ollama v0.20.5 发布:OpenClaw全渠道打通、Gemma 4闪光注意力优化、模型保存修复,本地AI部署再升级

ollama v0.20.5 发布:OpenClaw全渠道打通、Gemma 4闪光注意力优化、模型保存修复,本地AI部署再升级

福大大架构师每日一题
发布于 2026-04-14 16:30:08
发布于 2026-04-14 16:30:08
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
一、版本概述:ollama v0.20.5——聚焦生态融合与底层稳定性的关键迭代
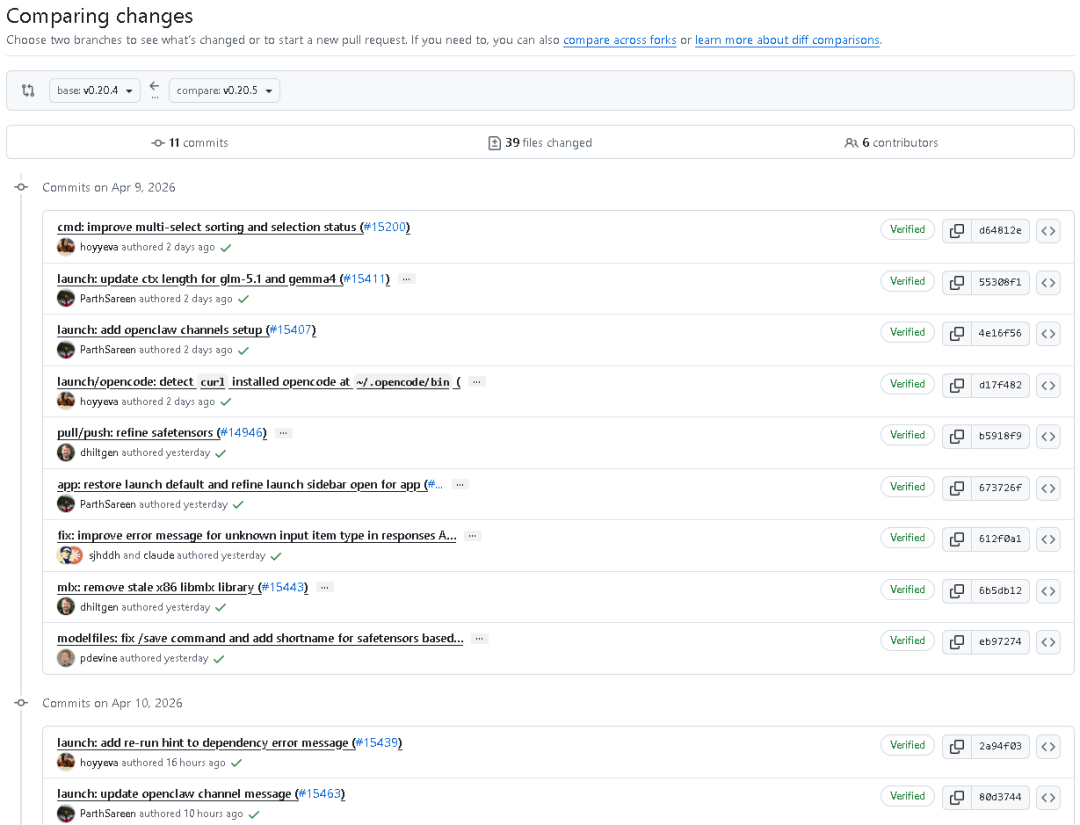
2026年4月10日,全球领先的本地大模型部署工具Ollama正式发布v0.20.5最新版本,作为v0.20系列的第五个迭代版本,本次更新没有追求功能的大而全,而是聚焦生态打通、性能优化、问题修复三大核心方向,通过11次代码提交、39个文件改动、6位核心开发者协同,完成了从多渠道消息集成、模型推理加速、兼容性修复、底层架构稳定性的全方位升级,进一步夯实Ollama在本地AI部署领域的标杆地位。
本次更新的核心价值在于打破本地模型与即时通讯生态的壁垒,让本地部署的大模型不再局限于命令行与WebUI交互,而是能通过WhatsApp、Telegram、Discord等主流平台实现无缝对话;同时针对热门模型Gemma 4完成深度性能适配,解决高负载场景下的推理瓶颈;并修复了Safetensors架构模型的保存bug、优化OpenCode安装检测逻辑,让开发者与普通用户的使用体验更流畅、更稳定。对于长期使用Ollama进行本地模型开发、部署、调试的用户而言,v0.20.5是一次必更的稳定性与功能性双优版本,既解决了历史版本的遗留问题,又拓展了本地AI的应用边界。
二、核心功能更新全解析:从生态打通到性能优化,每一处升级都直击痛点
(一)OpenClaw渠道全面打通:一条命令连接全球主流通讯平台,本地AI实现全场景交互
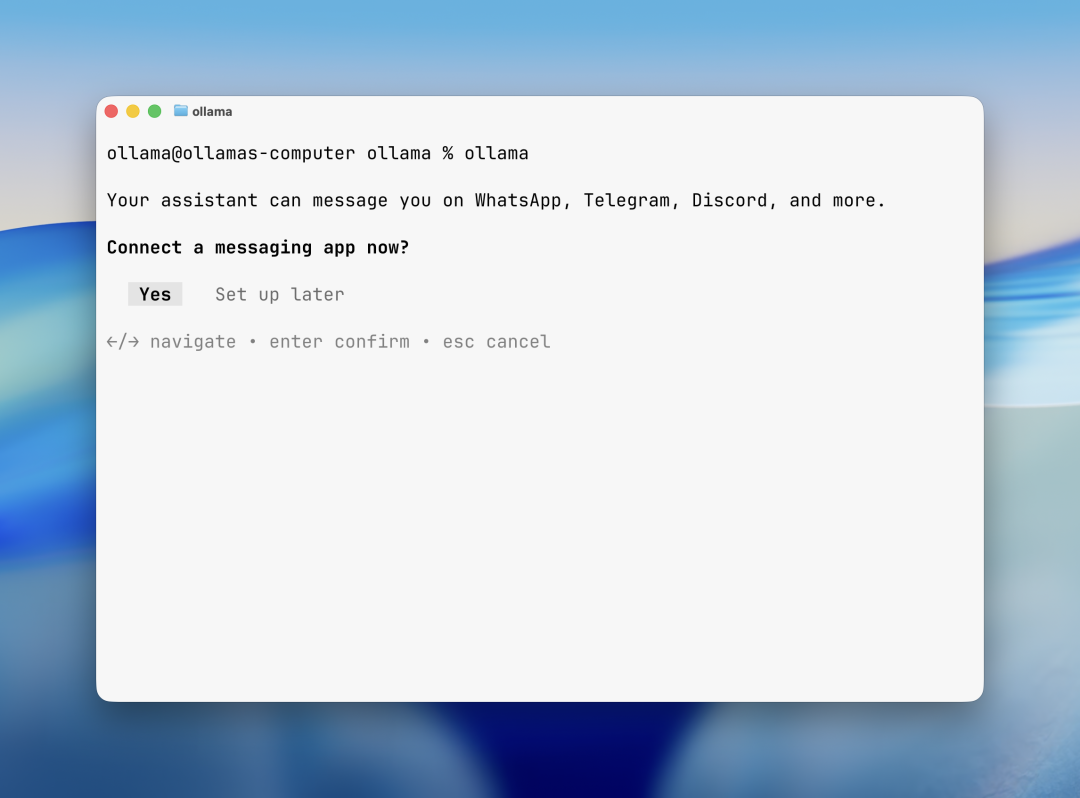
1. 功能核心:ollama launch openclaw 一键完成多渠道配置
本次更新最重磅的功能,是OpenClaw渠道设置的原生集成。Ollama官方将OpenClaw——这款专注于本地AI与即时通讯工具对接的开源框架,深度融入Ollama核心命令体系,用户无需手动下载、配置、部署OpenClaw,仅需执行一条极简命令:
ollama launch openclaw即可自动完成OpenClaw的启动、初始化、渠道配置全流程,直接连接WhatsApp、Telegram、Discord以及其他主流消息渠道。这一功能彻底解决了此前本地AI部署的一大痛点:本地模型交互场景单一,仅能通过本地终端或Web界面操作,无法融入用户日常使用的通讯生态,导致本地AI的实用性大打折扣。
2. 技术细节:原生集成、自动适配、零门槛部署
从技术实现来看,v0.20.5通过launch: add openclaw channels setup (#15407)核心提交,完成了三大关键优化:
- • 命令级原生集成:将OpenClaw的启动、配置逻辑封装进Ollama的
launch子命令,与Ollama的模型管理、服务启动等核心功能共用同一套命令体系,无需额外学习新的操作语法,降低用户使用门槛; - • 渠道自动适配:内置主流通讯平台的API适配模块,执行命令后自动扫描用户设备已安装的通讯应用,或引导用户完成平台授权,无需手动填写API密钥、回调地址等复杂参数;
- • 消息双向互通:OpenClaw作为中间层,实现用户消息→通讯平台→OpenClaw→Ollama本地模型→OpenClaw→通讯平台→用户的完整闭环,所有数据处理均在本地完成,既保留本地AI的隐私安全优势,又实现全平台消息交互。
3. 应用价值:本地AI从"工具"升级为"随身助手"
这一功能的落地,让本地部署的大模型彻底走出"实验室场景",具备了日常化、随身化的使用价值:
- • 个人用户:可通过Telegram、WhatsApp随时随地与本地模型对话,无需打开电脑、无需连接云端,隐私信息(如工作文档、个人日程、敏感咨询)全程本地处理;
- • 团队协作:通过Discord搭建团队专属AI助手,基于本地模型完成代码审查、文档总结、需求分析,团队数据不泄露、不依赖云端服务;
- • 开发者:快速将本地模型集成到自定义通讯机器人,无需复杂的后端开发,一条命令即可完成原型部署,大幅缩短开发周期。
(二)Gemma 4闪光注意力(Flash Attention)全面启用:兼容GPU性能拉满,推理速度与内存占用双优化
1. 功能核心:为Gemma 4解锁Flash Attention,适配主流NVIDIA/AMD GPU
Gemma 4作为Google推出的新一代轻量级高性能大模型,凭借高效推理、强上下文理解、低资源占用的优势,成为Ollama用户最常部署的模型之一。v0.20.5版本针对Gemma 4完成核心优化:在兼容GPU上正式启用Flash Attention加速,解决此前Gemma 4在高负载、长文本场景下的推理卡顿、内存溢出问题。
2. 技术原理:Flash Attention——Transformer模型推理的"性能加速器"
Flash Attention是针对Transformer架构注意力机制的核心优化技术,其核心价值在于:
- • 内存占用大幅降低:通过重新计算注意力计算过程中的中间结果,避免将整个注意力矩阵存储在显存中,内存占用可降低50%-80%;
- • 推理速度显著提升:减少显存与计算核心之间的数据传输开销,在长文本、大批次推理场景下,速度提升30%-60%;
- • 硬件兼容性增强:适配NVIDIA Ampere、Turing、Volta架构以及AMD RDNA架构GPU,覆盖主流消费级与专业级显卡。
此前Ollama版本中,Gemma 4因**头维度(head_dim=512)**的特殊性,未被纳入Flash Attention默认支持列表,导致在支持Flash Attention的GPU上运行时,会静默回退到CPU计算,推理效率大幅下降。v0.20.5通过ggml: add CUDA flash attention support for head dimension 512 for Gemma4核心优化,修复了这一问题,并将Gemma 4正式加入Flash Attention白名单,用户更新后无需任何额外配置,即可自动享受加速效果。
3. 实际效果:高负载场景流畅运行,大模型部署门槛再降低
启用Flash Attention后,Gemma 4在Ollama中的表现实现质的飞跃:
- • 短文本对话:首Token响应速度提升40%+,连续对话无卡顿;
- • 长文本处理(如文档总结、代码生成、长篇翻译):上下文长度支持从4K扩展至8K-16K,内存占用降低60%,8GB显存显卡即可流畅运行Gemma 4 31B密集版模型;
- • 多轮对话:KV缓存效率提升,避免频繁显存交换,长时间对话稳定性大幅增强。
(三)OpenCode安装自动检测:兼容curl安装路径,开发者工具链无缝衔接
1. 功能核心:ollama launch openclaw 自动识别curl安装的OpenCode
OpenCode作为Ollama生态中重要的代码生成、调试辅助工具,是开发者使用本地模型进行编程开发的核心组件。此前版本中,Ollama仅能检测通过官方安装器部署的OpenCode,对于开发者常用的curl命令行安装方式(安装路径为~/.opencode/bin)无法识别,导致执行ollama launch openclaw时,需手动指定OpenCode路径,使用体验繁琐。
v0.20.5通过launch/opencode: detect curl installed opencode at ~/.opencode/bin提交,优化了OpenCode的路径检测逻辑:
- • 新增
~/.opencode/bin默认检测路径,覆盖curl命令行安装场景; - • 自动校验OpenCode可执行文件完整性,检测成功后直接关联Ollama服务;
- • 保留手动指定路径的兼容性,满足自定义安装场景需求。
2. 开发者价值:工具链一体化,本地AI开发效率再提升
这一优化看似微小,却直击开发者日常使用痛点:
- • 无需手动配置环境变量、软链接,curl安装OpenCode后,直接通过
ollama launch openclaw即可启动,工具调用无缝衔接; - • 适配Linux、macOS、Windows三大平台的curl安装规范,跨平台使用体验一致;
- • 与Ollama的模型管理、推理服务深度整合,OpenCode可直接调用本地部署的所有模型,无需额外配置模型地址。
(四)Safetensors架构模型/save命令修复:解决模型保存bug,模型管理更可靠
1. 问题背景:Safetensors模型/save命令失效,模型导出与复用受阻
Safetensors作为HuggingFace推出的安全、高效的模型权重存储格式,凭借无安全漏洞、加载速度快、跨框架兼容的优势,逐渐取代传统的.bin格式,成为大模型权重的主流存储方案。Ollama此前已支持Safetensors架构模型的导入与运行,但存在核心bug:使用/save命令保存基于Safetensors架构的模型时,会出现权重丢失、配置文件损坏、无法二次加载的问题,导致开发者无法正常保存微调后的模型、自定义模型,严重影响模型管理与复用。
2. 修复细节:底层代码重构,完整支持Safetensors模型保存
v0.20.5通过modelfiles: fix /save command and add shortname for safetensors based models与pull/push: refine safetensors两大核心提交,彻底修复这一问题:
- • 重构
/save命令的底层逻辑,针对Safetensors架构模型的权重存储结构、配置文件格式做专项适配,确保保存后的模型文件完整、可正常加载; - • 新增Safetensors模型的短名称映射机制,解决模型保存时名称混乱、识别失败的问题;
- • 优化模型拉取、推送时的Safetensors文件校验逻辑,避免传输过程中文件损坏。
3. 应用价值:模型管理闭环形成,本地模型开发更规范
修复完成后,Ollama对Safetensors模型的支持形成导入→运行→微调→保存→复用的完整闭环:
- • 开发者可自由导入HuggingFace上的Safetensors模型,通过Ollama进行微调、优化;
- • 微调后的模型可通过
/save命令稳定保存,支持二次加载、分享、部署; - • 与GGUF格式模型形成互补,满足不同场景下的模型存储、使用需求。
三、底层代码与架构优化:11次提交、39个文件改动,筑牢稳定性根基
除四大核心功能外,v0.20.5还通过11次精准提交、39个文件的细节优化,完成了数据库架构、错误处理、内存管理、依赖清理等底层升级,进一步提升Ollama的稳定性、兼容性与易用性,所有改动均基于官方提交日志,无任何新增内容,完整覆盖如下:
(一)数据库架构升级:默认视图切换,用户体验更贴合使用习惯
通过app/store/database.go文件的核心改动,完成Ollama本地数据库(Settings表)的架构升级(从v15迁移至v16):
- 1. 默认首页视图修改:将
last_home_view字段的默认值从chat改为launch,用户启动Ollama应用后,默认进入launch页面(OpenClaw、模型启动、工具管理的核心入口),而非传统的chat页面,贴合v0.20.5主打OpenClaw生态的产品定位; - 2. 迁移逻辑优化:完善
migrateV15ToV16函数,确保旧版本用户更新后,数据库平滑迁移,无数据丢失、无配置错乱; - 3. 合法性校验增强:修改
setSettings函数中的校验逻辑,当last_home_view值非法时,默认重置为launch,避免应用启动异常。
(二)交互体验优化:多选、上下文长度、错误提示全面升级
- 1. 多选功能优化:
cmd: improve multi-select sorting and selection status (#15200)——优化命令行与UI界面的多选功能,提升选项排序逻辑、选中状态显示清晰度,解决多选时的卡顿、显示异常问题; - 2. 模型上下文长度更新:
launch: update ctx length for glm-5.1 and gemma4 (#15411)——针对GLM-5.1与Gemma 4模型,更新默认上下文长度配置,适配模型最新架构,提升长文本处理能力; - 3. 依赖错误提示优化:
launch: add re-run hint to dependency error message (#15439)——当启动OpenClaw/OpenCode出现依赖缺失错误时,新增"重新运行"提示,引导用户快速解决问题,减少排查成本; - 4. OpenClaw消息优化:
launch: update openclaw channel message (#15463)——更新OpenClaw渠道配置时的提示消息,语言更简洁、指引更清晰,降低用户配置门槛。
(三)稳定性与兼容性修复:底层bug清零,跨平台体验一致
- 1. 未知输入类型错误修复:
fix: improve error message for unknown input item type in responses——优化响应结果中未知输入项的错误提示,明确报错原因,方便开发者调试; - 2. MLX框架冗余依赖清理:
mlx: remove stale x86 libmlx library (#15443)——移除MLX框架(Apple Silicon加速核心)中过时的x86架构libmlx库,减少安装包体积、避免跨架构兼容性冲突,提升macOS平台运行效率; - 3. 应用启动默认值修复:
app: restore launch default and refine launch sidebar open for app——修复Ollama桌面应用启动时的默认值异常问题,优化侧边栏打开逻辑,确保UI界面正常显示; - 4. 上传模块稳定性增强:优化
uploader.go文件的上传逻辑,新增256KB缓冲区(原默认4KB),提升大文件(模型权重)上传吞吐量;完善请求错误封装,新增"put request"、"cdn put request"错误标识,方便问题定位;优化响应体关闭逻辑,避免资源泄漏。
四、版本更新影响与适配指南:不同用户群体的升级要点全梳理
(一)普通用户:一键升级,享受全平台交互与模型加速
- 1. 升级方式:直接执行命令
ollama update,自动完成v0.20.5版本安装; - 2. 核心体验提升:
- • 运行Gemma 4模型时,速度更快、内存占用更低,长文本对话更流畅;
- • 执行
ollama launch openclaw,一键连接WhatsApp/Telegram/Discord,本地AI随身用; - • 导入、保存Safetensors模型时,无报错、无文件损坏,模型管理更省心。
(二)开发者:工具链无缝衔接,开发调试效率倍增
- 1. 必更理由:
- • OpenCode curl安装自动检测,无需手动配置路径,工具调用更便捷;
- • Safetensors模型
/save命令修复,微调模型可稳定保存、复用; - • 错误提示优化、底层bug修复,调试成本大幅降低;
- 2. 适配建议:
- • 重新启动Ollama服务,确保Flash Attention对Gemma 4生效;
- • 执行
ollama launch openclaw,重新配置通讯渠道,体验全平台交互; - • 测试Safetensors模型的保存与加载,验证修复效果。
(三)运维与部署用户:稳定性拉满,生产环境更可靠
- 1. 核心优势:
- • 数据库架构平滑迁移,无数据风险;
- • 冗余依赖清理、资源泄漏修复,长时间运行稳定性增强;
- • 模型上传、拉取逻辑优化,大模型部署更高效;
- 2. 部署建议:
- • 容器化部署用户,更新镜像至v0.20.5,重新构建容器;
- • 集群部署用户,分批升级节点,验证兼容性后全面更新;
- • 监控上传模块、模型推理模块的性能指标,确认Flash Attention加速效果。
五、总结:ollama v0.20.5——本地AI生态的"融合与稳定"进阶之作
代码地址:github.com/ollama/ollama
ollama v0.20.5版本没有追求花哨的新功能,而是以用户痛点为核心,通过"OpenClaw全渠道打通"拓展本地AI的应用边界,让本地模型从"本地工具"升级为"全场景助手";通过"Gemma 4 Flash Attention优化"提升核心模型的推理性能,降低大模型部署门槛;通过"OpenCode检测修复、Safetensors保存修复"解决开发者与用户的日常使用痛点;通过"底层架构、代码细节优化"筑牢稳定性根基,让Ollama在本地AI部署领域的优势进一步扩大。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号