RK3588上111 FPS:轻量YOLOv8+异步视频处理系统实现无人机自主电力巡检
原创
RK3588上111 FPS:轻量YOLOv8+异步视频处理系统实现无人机自主电力巡检
原创
CoovallyAIHub
发布于 2026-04-14 16:18:21
发布于 2026-04-14 16:18:21
导读
无人机电力巡检正在从"按预设航点飞行+离线分析"向"实时检测+自主决策"演进,但边缘端算力始终是瓶颈——RK3588的NPU只有6 TOPS,功耗低至个位数瓦特,如何在这样的硬件上跑出可用的检测帧率?
千叶大学Suzuki团队给出了一套从模型到系统的完整方案:对YOLOv8做 VanillaBlock重参数化+ Slim-Neck+ 结构化剪枝三步改造,剪枝后仅 3.7 GFLOPs、1.92M 参数;再通过自研的DVSPS异步视频处理系统(3核NPU并行 + 多线程调度 + 硬件加速编解码),RK3588三核NPU实测达到111.3 FPS,系统端到端延迟仅 23ms。最终在自建的11451张电力巡检数据集上部署验证,INT8量化后 mAP50达84.2%。更值得关注的是,系统还集成了无需外部航点的塔杆自主定位和导线追踪功能,将检测、导航、决策闭合在一块6 TOPS的板子上。
论文信息
- 标题:A Lightweight Drone Vision System for Autonomous Inspection with Real-Time Processing
- 作者:Zhengran Zhou, Wei Wang, Hao Wu, Tong Wang, Satoshi Suzuki
- 机构:Chiba University, Japan; F-REI Fukushima, Japan
- 期刊:Drones 2026, 10(2), 126
- 发表日期:2026年2月11日
一、6 TOPS边缘板上的实时检测:问题有多难?
电力巡检无人机需要在飞行过程中实时识别铁塔各部件(塔顶、横担、绝缘子、塔身、塔基),同时保持足够的帧率以支撑导航决策。这对机载计算提出了三重约束:
- 算力有限:RK3588集成的NPU为6 TOPS,与桌面GPU(如RTX 4080)相比差距显著
- 功耗严格:作为低功耗嵌入式平台,难以搭载高功耗计算模块
- 实时性要求:视频流处理需要达到接近30 FPS以上才能支撑连续飞行中的检测和导航
论文采用的硬件平台包括:自研四旋翼无人机、SIYI ZR10网络相机(1920×1080分辨率,H.265编码,30fps)和基于RK3588的自研机载计算机,软件栈基于ROS + OpenCV构建。整套系统的目标是在不依赖云端或地面站计算的前提下,完成从视频解码、目标检测到导航决策的全流程。
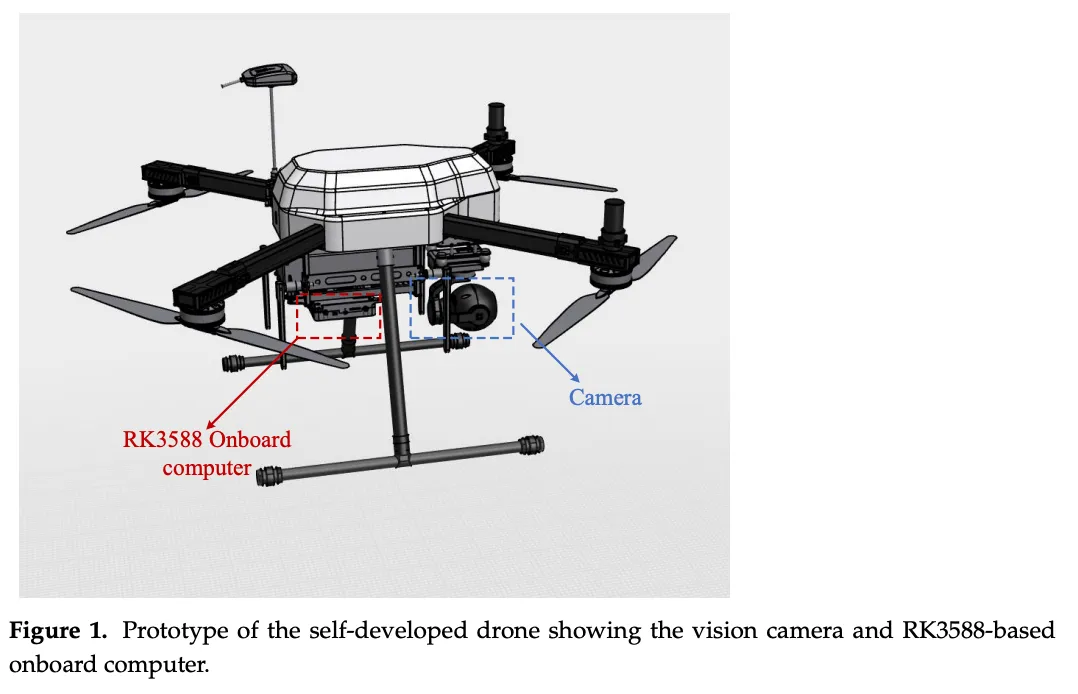
图片来源于原论文
二、三步模型轻量化:VanillaBlock + Slim-Neck + 结构化剪枝
论文基于YOLOv8进行了三个层次的轻量化改造,目标是在压缩计算量的同时保持检测精度。
2.1 VanillaBlock替换C2F(Backbone)
VanillaBlock的核心思路是训练-推理解耦:训练阶段使用堆叠的ReLU激活函数(Stacked ReLU)来增强非线性表达能力;推理阶段通过多步重参数化实现加速——先将BN层参数融合到卷积权重中,再让激活函数退化为线性映射,最后将相邻的线性卷积层合并为单一操作。这样训练时保留了足够的模型容量,推理时又获得了线性操作带来的速度优势。
2.2 Slim-Neck替换Neck中的C2f
在Neck部分,论文用GSConv + VoV-GSCSP替换原有的C2f模块,构建Slim-Neck结构。GSConv将标准卷积与深度可分离卷积混合使用,并引入通道混洗(channel shuffle)操作来增强特征交互,在减少参数量的同时维持特征融合质量。
2.3 结构化剪枝
在模型训练完成后,论文对BN层的缩放因子γ施加L1正则化,然后移除γ值较小的通道,最后通过微调恢复精度。在0.8剪枝率下,最终模型达到mAP50 88.4%、FLOPs 3.7G、参数量1.92M。
数据集与训练配置
论文构建了一个包含11,451张高分辨率图像的电力巡检数据集,覆盖城市和山区两种环境,标注5类目标:Tower Head Assembly(塔头组件)、Concrete Pole Shaft(杆身)、Insulator(绝缘子)、Top Section of the Concrete Pole(杆顶段)、Embedded Section of the Concrete Pole(杆基埋入段),按8:1:1划分为训练集(9,160张)、验证集(1,145张)和测试集(1,146张)。训练在RTX 4080 + i9-14900K上完成,300 epochs,batch size 16,输入分辨率640×640,优化器为AdamW(初始学习率1e-3),部署时通过INT8量化转换到RK3588的RKNN格式。
消融实验:各组件的贡献
论文在COCO val2017上(RTX 4080环境)对Backbone和Head的不同组合做了系统消融:
Backbone | Head | mAP50(%) | mAP50:95(%) | FLOPs(G) | Latency(ms) | P(%) | R(%) |
|---|---|---|---|---|---|---|---|
C2F(BN) | C2F(BN) | 83.0 | 49.1 | 8.2 | 5.0 | 80.9 | 78.2 |
C2F(VanillaBlock) | VoV-GSCSP | 85.5 | 53.0 | 6.1 | 5.4 | 82.3 | 81.1 |
C2F(VanillaBlock) | C2F(VanillaBlock) | 86.7 | 53.6 | 6.1 | 5.5 | 83.7 | 80.8 |
C2F(BN) | VoV-GSCSP | 87.8 | 53.0 | 7.4 | 4.9 | 82.6 | 83.8 |
VanillaBlock | C2F(BN) | 86.2 | 53.9 | 6.8 | 5.1 | 83.6 | 80.7 |
VanillaBlock | VoV-GSCSP | 87.9 | 55.1 | 5.7 | 4.8 | 84.9 | 83.2 |
最优组合为VanillaBlock(Backbone)+ VoV-GSCSP(Head),相比基线C2F(BN)+C2F(BN):
- mAP50提升+4.9%(83.0% → 87.9%)
- FLOPs降低30.5%(8.2G → 5.7G)
- 延迟降低4.0%(5.0ms → 4.8ms)
三、DVSPS:从单帧推理到视频流实时处理
模型本身的推理速度只是问题的一半。在实际的视频流场景中,还需要处理视频解码、色彩空间转换、推理调度、结果编码传输等环节。论文提出的DVSPS(Digital Video Stream Processing System)从系统层面解决这个问题,包含三个核心模块:
3.1 RKNN Pool:3核NPU并行推理
RK3588集成了3个NPU核心,DVSPS通过RKNN Pool实现动态NPU选择和并行推理调度,将3个核心的算力充分利用,而非仅使用单核。
3.2 Thread Pool:异步多线程调度
通过线程池实现视频解码、模型推理、结果传输三个环节的异步解耦。各环节可以并行运行,不需要串行等待,从而隐藏各阶段的延迟。
3.3 Media Transmission:硬件加速编解码
利用RK3588内置的MPP(Media Process Platform)进行硬件加速的视频编解码,以及RGA(Raster Graphic Acceleration)进行色彩空间转换,避免CPU软解码的性能瓶颈。
部署性能
Backbone | Head | 原始大小(MB) | INT8量化(MB) | FPS (GPU) | FPS (NPU单核) | FPS (NPU三核) |
|---|---|---|---|---|---|---|
VanillaBlock | VoV-GSCSP | 4.33 | 3.5 | 159 | 12.5 | 111.3 |
关键数据:
- 经过INT8量化后模型仅3.5 MB
- 单线程处理延迟为192ms,DVSPS异步流水线将其压缩到36ms,实现5.3倍加速
- RK3588三核NPU达到111.3 FPS,远超30fps的实时需求
- 最终系统INT8量化部署后,端到端延迟仅23ms,mAP50为84.2%(mAP50:95为52.5%)。相比剪枝后未量化的88.4%,INT8量化带来约4.2个百分点的精度损失,但换来了显著的推理速度提升和模型体积压缩
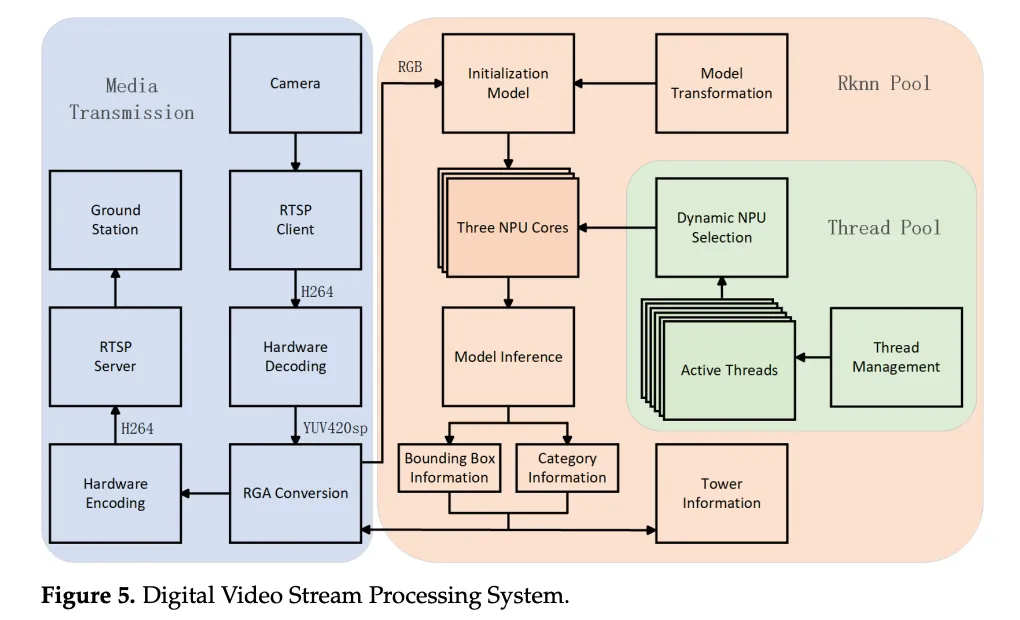
图片来源于原论文
四、自主巡检导航:无需预设航点的塔杆定位与导线追踪
除了检测模型和视频处理系统外,论文还设计了两项自主导航功能,使无人机能够在无需外部航点规划的情况下完成巡检任务。
4.1 塔杆自主定位
基于针孔相机模型,通过多帧图像中塔杆目标的几何关系估计塔杆的空间位置。这种方法不依赖预先标注的GPS航点或三维地图,仅依靠视觉检测结果和相机参数即可完成定位。
4.2 导线追踪
导线追踪流程为:先用线段检测器从图像中提取线段,然后通过K-means聚类找到主导方向,再据此提取航向并进行校正。论文设定的角度阈值δθ为5°,当偏差超过此阈值时触发航向调整。
这两项功能与前述的检测模型和DVSPS系统配合,构成了一条从"看到什么"到"往哪里飞"的完整闭环,核心的检测、导航、决策流程均在机载RK3588上运行。
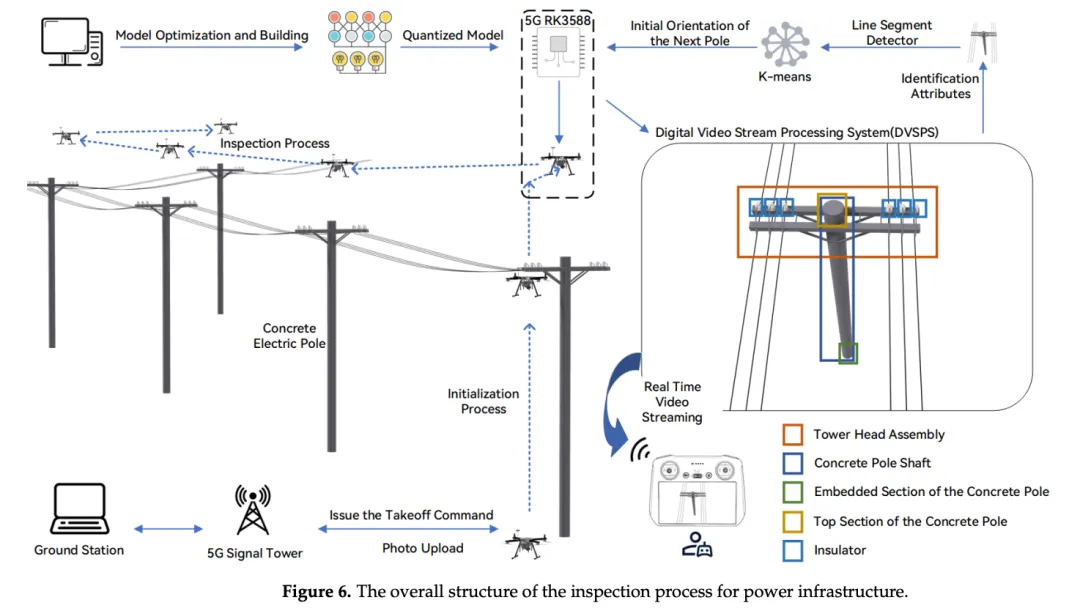
图片来源于原论文
五、总结与思考
论文构建了一套从模型优化到系统部署再到自主导航的完整无人机电力巡检方案。模型层面,VanillaBlock + Slim-Neck + 结构化剪枝将YOLOv8的FLOPs从8.2G压缩到3.7G,mAP50反而提升到88.4%;系统层面,DVSPS通过NPU并行、异步调度和硬件编解码在RK3588上实现了111.3 FPS;应用层面,集成了无需外部航点的塔杆定位和导线追踪。
在此基础上,有几点值得进一步思考:
- DVSPS的通用性值得关注。这套NPU并行 + 异步线程池 + 硬件编解码的架构并不绑定于电力巡检场景,其他在RK3588上部署视频流检测的项目(如安防、工业质检)也可以借鉴。将单帧192ms压缩到36ms的5.3倍加速,更多来自系统工程而非模型本身,这类工作往往在学术论文中被低估。
- 数据集规模与多样性。11,451张图像覆盖了城市和山区环境,5类目标的划分面向电力塔结构,这在电力巡检领域是一个可用的基准。不过数据集是否公开、能否支撑其他团队的复现和对比,论文未明确说明。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号