手搓484行代码是如何做到用普通CPU训练,耗时还不到20分钟就完成一个3.37M中文GPT模型?回答的效果还不错!一文讲清楚,30分钟轻松复刻

手搓484行代码是如何做到用普通CPU训练,耗时还不到20分钟就完成一个3.37M中文GPT模型?回答的效果还不错!一文讲清楚,30分钟轻松复刻

烟雨平生
发布于 2026-04-14 18:34:45
发布于 2026-04-14 18:34:45
对AI很感兴趣,一直在持续学习,从书本上学,从论文上学,从B站上学,从极客时间上学,从实践中学。为了将晦涩的理论转化为直观的工程触感,就搞一次略带“整活”性质的实践。希望通过从零“手搓”的方式,在满足工程师好奇心的同时,帮助大家打破对大模型的神秘感,真正理解其底层的运行机制与实现原理。
先整体感觉一下训练GPT模型的过程,心中有个概念有个框架,聊到细节时不迷路:

图片
输入样本从“特征文本 → 分词ID → 批次张量 → 嵌入[Embedding] → 注意力/前馈 → 归一化 → 线性输出 → logits”。训练在logits上计算交叉熵损失并反向传播;推理在logits上采样生成下一个token。

logits,字的分数、权重

图片
- 个人非科班的业余爱好者,靠各种碎片信息修炼的邪修,可能会对一些术语没有展开讲,请见谅,可以留言交流。
- 适应人群: 对于智商超群的算法同学来说可能有些简单,但对终日加班,目光涣散的开发苦哥们来说刚刚好。
一、为什么要 “手搓” 一个中文 GPT?
当我们谈论大模型时,总会被 “千亿参数”“千卡训练”“百万级GPU小时” 这些词吓退——仿佛训练一个能干活的GPT,是只有大厂才玩得起的游戏。
但真的是这样吗?
最近手搓484行代码,在一台普通办公电脑(i7 CPU,16G 内存)上

花了19分47秒(1186.95秒)训练出了一个 3.37M 参数的中文 GPT 模型。它能回答简单的问题,能续写句子,甚至能理解 “用户:xxx\n 助手:xxx” 的对话格式。
这个过程没有用任何GPU,没有依赖复杂框架
所有代码都是 “手搓” 的极简实现。这篇文章就拆解一下:如何让训练中文GPT这件事,从 “遥不可及” 变成 “人人可做”。
二、核心成果:小而美的 3.37M 模型
先直接上结果,让大家有个直观感受:

- 模型规模3.37M参数(n_layer=4, n_head=4, n_embd=256),比很多开源模型小1000 倍以上;
- 训练耗时1186.95 秒(约 19.78 分钟),普通 CPU 全程跑完,中间还能正常用电脑办公;
- 功能效果支持中文问答、文本续写,能理解基础指令(比如 “解释什么是 GPT”);
- 代码量484 行(含模型定义、数据处理、训练全流程),没有冗余逻辑,新手也能看懂。
这个模型的仓库在GitHub:GPT_teacher-3.37M-cn,所有代码和训练数据模板都已开源(MIT 协议),拉下来就能复刻。仓库完整地址见文末。
三、技术拆解:让 CPU 能扛住训练的 4 个关键技巧
训练大模型的本质是 “算力、数据、模型” 的平衡。在CPU上训练,核心是 “做减法”—— 用最小的资源实现核心功能。
1. 模型架构:砍到不能再砍的 “迷你 GPT”
大模型的参数主要集中在 Transformer 层,我们直接把 “骨架” 压缩到极限:
- 层数与头数4 层 Transformer(n_layer=4),每层4个注意力头(n_head=4),比 GPT-2 的12层12头精简75%;
- 嵌入维度256 维(n_embd=256),仅为GPT-2(768 维)的1/3;
- 序列长度128 tokens(seq_len=128),刚好覆盖短句和问答场景。
更关键的是,模型实现用了 “极简主义”:
- 用 RMSNorm 替代 LayerNorm(计算量更少,效果相当);
- 手写 RoPE 位置编码(仅 30 行代码,避免冗余依赖);
- 注意力机制直接用矩阵乘法实现,去掉所有冗余检查。
# 模型核心代码(src/model.py)
class GPT(nn.Module):
def __init__(self, vocab_size, n_layer, n_head, n_embd, seq_len, dropout):
super().__init__()
self.seq_len = seq_len
self.tok_emb = nn.Embedding(vocab_size, n_embd) # 词嵌入
self.blocks = nn.ModuleList([Block(n_embd, n_head, dropout) for _ in range(n_layer)]) # Transformer层
self.norm = RMSNorm(n_embd) # 简化版归一化
self.head = nn.Linear(n_embd, vocab_size, bias=False) # 输出层(共享词嵌入权重)
def forward(self, idx):
x = self.tok_emb(idx) # 词嵌入
mask = torch.tril(torch.ones(T, T, device=idx.device)).unsqueeze(0).unsqueeze(0) # 下三角掩码
for blk in self.blocks:
x = blk(x, mask) # 过Transformer层
x = self.norm(x)
return self.head(x) # 输出logits这样的模型,单批次计算量只有标准GPT-2的1/1000,CPU完全能扛住。
2. 数据与词表:小而精的 “中文适配”
中文训练的一大痛点是 “词表大”,但我们用两个技巧解决:
- 小词表 BPE用 Hugging Face 的tokenizers库训练2048大小的词表(默认配置)
覆盖常用中文词汇和指令格式(“用户:”“助手:”);
- 数据格式精简: 训练数据用 JSONL 格式,每行一条 “prompt+completion”,比如:
{"prompt": "什么是人工智能?", "completion": "人工智能是研究如何让机器模拟人类智能的技术。"}- 长度控制超过 128 tokens 的样本直接截断,避免冗余计算。
词表和数据处理加起来不到 80 行代码(src/data.py + src/build_tokenizer.py),但能高效喂饱小模型。
3. 训练策略:CPU 友好的 “梯度累积”
普通CPU的内存有限,直接跑大批次会OOM。我们用 “梯度累积” 模拟大批次:
- 实际 batch_size=16,但每次只算 4 个样本(micro_batch=4);
- 每算 4 次(16/4=4)就更新一次参数,等价于 batch_size=16 的效果;
- 学习率用 “线性预热 + 余弦退火”:前 5 步慢慢升到 0.0003,之后逐渐下降,避免震荡。
# 训练循环核心(src/train.py)
accum = 0 # 累积计数器
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
logits = model(xb) #
loss = loss_fn(logits.view(-1, logits.size(-1)), yb.view(-1)) #计算损失loss
loss.backward() # 累积梯度
accum += 1
if accum == bs // mb: # 累积到等效batch_size
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪
opt.step() # 更新参数
opt.zero_grad()
sched.step() # 调整学习率
accum = 0这套策略让CPU内存占用控制在8G以内,16G内存的电脑完全能跑。
GPT都是Decoder-only Transformer,先看架构图有个概念有个感觉,看代码时不迷路:
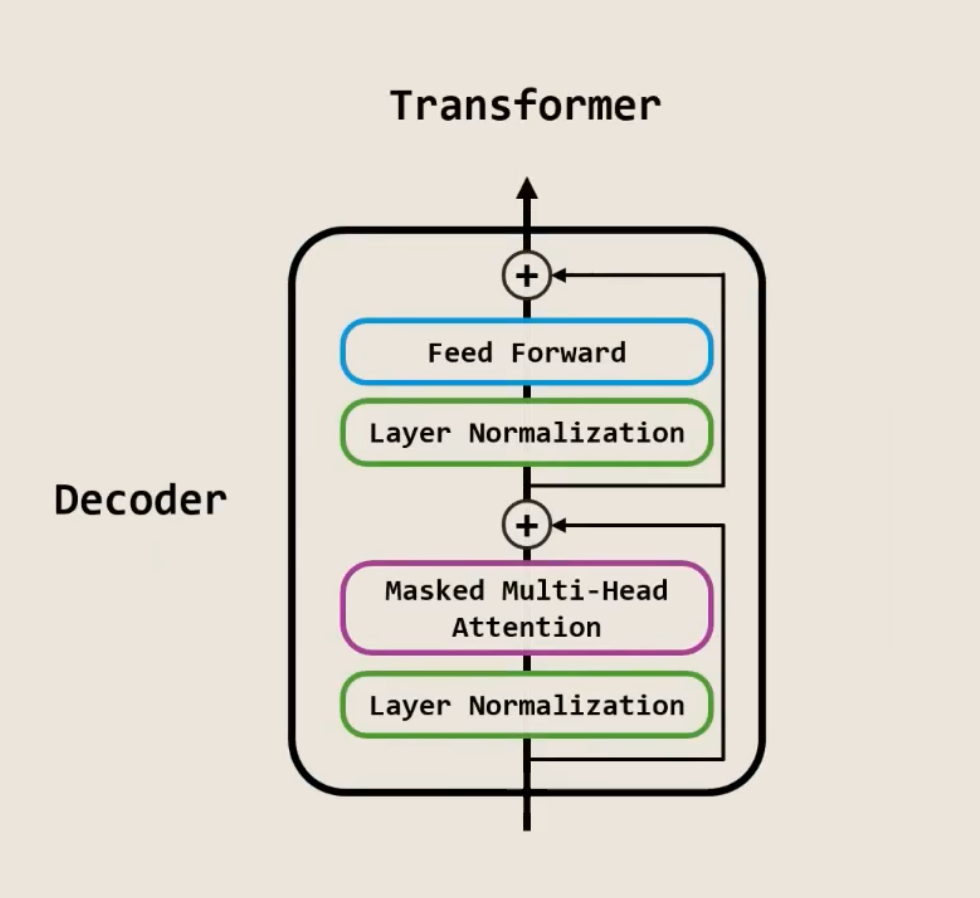
从GPT模型的输入开始,一步步看它如何流过代码,并对应到图上。
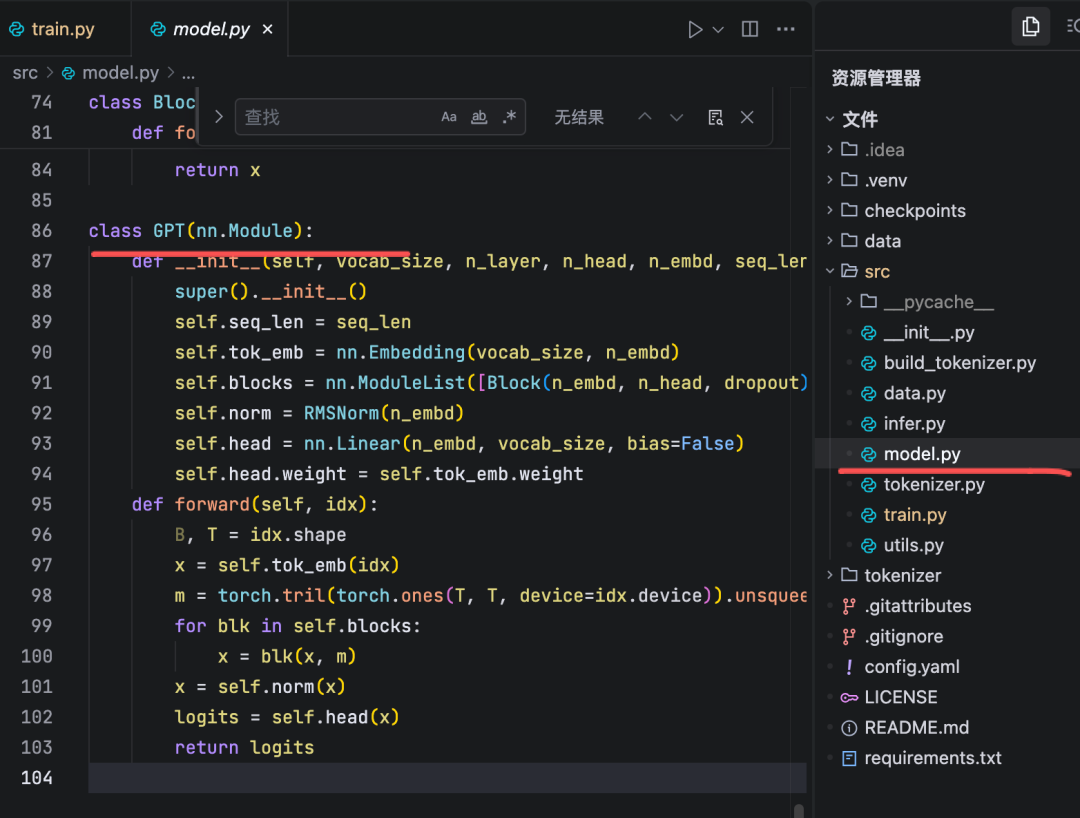
假设输入是 idx,一个形状为 (Batch_Size, Sequence_Length) 的张量。
a. GPT.forward - 模型入口
def forward(self, idx):
B, T = idx.shape
# 1. 词嵌入 (Token Embedding)
x = self.tok_emb(idx)
# 对应图的最左侧输入。将输入的token ID序列转换为词嵌入向量。
# x 的形状变为 (B, T, n_embd)
# 2. 生成因果掩码 (Causal Mask)
m = torch.tril(torch.ones(T, T, device=idx.device)).unsqueeze(0).unsqueeze(0)
# 这是一个下三角矩阵,用于在自注意力计算中“遮蔽”未来的token,确保模型在预测第i个token时,只能看到前i-1个token。
# 这个掩码 m 会被传递给每个 Block。
# 3. 堆叠的 Decoder 层
for blk in self.blocks:
x = blk(x, m)
# 循环遍历所有的Block。每一次循环,都执行一次完整的Decoder层计算(即图中的所有步骤)。
# x 是上一层的输出,也是下一层的输入。
# 6. 最终归一化和输出头
x = self.norm(x)
logits = self.head(x)
# 所有Block计算完毕后,进行一次最终的归一化。
# 然后通过一个线性层 `head` 将特征向量映射回词汇表大小,得到最终的预测logits。
# 对应图的最右侧输出。
return logitsb. Block.forward - 核心计算单元 (对应单张图)
现在我们深入到 for blk in self.blocks: 循环内部,看一个Block是如何工作的。
def forward(self, x, mask):
# 4. 第一个子层:多头注意力与残差连接
x = x + self.attn(self.norm1(x), mask)
# 这一行完美对应了图的上半部分:
# a. `self.norm1(x)`: Layer Normalization (使用RMSNorm)。对应图中第一个Add & Norm左侧的Norm。
# b. `self.attn(..., mask)`: Masked Multi-Head Attention。对应图中的紫色模块。
# c. `x + ...`: Residual Connection (残差连接)。对应图中的第一个Add操作。
# 5. 第二个子层:前馈网络与残差连接
x = x + self.mlp(self.norm2(x))
# 这一行完美对应了图的下半部分:
# a. `self.norm2(x)`: Layer Normalization (使用RMSNorm)。对应图中第二个Add & Norm左侧的Norm。
# b. `self.mlp(...)`: Feed-Forward Network (前馈网络)。对应图中的蓝色模块。
# c. `x + ...`: Residual Connection (残差连接)。对应图中的第二个Add操作。
return xc. SelfAttention.forward - 注意力机制详解
这是图中紫色模块 Masked Multi-Head Attention 的具体实现。
def forward(self, x, mask):
# ... (形状定义)
# 1. 生成 Q, K, V
qkv = self.qkv(x)
q, k, v = qkv.split(C, dim=-1)
# 通过一个线性层一次性生成查询(Q), 键(K), 值(V)。
# 2. 拆分多头
q = q.view(B, T, h, self.head_dim).transpose(1, 2)
k = k.view(B, T, h, self.head_dim).transpose(1, 2)
v = v.view(B, T, h, self.head_dim).transpose(1, 2)
# 将 Q, K, V 张量拆分成多个头,并调整维度以进行并行计算。
# 3. 应用旋转位置编码 (RoPE)
q, k = rope(q, k, T, self.head_dim, x.device)
# 这是你的代码中一个重要的细节。它没有使用单独的位置嵌入层,而是采用了旋转位置编码。
# 它将位置信息直接编码到 Q 和 K 的向量中,这是现代LLaMA等模型常用的方法。
# 这一步对应了图中输入到注意力层之前隐含的“位置编码”步骤。
# 4. 计算注意力分数并应用掩码
att = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
att = att.masked_fill(mask == 0, float("-inf"))
# 计算缩放点积注意力分数,并应用之前生成的因果掩码,将未来token的注意力分数设为负无穷。
# 5. Softmax 和 Dropout
att = F.softmax(att, dim=-1)
att = self.drop(att)
# 将注意力分数归一化为概率分布。
# 6. 加权求和与输出投影
y = att @ v
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.proj(y)
y = self.drop(y)
# 将注意力权重应用到V上,然后将所有头的输出拼接起来,并通过一个最终的线性层(Projection)得到注意力子层的输出。最后,从train的视角整体梳理一遍训练GPT的流程:
'''train方法整合了数据加载、模型构建、梯度累积、学习率调度(预热 + 余弦退火)、梯度裁剪、定期验证与保存,以及最终的模型量化等一系列关键技术,遵循了现代深度学习训练的最佳实践'''
def train(device_arg: str | None = None):
# 1. 加载配置
cfg = load_config("config.yaml")
# 2. 设置随机种子以保证结果可复现
set_seed(cfg["training"]["seed"])
# 3. 设置PyTorch的线程数
torch.set_num_threads(num_threads())
# 4. 构建数据集和Tokenizer
tok, train_ds, val_ds = build_datasets(cfg)
# 5. 从配置中获取模型参数
seq_len = cfg["model"]["seq_len"]
# 6. 初始化GPT模型
model = GPT(
vocab_size=tok.vocab_size,
n_layer=cfg["model"]["n_layer"],
n_head=cfg["model"]["n_head"],
n_embd=cfg["model"]["n_embd"],
seq_len=seq_len,
dropout=cfg["model"]["dropout"],
)
# 7. 确定并设置训练设备 (CPU/GPU)
device = get_device(device_arg)
model.to(device)
# 8. 设置批处理大小和微批处理大小(用于梯度累积)
bs = cfg["training"]["batch_size"]
mb = cfg["training"]["micro_batch"]
# 9. 创建DataLoader,用于高效加载数据
train_loader = DataLoader(
train_ds,
batch_size=mb,
shuffle=True,
num_workers=0,
collate_fn=lambda b: collate(b, seq_len, tok.pad_id),
)
# ... val_loader 类似 ...
# 10. 定义优化器,用来更新梯度
opt = torch.optim.AdamW(
model.parameters(),
lr=cfg["training"]["lr"],
weight_decay=cfg["training"]["weight_decay"],
)
# 11. 定义学习率调度器 (Warmup + Cosine Annealing)
total_steps = cfg["training"]["max_steps"]
warmup = cfg["training"]["warmup_steps"]
def lr_lambda(step):
if step < warmup:
return step / max(1, warmup) # 线性预热
t = (step - warmup) / max(1, total_steps - warmup)
return 0.5 * (1 + math.cos(math.pi * t)) # 余弦退火
sched = torch.optim.lr_scheduler.LambdaLR(opt, lr_lambda)
# 12. 定义损失函数
loss_fn = nn.CrossEntropyLoss(ignore_index=-100)
# 13. 创建保存目录
save_dir = cfg["training"]["save_dir"]
ensure_dir(save_dir)
step = 0
accum = 0
model.train() # 设置模型为训练模式
start_time = time.time()
# 14. 循环直到达到总步数
while step < total_steps:
# 15. 遍历训练数据
for xb, yb in train_loader:
xb = xb.to(device)
yb = yb.to(device)
# 前向传播,logits张量是模型对输入 xb 进行预测后产生的原始、未归一化的分数
logits = model(xb) # 触发一次完整的前向传播
loss = loss_fn(logits.view(-1, logits.size(-1)), yb.view(-1)) # logits用计算损失
# 反向传播,计算梯度
loss.backward()
accum += 1 #梯度累积
# 16. 当梯度累积到一定次数后,更新参数
if accum == bs // mb:
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
opt.step() # 梯度更新,更新权重
opt.zero_grad() # 清零梯度,为下一次累积做准备
sched.step() # 更新学习率,驱动整个学习率策略(从预热到衰减)的 “引擎”
step += 1
accum = 0
# 17. 定期打印训练信息
if step % 10 == 0:
print(f"step {step} loss {loss.item():.4f} lr {sched.get_last_lr()[0]:.6f}")
# 18. 定期进行验证和保存
if step % cfg["training"]["eval_interval"] == 0:
eval_loss = evaluate(model, val_loader, loss_fn, device)
# ... 打印并保存模型 ...
torch.save({"model": model.state_dict(), "cfg": cfg}, os.path.join(save_dir, "last.pt"))
if step >= total_steps:
breaksrc.train.train方法整合了数据加载、模型构建、梯度累积、学习率调度(预热 + 余弦退火)、梯度裁剪、定期验证与保存,以及最终的模型量化等一系列关键技术,遵循了现代深度学习训练的最佳实践
4. 硬件优化:榨干 CPU 性能
最后一步是 “细节调优”,让 CPU 跑满算力:
- 线程控制:
torch.set_num_threads(os.cpu_count()),让 PyTorch 用满所有 CPU 核心; - 禁用多进程:DataLoader 的 num_workers=0(尤其 macOS 上,多进程会拖慢速度);
- 训练后量化:导出模型时用
torch.quantization.quantize_dynamic转为 int8,推理速度翻倍,内存占用减半。
四、实战步骤:3 步跑通训练全流程
只要你会用命令行,跟着这 3 步就能复现:
1. 准备环境
先安装依赖(Python 3.11.10):
pip install -r requirements.txt
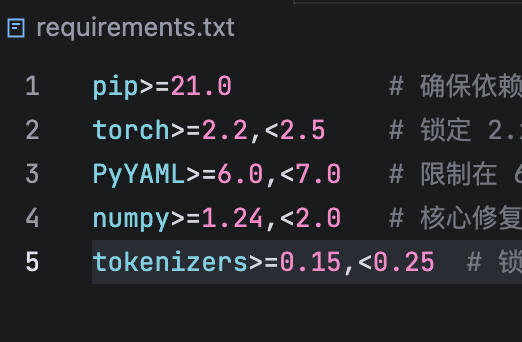
# 依赖很轻量:torch>=2.2、PyYAML、tokenizers,没有其他花里胡哨的库2. 准备数据和词表
- 把训练数据放到
data/train.jsonl,验证数据放到data/val.jsonl(仓库里有示例); - 生成词表:
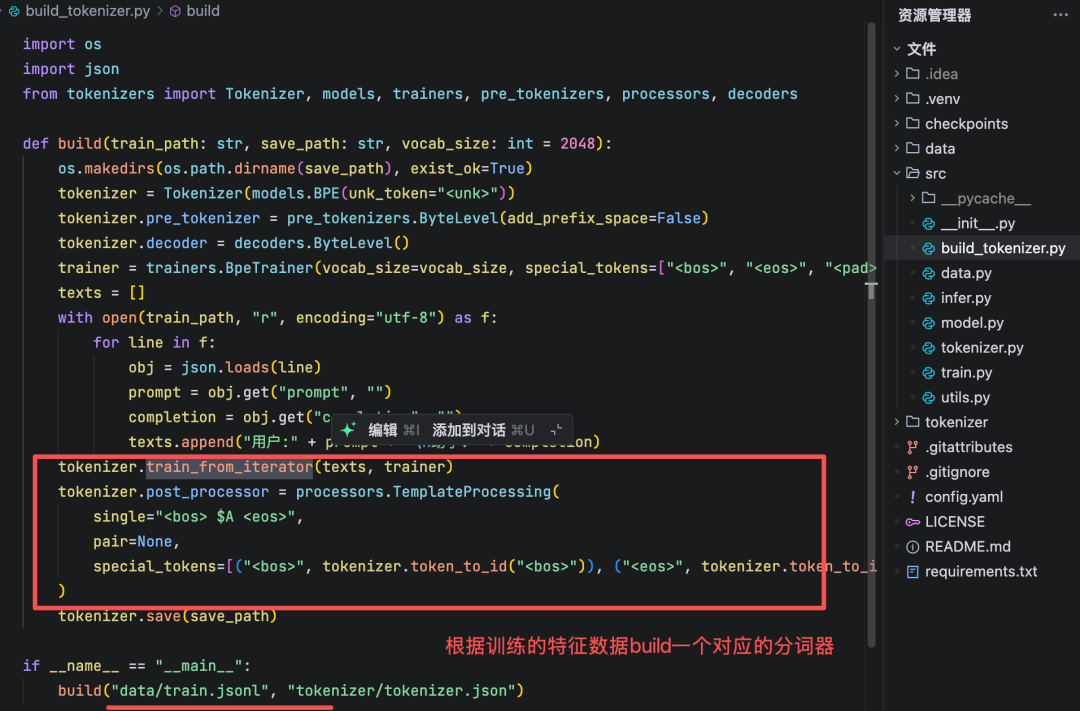
python -m src.build_tokenizer
# 会在tokenizer/目录生成tokenizer.json(2048词表)3. 启动训练
直接用 CPU 训练,不加参数--device cpu会优先使用GPU训练。消费级显卡X5060需要不到60s:
python -m src.train --device cpu训练过程会实时输出 loss:
step 10 loss 5.2314 lr 0.000060
step 20 loss 4.8921 lr 0.000120
...
eval loss 3.2105 elapsed 600.2s # 每20步验证一次
...17分钟后,checkpoints/目录会生成两个模型:
last.pt :完整精度模型。FP32,(32 位浮点数)精度;quantized.pt:量化后的轻量模型(推理用这个更快)。INT8(8 位整数)精度。
五、效果演示:小模型能做什么?
虽然只有 3.37M 参数,但模型已经能处理基础任务:
- 问答示例:

GPT_teacher-3.37M-cn % python -m src.infer --prompt "什么是注意力机制?" --show_label
回答:注意力通过分配权重让模型重点参考关键位置,提升对序列关系的理解。
GPT_teacher-3.37M-cn % python -m src.infer --prompt "解释蒸馏水与纯水区别?" --show_label
回答:蒸馏水是通过蒸馏获得的水,去除了大部分杂质;纯水是指杂质含量极低的水,制备方式可以是蒸馏、反渗透等。- 续写示例:

% python -m src.infer --prompt "RoPE的作用是" --show_label
回答:RoP把相对位置信息注入注意力,保留位序关系且高效。
效果不算惊艳,但作为 “从 0 到 1” 的成果,已经能体现 GPT 的核心逻辑 —— 用自注意力捕捉上下文关系。六、总结:训练自由,从 “能跑” 开始
这个3.37M中文GPT的意义,不在于性能多强,而在于证明:训练大模型不是 “贵族游戏”。
484行代码、普通CPU、20分钟,这些数字背后是“简化”的智慧 —— 去掉冗余功能,聚焦核心逻辑,让更多人能亲手触摸大模型的训练过程。
如果你也想入门大模型训练,不妨从这个仓库开始:跑通流程,改改参数,看看loss变化,这种“亲手创造”的体验,比读100篇论文更实在。不仅要读万卷书,也行万里路。
最后放个仓库地址:https://github.com/helloworldtang/GPT_teacher-3.37M-cn,欢迎 star 和叉走尝试~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号