2026-04-13:不同首字母的子字符串数目。用go语言,给定一个只包含小写字母的字符串 s。 你需要把它切分成若干个连续、非空的子串(覆盖

2026-04-13:不同首字母的子字符串数目。用go语言,给定一个只包含小写字母的字符串 s。 你需要把它切分成若干个连续、非空的子串(覆盖

福大大架构师每日一题
发布于 2026-04-14 16:34:10
发布于 2026-04-14 16:34:10
2026-04-13:不同首字母的子字符串数目。用go语言,给定一个只包含小写字母的字符串 s
你需要把它切分成若干个连续、非空的子串(覆盖整个字符串,且不重叠)。
目标是:让子串的数量尽可能多,并满足限制——每个子串的起始字符都必须各不相同,也就是说任意两个子串的第一个字母不能相同。
请输出满足上述条件时,子串的最大数量。
1 <= s.length <= 100000。
s 仅由小写英文字母组成。
输入: s = "abcd"。
输出: 4。
解释:
可以将 "abcd" 划分为 "a"、"b"、"c" 和 "d"。
每个子字符串都以不同的字符开头。因此,答案是 4。
题目来自力扣3760。
解题过程分步详细描述
一、理解题目核心要求
我们需要把给定的纯小写字母字符串,分割成连续、不重叠、非空的子串,满足两个关键条件:
- 1. 所有子串的起始字符必须完全不同(不能有两个子串以同一个字母开头);
- 2. 在满足第一个条件的前提下,分割出的子串数量要尽可能多。 最终输出这个最大的子串数量。
补充:小写字母一共只有26个(a-z),因此最大可能的子串数量永远不会超过26,这是核心限制。
二、解题核心思路
要让子串数量最多,最优策略是:尽可能把每个字符单独切分为一个子串,只要这个字符还没有被用作过子串的起始字符。 因为一旦某个字母作为子串开头使用过一次,后续就不能再用了,所以我们需要记录已经使用过的起始字母,遍历字符串时逐个判断。
三、分步骤执行过程(以示例 s="abcd" 为例)
步骤1:初始化记录工具
创建一个标记集合/标记位,专门用来记录已经被用作子串起始的字母,初始状态为空,没有任何字母被使用。 同时初始化一个计数器,用来统计最终的子串数量,初始值为0。
步骤2:从头开始遍历字符串的每一个字符
我们按顺序处理字符串中的每一个字符,判断当前字符是否能作为新子串的起始字符:
- 1. 处理第一个字符
a:- • 检查
a是否在已使用的起始字母集合中 → 未使用; - • 可以将
a单独切分为一个子串; - • 把
a加入已使用集合; - • 子串计数器 +1(当前计数:1)。
- • 检查
- 2. 处理第二个字符
b:- • 检查
b是否在已使用的起始字母集合中 → 未使用; - • 可以将
b单独切分为一个子串; - • 把
b加入已使用集合; - • 子串计数器 +1(当前计数:2)。
- • 检查
- 3. 处理第三个字符
c:- • 检查
c是否在已使用的起始字母集合中 → 未使用; - • 可以将
c单独切分为一个子串; - • 把
c加入已使用集合; - • 子串计数器 +1(当前计数:3)。
- • 检查
- 4. 处理第四个字符
d:- • 检查
d是否在已使用的起始字母集合中 → 未使用; - • 可以将
d单独切分为一个子串; - • 把
d加入已使用集合; - • 子串计数器 +1(当前计数:4)。
- • 检查
步骤3:遍历结束,输出结果
整个字符串遍历完成,计数器的值就是最大子串数量,最终结果为4。
四、通用场景补充说明(非示例,帮助理解)
如果字符串出现重复字母,例如 s="abac":
- 1. 第一个字符
a:未使用,切分,计数=1,标记a; - 2. 第二个字符
b:未使用,切分,计数=2,标记b; - 3. 第三个字符
a:已标记使用过,不能作为新子串开头,必须和前一个子串合并(即ba合并为一个子串); - 4. 第四个字符
c:未使用,切分,计数=3,标记c; 最终结果为3。
复杂度分析
1. 时间复杂度
- • 我们只需要从头到尾遍历一次字符串,每个字符仅处理一次;
- • 所有判断、标记操作都是常数时间 O(1)(因为字母只有26个,操作无额外循环);
- • 总时间复杂度:O(n),n 为字符串的长度。
2. 额外空间复杂度
- • 我们仅使用了固定大小的空间(一个整数位标记/26个布尔值标记)来记录已使用的字母;
- • 空间大小不随字符串长度 n 变化,属于常数级空间;
- • 总额外空间复杂度:O(1)。
总结
- 1. 解题核心:遍历字符串,标记已使用的起始字母,尽可能切分单个字符为子串;
- 2. 时间复杂度:O(n)(线性遍历,高效适配10万长度的字符串);
- 3. 额外空间复杂度:O(1)(常数空间,无额外内存消耗)。
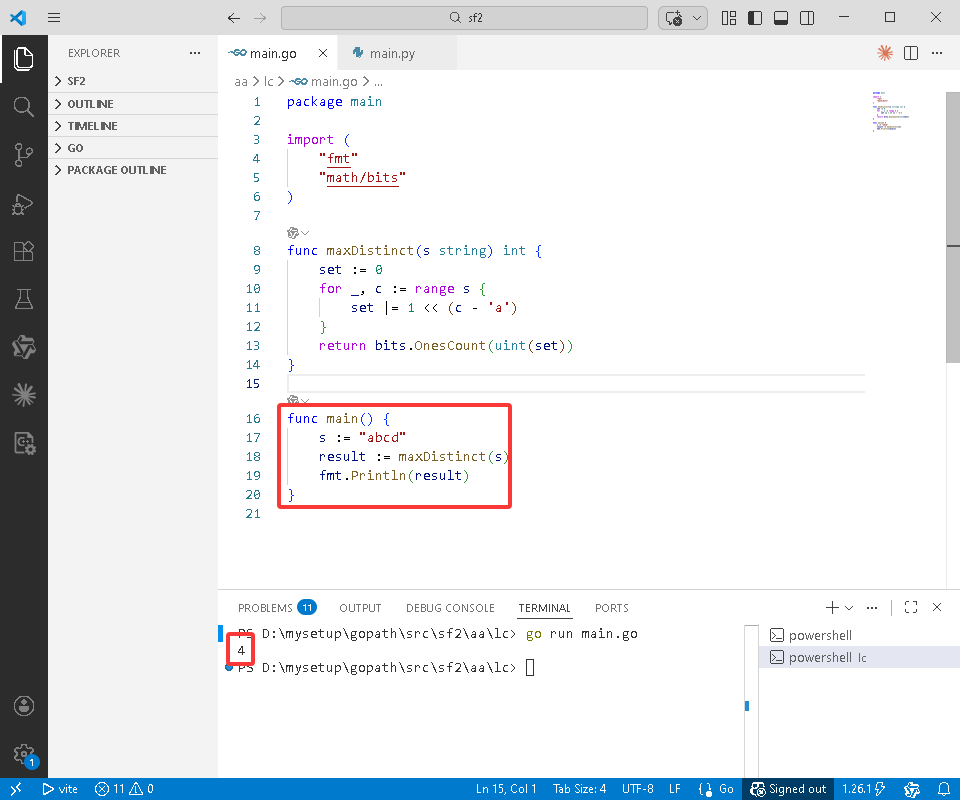
Go完整代码如下:
.
package main
import (
"fmt"
"math/bits"
)
func maxDistinct(s string)int {
set := 0
for _, c := range s {
set |= 1 << (c - 'a')
}
return bits.OnesCount(uint(set))
}
func main() {
s := "abcd"
result := maxDistinct(s)
fmt.Println(result)
}
在这里插入图片描述
Python完整代码如下:
.
# -*-coding:utf-8-*-
def max_distinct(s: str) -> int:
bitmask = 0
for c in s:
bitmask |= 1 << (ord(c) - ord('a'))
return bin(bitmask).count('1')
if __name__ == "__main__":
s = "abcd"
result = max_distinct(s)
print(result)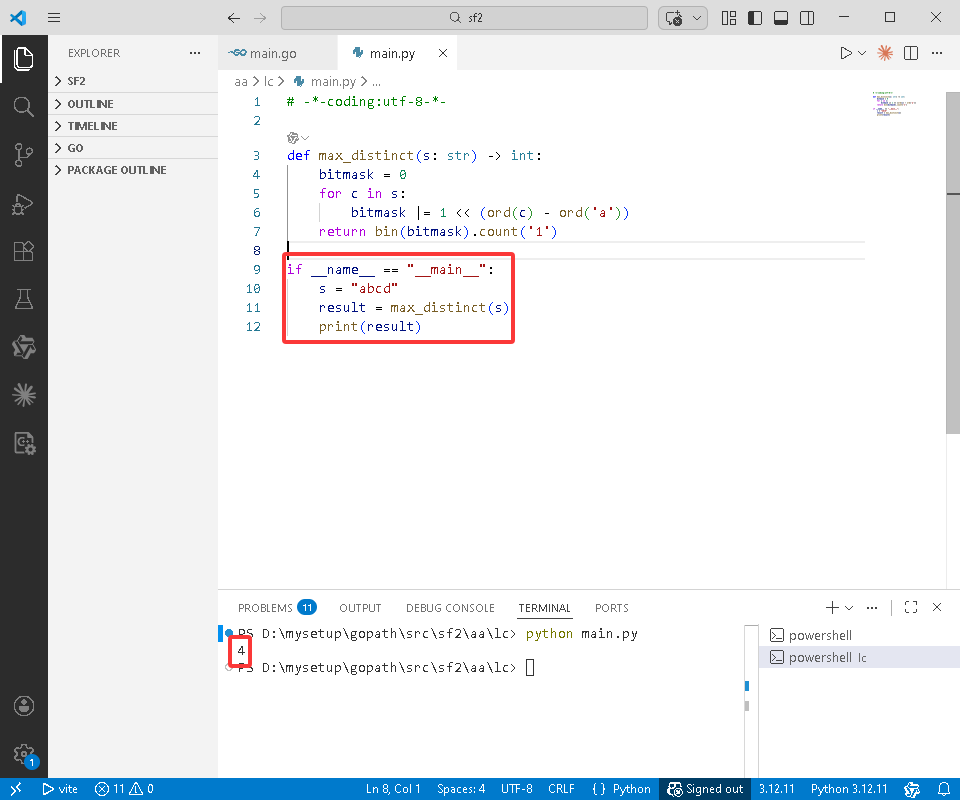
在这里插入图片描述
C++完整代码如下:
.
#include <iostream>
#include <string>
#include <bit>
int maxDistinct(const std::string& s) {
int set = 0;
for (char c : s) {
set |= 1 << (c - 'a');
}
return std::popcount(static_cast<unsigned int>(set));
}
int main() {
std::string s = "abcd";
int result = maxDistinct(s);
std::cout << result << std::endl;
return0;
}
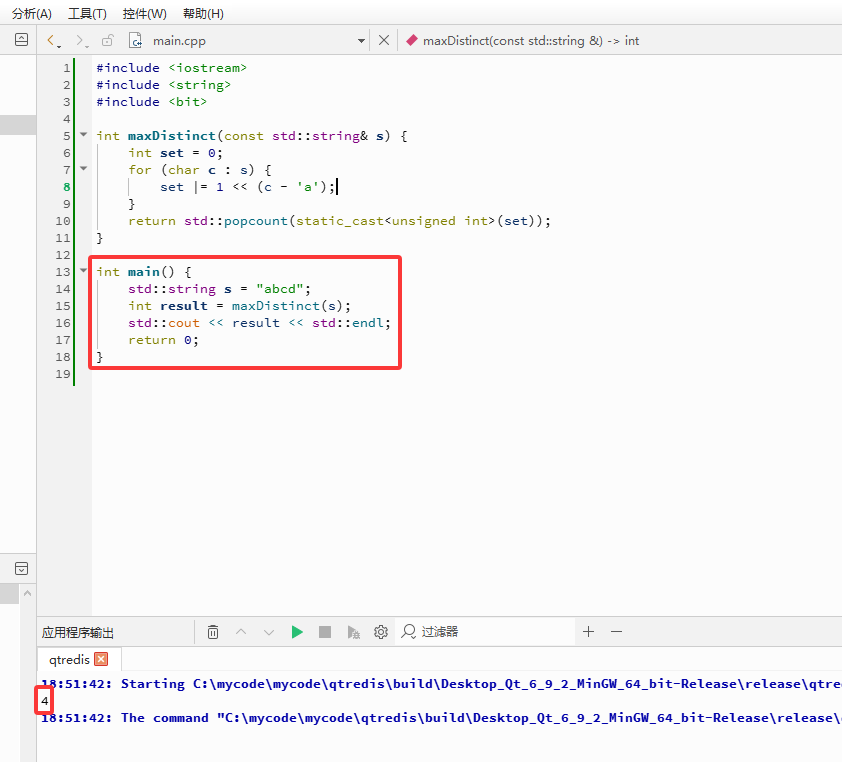
在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号