深度解析Skills:从Prompt到能力复用的技术革命

深度解析Skills:从Prompt到能力复用的技术革命

用户9574405
发布于 2026-04-14 15:46:43
发布于 2026-04-14 15:46:43
本文字数:4496 字,阅读约需 15 分钟。
从Prompt到Skills的转变
2023年到2024年是"Prompt工程"的黄金时期。到了2025年底,AI圈开始频繁讨论一个新概念——Skills(技能)。
GitHub上Skills相关仓库获得上万star,各行各业的专业人士开始分享自己封装的Skills。Skills到底是什么?它为什么能引发如此关注?
Skills的本质:模块化能力包
Agent Skills是模块化的能力包,包含指令、元数据和可选资源(脚本、模板),让AI Agent在需要时自动加载和使用。
Skills就像AI助手的"工作手册库"。它不是每次对话都要重新输入的临时指令,而是一套可以长期保存、随时调用的能力模块。
从"带新人"到"给手册"
要理解Skills,先看传统AI交互的问题。
想象你在公司带一个新人。他聪明、理解能力强,但不熟悉规矩。
- Prompt方式就像你每次都口头交代任务:"今天写一段公众号开头"、"把这个语气改得更克制"、"按我的结构写一页PPT"。这适合一次性指令,但一旦关闭对话,所有指令就消失,下次得从头教。
- Rules或记忆机制相当于在工位贴一张"公司行为守则",只能管态度和格式这类宽泛要求。
- MCP和工具调用更像是给他的电脑装一堆软件和API,他能调用外部工具,但不知道什么时候该用、怎么组合。
Skills改变了这一局面。它就像给新人一本完整的公司内部SOP手册——不是长到让人窒息的Word文档,而是一个知识库文件夹,里面有规范、脚本、模板、参考资料。AI会在需要时自己翻阅,按需加载。
Skills的物理形态
很多人问:"这不就是Prompt吗?"实际上两者在形态上有本质区别:
- Prompt:一段文本(通常是Markdown格式)。
- Skills:一个文件夹结构,包含多种资源。
一个标准的Skill目录:
skill-name/
├── SKILL.md # 核心指令文件(必需)
├── scripts/ # 可执行脚本(可选)
├── references/ # 参考文档(可选)
├── templates/ # 模板文件(可选)
└── assets/ # 其他资源(可选)
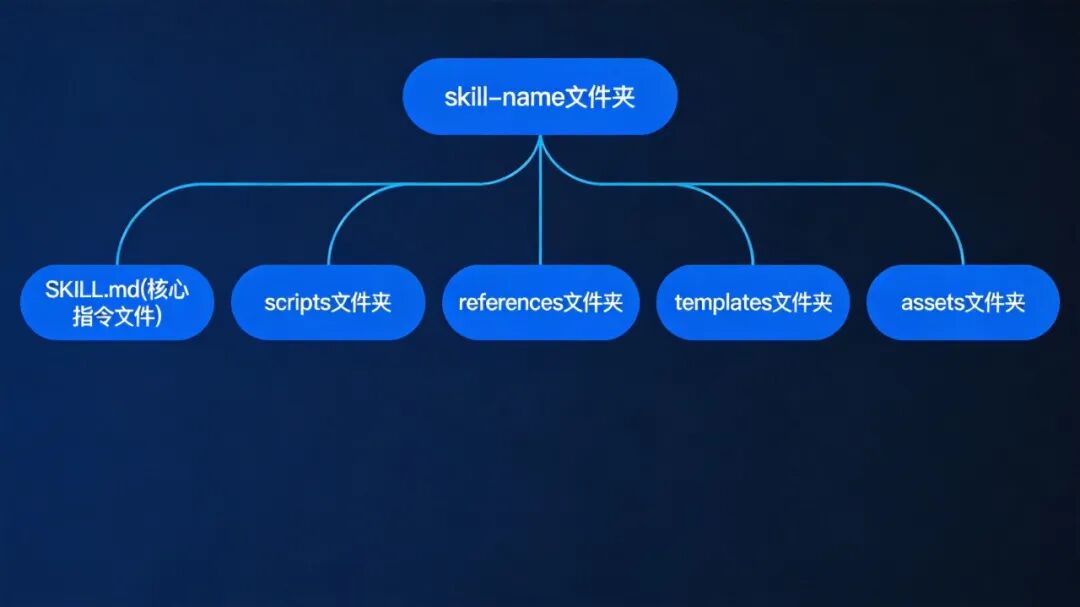
Skills标准目录结构
Skills标准目录结构
SKILL.md是唯一必需的文件,它采用YAML前导格式(类似简历开头的个人信息区),包含元数据和详细指令。这种设计让Skills不仅能承载知识,还能承载工具和流程。
渐进式披露架构
为什么"一次性塞进所有信息"行不通?
Skills采用了渐进式披露(Progressive Disclosure)架构。这个概念在移动互联网时代曾是用户体验设计的核心原则之一。
打开一个APP,如果它一次性把所有功能、设置、选项都堆在你面前,你会怎样?认知负荷爆炸,不知所措。
人的瞬时记忆区非常有限,一瞬间只能接受最多7±2个信息块。AI也是如此——受限于Token窗口,对话越长,模型越"笨"。Token在Agent架构上寸土寸金。
传统做法:每次对话都把完整指令塞进上下文。一个详细的PDF处理工作流可能需要3000+ tokens。如果同时处理Excel、写代码、生成报告,上下文窗口很快爆满。
三层加载机制
Skills通过三层渐进式加载解决这个问题:
第一层:元数据——目录索引
这是Skills的"封面",包含技能名称和一句话描述。
- 加载时机:每次对话开始时。
- Token消耗:约100 tokens/Skill。
- 作用:让AI知道有哪些Skills可用,何时该用。
你可以安装数十个Skills,几乎没有性能损失。AI就像看图书馆的目录,知道有哪些书,但不必都翻开。
第二层:指令——详细手册
当AI通过元数据判断某个任务需要特定Skill时,它会读取完整的SKILL.md文件。
- 加载时机:任务匹配时触发。
- Token消耗:数千tokens(按实际文件大小)。
- 作用:提供详细的操作指南和最佳实践。
用户说"帮我处理这个PDF",AI会判断匹配PDF Skill,然后加载详细的处理流程:先提取文本,再识别表单字段,最后填写并保存。
第三层:资源和代码——深度参考
这层包括参考文档、可执行脚本、模板文件等。
- 加载时机:SKILL.md中引用时。
- Token消耗:按需加载。
- 关键优势:脚本执行不消耗上下文(仅结果消耗)。
一个包含复杂Python脚本的Skill,脚本本身的代码不会进入上下文,只有执行结果会返回。这让Skills可以承载几乎无限的资源,而不必担心Token限制。

Skills三层渐进式加载架构
Skills三层渐进式加载架构
一个真实的加载流程
以PDF处理为例,看Skills如何工作:
阶段1:初始状态
用户输入:"用PDF技能填写这份合同"
系统提示 + 技能目录 + 用户消息
Token消耗:约100 tokens
阶段2:加载主手册
AI判断:这个任务匹配PDF Skill
执行:bash cat ~/.claude/skills/pdf/SKILL.md
Token消耗:+3000 tokens
阶段3:按需加载参考资料
AI判断:需要表单填写规则
执行:bash cat ~/.claude/skills/pdf/references/forms.md
Token消耗:+500 tokens
阶段4:执行脚本
执行:python scripts/fill_form.py --input contract.pdf --output filled.pdf
Token消耗:+200 tokens(仅输出结果)
总Token消耗:约3800 tokens。
对比传统方式:一次性加载所有相关文档和脚本定义,可能需要10,000+ tokens。Skills节省了60-70%的上下文空间。
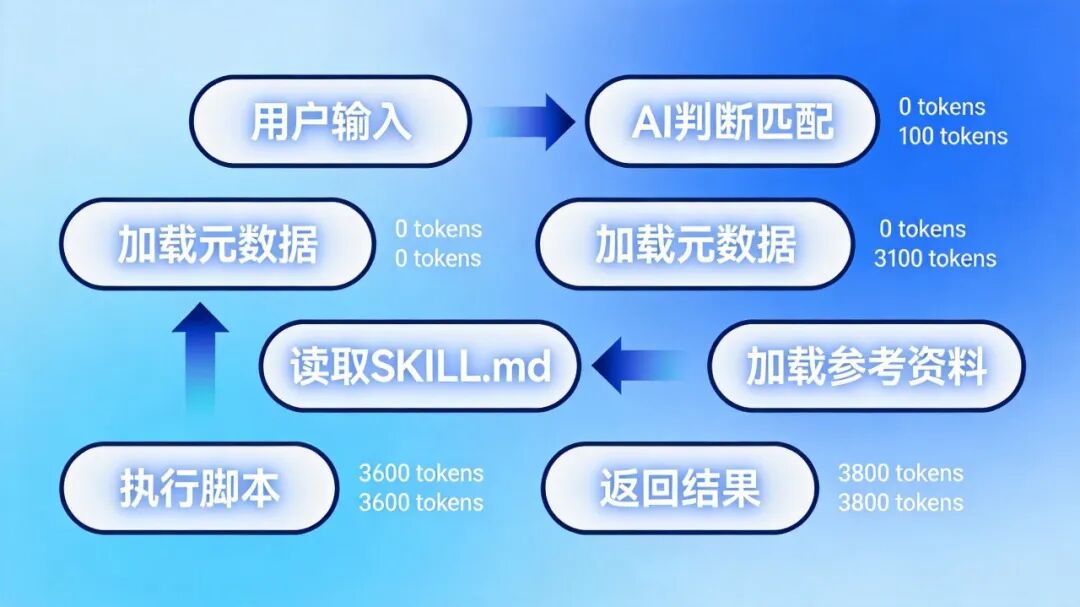
Skills加载流程示意图
Skills加载流程示意图
Skills vs MCP vs Prompt:互补关系
三者的核心定位
Skills、MCP、Prompt不是竞争关系,而是互补关系:
维度 | Skills | MCP | Prompt |
|---|---|---|---|
核心定位 | 工作流程指南(How) | 外部系统连接(What) | 临时指令 |
解决问题 | 如何使用能力 | 提供什么数据/能力 | 当下做什么 |
形象比喻 | 使用说明书 | 工具箱 | 口头指令 |
Token效率 | 高(渐进加载) | 低(全量加载) | 中(每次重复) |
复用性 | 强(文件系统) | 中(协议层面) | 弱(手动复制) |

Skills vs MCP vs Prompt对比图
Skills vs MCP vs Prompt对比图
Skills与MCP:工作手册 vs 门禁卡
Skills解决"怎么做"(方法论/工作流),MCP解决"连到哪儿"(连接外部系统)。
用职场类比:
- MCP:给AI一张门禁卡,让它能进入公司的各个系统(数据库、API、外部工具)。
- Skills:给AI一本工作手册,教它如何使用这些系统完成具体任务。
一个组合场景:
生成销售报告
- MCP提供数据连接
- 连接Salesforce获取客户数据。
- 连接PostgreSQL查询销售记录。
- 连接Google Sheets读取目标数据。
- Skills提供工作流程
- 数据提取顺序(先查哪个系统)。
- 计算逻辑(增长率、完成率)。
- 报告格式和模板。
- 异常处理规则。
MCP解决"能访问什么数据",Skills解决"如何使用这些数据生成报告"。
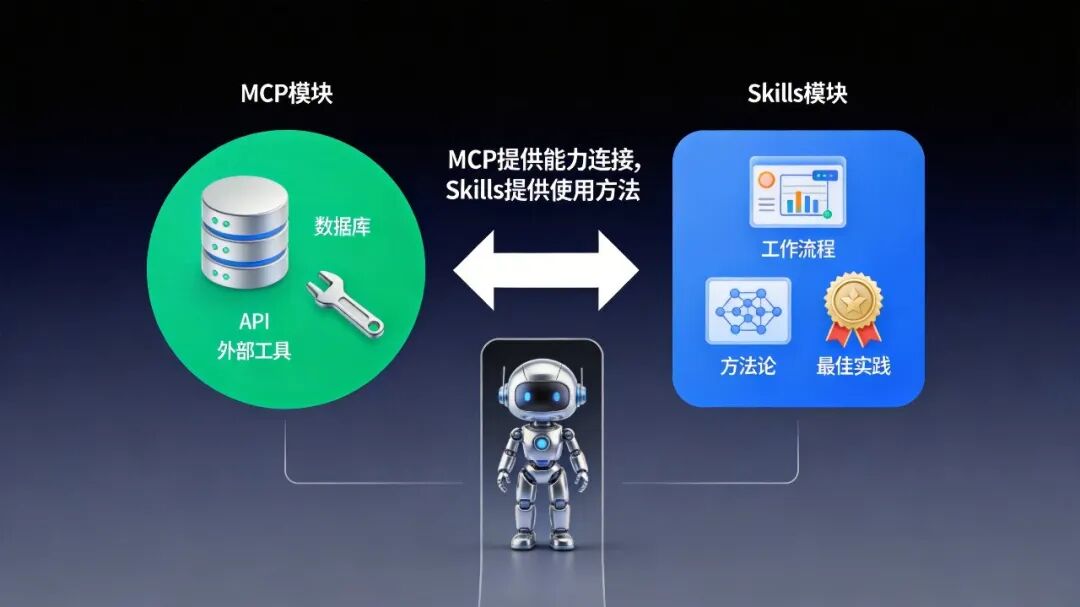
Skills与MCP协作关系
Skills与MCP协作关系
Skills vs Prompt:从临时指令到持久能力
Skills不就是高级一点的Prompt吗?
答案既是肯定的,也是否定的。
相同点:Skills的核心确实是自然语言指令,这与Prompt一致。
根本区别:
- 生命周期:Prompt是对话级的,Skills是系统级的。
- 复用方式:Prompt需要手动复制粘贴,Skills自动匹配触发。
- 承载能力:Prompt只能承载文本,Skills可以承载脚本、模板、参考文档。
- Token效率:Prompt每次都全量加载,Skills按需渐进加载。
用一个实际例子:
没有Skills时,每次都要说:
帮我总结这篇文章 → 翻译成英文 → 改成公众号风格 → 加标题 → 输出Markdown格式
有了Skills后,只需要一句:
使用「技术文章转公众号」Skill
AI会自动按照预设的完整流程执行。
实际应用
个人场景:把重复工作封装成能力包
案例1:AI选题系统
一个内容团队用Skills构建了自动化选题系统,包含:
- 1个总控Agent。
- 3个Skill(热点采集、选题生成、选题审核)。
每天只需要一句:"开始今日选题生成",系统就会自动:
- 从多个平台采集全网热点。
- 筛选并生成TOP10选题(包含事件描述、核心角度、标题)。
- 按照内部方法论自动审核。
- 不通过时给出修改意见并迭代优化。
过去需要2-3小时的工作,现在几分钟就能完成初筛。
案例2:整合包生成器
很多GitHub开源项目没有前端界面,环境配置复杂。有人用Skills做了一个"整合包生成器":
提供一个GitHub链接,Skill就会:
- 分析项目结构。
- 自动生成前端界面。
- 编写启动脚本。
- 打包成开箱即用的整合包。
解决了"想用但不会配置"的痛点。
团队场景:知识资产沉淀与共享
传统方式的问题:
- 每个团队各自维护长Prompt。
- 写法、风格不统一。
- 复用靠复制粘贴。
- 难以版本管理和评审。
Skills带来的改变:
- 把"怎么做好一件事"固化成SKILL.md + 脚本 + 参考文档。
- 放入Git版本库,走标准开发流程。
- 团队间共享、评审、复用。
- 形成企业内部的"技能库"(Skill Library)。
组织架构示例:
公司级Agent产品
├── 市场部维护:品牌文案Skill
├── 法务部维护:合同审阅Skill
├── 财务部维护:报销审核Skill
└── 技术部维护:代码审查Skill
所有技能装在同一个Agent身上,用户只跟一个界面打交道。
行业场景:专业知识标准化
医疗诊断流程:将诊断标准、注意事项、药物禁忌等封装成Skill,确保AI遵循医疗规范
法律文书审查:将审查要点、风险识别、合规要求标准化,提高审查质量和一致性
代码审计规范:将安全检查项、代码风格要求、最佳实践固化
ML实验配置:将实验设计规范、参数推荐范围、结果记录模板封装
这些领域知识需要结构化存储、团队共享、版本管理、跨平台使用——正是Skills的强项。
技术实现
最小可行Skill
创建一个Skill只需要一个SKILL.md文件:
---
name: hello-skill
description: A simple skill that greets users
---
# Hello Skill
When user says hello, respond with a friendly greeting.
必填字段:
name:技能名称(小写字母、数字、连字符符)。description:功能描述。
简单到人人可创建,强大到专业团队可用。
完整Skill:PDF处理案例
pdf-skill/
├── SKILL.md
├── scripts/
│ ├── extract_text.py
│ ├── fill_form.py
│ └── merge_pdfs.py
├── references/
│ ├── FORMS.md
│ └── API_REFERENCE.md
└── templates/
└── report_template.md
SKILL.md内容:
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs.
---
# PDF Processing
## Quick Start
1. For text extraction, use `python {baseDir}/scripts/extract_text.py`
2. For form filling, see [FORMS.md](references/FORMS.md)
3. For merging PDFs, execute the merge script
## Supported Operations
- Text extraction from text-based PDFs
- OCR for scanned PDFs (requires Tesseract)
- Form field identification and filling
- Multi-document merging
## Best Practices
- Always validate PDF integrity before processing
- Use OCR only when necessary (higher token cost)
- Keep extracted text under 10,000 tokens for best performance
关键点:
{baseDir}是自动替换变量,表示Skill的安装路径。- 可以引用其他文件(如FORMS.md),AI会在需要时加载。
- 指令清晰、结构化,便于AI理解和执行。
安装和使用
方法1:命令安装
# 安装官方Skill
claude skill install https://github.com/anthropics/skills/tree/main/skills/pdf
# 或在对话中直接说
"安装这个skill:https://github.com/xxx/skill-name"
方法2:手动放置
将Skill文件夹放到对应目录:
- Claude Code:
~/.claude/skills/。 - Cursor:
~/.cursor/skills/。 - OpenCode:
~/.config/opencode/skill/。
使用方式:
直接对话:
用户:"帮我处理这个PDF"
AI会自动识别并调用PDF Skill
或者显式指定:
用户:"使用PDF Skill提取这份文档的文本"
未来展望
从工具到生态
目前Skills还处于早期阶段,但已经有了生态雏形:
- 官方Skills库:Anthropic开源了官方Skills仓库,包含PDF、Excel、PPT、Word等常用技能。
- 社区贡献:GitHub上涌现大量社区贡献的Skills,涵盖数据分析、代码审查、文档生成等多个领域。
- 工具支持:Claude Code、Cursor、OpenCode等主流工具均已支持Skills。
- 技能市场:扣子等平台开始提供技能市场,支持搜索、安装、分享Skills。
潜在挑战
Skills也面临挑战:
- 标准化问题:不同平台、不同团队的Skills格式可能不统一,需要建立行业标准。
- 安全与隐私:Skills可以执行脚本,需要沙箱隔离和权限控制。
- 质量参差:开放的生态意味着质量良莠不齐,需要评价和筛选机制。
- 学习曲线:虽然创建简单,但要设计高质量的Skill仍需要经验。
对AI发展的意义
Skills代表一个重要趋势:**从让AI"理解"到让AI"执行"**。
过去几年,我们主要关注如何让AI更好地理解自然语言、理解上下文、理解意图。这是必要的基础,但还不够。
Skills的出现,标志着我们开始关注如何让AI系统地、可重复地、高质量地执行复杂任务。这不仅需要理解能力,还需要方法论、最佳实践、工具链的支持。
这是AI从"对话伙伴"进化为"工作伙伴"的关键一步。
今天就开始你的第一个Skill
Skills的热度已不亚于当年的Prompts。但这不只是流行趋势,而是实实在在的生产力革命。
如果你还在犹豫是否要尝试Skills,建议从最简单的开始:
今天,安装一个官方Skill(比如skill-creator),感受一下"一个命令安装能力"的便捷。
明天,把最常用的一个动作固化成Skill——比如选题筛热点、报错日志分析、链接摘要生成。
后天,你会想把更多工作流程都搬进去。
到那一步,你就进入了另一个状态:自由,创造的状态。
Skills的核心价值,在于复用。当你把一次性的努力转化为可重复调用的能力,你就不再是每次都从零开始,而是站在前人的肩膀上持续前进。
都看到这里了,如果觉得有帮助,还请您给我个小小的鼓励,动动手指,帮忙点个在看或者点个赞👍🏻!谢谢喽!!!
关注我,持续分享后端开发经验!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号