创痛与蜕变:一个标书系统架构师的轻量化心路


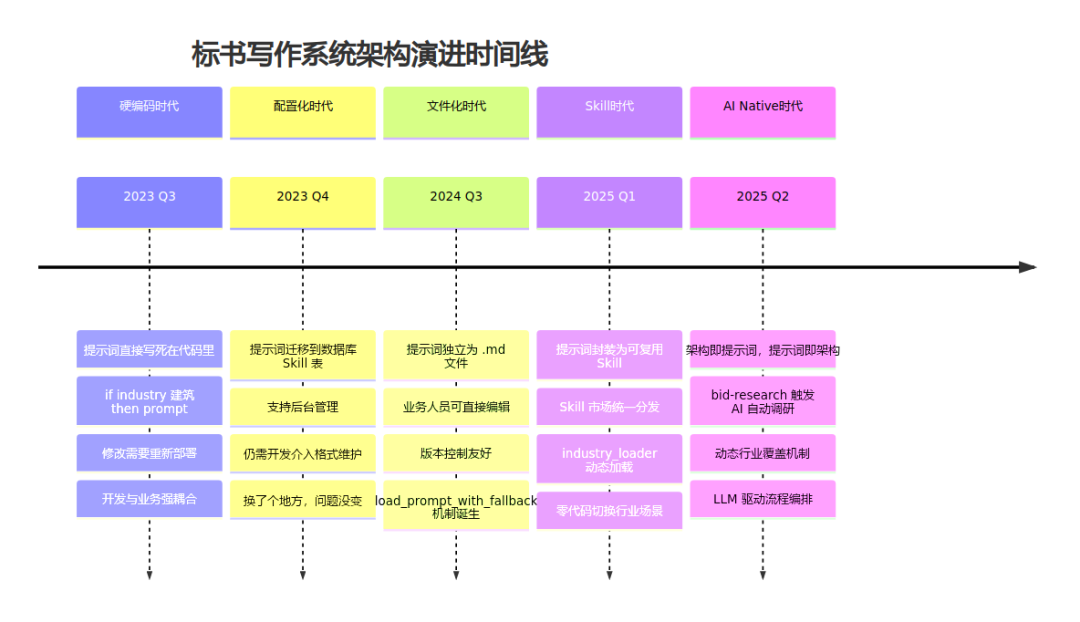
标书写作系统架构演进时间线
标书写作系统架构演进时间线
2023年的硬编码时代,到2025年的 AI Native 时代——每一步都是被痛逼出来的。
序:那个让我睡不着觉的夜晚
那是 2023 年深冬的某个凌晨两点。
我坐在电脑前,盯着一个 PR Review。需求很简单:产品说,医疗行业的客户反映,标书里的"技术方案"章节太泛,能不能加一些医疗信息化的专业术语?
我去翻代码。找了二十分钟,在 prompt_templates.py 的第 412 行,找到了那个字符串:
SECTION_CONTENT_SYSTEM_PROMPT = """
你是一位专业的标书写作专家...
请生成符合要求的技术方案章节...
"""我当时的第一反应,不是"我要改这里",而是一种说不清楚的恶心感。
这行代码,是我自己写的。
那一刻我意识到:我已经亲手建造了一个监狱,然后把自己关了进去。不是代码的监狱,是思维方式的监狱。
一、创痛的起点:我们是怎么走进这个坑的
每一个"烂"架构,都有一个当时"完全合理"的起点。
2023 年我们决定做这个智能标书系统。技术选型很现代:Python 3.11 + FastAPI + React 18 + PostgreSQL。AI 调用用 OpenAI API。这套组合,放在当时完全是主流的、合理的选择。
问题出在提示词上。
最初我的想法很简单:提示词就是个字符串,放在代码里最方便,直接用就行。于是 prompt_templates.py 诞生了。一个文件,放所有提示词。
第一个月:这个文件有 100 行,清晰整洁。
第三个月:膨胀到 400 行,开始有人不知道该在哪里加新提示词。
第六个月:800 行,五个人在同一个文件里改代码,merge conflict 成了家常便饭。
我们为什么走进了这个坑?
不是因为我们不懂架构。而是因为我们用工程师的视角处理了一个本质上不同的问题。
提示词不是代码。代码是确定的逻辑,提示词是对话语言。代码改动需要经过严格的代码审查,提示词的调整应该像配置文件一样随时可改。我用对待代码的方式对待了提示词,这是根本性的认知错误。
传统重量级 vs AI Native 轻量化:一眼看清架构差距
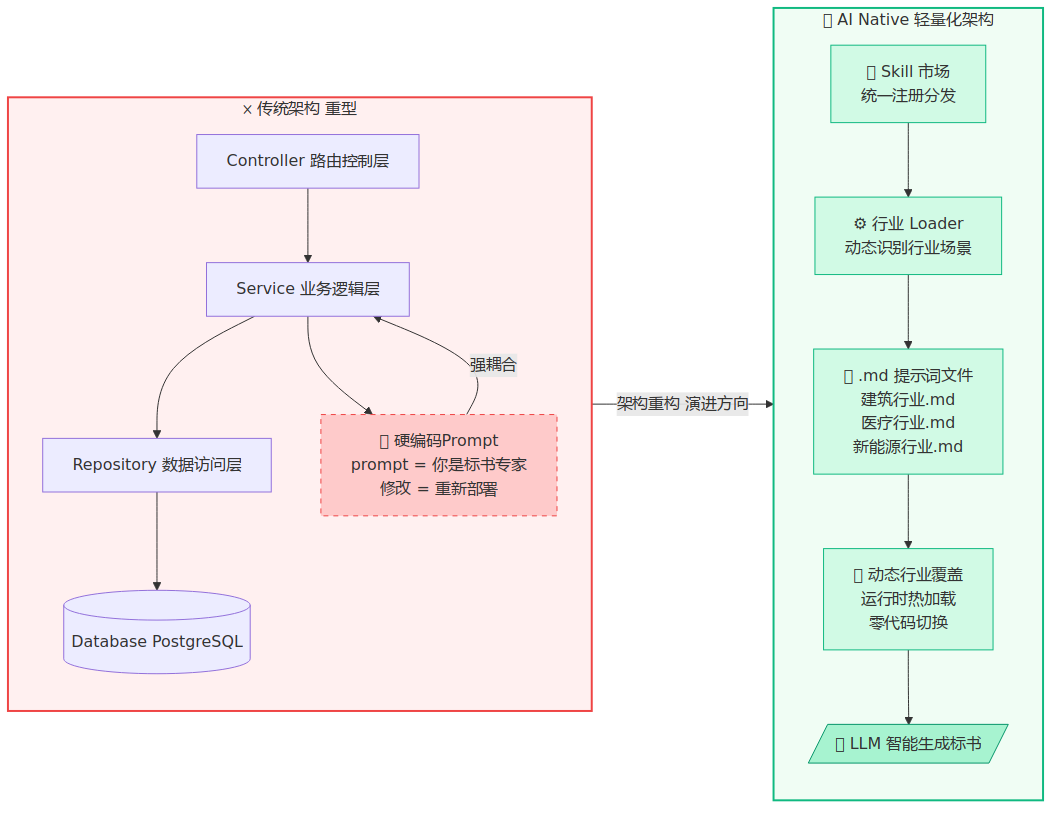
传统架构 vs AI Native 轻量化架构对比
传统架构 vs AI Native 轻量化架构对比
左边是我们起点的样子,右边是我们现在的样子。两张图之间,隔着将近两年的纠结、返工和自我否定。
二、重量的感知:架构的重量压垮的不是服务器,是迭代速度
"架构太重"这件事,很少在某一天突然爆发。它是慢性病,用三四个月的时间,把你的迭代速度从"每周上线新功能"拖成"改一行提示词要走三个工作日审批流程"。
第一个症状出现在某个周五下午。产品经理走到我工位旁边说:"能不能把建筑行业的提示词稍微调一下?用户反馈机电工程的描述太机械了。"
我当时的表情大概很难看,因为我内心的第一反应是:"你知道改这个要动多少地方吗?"
我要找到 SECTION_CONTENT_SYSTEM_PROMPT,确认它在所有调用路径中的影响,写测试,走 review,部署,回归测试。整个流程最快两天。
产品经理需要的是半小时内看到效果。
这种错配,才是"架构太重"的真实感受。不是性能慢,不是功能缺失,而是人与系统之间的摩擦系数太高。
三、最深的纠结:我知道答案,但我迟迟不敢动
这是我想重点写的部分,因为我看到太多架构师在这里卡住。
知道怎么做,但就是不做。
架构师内心的决策纠结树

架构师内心决策树:每条虚线都是忍无可忍后的妥协
架构师内心决策树:每条虚线都是忍无可忍后的妥协
这张图里每一条虚线箭头,都是"忍无可忍"之后的妥协。你会发现,每一次演进,都不是主动的技术选择,而是被痛逼出来的。
2024 年初,我其实已经知道解法了:提示词应该文件化,变成 .md 文件,用一个加载器按需读取。这样产品经理可以直接编辑文件,工程师不需要介入。
但我没动。整整两个季度,我知道答案,我没动。
第一层纠结:破坏稳定性的恐惧
"现在这套虽然丑,但它跑着呢。" 这是工程师的本能防御:在不完全理解系统的情况下,不要动正在跑的东西。这个本能是对的,但被我用来合理化拖延。
第二层纠结:性价比的算计
把所有提示词文件化,大概需要 2 周时间。但这 2 周产出的是"基础设施",没有新功能,对外没有任何用户可见的价值。在一个"功能驱动"的业务节奏里,这 2 周怎么说服老板?
第三层纠结,也是最深的那层:对自己的怀疑
"也许是我想多了?也许硬编码在这个规模下完全可以接受?也许我只是强迫症?"
这种自我怀疑,是架构师最危险的陷阱。它让你把"技术判断"和"个人偏好"混淆,让你无法区分"这是工程债"和"这是我的洁癖"。
最终推动我动手的,不是技术洞察,而是需求的压迫: 我们要支持四个垂直行业——建筑、医疗、软件、新能源。如果继续硬编码,我需要写四个 if-elif 分支,一个 3000 行的 prompt_templates.py。
光是想象那个场景,我的手就抖了。
四、抛弃的过程:痛苦、怀念,然后释然
真正开始动手的那天,我制定了一个原则:最小破坏原则。
不是全量替换,而是:
- 1. 先写
load_prompt_with_fallback(name, fallback)函数 - 2. 逐个函数改造:如果
.md文件存在就读文件,否则 fallback 到原来的 inline 字符串 - 3. 原来的字符串保留,作为兜底,不删除
三层 fallback 机制,层层托底:
优先级 | 数据来源 | 语义 |
|---|---|---|
第一层(最高) | 行业专属 .md 文件 | 已针对该行业深度定制 |
第二层 | 通用 .md 文件 | 文件化通用版,产品可随时编辑 |
第三层(兜底) | inline 字符串 | 文件缺失时确保系统永不崩溃 |
这个设计让我可以一个提示词一个提示词地迁移,随时可以停下来,不会造成全量影响。
抛弃那些字符串,比我想象中更让我不舍。
不是因为代码写得好。而是因为每一行提示词的背后,都有一段记忆:这段是第一次客户演示前一晚熬夜调的,那段是某个 case 跑错了三次才调对的,还有一段是从一个做过 10 年标书的老师那里抄来的经验。
后来我才明白:这种"不舍"本身,就是架构病。提示词被混进代码里的亲密感,恰好说明了边界的模糊。让它离开代码,才是还给它真正的位置。
五、行业感知的诞生:从"一套提示词打天下"到"行业智能路由"
文件化之后,第二层演进很自然地来了。
industry_loader.py 诞生了。它的逻辑极其简单,但影响深远:
三层行业感知路由:
- 1. SkillExecutor 执行时获取
industry_key(如medical/energy) - 2. 查询
industry_configs表的prompt_overridesJSONB 字段 - 3. 按优先级返回:行业专属版 → 通用文件版 → inline 兜底版
- 4. 将行业专属 system prompt 注入 LLM 调用的消息历史首条
核心价值:上下文的彻底切换
同一个标书系统,用医疗行业视角写出来的内容,和用新能源视角写出来的内容,从专业术语到论证逻辑,都是完全不同的:
医疗行业:HIS / EMR / 互联互通 / 等保三级 / 电子病历评级 新能源:并网规范 / 储能系统 / 光伏组件效率 / IRR / LCOE
这不是"改几个词",这是整个认知框架的切换。industry_loader 让这件事变得优雅。
六、Skill 市场:当架构开始自我生长
这是让我最感到震撼的一步,不是因为技术复杂,而是因为它改变了架构演进的主体。
在这之前,架构演进的主体是我——一个工程师,用技术判断驱动改变。
在 Skill 市场化之后,架构演进的部分主体变成了 AI。
人工驱动 vs AI 驱动:
阶段 | 流程 | 人工介入 |
|---|---|---|
人工驱动 | 发现问题 → 手写提示词 → 代码审查 → 部署 | 每个环节 |
AI 驱动 | /bid-research → AI 调研 → AI 生成 Skill → 自动写入 → 重启生效 | 仅定义框架 |
我第一次意识到这个循环的时候,站在那里愣了几秒钟。
当系统可以扩展自己的能力时,架构师的角色是什么?
答案我想了很久:架构师从"建造者"变成了"边界定义者"。不再是每一块砖都亲手砌,而是定义什么能建、怎么建、建到哪里停。
这个转变,比任何一次代码重构都更深刻。
七、轻量化的本质:我最终想明白的事
经历了这一切,我得出了一个也许有些反直觉的结论:
轻量化不是减少代码,而是减少摩擦。
真正的轻量化,是系统中每一个参与方的摩擦系数降低:
- • 产品经理想改提示词 → 编辑一个
.md文件,不需要找工程师 - • 工程师想加一个行业 → 写一个 Skill,不需要改核心代码
- • 业务想覆盖某行业写作风格 → 在
industry_configs表里加一条记录,不需要重新部署 - • 架构师想了解一个新行业 → 运行
/bid-research <行业>,不需要人工调研
每一层的"不需要介入",才是轻量化的真实含义。
但轻量化也有边界:
应该外置(变化频繁) | 应该保留(相对稳定) |
|---|---|
提示词内容 | 系统调用链 |
行业专属配置 | 错误处理逻辑 |
评分关键词 | LLM API 封装 |
Skill 的分类标签 | 数据库 Schema |
过早抽象和过晚重构,是架构师最常掉进去的两个洞。
八、清醒的认知:现在的架构,5年后会被推翻吗?
会。
我对此没有任何怀疑。
现在的架构,带着下一次演进的伏笔:
伏笔 1:Skill 的 prompt 还是字符串 随着 Skill 从 17 个增长到 170 个,会变成新的"prompt_templates.py 问题"。
伏笔 2:行业配置还在数据库里 当行业增多,配置复杂度提升后,可能需要演进为 Git 管理的 YAML 文件或独立配置服务。
伏笔 3:AI 调研的质量还不稳定
/bid-research 生成的 Skill 质量参差不齐,自动化 pipeline 本身又引入新的复杂度。
这些伏笔,我看得清楚。我选择先不动它们。
架构决策永远是一个时间维度的性价比判断,而不是追求永恒正确的理论体操。
后记:写给还在纠结的你
如果你现在正盯着一段你自己写的、让你夜不能寐的代码,我想对你说:
那种恶心感,是对的。 它说明你成长了,你的审美超越了你的代码。
但不要因为恶心就立刻全量重构。 找到那个"最小破坏"的切入点,留好 fallback,一点一点地还债。
每次演进都意味着抛弃。 你要抛弃的,不只是旧代码,还有对旧代码的感情、对当时的自己的辩护、对"我已经想清楚了"的幻觉。
轻量化没有终点。 你现在觉得轻的架构,五年后会变重。不是你做错了,是业务长大了,是技术迭代了,是认知提升了。
这才是架构演进的真相:
它不是一个从"错"到"对"的线性旅程,而是一个在每个时刻都做出当下最好的选择的螺旋上升。
写于 2026 年春,某个又一次推翻自己的深夜。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号