lmdeploy v0.12.3:视频输入、Qwen3.5、TurboMind 压缩张量、Ray 安全 API 等重大升级全面解析

lmdeploy v0.12.3:视频输入、Qwen3.5、TurboMind 压缩张量、Ray 安全 API 等重大升级全面解析

福大大架构师每日一题
发布于 2026-04-14 16:34:39
发布于 2026-04-14 16:34:39
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
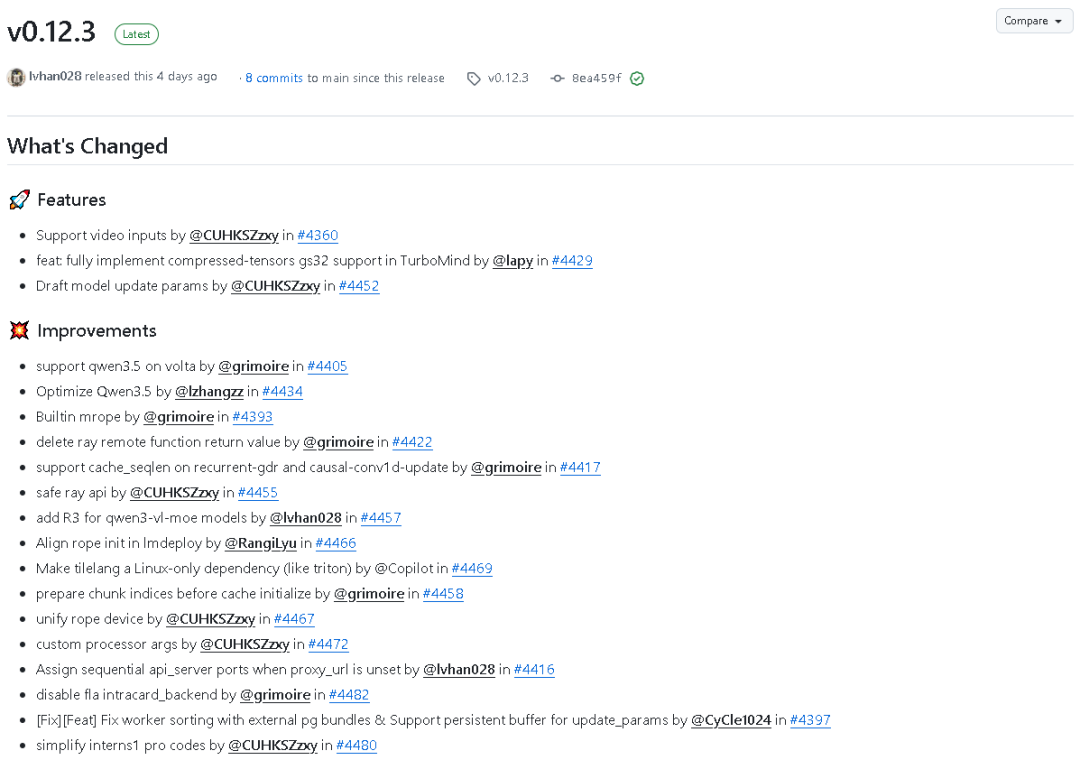
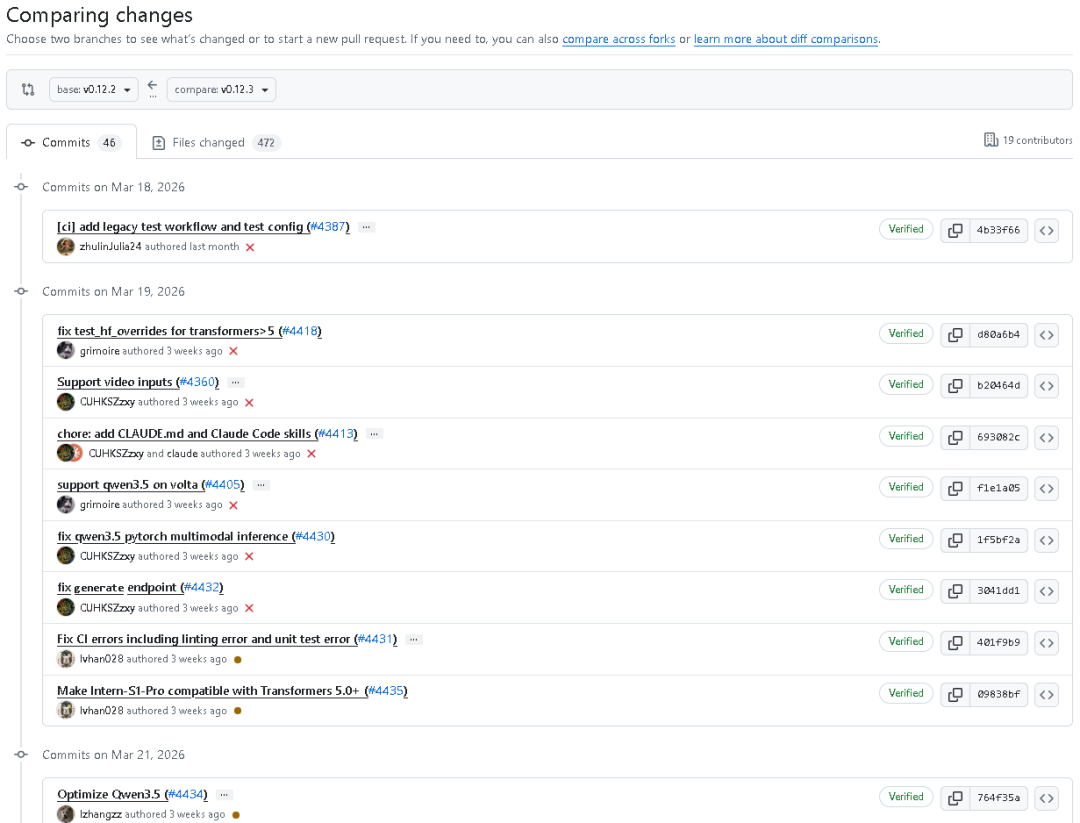
LMDeploy 在 2026 年 4 月 8 日发布了 v0.12.3 版本。这一版本覆盖了 Features、Improvements、Bug fixes、Other 四大部分,累计 19 位贡献者、46 个 commits、472 个 files changed,属于一次覆盖面非常广、实用性非常强的版本更新。
如果你正在关注 LMDeploy 的推理能力、多模态支持、Qwen3.5 适配、TurboMind 能力、Ray 相关改造、部署稳定性优化,那么这个版本几乎可以说是一次“系统级增强”。
一、v0.12.3 版本概览
本次版本更新的关键词非常明确:
- • 多模态能力增强
- • Qwen3.5 全面适配与优化
- • TurboMind 推理能力增强
- • Ray 与服务端安全性改进
- • RoPE / mRoPE 相关统一与修复
- • 缓存、端点、生成、图像视频处理等关键链路修复
- • CI、Docker、Python 代码现代化改造
从更新列表看,这次版本不只是修复 bug,更像是一次围绕模型推理、服务稳定性和工程化能力的集中升级。
二、核心功能更新:v0.12.3 带来了什么
1)支持视频输入
这是本版本最受关注的特性之一:支持视频输入。
这意味着 LMDeploy 的多模态输入能力进一步扩展,不再局限于文本或静态图像,开始向视频类输入场景延伸。对于本地推理、视频理解、多模态交互等场景来说,这是非常关键的能力升级。
从更新内容来看,视频输入并不是一个边角功能,而是被列为正式 Features,说明其在版本中具有明显的功能地位。
2)TurboMind 完整支持 compressed-tensors gs32
本版本中,TurboMind 新增了对 compressed-tensors gs32 的完整支持。
这类更新通常意味着推理引擎在处理压缩权重、量化模型或相关张量格式时,兼容性与稳定性得到进一步增强。对于依赖 TurboMind 的用户来说,这是一项非常重要的底层能力提升,直接关系到模型加载、运行与推理表现。
3)Draft model update params
本版本加入了 Draft model update params。
从功能名称来看,这是对草稿模型参数更新流程的增强,属于推理链路中的关键能力优化。虽然更新信息本身没有展开细节,但从其被列为 Features 可以看出,这项能力已经进入正式支持范围。
三、重点改进:Qwen3.5 相关更新最密集
v0.12.3 中,Qwen3.5 相关内容非常多,几乎贯穿了多个模块,是本次更新最核心的主题之一。
1)支持 Qwen3.5 在 Volta 上运行
版本更新中明确提到:support qwen3.5 on volta。
这意味着 Qwen3.5 在 Volta 相关环境中的支持能力得到增强,进一步扩大了其可部署范围。
2)优化 Qwen3.5
本版本还包含了专门的 Optimize Qwen3.5。
这说明 Qwen3.5 不只是“能跑”,而是继续在性能、兼容性或推理表现上进行针对性优化。
3)Qwen3.5 PyTorch 多模态推理修复
更新中提到:fix qwen3.5 pytorch multimodal inference。
这是针对 Qwen3.5 在 PyTorch 多模态推理路径上的修复,说明在多模态场景中,Qwen3.5 的推理链路已经被纳入重点保障范围。
4)Qwen3.5 FP8 支持修复
版本还修复了:fix qwen3.5 fp8 support。
FP8 支持是推理精度、性能与模型部署中常见的重要方向之一。该修复表明 Qwen3.5 在 FP8 路径上得到了进一步完善。
5)Qwen3.5 MTP 支持
本次更新还包含:Support qwen35 with mtp。
这说明 Qwen3.5 与 MTP 相关的支持能力也被纳入版本升级内容中,进一步增强了其适配范围。
6)Qwen3Coder 工具调用参数拆分
版本中还加入了:Split/tool call args json for qwen3coder tool calls (Qwen3.5)。
这项更新与 Qwen3.5 的 tool call 能力有关,说明工具调用参数的 JSON 拆分处理方式得到了调整和支持,属于面向工具调用链路的修复和增强。
四、多模态与视觉相关升级
1)视频输入支持
前面已经提到,本版本新增了视频输入支持,这是非常明确的多模态扩展。
2)图像 / 视频 resize 函数修复
本版本还修复了:fix image / video resize function。
这说明图像和视频在尺寸处理过程中存在的问题被修正了。对于多模态输入来说,resize 是非常基础但关键的一环,关系到输入是否能正确进入模型链路。
3)Qwen3-VL-MOE 增加 R3
更新中提到:add R3 for qwen3-vl-moe models。
这属于对视觉语言混合模型的适配增强,说明 Qwen3-VL-MOE 在本版本中也得到进一步支持。
五、推理引擎与底层能力增强
1)Builtin mrope
本版本加入了 Builtin mrope。
这意味着 mRoPE 相关能力开始成为 LMDeploy 的内建组成部分之一。对于模型推理中的位置编码处理,这类变化通常非常关键。
2)RoPE 初始化对齐
更新中提到:Align rope init in lmdeploy。
这说明 LMDeploy 内部 RoPE 初始化逻辑得到了对齐处理,属于底层一致性增强。
3)统一 rope device
本版本还包括:unify rope device。
这意味着 RoPE 所使用的设备处理逻辑被统一,减少不同路径下的设备差异问题。
4)动态 NTK 设备修复
更新中还提到:fix dynamic ntk device。
动态 NTK 相关流程中设备处理问题被修复,有助于提升运行稳定性。
5)准备缓存前先准备 chunk indices
版本中有一项改进:prepare chunk indices before cache initialize。
这说明缓存初始化流程中的前置准备工作被调整了顺序,属于推理链路中的时序优化。
6)支持 recurrent-gdr 和 causal-conv1d-update 的 cache_seqlen
更新中提到:support cache_seqlen on recurrent-gdr and causal-conv1d-update。
这类内容指向缓存长度相关能力增强,属于底层推理状态管理的优化。
7)release state cache
版本还加入了:release state cache。
这说明状态缓存释放逻辑得到补充,有利于资源管理与运行稳定性。
六、Ray 与服务端相关改进
1)安全 Ray API
版本中提到:safe ray api。
这说明 Ray API 的使用变得更加安全,属于服务编排和并行处理链路中的重要改进。
2)删除 ray remote function return value
本版本还包含:delete ray remote function return value。
这表明 Ray remote function 的返回值处理逻辑被调整,属于运行行为和接口行为上的变化。
3)当 proxy_url 为空时,api_server 端口顺序分配
更新中提到:Assign sequential api_server ports when proxy_url is unset。
这项改进与服务端口分配逻辑相关,当 proxy_url 未设置时,api_server 会按顺序分配端口,提升部署可控性。
4)修复 generate endpoint
版本还修复了:fix generate endpoint。
这意味着生成接口链路存在的问题得到了处理,直接影响推理服务可用性。
5)修复多轮聊天
更新中提到:fix multiround chat。
说明多轮对话场景中的问题已被修复,这对在线对话服务很关键。
6)修复 metrics
版本还修复了:fix metrics。
这通常意味着监控指标输出、统计或采集链路得到修正。
7)修复安全问题
更新列表中还明确提到:fix security issues。
这说明本版本包含安全性修复,属于必须重视的升级项。
七、TurboMind 与模型推理相关修复
1)ApplyTokenBitmaskInplace 维度不匹配修复
版本中提到:fix(turbomind): fix dimension mismatch in ApplyTokenBitmaskInplace。
这是 TurboMind 相关的关键修复,说明在应用 token bitmask 的过程中出现了维度不匹配问题,本次已修复。
2)pagedattention pointer range 修复
更新中提到:fix pagedattention pointer range。
PagedAttention 是推理中常见技术点之一,这类修复通常与底层指针范围、内存访问或计算边界有关,属于非常关键的稳定性修正。
3)Torch AWQ 修复
版本中还提到:Fix torch awq。
这意味着 Torch AWQ 相关路径的问题已被修复,对依赖该路径的推理流程来说是重要补强。
八、模型兼容性与特殊模型支持
1)Intern-S1-Pro 兼容 Transformers 5.0+
版本中提到:Make Intern-S1-Pro compatible with Transformers 5.0+。
这说明 Intern-S1-Pro 的兼容性得到提升,能够适配 Transformers 5.0 及以上版本。
2)Intern-S1-Pro 代码简化
更新中还包含:simplify interns1 pro codes。
这表示相关代码路径做了简化处理,有利于维护和后续迭代。
3)glm4.7-flash 修复
版本中还提到:fix glm4.7-flash。
说明该模型相关的问题已被修正。
九、工程化与 CI / Docker / Python 代码现代化
除了推理与模型本身,v0.12.3 还对工程体系做了不少整理。
1)添加旧版测试工作流和测试配置
版本中有:[ci] add legacy test workflow and test config。
这说明 CI 流程中补充了旧版测试工作流与测试配置,便于兼容历史路径的验证。
2)修复 CI 错误
更新中提到:Fix CI errors including linting error and unit test error。
说明本次修复了 CI 中的 linting 错误和单测错误。
3)使用 pyupgrade 和 ruff 现代化 Python 代码
版本中提到:Use pyupgrade and ruff to modernize LMDeploy Python Code。
这是对 Python 代码风格和质量的现代化处理,涉及自动化代码规范与升级。
4)减少 CI 内存占用
更新中提到:reduce ci memory。
说明 CI 运行过程中的内存压力被降低。
5)Docker 工作流中添加 safe.directory
版本中提到:fix: add safe.directory for git in docker workflows。
这属于 Docker 构建或工作流中的 Git 安全配置修复。
6)添加 nightly docker build workflow
更新中提到:[ci] add nightly docker build workflow。
这表示新增了 nightly docker 构建流程。
7)拆分 Docker wheel 准备步骤并使用 Python 3.12 作为默认版本
版本中还提到:split docker wheel preparation into staged build steps and use python 3.12 as the default version。
这说明 Docker wheel 的准备流程被拆成分阶段构建步骤,并将 Python 3.12 设为默认版本。
8)添加 CLAUDE.md 和 Claude Code skills
更新中还包含:chore: add CLAUDE.md and Claude Code skills。
这属于仓库文档与代码辅助能力方面的补充。
十、其他重要改动与补充
1)外部 pg bundles 下 worker 排序修复,并支持 persistent buffer for update_params
版本中有一项较长的更新:[Fix][Feat] Fix worker sorting with external pg bundles & Support persistent buffer for update_params。
这说明在外部 pg bundles 场景下的 worker 排序问题得到了修复,同时 update_params 还支持 persistent buffer。
2)禁用 fla intracard_backend
更新中提到:disable fla intracard_backend。
这属于某个后端能力的禁用调整。
3)支持 qwen3.5 on volta 与 qwen35 with mtp 同时出现
这两项内容说明 Qwen3.5 的支持矩阵在本版本中被持续扩展,体现出版本更新对该模型系列的集中投入。
4)添加 R3、统一 rope、builtin mrope、cache_seqlen、state cache 等一系列底层改动
这些更新虽然分散,但整体上表明 v0.12.3 在“位置编码、缓存管理、推理稳定性、设备一致性”方面做了大量基础建设。
十一、v0.12.3 的版本定位总结
如果把这次更新概括成一句话,那就是:
v0.12.3 是一次围绕多模态、Qwen3.5、TurboMind、Ray 安全性、底层推理链路与工程化能力的全面增强版本。
它的特点非常明显:
- • 新能力上:支持视频输入,增强多模态场景
- • 模型上:Qwen3.5 相关支持与优化最密集
- • 引擎上:TurboMind、RoPE、cache、pagedattention 等底层链路均有补强
- • 服务上:generate endpoint、多轮聊天、metrics、端口分配、安全 API 均有修复
- • 工程上:CI、Docker、Python 代码规范持续现代化
这不是一个单点修复版本,而是一个覆盖推理、部署、兼容、性能与稳定性的综合升级版本。
十二、结语
代码地址:github.com/InternLM/lmdeploy
对于正在使用 LMDeploy 的开发者来说,v0.12.3 值得重点关注,原因并不只是“版本号变了”,而是它集中解决了多个核心方向的问题:
- • 想用视频输入的,可以关注本次多模态扩展;
- • 重点跑 Qwen3.5 的,可以关注其多项适配、优化与修复;
- • 依赖 TurboMind 的,可以关注 compressed-tensors gs32、ApplyTokenBitmaskInplace、pagedattention 等底层修复;
- • 关注服务部署和在线推理的,可以关注 Ray 安全 API、端口分配、generate endpoint、多轮聊天与 metrics 修复;
- • 关注工程体系的,可以关注 CI、Docker、Python 现代化改造。
总的来说,LMDeploy v0.12.3 是一次“面向可用性、兼容性、稳定性和扩展性”的扎实升级。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号