中间件:高可用、高性能、可扩展三大核心设计原则

中间件:高可用、高性能、可扩展三大核心设计原则

果酱带你啃java
发布于 2026-04-14 15:31:17
发布于 2026-04-14 15:31:17
分布式系统的浪潮下,中间件早已成为企业级架构的核心基础设施。从RPC框架、消息队列,到缓存、数据库中间件,每一个支撑海量流量的系统背后,都离不开稳定可靠的中间件。而决定一个中间件能走多远、能扛多大压力的核心,永远绕不开三个灵魂级的设计原则:高可用、高性能、可扩展。
一、高可用设计原则:让系统在故障中依然屹立不倒
高可用的核心本质,是系统在面对各类异常场景(硬件故障、网络波动、流量洪峰、程序bug)时,依然能够持续对外提供服务的能力。行业内通常用SLA(服务等级协议)来量化这一能力,核心目标是减少非计划停机时间,阻止故障扩散。
这里需要明确一个常见的认知误区:高可用≠多实例。很多人以为部署两个节点就实现了高可用,实则不然。如果两个节点共用同一个单点数据库,数据库挂了,两个节点都会失效;如果没有故障隔离机制,一个节点故障导致流量全量打到第二个节点,直接把健康节点也打垮,引发雪崩,这根本算不上真正的高可用。
1.1 故障隔离:把故障锁在最小范围内
分布式系统的故障是必然发生的,我们无法杜绝故障,但可以阻止故障的扩散。这就像轮船的舱壁设计,一个舱室进水,不会导致整艘船沉没,这就是经典的舱壁模式(Bulkhead Pattern)。
故障隔离的核心实现方案分为三类:
- 线程池隔离:不同的服务/接口使用独立的线程池,避免一个慢接口占满整个服务的线程资源,导致其他正常接口无法响应
- 进程/容器隔离:不同的业务模块部署在独立的进程/容器中,避免一个模块OOM导致整个服务宕机
- 熔断隔离:当依赖的服务出现大量异常时,自动熔断请求,不再调用故障服务,避免线程被故障服务的超时等待占满,引发雪崩
代码实例:基于Resilience4j的舱壁与熔断隔离实现
项目基础依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<groupId>com.jam</groupId>
<artifactId>middleware-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>middleware-demo</name>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.32</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot3</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.1.0-jre</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.49</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.115.Final</version>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.6</version>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.3.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot3-starter</artifactId>
<version>5.4.1</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.25.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
业务服务实现
package com.jam.demo.service;
import io.github.resilience4j.bulkhead.annotation.Bulkhead;
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
/**
* 订单服务
* @author ken
*/
@Slf4j
@Service
publicclass OrderService {
/**
* 创建订单核心接口
* @param orderId 订单ID
* @return 订单创建结果
*/
@Bulkhead(name = "orderService", type = Bulkhead.Type.THREADPOOL)
@CircuitBreaker(name = "orderService", fallbackMethod = "createOrderFallback")
public String createOrder(String orderId) {
log.info("开始创建订单,订单ID:{}", orderId);
// 核心订单创建逻辑
return"订单创建成功,订单ID:" + orderId;
}
/**
* 订单创建降级方法
* @param orderId 订单ID
* @param e 异常对象
* @return 降级结果
*/
private String createOrderFallback(String orderId, Exception e) {
log.error("订单创建失败,触发降级,订单ID:{}", orderId, e);
return"当前系统繁忙,请稍后重试";
}
}
接口层实现
package com.jam.demo.controller;
import com.jam.demo.service.OrderService;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.Parameter;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* 订单接口
* @author ken
*/
@RestController
@RequestMapping("/order")
@RequiredArgsConstructor
@Tag(name = "订单管理", description = "订单相关接口")
publicclass OrderController {
privatefinal OrderService orderService;
/**
* 创建订单接口
* @param orderId 订单ID
* @return 订单创建结果
*/
@PostMapping("/create")
@Operation(summary = "创建订单", description = "创建新的订单")
public String createOrder(
@Parameter(description = "订单ID", required = true) @RequestParam String orderId) {
return orderService.createOrder(orderId);
}
}
1.2 冗余备份与故障自动转移
单点是高可用的天敌,任何单点故障都会导致整个系统不可用。冗余备份的核心是消除单点,而故障自动转移则是在节点故障时,无需人工干预,自动把流量切换到健康的备份节点,保障服务持续可用。
核心实现方案分为三个环节:
- 多副本冗余:通过主从架构、集群架构实现数据与服务的多副本备份,副本分为同步副本(强一致性优先)和异步副本(高可用性优先)
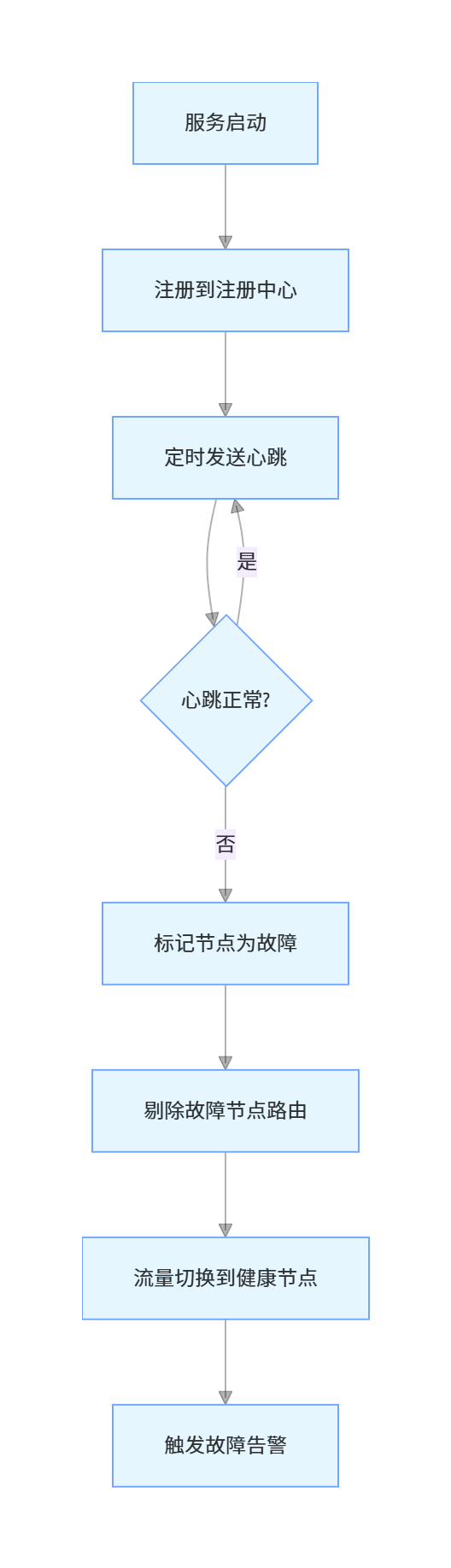
- 心跳检测:通过定时心跳机制检测节点健康状态,精准判断节点是否故障,核心是平衡心跳超时时间,避免误判与故障转移不及时的问题
- 故障自动转移(Failover):检测到主节点故障后,自动从副本节点中选举出新的主节点,更新路由信息,将流量无缝切换到新主节点,整个过程对调用方透明
故障转移核心流程
1.3 限流与降级兜底
系统的承载能力永远有上限,当流量超过系统承载阈值时,最有效的保护方式就是限流:只放行系统能承载的流量,超出的流量直接拒绝。同时对非核心业务进行降级,释放资源给核心业务,确保核心服务的可用性。
核心实现方案分为两类:
- 限流算法:固定窗口限流、滑动窗口限流、令牌桶限流、漏桶限流。其中令牌桶适合应对突发流量,漏桶适合平滑流量,是目前最常用的两种限流算法
- 降级策略:熔断降级、开关降级、兜底降级。核心是优先保障核心业务,非核心业务在流量高峰时可以降级,返回兜底数据
代码实例:令牌桶限流实现
package com.jam.demo.limit;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.atomic.AtomicLong;
/**
* 令牌桶限流实现
* @author ken
*/
@Slf4j
publicclass TokenBucket {
/**
* 令牌桶容量
*/
privatefinallong capacity;
/**
* 令牌生成速率(个/秒)
*/
privatefinallong rate;
/**
* 当前令牌数量
*/
privatefinal AtomicLong currentTokens;
/**
* 上次令牌生成时间
*/
privatefinal AtomicLong lastRefillTime;
public TokenBucket(long capacity, long rate) {
this.capacity = capacity;
this.rate = rate;
this.currentTokens = new AtomicLong(capacity);
this.lastRefillTime = new AtomicLong(System.currentTimeMillis());
}
/**
* 尝试获取令牌
* @param requiredTokens 需要的令牌数量
* @return 是否获取成功
*/
public synchronized boolean tryAcquire(long requiredTokens) {
refillTokens();
long current = currentTokens.get();
if (current >= requiredTokens) {
currentTokens.addAndGet(-requiredTokens);
returntrue;
}
returnfalse;
}
/**
* 补充令牌
*/
private void refillTokens() {
long now = System.currentTimeMillis();
long lastTime = lastRefillTime.get();
long elapsedTime = now - lastTime;
if (elapsedTime > 0) {
long newTokens = (elapsedTime * rate) / 1000;
if (newTokens > 0) {
long totalTokens = Math.min(currentTokens.get() + newTokens, capacity);
currentTokens.set(totalTokens);
lastRefillTime.set(now);
}
}
}
}
1.4 数据一致性保障
高可用不能以数据丢失为代价,冗余备份的同时,必须保障数据的一致性。核心是在一致性与可用性之间找到平衡,根据业务场景选择合适的复制策略。
核心复制策略对比:
- 同步复制:写操作必须同步到所有副本后才返回成功,强一致性保障,但可用性低,任意副本故障都会导致写操作失败
- 异步复制:写操作在主节点执行成功后立即返回,异步同步到副本,可用性高,但主节点故障时可能丢失数据
- 半同步复制:写操作至少同步到一个副本后才返回成功,平衡了一致性与可用性,是目前主流数据库、消息队列采用的复制策略
这里需要明确CAP定理的核心:分区容错性(P)是分布式系统的前提,网络分区必然会发生,因此只能在一致性(C)和可用性(A)之间做平衡,不存在绝对的CA系统。
二、高性能设计原则:把硬件性能压榨到极致
高性能的核心本质,是在有限的硬件资源下,系统实现更低的请求延迟、更高的并发吞吐量。核心目标是减少无效开销,最大化硬件资源的利用率。
这里需要纠正一个常见的认知误区:高性能≠高并发。高并发是系统能同时处理的请求数,高性能是高并发的基础,没有高性能的设计,高并发只是空中楼阁。同时,高性能也不是一味堆硬件,而是通过合理的设计,把硬件的性能发挥到极致。
2.1 网络IO模型优化
网络通信是中间件性能的第一个瓶颈,80%的中间件性能问题都出在网络IO模型上。从BIO到NIO,再到IO多路复用,本质上都是为了减少线程阻塞,降低线程上下文切换的开销,最大化CPU的利用率。
四种核心IO模型的核心差异:
- BIO(阻塞IO):每个连接对应一个线程,线程在读写数据时全程阻塞,并发量上来后线程数会爆炸,上下文切换开销极大,仅能支撑数百级别的并发
- NIO(非阻塞IO):线程发起IO请求后立即返回,无需阻塞等待,通过轮询检查数据是否就绪,但轮询会消耗大量CPU资源
- IO多路复用:用一个或少量线程监听多个连接的IO事件,仅当连接有IO事件就绪时,才通知线程处理,是目前高性能网络组件的核心模型,Linux下的epoll、Java中的Selector都是对该模型的封装
- 异步IO(AIO):IO操作完全交给操作系统,操作系统完成IO操作后再通知线程处理,Linux下的AIO实现不够成熟,目前工业界应用最广泛的还是IO多路复用
基于IO多路复用的Reactor模型,是目前高性能网络组件的标准实现,分为三种经典模式:
- 单Reactor单线程:所有IO操作和业务处理都在一个线程中完成,适合业务逻辑极简单的场景,典型代表是Redis
- 单Reactor多线程:Reactor线程仅负责监听和分发IO事件,业务处理交给线程池,适合业务逻辑较复杂的场景,但单Reactor在高并发下会成为瓶颈
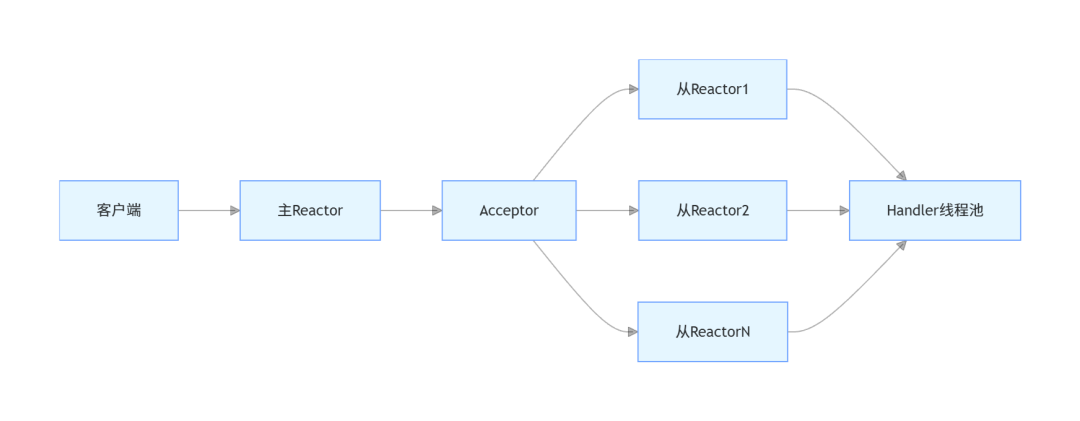
- 主从Reactor多线程:主Reactor仅负责监听连接的建立,建立完成的连接交给从Reactor监听IO事件,业务处理交给线程池,是目前性能最优的模型,Netty就是基于该模型实现的
主从Reactor模型架构
代码实例:基于Netty的主从Reactor高性能服务端实现
package com.jam.demo.netty;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.ChannelFuture;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.ChannelOption;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.handler.codec.string.StringDecoder;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.util.CharsetUtil;
import lombok.extern.slf4j.Slf4j;
/**
* Netty高性能服务端
* @author ken
*/
@Slf4j
publicclass NettyServer {
privatefinalint port;
public NettyServer(int port) {
this.port = port;
}
/**
* 启动服务端
* @throws InterruptedException 中断异常
*/
public void start() throws InterruptedException {
// 主Reactor线程组,仅负责处理连接建立
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
// 从Reactor线程组,负责处理IO事件
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childOption(ChannelOption.TCP_NODELAY, true)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
ch.pipeline()
.addLast(new StringDecoder(CharsetUtil.UTF_8))
.addLast(new StringEncoder(CharsetUtil.UTF_8))
.addLast(new ServerHandler());
}
});
ChannelFuture future = bootstrap.bind(port).sync();
log.info("Netty服务端启动成功,端口:{}", port);
future.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
public static void main(String[] args) throws InterruptedException {
new NettyServer(8080).start();
}
}
package com.jam.demo.netty;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.SimpleChannelInboundHandler;
import lombok.extern.slf4j.Slf4j;
/**
* 服务端业务处理器
* @author ken
*/
@Slf4j
publicclass ServerHandler extends SimpleChannelInboundHandler<String> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) {
log.info("收到客户端消息:{}", msg);
ctx.writeAndFlush("服务端已收到消息:" + msg);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
log.error("通道发生异常", cause);
ctx.close();
}
}
2.2 内存管理优化
Java的GC是影响系统性能的核心因素,频繁的Full GC会导致STW(Stop The World),引发系统卡顿、吞吐量下降。同时,数据在内存与磁盘、网络之间的拷贝,也会带来大量的性能开销。内存优化的核心,就是减少GC开销,减少数据拷贝次数。
核心实现方案分为三类:
- 堆外内存:JVM堆内内存受GC管理,堆外内存(Direct Memory)不受GC管理,生命周期由手动控制,大幅降低GC压力。同时在网络传输时,无需从堆内拷贝到堆外,减少一次数据拷贝,Netty的ByteBuf就是基于堆外内存实现的
- 零拷贝技术:减少数据在用户态和内核态之间的拷贝次数。Linux下的sendFile系统调用,可直接把文件从内核缓冲区拷贝到Socket缓冲区,无需经过用户态,Java中的FileChannel.transferTo()就是对sendFile的封装;mmap技术把文件映射到用户态内存,无需read系统调用,直接操作内存,Java中的MappedByteBuffer是对mmap的封装
- 对象池与内存池:频繁创建和销毁对象会导致YGC频繁,通过对象池复用对象,减少对象的创建和销毁;内存池提前申请一块连续内存,后续内存申请都从该内存块分配,避免频繁向操作系统申请和释放内存,Netty的PooledByteBufAllocator就是内存池的成熟实现
2.3 锁与并发优化
多线程并发是提升CPU利用率的核心,但线程之间的锁竞争,会导致线程阻塞、上下文切换开销增大,甚至引发死锁。并发优化的核心,就是降低锁竞争的粒度,甚至实现无锁设计。
核心实现方案分为四类:
- 无锁设计:基于CAS(Compare And Swap)实现无锁操作,CAS是CPU硬件级别的原子操作,无需加锁,避免了锁竞争的开销,Java中的Atomic系列类就是基于CAS实现的
- 分段锁:把整个数据结构分成多个段,每个段独立加锁,不同段的操作不会产生锁竞争,JDK1.7的ConcurrentHashMap就是基于分段锁实现的
- 读写锁:读多写少的场景下,使用ReentrantReadWriteLock,读操作共享锁,写操作独占锁,读与读之间不会产生竞争,大幅提升并发量
- 无锁队列:基于环形数组的无锁队列,典型代表是Disruptor,通过CAS实现无锁的生产消费模型,吞吐量比LinkedBlockingQueue高两个数量级以上,是RocketMQ、Storm等高性能中间件的核心组件
代码实例:基于Disruptor的无锁生产消费模型实现
package com.jam.demo.disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.util.DaemonThreadFactory;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
/**
* 消息事件
* @author ken
*/
@Data
public class MessageEvent {
private String message;
}
package com.jam.demo.disruptor;
import com.lmax.disruptor.EventHandler;
import lombok.extern.slf4j.Slf4j;
/**
* 消息事件处理器
* @author ken
*/
@Slf4j
public class MessageEventHandler implements EventHandler<MessageEvent> {
@Override
public void onEvent(MessageEvent event, long sequence, boolean endOfBatch) {
log.info("消费消息:{},序列号:{}", event.getMessage(), sequence);
}
}
package com.jam.demo.disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.util.DaemonThreadFactory;
import lombok.extern.slf4j.Slf4j;
/**
* Disruptor服务启动类
* @author ken
*/
@Slf4j
publicclass DisruptorServer {
public static void main(String[] args) {
// 环形缓冲区大小,必须是2的幂
int bufferSize = 1024 * 1024;
// 创建Disruptor实例
Disruptor<MessageEvent> disruptor = new Disruptor<>(
MessageEvent::new,
bufferSize,
DaemonThreadFactory.INSTANCE
);
// 设置事件处理器
disruptor.handleEventsWith(new MessageEventHandler());
// 启动Disruptor
disruptor.start();
// 获取环形缓冲区
RingBuffer<MessageEvent> ringBuffer = disruptor.getRingBuffer();
// 生产消息
for (int i = 0; i < 100; i++) {
long sequence = ringBuffer.next();
try {
MessageEvent event = ringBuffer.get(sequence);
event.setMessage("测试消息-" + i);
} finally {
ringBuffer.publish(sequence);
}
}
// 关闭Disruptor
disruptor.shutdown();
}
}
2.4 序列化与反序列化优化
分布式系统中,网络传输的对象必须经过序列化和反序列化,这个过程的性能开销,直接影响整个系统的吞吐量和延迟。序列化优化的核心,就是减小序列化后的体积,提升序列化/反序列化的速度。
核心实现方案分为两类:
- 选择高性能的序列化框架:JSON类框架可读性好,但性能一般,序列化后体积大;二进制序列化框架(Protobuf、Hessian2、Kryo)性能更优,体积更小,其中Protobuf跨语言兼容性好,性能稳定,是gRPC等主流RPC框架的默认序列化方案
- 序列化优化技巧:避免序列化大对象,拆分大对象为多个小对象;仅序列化需要传输的字段,过滤无用字段;使用基本类型代替包装类型,减少序列化开销
2.5 数据结构与算法优化
数据结构是程序的基础,不同的数据结构在不同场景下,性能差异能达到几个数量级。算法优化的核心,就是选择时间复杂度和空间复杂度最优的数据结构,适配业务场景。
核心优化方案分为三类:
- 跳表(SkipList):平衡树的替代方案,插入、删除、查询的时间复杂度均为O(logn),但实现更简单,无需旋转平衡,并发控制更容易,Redis的Sorted Set、LevelDB、RocksDB都采用了跳表实现
- 布隆过滤器(Bloom Filter):基于位图实现的概率型数据结构,用于快速判断一个元素是否存在于集合中,不存在的判断100%准确,存在的判断有可控的误判率,适合用于减少缓存穿透、无效数据库查询,Guava提供了成熟的布隆过滤器实现
- 环形数组:比链表更高效的队列实现,内存连续,CPU缓存命中率高,无需频繁创建和销毁节点,Disruptor、ArrayBlockingQueue都是基于环形数组实现的
代码实例:基于布隆过滤器解决缓存穿透问题
package com.jam.demo.bloom;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
* 商品实体
* @author ken
*/
@Data
@TableName("t_product")
publicclass Product {
@TableId(type = IdType.AUTO)
private Long id;
private String productName;
private Long price;
private Integer stock;
}
package com.jam.demo.bloom;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;
/**
* 商品Mapper
* @author ken
*/
@Mapper
public interface ProductMapper extends BaseMapper<Product> {
}
package com.jam.demo.bloom;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import jakarta.annotation.PostConstruct;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 商品服务
* @author ken
*/
@Slf4j
@Service
@RequiredArgsConstructor
publicclass ProductService {
privatefinal ProductMapper productMapper;
privatefinal RedisTemplate<String, Object> redisTemplate;
private BloomFilter<Long> bloomFilter;
privatestaticfinal String PRODUCT_KEY_PREFIX = "product:";
privatestaticfinallong EXPECTED_INSERTIONS = 1000000L;
privatestaticfinaldouble FPP = 0.001;
@PostConstruct
public void initBloomFilter() {
log.info("开始初始化布隆过滤器");
List<Long> productIdList = productMapper.selectList(null).stream().map(Product::getId).toList();
bloomFilter = BloomFilter.create(Funnels.longFunnel(), EXPECTED_INSERTIONS, FPP);
for (Long productId : productIdList) {
bloomFilter.put(productId);
}
log.info("布隆过滤器初始化完成,共加载{}个商品ID", productIdList.size());
}
/**
* 根据ID查询商品
* @param id 商品ID
* @return 商品信息
*/
public Product getProductById(Long id) {
// 布隆过滤器拦截不存在的ID,避免缓存穿透
if (!bloomFilter.mightContain(id)) {
log.info("布隆过滤器拦截不存在的商品ID:{}", id);
returnnull;
}
// 查询缓存
String key = PRODUCT_KEY_PREFIX + id;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 查询数据库
product = productMapper.selectById(id);
if (product != null) {
redisTemplate.opsForValue().set(key, product);
}
return product;
}
}
MySQL表结构
CREATE TABLE`t_product` (
`id`bigintNOTNULL AUTO_INCREMENT COMMENT'商品ID',
`product_name`varchar(255) NOTNULLCOMMENT'商品名称',
`price`bigintNOTNULLCOMMENT'商品价格(分)',
`stock`intNOTNULLDEFAULT'0'COMMENT'商品库存',
PRIMARY KEY (`id`)
) ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='商品表';
三、可扩展设计原则:让系统适配业务的无限变化
可扩展的核心本质,是系统在面对需求变化、流量增长、功能迭代时,无需重构核心架构,仅通过最小化的代码改动,就能快速支撑新的需求。核心目标是解耦依赖,实现开闭原则——对扩展开放,对修改关闭。
这里需要纠正一个常见的认知误区:可扩展≠可伸缩。可伸缩是指通过增加机器就能线性提升系统性能,属于水平扩展,是可扩展的一个子集;可扩展还包括功能的垂直扩展,新增功能无需修改核心代码。
3.1 SPI机制与插件化架构
SPI(Service Provider Interface)是一种服务发现机制,核心是把核心接口和实现分离,核心系统仅依赖接口,具体的实现由第三方插件提供,运行时动态加载,实现了核心逻辑和扩展逻辑的完全解耦,是插件化架构的核心基础。
Java原生的SPI机制,通过META-INF/services目录下的配置文件指定接口的实现类,由ServiceLoader动态加载;Spring的SPI机制通过META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件加载;Dubbo的SPI机制在原生SPI的基础上,增加了IOC和AOP的支持,功能更强大。
代码实例:基于Java SPI的插件化实现
核心接口定义
package com.jam.demo.spi;
/**
* 序列化接口
* @author ken
*/
public interface Serializer {
/**
* 序列化
* @param obj 待序列化对象
* @return 序列化后的字节数组
*/
byte[] serialize(Object obj);
/**
* 反序列化
* @param data 字节数组
* @param clazz 目标类
* @return 反序列化后的对象
* @param <T> 泛型类型
*/
<T> T deserialize(byte[] data, Class<T> clazz);
/**
* 获取序列化类型名称
* @return 类型名称
*/
String getName();
}
Fastjson2实现类
package com.jam.demo.spi.impl;
import com.alibaba.fastjson2.JSON;
import com.jam.demo.spi.Serializer;
/**
* Fastjson2序列化实现
* @author ken
*/
publicclass Fastjson2Serializer implements Serializer {
@Override
publicbyte[] serialize(Object obj) {
return JSON.toJSONBytes(obj);
}
@Override
public <T> T deserialize(byte[] data, Class<T> clazz) {
return JSON.parseObject(data, clazz);
}
@Override
public String getName() {
return"fastjson2";
}
}
Protobuf实现类
package com.jam.demo.spi.impl;
import com.google.protobuf.Message;
import com.jam.demo.spi.Serializer;
/**
* Protobuf序列化实现
* @author ken
*/
publicclass ProtobufSerializer implements Serializer {
@Override
publicbyte[] serialize(Object obj) {
if (!(obj instanceof Message)) {
thrownew IllegalArgumentException("Protobuf序列化对象必须实现Message接口");
}
return ((Message) obj).toByteArray();
}
@Override
@SuppressWarnings("unchecked")
public <T> T deserialize(byte[] data, Class<T> clazz) {
if (!Message.class.isAssignableFrom(clazz)) {
thrownew IllegalArgumentException("Protobuf反序列化目标类必须实现Message接口");
}
try {
Message defaultInstance = (Message) clazz.getMethod("getDefaultInstance").invoke(null);
return (T) defaultInstance.newBuilderForType().mergeFrom(data).build();
} catch (Exception e) {
thrownew RuntimeException("Protobuf反序列化失败", e);
}
}
@Override
public String getName() {
return"protobuf";
}
}
SPI配置文件在resources/META-INF/services目录下创建文件com.jam.demo.spi.Serializer,内容如下:
com.jam.demo.spi.impl.Fastjson2Serializer
com.jam.demo.spi.impl.ProtobufSerializer
SPI服务加载器
package com.jam.demo.spi;
import com.google.common.collect.Maps;
import java.util.Map;
import java.util.ServiceLoader;
/**
* 序列化器工厂
* @author ken
*/
publicclass SerializerFactory {
privatestaticfinal Map<String, Serializer> SERIALIZER_MAP = Maps.newHashMap();
static {
// 加载所有SPI实现
ServiceLoader<Serializer> serviceLoader = ServiceLoader.load(Serializer.class);
for (Serializer serializer : serviceLoader) {
SERIALIZER_MAP.put(serializer.getName(), serializer);
}
}
/**
* 根据名称获取序列化器
* @param name 序列化器名称
* @return 序列化器实例
*/
public static Serializer getSerializer(String name) {
return SERIALIZER_MAP.get(name);
}
}
3.2 微内核架构
微内核架构(也叫插件化架构),把系统分为两部分:核心系统(微内核)和插件模块。核心系统仅负责插件的生命周期管理、插件之间的通信、核心配置的管理,是系统最稳定的部分,不会轻易改动;所有的业务逻辑、功能扩展都以插件的形式存在,插件之间相互独立,可插拔,新增功能仅需开发新的插件,无需修改核心系统。
微内核架构的核心优势:稳定性高,核心系统改动极少;可扩展性强,新增功能仅需新增插件;可维护性高,插件之间完全解耦,出问题仅需禁用对应插件,不影响整个系统。Eclipse、IDEA、Dubbo、RocketMQ都采用了微内核的设计思想。
3.3 接口与协议标准化
可扩展的前提是标准化,只有统一的接口规范、统一的协议格式,才能实现不同实现之间的无缝替换,新增扩展不会影响现有系统。协议设计的核心,是预留扩展字段,保证向前兼容,新增功能无需修改协议的核心结构,旧版本客户端能正常访问新版本服务端,新版本服务端也能兼容旧版本客户端。
核心实现方案分为两类:
- 接口标准化:基于面向接口编程,所有扩展点都定义统一的接口,接口一旦确定就不会轻易修改,新增功能通过新增接口实现类完成,而非修改接口
- 协议可扩展设计:协议头预留扩展字段,采用TLV(Tag-Length-Value)格式存储扩展内容,新增扩展字段不会影响现有字段的解析,保证协议的向前兼容,TCP、HTTP、Dubbo协议都采用了类似的设计
3.4 集群水平扩展
当系统流量增长,单节点性能达到瓶颈时,最有效的扩展方式就是水平扩展,通过增加机器节点,线性提升系统的承载能力。水平扩展的核心前提是无状态设计,节点之间没有依赖,任何一个节点都能处理所有请求,请求可以分发到任意一个节点,新增节点仅需注册到集群中,就能承接流量,无需修改任何配置。
核心实现方案分为三类:
- 无状态设计:所有的状态数据(用户会话、业务数据)都存储在分布式存储中,节点本身不存储任何状态,节点之间完全对等,可随时替换、新增、删除
- 分片/分区机制:对于有状态的系统,通过分片机制把数据分散到多个节点上,每个节点仅负责一部分数据,新增节点仅需迁移部分分片数据,就能线性提升系统的存储和处理能力,典型代表是Redis Cluster的哈希槽分片、MySQL的分库分表
- 一致性哈希算法:解决传统哈希取模分片,新增节点时需要迁移大量数据的问题。一致性哈希把哈希空间组成一个环形,每个节点对应环上的一个位置,数据根据哈希值落到环上的对应位置,顺时针找到第一个节点存储,新增节点时,仅需迁移相邻节点的部分数据,大幅减少数据迁移量,是分布式缓存、负载均衡的核心算法
代码实例:一致性哈希负载均衡实现
package com.jam.demo.hash;
import com.google.common.collect.Lists;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 一致性哈希实现
* @author ken
*/
publicclass ConsistentHash {
/**
* 虚拟节点数量
*/
privatestaticfinalint VIRTUAL_NODE_COUNT = 160;
/**
* 哈希环
*/
privatefinal SortedMap<Long, String> hashRing = new TreeMap<>();
/**
* 真实节点列表
*/
privatefinal List<String> realNodes = Lists.newArrayList();
/**
* 添加节点
* @param node 节点地址
*/
public void addNode(String node) {
realNodes.add(node);
// 添加虚拟节点
for (int i = 0; i < VIRTUAL_NODE_COUNT; i++) {
String virtualNodeName = node + "&&VN" + i;
long hash = hash(virtualNodeName);
hashRing.put(hash, node);
}
}
/**
* 移除节点
* @param node 节点地址
*/
public void removeNode(String node) {
realNodes.remove(node);
// 移除虚拟节点
for (int i = 0; i < VIRTUAL_NODE_COUNT; i++) {
String virtualNodeName = node + "&&VN" + i;
long hash = hash(virtualNodeName);
hashRing.remove(hash);
}
}
/**
* 根据key获取对应的节点
* @param key 路由key
* @return 节点地址
*/
public String getNode(String key) {
if (hashRing.isEmpty()) {
returnnull;
}
long hash = hash(key);
// 顺时针查找第一个节点
SortedMap<Long, String> subMap = hashRing.tailMap(hash);
Long targetHash = subMap.isEmpty() ? hashRing.firstKey() : subMap.firstKey();
return hashRing.get(targetHash);
}
/**
* MD5哈希算法
* @param key 待哈希的key
* @return 哈希值
*/
private long hash(String key) {
try {
MessageDigest md5 = MessageDigest.getInstance("MD5");
byte[] digest = md5.digest(key.getBytes());
return ((long) (digest[3] & 0xFF) << 24)
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
} catch (NoSuchAlgorithmException e) {
thrownew RuntimeException("MD5算法不存在", e);
}
}
}
四、三大原则的协同与平衡
很多开发者会陷入一个误区,认为三个原则是相互独立的,甚至是相互冲突的。比如为了高可用做了多副本同步复制,会影响性能;为了高性能做了很多定制化优化,会影响可扩展性。实则不然,三个原则是相辅相成的,优秀的中间件设计,一定是在三个原则之间找到了最优的平衡。
- 高可用是高性能的基础:如果系统经常宕机,再高的性能也没有意义,高可用保障了系统能持续提供服务,高性能才能发挥价值
- 高性能是可扩展的前提:如果单节点性能很差,即使水平扩展,也需要大量的机器,成本极高。把单节点性能优化到极致,再通过水平扩展提升整体承载能力,才是最优的方案
- 可扩展是高可用和高性能的长期保障:业务在不断发展,流量在不断增长,只有可扩展的架构,才能支撑业务的长期发展,持续优化高可用和高性能的能力,而不是每次业务变化都要重构架构
Kafka就是三大原则完美平衡的典范:通过多副本机制、ISR同步、故障自动转移实现高可用;通过顺序写磁盘、零拷贝、批量传输实现高性能;通过分区水平扩展、插件化架构实现可扩展,最终成为了工业界公认的高性能、高可靠消息队列。
写在最后
不管你是在使用开源中间件,想要深入理解背后的原理,排查线上问题;还是想要自研中间件,打造适合自己业务的基础设施,都要围绕这三个原则来思考,从底层逻辑出发,结合业务场景,选择最合适的实现方案。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号