AI时代如何沉淀和复用团队技能



工欲善其事,必先利其器。——《论语·卫灵公》
一、一个冷汗直冒的下午
老李10年 架构师,手上带着三个项目组,加一起二十多号工程师。
那天下午 Code Review,他打开小王提交的 PR,一个"用户登录"接口,Claude Code 十分钟生成,三百行。
Controller 里查数据库。
UserBo 直接放进了响应 Res。
OrderStatusEnum 堂而皇之挂在 LoginReq 的字段上。
App 里嵌了四层私有方法,进去就出不来。
老李叹了口气。代码没有错——逻辑是通的,功能是好的。
但这不是他们团队的代码。
更让他心沉的不是小王这一个人。是另外两个项目组,同样在用 Claude Code,同样在以各自不同的"随机风格"生成代码。
AI 的速度,在放大每个人的不同习惯,把团队风格炸得七零八落。
这不是工具问题。这是经验没有被固化的问题。
二、为什么有规范还是没用
善弈者谋势,不善弈者谋子。——《弈理》
老李在职场做了这么多年,见过太多这样的循环:
第一步:老李写了一份 Wiki 规范文档,洋洋洒洒八千字。
第二步:新人入职,HR 发链接,"这是我们的规范,请阅读"。
第三步:新人读了,觉得明白了,然后写出来的代码还是老样子。
第四步:Code Review 打回,新人改,老李解释,来回三轮。
第五步:两周后,老李发现另一个老员工也没遵守规范。
第六步:规范文档更新了,但没人知道更新了。
Wiki 传递不了判断力,只传递文字。
而 AI IDE 时代,这个问题被放大了十倍——AI 不读 Wiki,AI 只看它能访问的上下文。
你不给 AI 规范,AI 就按"互联网平均水平"生成代码。
而互联网平均水平,就是你最不想要的那种代码。
企业软件系统三大痛点,AI 时代一条都没解决,反而加速了:
痛点 | AI 时代的放大效应 |
|---|---|
Controller 变垃圾桶 | AI 默认把所有逻辑堆在最上层,一次生成,全员复制 |
入参出参边界模糊 | AI 不知道 BO 不能出现在 Res,直接透传 |
业务流程不可读 | AI 没有"两层限制"概念,嵌套到第五层毫不手软 |
三、分层规范全景图
不谋全局者,不足谋一域。——《寤言二迁都建藩议》
老李把团队多年沉淀的规范,整理成了一张清晰的架构图,核心要点如下:
接口触发层同级:controller(HTTP接口)、job(定时任务)、listener(MQ/Redis消息)三者平级,都是"触发入口",不是谁管谁的关系。
para 的边界:
XReq/XRes:
只能在接口触发层使用,禁止出现在 App 层及以下
XBo/XEnum:可以在应用层和业务层流转,禁止暴露到接口层
service 可以调用 manager:service 是本模块的业务能力
manager 是跨模块的复用能力,
service 可以调用 manager,但 manager 不依赖具体 service。
四、金字塔模型:App 层的灵魂
治大国,若烹小鲜。——《道德经》
这是老李最看重的规范,也是最被 AI 破坏的规范。
业界最佳实践(Clean Architecture + DDD Application Layer)对应用层的共识是:一个 Use Case = 一个 Application Service,对外只暴露一个执行入口,内部用语义化私有方法描述业务步骤。
老李把它具体化成"金字塔双层":
以电商"用户下单"为例:
OrderApp.exe(PlaceOrderReq req)
│
├─ 第一层(业务流程,一眼看懂做了什么)
│ ├─ validateStock(req) 校验库存
│ ├─ calculatePrice(req, items) 计算价格(含优惠券)
│ ├─ createOrder(req, price) 创建订单
│ ├─ deductStock(items) 扣减库存
│ └─ sendOrderNotice(order) 发送通知
│
└─ 第二层(每个步骤的细节实现)
├─ validateStock 内部:查缓存→查DB→比较库存数
├─ calculatePrice 内部:查商品价→应用优惠规则→汇总
└─ ...(每个方法独立实现,不再有第三层调用链)
为什么这么设计?
读 exe() 就像读一份业务说明书:
校验库存 → 算价格 → 建订单 → 扣库存 → 发通知。
不用进每个方法,业务全程一览无余。
这不只是为了人阅读——这也是 AI 最喜欢的结构。扁平、语义化、两层到头,AI 生成后续代码时不会迷失在调用链里。
五、把规范变成 Skill的完整步骤
授人以鱼,不如授人以渔。——《淮南子》
老李做了一件事,把规范"装"进了 AI 的大脑——写成了 SKILL.md。
Skill 是什么?
一个带有 YAML 元数据头的 Markdown 文件,放在 AI IDE 能自动发现的位置。
AI 在接到相关任务时,自动加载并遵循其中的规范。这不是 prompt,是持久化的规范记忆。
步骤一:创建 SKILL.md
java-layered-arch/
├── SKILL.md ← 核心规范文件
└── references/
└── examples.md ← 可选:代码示例(避免 SKILL.md 过长)
SKILL.md 结构(基于官方规范):
---
name: java-layered-arch
description: >
Java企业分层架构代码生成规范。当用户要求生成Java接口、
Controller/App/Service/Mapper代码时触发。
触发词:生成Java代码、写接口、按分层规范、写Controller、
写Service、写Mapper、接口入参出参、BO对象、枚举定义。
---
# Java 分层规范
[规范内容...]
关键:
description字段最多200字,必须包含触发词,AI 靠它决定何时加载此 Skill。
步骤二:在 Claude Code 中安装使用
① 项目级安装(推荐,随Git版本管理)
cd your-project-root
mkdir -p .claude/skills/java-layered-arch
# 将 SKILL.md 放入该目录
cp /path/to/java-layered-arch/SKILL.md .claude/skills/java-layered-arch/
② 提交到 Git(团队所有成员克隆后自动生效)
git add .claude/skills/
git commit -m "feat: add java-layered-arch skill for AI code generation"
git push
③ 启动 Claude Code
claude # 在项目目录下启动
④ 验证 Skill 已加载
# 在 Claude Code 会话中输入:
/skills
# 应看到 java-layered-arch 出现在列表中
⑤ 使用(自动触发 或 显式调用)
# 自动触发:直接描述需求
# "按分层规范,生成用户登录接口的完整代码,模块名 user,表名 t_user"
# 显式调用:
# $java-layered-arch 生成订单创建接口
注意:Skill 文件的实时变更检测已支持,编辑 SKILL.md 后无需重启 Claude Code 即可生效。
步骤三:在 Codex 中安装使用
Codex 从 .agents/skills 目录(从当前工作目录向上扫描到仓库根)加载 Skill,同时支持全局个人 Skill:
① 项目级(团队共享,推荐)
mkdir -p .agents/skills/java-layered-arch
cp SKILL.md .agents/skills/java-layered-arch/
git add .agents/ && git commit -m "add codex skill"
② 个人全局级(跨项目)
mkdir -p $HOME/.agents/skills/java-layered-arch
cp SKILL.md $HOME/.agents/skills/java-layered-arch/
③ 补充 AGENTS.md(项目级规范文件,Codex 自动读取)
cat >> AGENTS.md << 'EOF'
## 代码规范
遵循 java-layered-arch Skill 的分层规范。
生成 Java 代码时,必须按 controller/app/service/mapper 分层。
EOF
④ 启动 Codex 并验证
codex
# 会话中输入:
/skills # 确认列表中有 java-layered-arch
⑤ 使用
# 自动触发(描述任务)或显式调用:
# $java-layered-arch 生成商品查询接口
Codex 的 personal skills 存储在
$HOME/.agents/skills,团队共享 skills 可以检入.agents/skills仓库目录,特别有助于新成员 onboarding。
步骤四:团队提示词模板(可直接用)
配合 Skill 使用的标准任务描述模板:
使用 $java-layer-arch,帮我设计一个订单新接口,按分层规范输出目录、类名和代码骨架。
使用 $java-layer-arch,重构这个遗留 controller,要求先不改行为,只做分层收敛。
Skill 步骤小结
步骤 | 操作 | 验证方式 |
|---|---|---|
写 SKILL.md | 规范内容 + 触发词描述 | 检查 description ≤200字,name唯一 |
Claude Code 安装 | 放入 .claude/skills/ 目录 | /skills 列表中可见 |
Codex 安装 | 放入 .agents/skills/ 目录 | /skills 列表中可见 |
Git 共享 | git commit 推送 | 新成员克隆即可用 |
验证效果 | 生成一个接口,对照检查清单 | 无层级违规即成功 |
六、三条洞见:从 AI 工具使用者到 AI 超级个体
君子不器。——《论语·为政》
洞见一:规范即资产,沉淀即复利
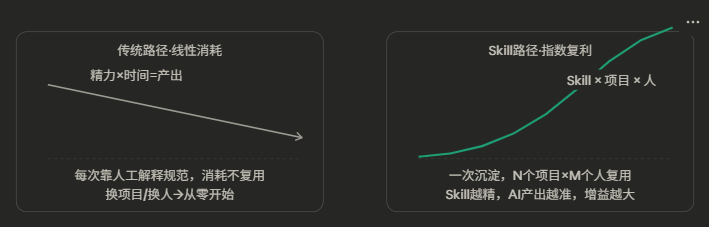
image.png
传统职场,你的经验只能靠"一对一传授"线性扩散。老李带一个新人,花两周,带十个人,花二十周。Skill 把这件事变成指数扩散:一次把规范写进 SKILL.md,注入 AI,所有人所有项目同时继承。你的经验,第一次可以并行复用。
洞见二:金字塔双层是 AI 时代的"可读代码"最低标准
以前代码只给人读,靠注释凑合。现在代码也给 AI 读,AI 要理解上下文才能生成正确的后续代码。三层以上的嵌套,AI 无法判断下一步方法属于哪层,生成结果随机落层。金字塔双层是人类可读性和 AI 可理解性的最大公约数。
洞见三:AI 超级个体的本质,是把隐性经验显性化的能力
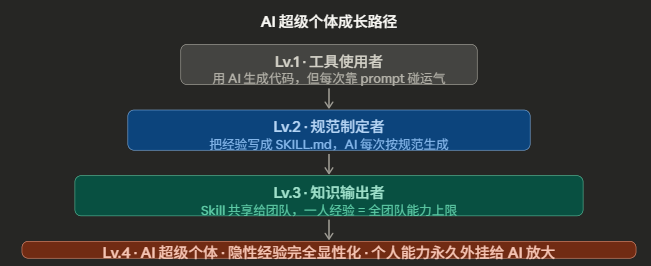
image.png
每一个职场人都有自己的"隐性经验"——那些没写下来但确实影响判断的东西。AI 时代最大的职业分化,不是会不会用 AI,而是能不能把自己的隐性经验显性化,装进 AI 的大脑。
Lv.1 的人用 AI,每次 prompt 不同,结果随机。
Lv.4 的人有 Skill,AI 永久携带他的经验标准,每次生成都是他审查过的质量。
这才是 AI 超级个体的真正含义:你的经验,第一次可以不依赖你在场就发挥作用。
七、你的职业经验值得被更好地传承
不积跬步,无以至千里。——《荀子·劝学》
老李做了这件事之后,项目组发生了三个变化:
1.新人入职第一天,克隆代码,Skill 自动加载,第一个 PR 的分层就是对的。
2.Code Review 的时间从"讲规范"变成了"讲业务"。
3.老李自己,终于可以把时间花在真正的架构决策上,而不是反复解释"BO 不能放进 Res"。
现在轮到你了。
你职业生涯里积累的那些判断——哪些操作是对的,哪些坑绝对不能踩——它们现在只活在你的脑子里。每次换项目、换团队、来新同事,就要重新传授一遍。
把它们写进 SKILL.md。一次,永久。
行动方法论:30 分钟开始你的第一个 Skill
写下你团队最重要的一条规范,哪怕只有 20 行AI 不是让你失业的工具,是让你的经验第一次摆脱了时间和空间的限制。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号