,刷新到主内存,同时清空工作内存副本 |
其中,StoreLoad屏障是功能最强的屏障,它同时具备其他3种屏障的所有功能,也是开销最大的屏障,x86架构下的lock指令就是典型的StoreLoad屏障。
4.2 volatile的内存屏障实现策略
JMM为volatile关键字制定了严格的内存屏障插入策略,保证其可见性和有序性:
- 在每个volatile写操作前,插入StoreStore屏障
- 在每个volatile写操作后,插入StoreLoad屏障
- 在每个volatile读操作后,插入LoadLoad屏障
- 在每个volatile读操作后,插入LoadStore屏障
这个策略完全禁止了volatile变量的读写操作和其他操作的重排序,同时保证了volatile变量的修改会立刻刷新到主内存,读取会从主内存获取最新值。
4.3 JDK 17+ 内存屏障实战:VarHandle的使用
JDK 9之后,官方推出了VarHandle类,替代了不安全的Unsafe类,提供了标准的内存屏障操作,JDK 17中已经完全稳定。VarHandle可以对变量进行细粒度的内存屏障控制,实现和volatile相同的内存语义,同时具备更高的灵活性。
package com.jam.demo.jmm;
import lombok.extern.slf4j.Slf4j;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.VarHandle;
/**
* VarHandle内存屏障示例
* @author ken
*/
@Slf4j
publicclass VarHandleBarrierDemo {
privateint x = 0;
privatevolatileint y = 0;
privatestaticfinal VarHandle X_HANDLE;
static {
try {
X_HANDLE = MethodHandles.lookup().findVarHandle(VarHandleBarrierDemo.class, "x", int.class);
} catch (NoSuchFieldException | IllegalAccessException e) {
thrownew ExceptionInInitializerError(e);
}
}
public void write() {
x = 10;
VarHandle.storeStoreFence();
y = 1;
}
public void read() {
if (y == 1) {
VarHandle.loadLoadFence();
log.info("x的值为:{}", x);
}
}
public static void main(String[] args) throws InterruptedException {
VarHandleBarrierDemo demo = new VarHandleBarrierDemo();
for (int i = 0; i < 10000; i++) {
Thread writer = new Thread(demo::write, "writer-thread-" + i);
Thread reader = new Thread(demo::read, "reader-thread-" + i);
writer.start();
reader.start();
writer.join();
reader.join();
demo.x = 0;
demo.y = 0;
}
log.info("测试完成,所有读操作都能正确获取x的值");
}
}
代码说明:
- 通过
VarHandle.storeStoreFence()禁止x的写操作和y的写操作重排序,保证x的修改先于y的修改完成 - 通过
VarHandle.loadLoadFence()保证y的读操作先于x的读操作执行,只要y等于1,一定能读到x的最新值10 - VarHandle还提供了
fullFence()方法,对应StoreLoad屏障,实现全功能的内存屏障控制
五、JMM的核心规则:Happens-Before先行发生原则
很多开发者对JMM的理解,停留在volatile、synchronized的关键字层面,但实际上,JMM的核心是Happens-Before先行发生原则,它是判断多线程环境下数据是否可见、操作是否有序的唯一标准。
5.1 Happens-Before的核心定义
首先必须纠正一个90%的人都误解的点:Happens-Before不是说A操作在B操作之前执行,而是A操作的执行结果,对B操作完全可见。
JMM定义:如果操作A Happens-Before 操作B,那么A操作的结果对B操作可见,且A操作的执行顺序排在B操作之前。
Happens-Before具备天然的传递性:如果A Happens-Before B,B Happens-Before C,那么A Happens-Before C。
5.2 Happens-Before的8大核心规则
JMM定义了8条天然的Happens-Before规则,无需任何同步操作,这些规则天然生效,是并发编程中可见性和有序性的核心依据。
1. 程序次序规则
在一个线程内,按照控制流顺序,前面的操作Happens-Before于后面的任意操作。
❝注意:是控制流顺序,不是代码顺序,if、for、switch等分支结构,会遵循实际执行的控制流顺序。
2. 管程锁定规则
对同一个锁的unlock操作,Happens-Before于后面对这个锁的lock操作。
❝这是synchronized和Lock的可见性、有序性保障的核心依据,前一个线程解锁前的所有修改,对后一个线程加锁后的所有操作完全可见。
3. volatile变量规则
对一个volatile变量的写操作,Happens-Before于后面对这个变量的读操作。
❝这是volatile可见性、有序性保障的核心依据,写volatile的所有结果,对后续读volatile的操作完全可见。
4. 线程启动规则
Thread对象的start()方法,Happens-Before于此线程内的所有操作。
❝主线程启动子线程前的所有修改,对子线程启动后的所有操作完全可见。
5. 线程终止规则
一个线程内的所有操作,Happens-Before于其他线程对这个线程的终止检测。
❝子线程执行完成后的所有修改,主线程通过Thread.join()等待子线程终止、Thread.isAlive()检测到子线程终止后,完全可见。
6. 线程中断规则
对线程interrupt()方法的调用,Happens-Before于被中断线程检测到中断事件的发生。
❝其他线程调用interrupt()中断线程前的所有修改,被中断线程检测到中断后,完全可见。
7. 对象终结规则
一个对象的初始化完成(构造方法执行结束),Happens-Before于它的finalize()方法的开始。
❝保证对象finalize()方法执行时,一定能看到对象初始化完成后的所有字段值。
8. 传递性规则
如果操作A Happens-Before 操作B,操作B Happens-Before 操作C,那么操作A Happens-Before 操作C。
❝这是Happens-Before规则的核心扩展能力,通过传递性,可以组合多条规则,实现复杂场景的可见性保障。
5.3 Happens-Before规则实战示例
package com.jam.demo.jmm;
import lombok.extern.slf4j.Slf4j;
/**
* Happens-Before规则演示
* @author ken
*/
@Slf4j
publicclass HappensBeforeDemo {
privatestaticint a = 0;
privatestaticvolatileint b = 0;
public static void main(String[] args) throws InterruptedException {
Thread threadA = new Thread(() -> {
a = 10;
b = 1;
}, "threadA");
Thread threadB = new Thread(() -> {
if (b == 1) {
log.info("a的值为:{}", a);
}
}, "threadB");
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
}
规则分析:
- 程序次序规则:threadA中,
a=10Happens-Beforeb=1 - volatile变量规则:threadA中
b=1的写操作,Happens-Before threadB中b==1的读操作 - 传递性规则:
a=10Happens-Beforeb=1,b=1Happens-Beforeb==1的读操作,因此a=10Happens-Before threadB中读取a的操作
因此,只要threadB中读到b等于1,就一定能读到a的值为10,不会出现a为0的情况,这就是Happens-Before规则的核心作用。
六、核心关键字的JMM内存语义
6.1 volatile的完整内存语义
volatile是JMM提供的最轻量级的同步机制,很多开发者只知道它能保证可见性,却不知道它的完整内存语义:
- 可见性:对volatile变量的写操作,立刻刷新到主内存;对volatile变量的读操作,立刻从主内存刷新最新值。
- 有序性:通过内存屏障,完全禁止volatile变量的读写操作和其他操作的重排序。
- 不保证原子性:对volatile变量的复合操作(如i++),不具备原子性保障,这是最常见的踩坑点。
volatile的适用场景:
- 状态标志位:如线程启停的标志位,符合单线程写、多线程读的场景
- DCL单例模式:禁止对象初始化的指令重排序
- 轻量级的事件通知:单线程发布事件,多线程感知事件,无需加锁
6.2 synchronized的完整内存语义
synchronized是JVM内置的锁机制,也是开发中最常用的同步手段,它的内存语义是全方面的:
- 原子性:同一时刻只有一个线程能获取锁,执行锁内的代码块,保证锁内操作的原子性。
- 可见性:unlock操作前,所有变量修改都会同步到主内存;lock操作时,会清空工作内存副本,从主内存读取最新值。
- 有序性:锁的排他性保证锁内代码相当于单线程执行,as-if-serial规则保证有序性,同时禁止锁内操作和锁外操作的重排序。
synchronized的底层通过对象头的Mark Word实现锁升级(无锁→偏向锁→轻量级锁→重量级锁),JDK 17中对synchronized做了大量优化,性能已经和Lock接口非常接近,开发中优先使用synchronized,降低代码复杂度。
6.3 final的完整内存语义
JSR-133规范对final的内存语义做了大幅增强,保证了final字段的初始化安全:
- 写final语义:final字段的写操作,和对象引用的赋值操作,禁止重排序,保证对象引用赋值给其他线程前,final字段已经完成初始化。
- 读final语义:第一次读取对象引用,和第一次读取该对象的final字段,禁止重排序,保证读取final字段前,一定能拿到初始化完成的对象引用。
核心结论:只要对象是正确构造的(构造方法执行完成后,才将对象引用发布给其他线程,没有this溢出),那么其他线程无需任何同步操作,就能看到final字段的正确初始化值。
final的this溢出陷阱实战
package com.jam.demo.jmm;
import lombok.extern.slf4j.Slf4j;
/**
* final字段this溢出错误示例
* @author ken
*/
@Slf4j
publicclass FinalEscapeDemo {
privatefinalint value;
privatestatic FinalEscapeDemo instance;
public FinalEscapeDemo() {
instance = this;
this.value = 10;
}
public static void main(String[] args) throws InterruptedException {
Thread writer = new Thread(FinalEscapeDemo::new, "writer-thread");
Thread reader = new Thread(() -> {
if (instance != null) {
log.info("value的值为:{}", instance.value);
}
}, "reader-thread");
writer.start();
reader.start();
writer.join();
reader.join();
}
}
问题分析: 构造方法中,在final字段初始化前,就将this引用发布给了静态变量instance,其他线程拿到instance对象时,final字段value可能还没有完成初始化,会读到默认值0,即使value是final修饰的。
正确做法:在构造方法执行完成后,再发布对象引用,避免this溢出。
七、高并发实战:伪共享问题与解决方案
7.1 什么是伪共享
CPU缓存是以缓存行(Cache Line)为单位存储的,主流CPU的缓存行大小是64字节,一个long类型占8字节,因此一个缓存行可以存储8个long类型的变量。
当多个线程同时修改同一个缓存行中的不同变量时,即使这些变量之间没有任何关联,也会因为缓存一致性协议,导致缓存行频繁失效,性能急剧下降,这就是伪共享(False Sharing)问题。
伪共享是高并发场景下的隐形性能杀手,很多并发框架(Disruptor、Netty)都针对伪共享做了专门的优化。
7.2 伪共享实战与解决方案
package com.jam.demo.jmm;
import lombok.extern.slf4j.Slf4j;
import jdk.internal.vm.annotation.Contended;
/**
* 伪共享问题演示与解决方案
* @author ken
*/
@Slf4j
publicclass FalseSharingDemo {
privatestaticfinalint THREAD_COUNT = 2;
privatestaticfinallong LOOP_COUNT = 1000_000_000L;
staticclass NoPaddingObject {
publicvolatilelong value = 0L;
}
staticclass ManualPaddingObject {
publicvolatilelong value = 0L;
publiclong p1, p2, p3, p4, p5, p6, p7;
}
staticclass ContendedObject {
@Contended
publicvolatilelong value = 0L;
}
public static void main(String[] args) throws InterruptedException {
NoPaddingObject[] noPaddingObjects = new NoPaddingObject[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
noPaddingObjects[i] = new NoPaddingObject();
}
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
int index = i;
threads[i] = new Thread(() -> {
for (long j = 0; j < LOOP_COUNT; j++) {
noPaddingObjects[index].value = j;
}
}, "no-padding-thread-" + i);
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
long end = System.currentTimeMillis();
log.info("无填充的执行时间:{}ms", end - start);
ManualPaddingObject[] manualPaddingObjects = new ManualPaddingObject[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
manualPaddingObjects[i] = new ManualPaddingObject();
}
start = System.currentTimeMillis();
threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
int index = i;
threads[i] = new Thread(() -> {
for (long j = 0; j < LOOP_COUNT; j++) {
manualPaddingObjects[index].value = j;
}
}, "manual-padding-thread-" + i);
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
end = System.currentTimeMillis();
log.info("手动填充的执行时间:{}ms", end - start);
ContendedObject[] contendedObjects = new ContendedObject[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
contendedObjects[i] = new ContendedObject();
}
start = System.currentTimeMillis();
threads = new Thread[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; i++) {
int index = i;
threads[i] = new Thread(() -> {
for (long j = 0; j < LOOP_COUNT; j++) {
contendedObjects[index].value = j;
}
}, "contended-thread-" + i);
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
end = System.currentTimeMillis();
log.info("@Contended注解的执行时间:{}ms", end - start);
}
}
执行结果说明:
- 无填充的执行时间,是手动填充和@Contended注解的3-5倍,性能差距极大
- 手动填充和@Contended注解的执行时间基本一致,都完美解决了伪共享问题
解决方案说明:
- 手动填充:在变量前后填充7个long类型的字段,让变量单独占满一个64字节的缓存行,避免和其他变量共享缓存行。
- @Contended注解:JDK提供的官方注解,自动为字段添加缓存行填充,避免伪共享。JDK 17中需要添加JVM启动参数
--add-exports java.base/jdk.internal.vm.annotation=ALL-UNNAMED才能使用。
八、JMM并发编程最佳实践与高频踩坑点
8.1 高频踩坑点避坑指南
- 误以为volatile能保证原子性:volatile只能保证可见性和有序性,不能保证复合操作的原子性,i++、count+=1这类操作必须使用原子类或锁机制。
- 混淆JMM内存划分和JVM内存区域:工作内存不是栈,主内存不是堆,两者是完全不同的概念,不要混淆。
- DCL单例忘记加volatile:会导致指令重排序,出现半初始化的对象,引发空指针异常。
- 构造方法中发生this溢出:导致final字段的初始化安全被破坏,其他线程读到未初始化的字段值。
- 忽略伪共享问题:高并发场景下,多线程修改相邻的变量,导致性能急剧下降,却找不到原因。
- 在循环中使用System.out.println()调试并发问题:println方法有synchronized修饰,会触发内存刷新,掩盖可见性问题,导致本地调试正常,生产环境出现问题。
8.2 生产环境最佳实践
- 优先使用高层级并发工具:优先使用java.util.concurrent包下的并发工具(原子类、并发集合、线程池、CountDownLatch等),不要手动使用volatile和synchronized实现复杂的并发逻辑,高层级工具已经做了完善的优化和正确性保障。
- 尽量减少共享变量的使用:并发问题的根源是共享变量的竞争,能不共享就不共享,优先使用线程隔离(ThreadLocal)、不可变对象,不可变对象天生线程安全,无需任何同步操作。
- 缩小锁的粒度:只在需要同步的代码块加锁,减少锁的持有时间,避免整个方法加锁,同时避免频繁的加锁解锁操作。
- 正确使用volatile:只有满足以下两个条件,才使用volatile:① 对变量的写操作不依赖当前值,或只有单线程执行写操作;② 变量没有包含在其他变量的不变式中。
- 优先使用不可变对象:使用final修饰类和字段,构建不可变对象,JMM对final字段有特殊的初始化安全保障,不可变对象是并发编程中最安全的对象类型。
- 高并发场景下避免伪共享:对高并发写的变量,使用@Contended注解或手动填充,避免伪共享带来的性能损耗。
九、项目依赖配置
本文所有示例代码,均基于JDK 17:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jam.demo</groupId>
<artifactId>jmm-demo</artifactId>
<version>1.0.0-SNAPSHOT</version>
<name>jmm-demo</name>
<description>JMM内存模型实战示例项目</description>
<properties>
<java.version>17</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<lombok.version>1.18.34</lombok.version>
<spring.version>6.1.14</spring.version>
<fastjson2.version>2.0.53</fastjson2.version>
<guava.version>33.2.1-jre</guava.version>
<mybatis-plus.version>3.5.7</mybatis-plus.version>
<springdoc.version>2.6.0</springdoc.version>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${springdoc.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>3.3.4</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.13.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
总结
JMM是Java并发编程的绝对基石,它的核心价值是通过一套统一的规范,屏蔽底层硬件和操作系统的内存模型差异,为Java开发者提供一致的并发编程语义。本文从硬件底层原理出发,完整讲解了JMM的抽象结构、三大核心特性、内存屏障底层实现、Happens-Before核心规则,结合可运行的实战代码,拆解了开发中高频的踩坑点,最终给出了生产环境的最佳实践。 理解JMM,本质上是理解多线程环境下,共享变量的读写规则,只有彻底吃透这些规则,才能写出正确、高效的并发代码,从根源上避免诡异的并发问题。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号