学习了知识图谱,发现大模型的幻觉还能再降低几个点!怎么做到的?一文讲清楚

学习了知识图谱,发现大模型的幻觉还能再降低几个点!怎么做到的?一文讲清楚

烟雨平生
发布于 2026-04-14 18:32:07
发布于 2026-04-14 18:32:07
2025Agent元年的时代里,大家都用过大模型,真的是很快、很强、很全,如果只是当玩具,真的是又好玩又高级。如果进行商业场景,大模型这个“才华横溢的文科天才”说话没个谱,缺乏可解释性,容易一本正经地胡说八道,出现了幻觉,就像李白一样,很炫、很酷、很有才,真是到办事,这个问题是非常致命的,皇帝担心关键时候掉链子,真心不敢用,“寡人性命全系你一念?”。
幻觉,大模型与生俱来的BUG,怎么办法降低呢?目前在工程层面有三个办法:一是加个RAG外挂,开卷考试,二是Prompt明确不能瞎编,找不到就回复不知道,三是Human-in-the-loop兜底—— 关键场景人工把关。
今天学了知识图片谱后,可以再增加第四个把知识图谱的结构化知识融入大模型的检索和生成过程。
知识图谱,就是给现实世界的知识画了一张关系地图。
下面我们来详细聊聊
你以为知识图谱是枯燥的数据蜘蛛网?错!它其实是AI世界的认知导航仪,用几块简单“积木”就能撬动千亿级知识网络。今天我们就来一场知识图谱的深度游,从三个方面把它彻底讲明白:第一,知识图谱到底是什么,底层逻辑是怎样的?第二,一个厉害的知识图谱是怎么一步一步搭建起来的?最后,也是最重要的——它和现在火得不行的大模型到底是什么关系,为什么总是一起出现?
一、知识图谱:复刻人类思维的“知识之网”
先来看知识图谱的基本原理。我们先俯瞰定义:想象一下你的大脑是怎么记东西的?比如提到“苹果”,你脑子里会立刻冒出来一堆信息:它是一种水果,口感脆甜,颜色有红色和绿色,还能做成苹果派;另外,创始人是乔布斯的那家公司也叫“苹果”。你看,我们大脑里的知识从来不是一个个孤立的点,而是像一张巨大的、相互连接的网。
知识图谱干的其实就是同样的事——用计算机能理解的方式画出这张“知识之网”。官方的说法是,知识图谱通过“实体-关系-实体”的三元组,把知识以结构化的方式进行表示。一听到“三元组”可能会懵,但其实它就是知识的基本“积木”,简单到让人意外。
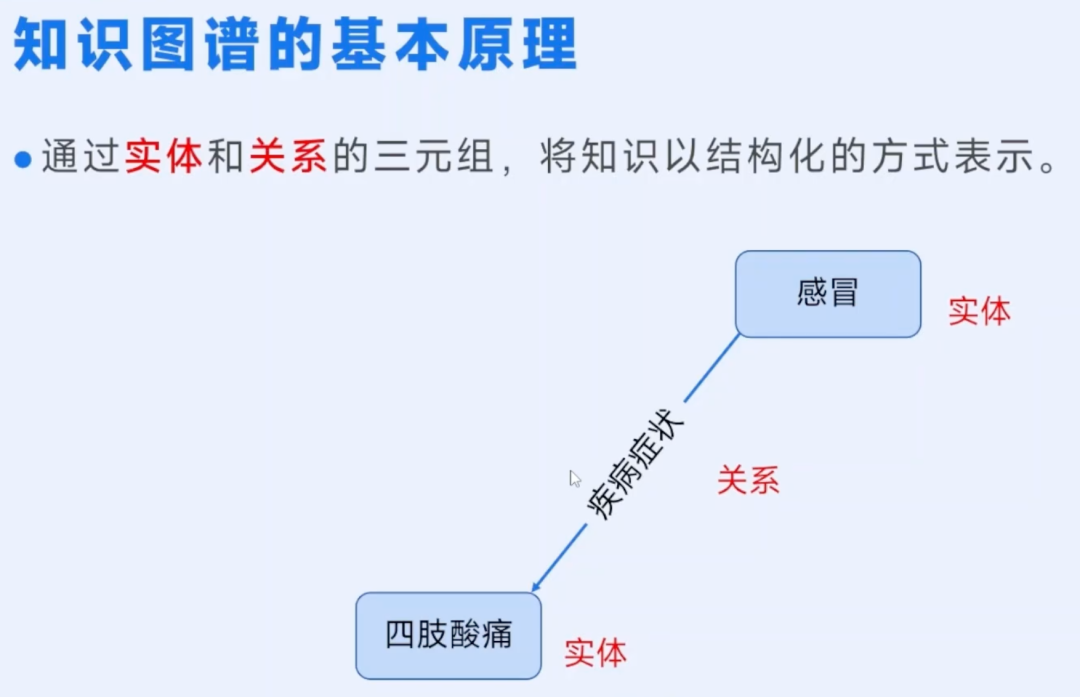
举个例子:“感冒的症状是四肢酸痛”,这就是一个最基础的三元组。这里的“感冒”和“四肢酸痛”是“实体”,你可以把它们理解成两个知识节点;而中间的“症状”,就是两个实体之间的关系。就这么简单,一个三元组就清晰地表达了一条完整的知识。
当成千上万个这样的“积木”搭在一起,会发生什么?
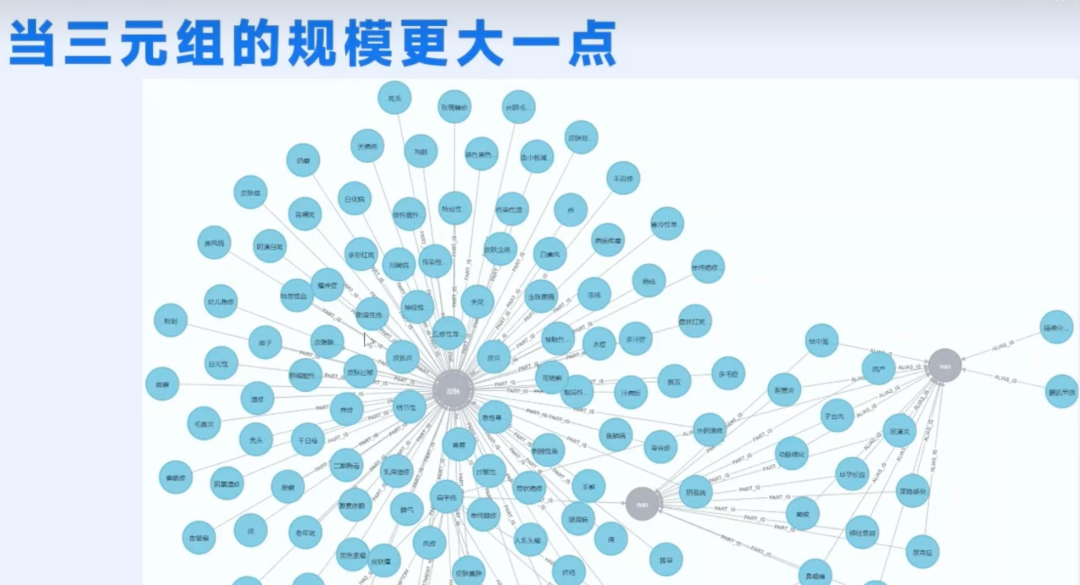
最终我们会得到覆盖特定领域的宏大知识网络——比如医学知识图谱。以“皮肤”这个节点为例,它关联的有皮炎、天花、水痘等多种疾病,每种疾病又对应着具体症状、治疗方案等信息。这张图谱把原本散落在书本里、网页上、医生脑子里的零散知识,整理得井井有条、一目了然。
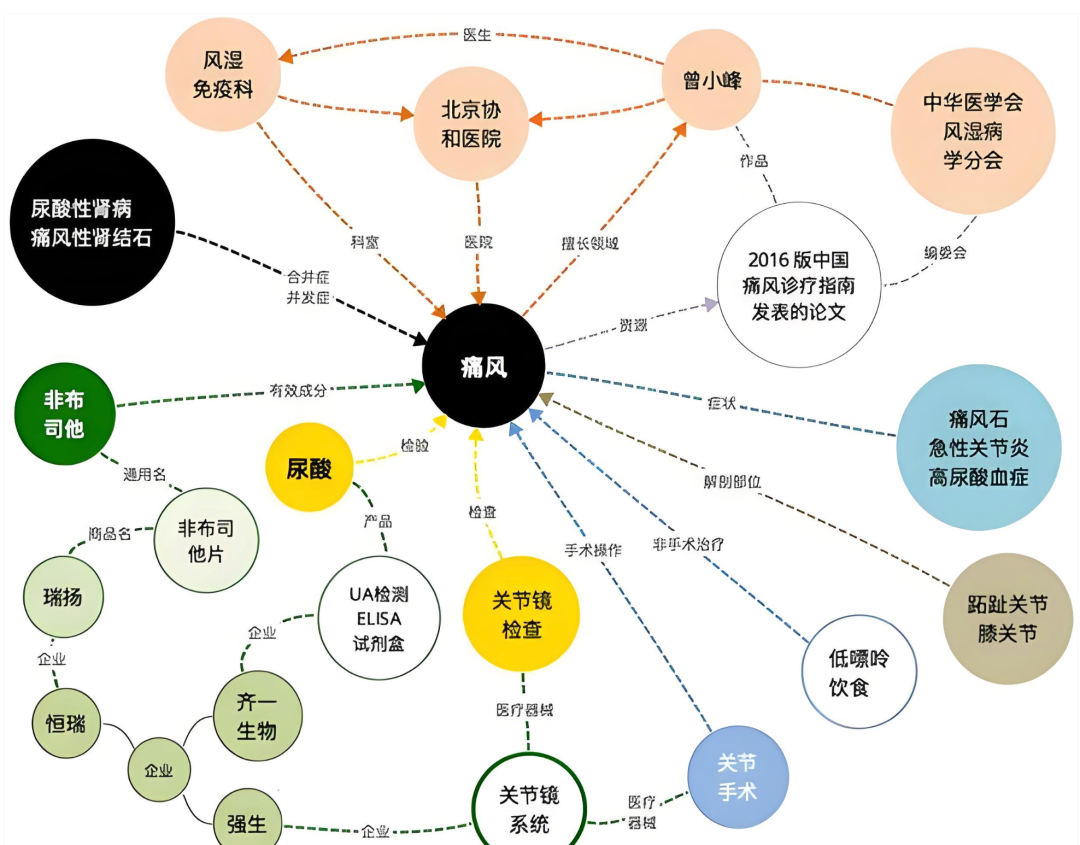
一句话总结:知识图谱的核心,就是用计算机能识别的“节点(实体)+连线(关系)”模式,复刻人类的关联思维,让零散信息变成结构化的知识网络,帮机器实现类似人类的“认知理解”能力。
二、从零到一搭建知识图谱:7步打造“智能知识库”
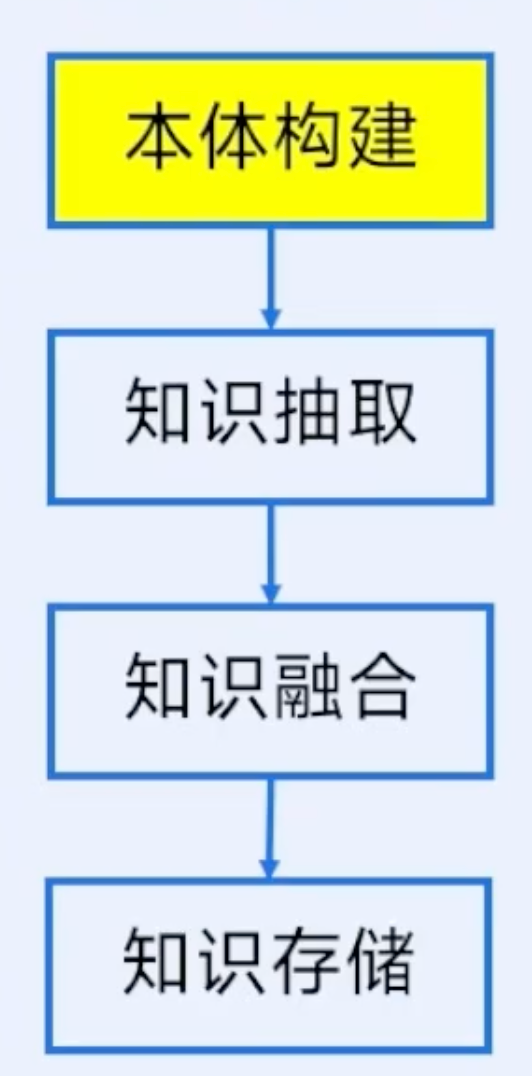
看似复杂的知识图谱,搭建过程就像盖房子,遵循“先设计图纸、再备料施工、最后验收使用”的逻辑,具体可以分为7个核心阶段:
1. 设计图纸:知识建模与本体设计
这是搭建的第一步,就像盖房子前先画好户型图。我们要先明确:这张知识图谱是给哪个领域用的(比如医学、金融、电商)?需要包含哪些核心实体(比如医学里的“疾病”“症状”“药物”)?实体之间有哪些关键关系(比如“疾病-症状”“药物-适应症”)?
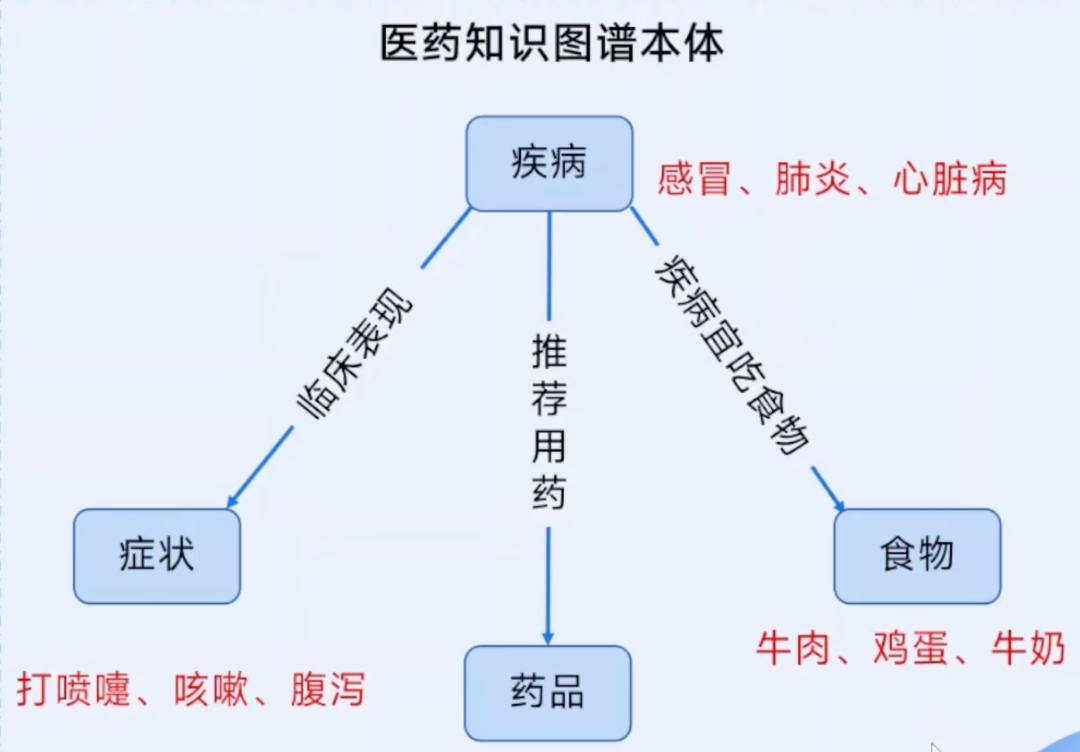
常见的设计模式有两种:如果是成熟领域(比如金融风控),就用“自顶向下”模式,先确定整体框架再填细节;如果是探索性领域(比如新兴技术研究),就用“自底向上”模式,从现有数据中归纳规律。比如金融风控图谱的核心实体就包括企业、股东、高管,核心关系有“持股”“担保”“任职”等。
2. 备料清洗:数据获取与预处理
图纸画好后,就要收集“建筑材料”——数据。

这些数据来源很广,既有企业工商信息、财报这样的结构化数据,也有招股说明书、网页这样的半结构化数据,还有裁判文书、论文这样的非结构化数据。
收集来的数据往往很“脏”,比如日期格式不统一(“2023/01/01”和“2023-01-01”)、存在缺失值(空的股东名单),这一步就要做清洗:统一格式、填补缺失、剔除错误数据,保证数据的准确可靠。
3. 拆解零件:知识抽取
清洗好的数据,需要拆解出“三元组积木”——这就是知识抽取。
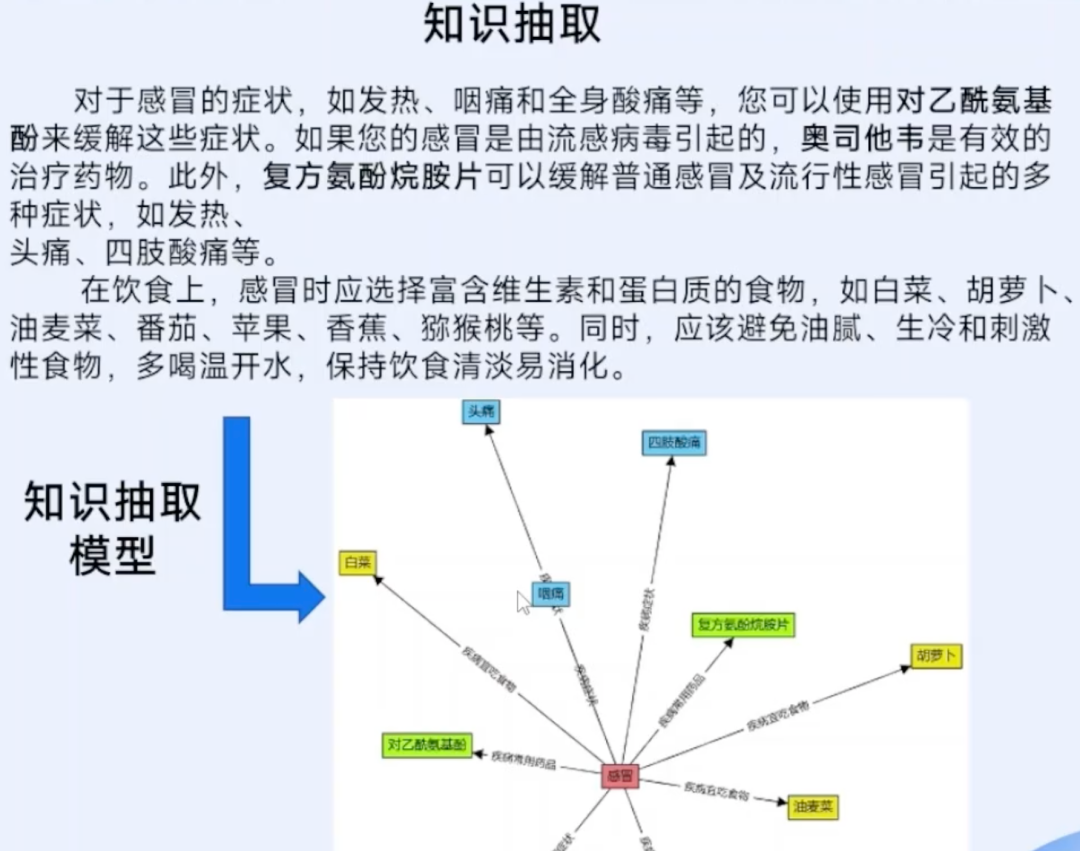
具体要做三件事:抽取实体(比如从文本中找出“蜀天梦图”“张三”这样的节点)、抽取关系(比如“蜀天梦图-创始人-张三”)、抽取属性(比如企业的“注册资本”、个人的“任职履历”)。这一步就像从一堆原材料里挑选出可用的零件,为后续组装做准备。
4. 组装调试:知识融合
不同来源的数据可能存在重复或矛盾:比如同一个企业,有的数据写“蜀天梦图”,有的写“蜀天梦图数据科技有限公司”;有的来源说某企业注册资本1000万,有的说2000万;比如毛毛虫、黄油弹、黄油/润滑脂均指同一种产品:一种用于机械设备润滑的半固态油脂,通常包装在波纹状金属或塑料管中,可直接装入黄油枪使用。
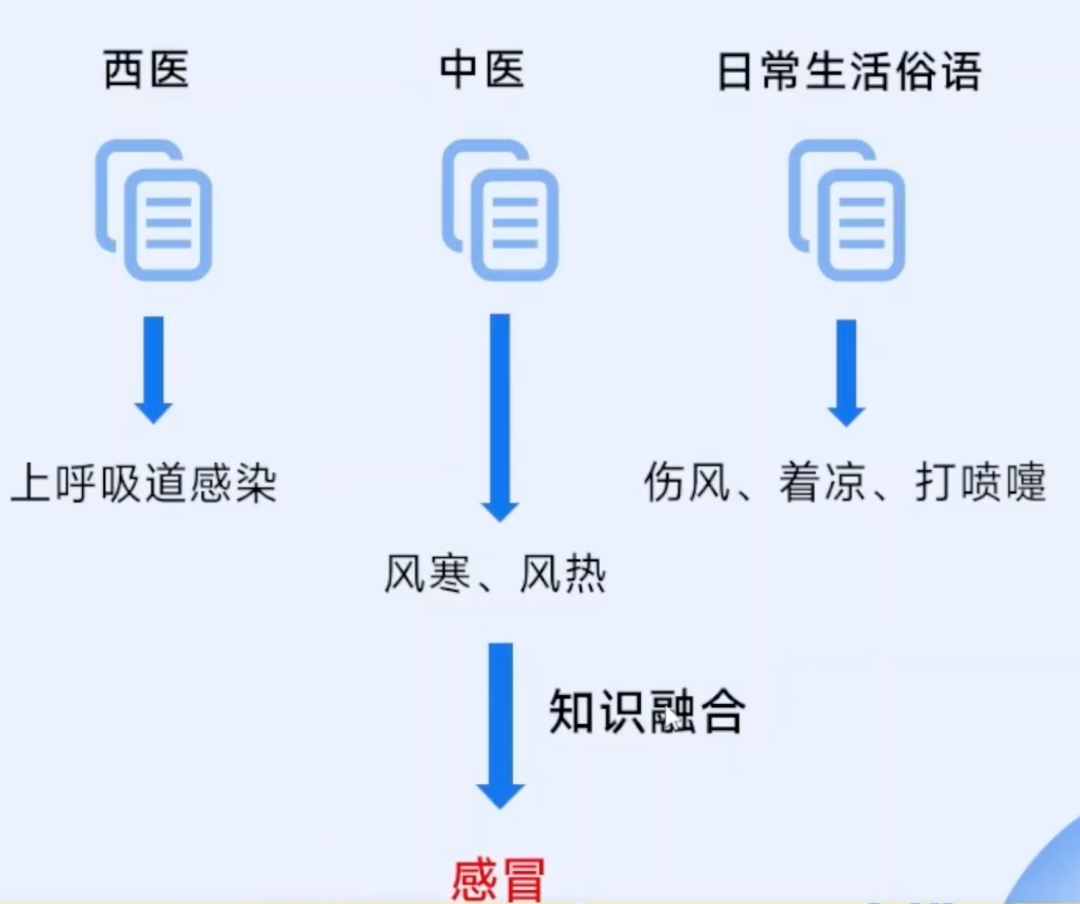
知识融合就是解决这些问题:合并重复实体(实体对齐)、解决矛盾数据(语义消歧),让“零件”能精准组装在一起。
5. 入库保存:知识存储
组装好的知识不能随便放,需要专门的“仓库”——图数据库(比如GDMBASE、neo4j)。
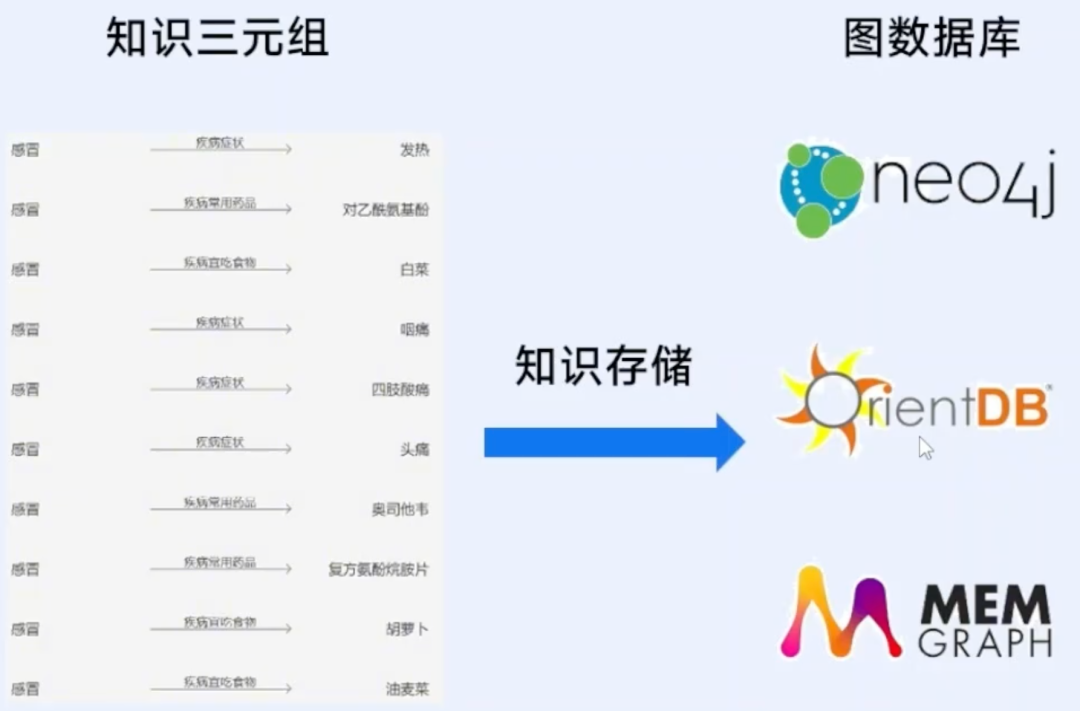
和传统数据库不同,图数据库擅长存储和查询网状的关系数据,能快速找到实体之间的关联路径,比如“A企业-持股-B企业-担保-C企业”这样的复杂关系,为后续使用提供高效支持。
6. 质检优化:知识加工
入库后还要做“质检”和“升级”:一方面通过知识推理补全缺失的关系(比如知道“A是B的上司”,就能推理出“B是A的下属”);另一方面做质量评估,检查知识的准确性和一致性,确保没有逻辑矛盾。这一步就像给房子做竣工验收,保证知识图谱的可靠性。
7. 投入使用:知识应用
经过前面6步,知识图谱终于可以“上岗”了。
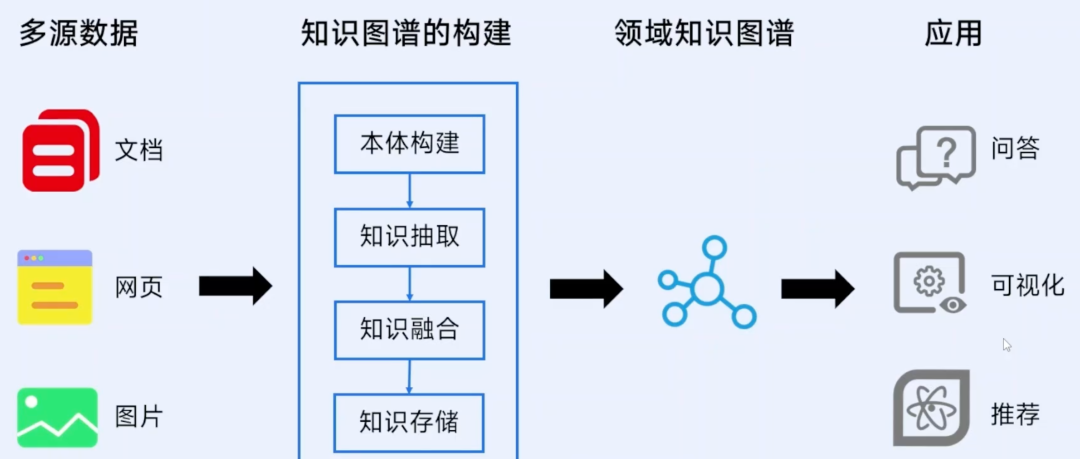
它的应用场景非常广泛:比如构建领域知识库(医学手册、金融风控指南)、多跳查询(顺藤摸瓜找企业间的隐藏关联)、可视化分析(让复杂关系一目了然),还有最热门的——助力大模型优化性能。
知识图谱讲到这,已经有个大概了解了,那与大模型是什么关系呢?

三、知识图谱与大模型:天生一对的“智能搭档”
为什么现在提到大模型,总少不了知识图谱?因为它们是互补的“智能搭档”——各自有优势,结合起来能让AI更聪明、更可靠。
先看两者的核心差异:大模型擅长理解语言、泛化能力强,能读懂海量文本,但容易“说胡话”(产生幻觉),而且推理过程像“黑箱”,没法解释;知识图谱擅长结构化组织知识,信息准确可验证,推理过程透明,但不擅长理解自然语言、泛化能力弱。
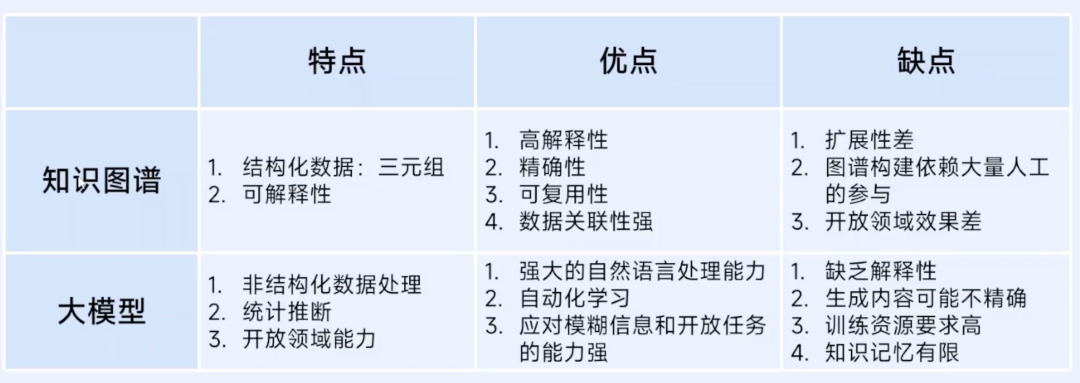
如果说知识图谱是逻辑严谨的理科状元,那么大模型,就是一个才华横溢的文科天才。
它们的互补性主要体现在两个方面:
1. 知识图谱帮大模型“少犯错、能解释”
大模型的“幻觉”问题,本质是缺乏准确的结构化知识支撑。知识图谱可以作为“权威知识库”,为大模型提供可验证的事实依据——比如大模型回答“感冒该吃什么药”时,会从医学知识图谱中调取准确的“疾病-药物”关联,避免乱推荐药物。同时,知识图谱的网状结构能让大模型的推理过程可视化,比如解释“为什么推荐这款药”时,能展示“感冒-症状-药物适应症”的关联路径,让黑箱推理变透明。
2. 大模型帮知识图谱“提效率、扩边界”
传统知识图谱构建需要大量人工,效率低。大模型擅长理解非结构化文本,能自动从新闻、论文、报告中抽取实体和关系,大幅提升图谱构建效率;而且大模型具备常识知识,能帮知识图谱补全缺失的关系——比如从“张三是李四的父亲”推理出“李四是张三的子女”,让知识图谱更完整。

现在热门的GraphRAG技术,就是两者深度融合的代表:把知识图谱的结构化知识融入大模型的检索和生成过程,既保证回答的准确性,又提升大模型处理复杂任务的能力。
结语:不止于连接,更是AI的“认知基石”
从1960年代的语义网络起源,到2012年谷歌正式提出“知识图谱”概念,再到如今与大模型深度融合,知识图谱的核心价值始终没变——让机器像人类一样理解知识的关联。它不是枯燥的蜘蛛网,而是AI世界的“认知导航仪”,把零散的信息编织成有序的知识,让智能系统更懂世界、更可靠。
知识图谱的本质是“关联”,搭建的关键是“把复杂流程拆成简单步骤”,而与大模型的结合则是未来的核心方向。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号