大语言模型训练范式入门课:LLM都是如何训练出来的?干货满满,一文讲清楚!

大语言模型训练范式入门课:LLM都是如何训练出来的?干货满满,一文讲清楚!

烟雨平生
发布于 2026-04-14 18:44:48
发布于 2026-04-14 18:44:48
按下面的思路来聊聊
1、GPT 模型的训练阶段
2、详解Pretrain、SFT、Reward Model、PPO
3、Llama 模型训练方式的差异
LLM都是如何训练出来的?
不同公司采用的训练pipeline还有些差别。
目前业界常见的训练阶段划分如下:
GPT
1、Pretrain
2、SFT(Supervised Fine-Tuning)
3、Reward Model
4、PPO(Proximal Policy Optimization)

Llama
1、Pretrain
2、Reward Model
3、Rejection Sampling
4、SFT(Supervised Fine-Tuning)
5、DPO(Direct Preference Optimization)
PPO(Proximal Policy Optimization,近端策略优化) 和 DPO (Direct Preference Optimization,直接偏好优化) 的核心区别在于训练范式、流程复杂度和适用场景,简单总结如下:
- 核心思想
- PPO:一种强化学习策略梯度算法,通过剪切机制或 KL 惩罚限制新旧策略的差异,避免训练崩溃,需要搭配奖励模型(RM) 和价值网络完成优化。
- DPO:一种简化的大模型对齐方法,跳过奖励模型,直接用人类标注的 “好 / 坏回答对”,通过对比损失让模型偏好优质输出,更接近监督学习范式。
- 训练流程
- PPO:遵循完整 RLHF 三步流程 → 监督微调(SFT)→ 训练奖励模型 → PPO 策略优化,属于 on-policy 算法,需实时采样新数据,历史数据无法复用。
- DPO:两步流程 → 监督微调(SFT)→ 直接用偏好对微调模型,属于 off-policy 算法,偏好数据可重复利用,样本效率更高。
- 成本与难度
- PPO:多模型协同训练,计算/内存成本高,超参敏感(需调剪切系数、KL 权重),工程实现难度大。
- DPO:单模型训练,流程简单,超参少,训练稳定,成本仅为PPO的1/4左右,适合中小团队。
- 适用场景
- PPO:适合复杂任务(如机器人控制、深度大模型对齐),需要强探索能力或细粒度 token 级优化的场景。
- DPO:适合算力有限、偏好数据易获取的场景,如快速验证对齐效果、中小模型的轻量化对齐。
Pretrain,预训练
最大的训练数据集,也是最耗时的步骤
1、不停地阅读大量大量大量的人类文字资料
2、亦步亦趋的学习人类是如何使用文字(一字一字的学习)
3、学习到最多的人类知识,学习到大量的文字表达方式
4、Pretrain阶段一般需要多大的数据量,一般训练一次需要多少算力(花多少钱)
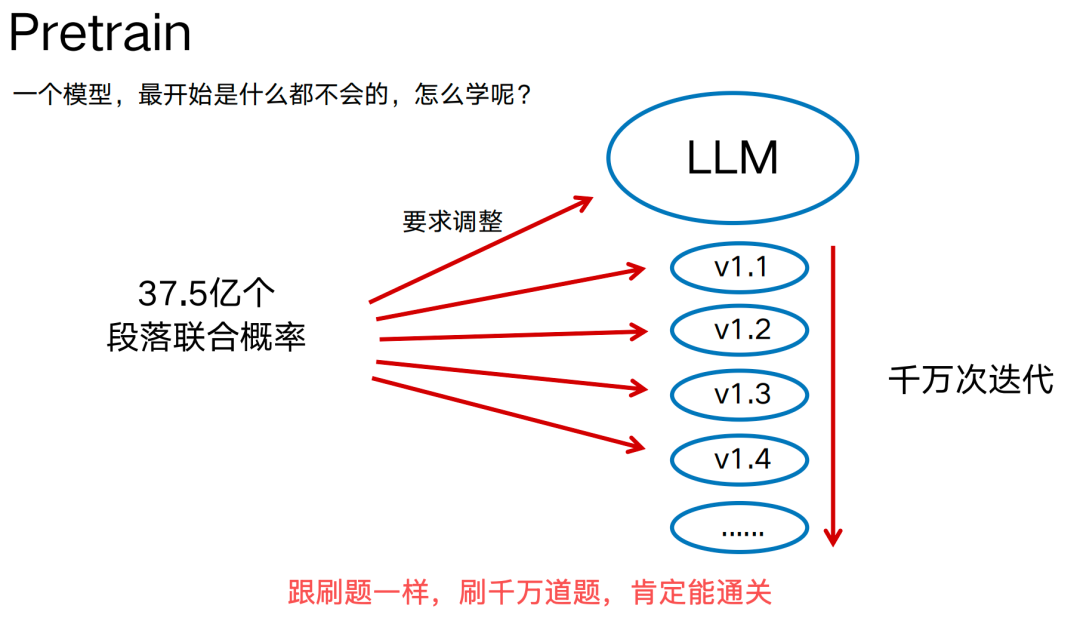
简单的讲,Pretrain就像考试前的刷题,先看做题,再对答案,如果不对,找出错误原因,改变大脑中已有知识,现继续刷,直到所有题的答案与大脑中的知识是一致的。
一个模型,最开始是什么都不会的,怎么学呢?
就跟刷题一样,刚开始大脑中会的知识很少。通过上面的方式刷上几百万道题,大脑中会的知识就很多了。
Pretrain阶段是一定要有的吗?
不一定。如果有海量的高质量的一问一答数据,是不需要Pretrain,直接进入SFT。目前还没有这么多的高质量一问一答数据,现阶段仍然是需要的。
从0到1手搓484行代码,用普通CPU训练一个3.37M中文GPT模型,耗时不到20分钟,回答的效果很不错,欢迎各位老师检查作业
这个中文小模型就是通过提供一批问答数据训练而成的,回答的问题也是对的。感兴趣的同学可以用电脑复刻一下,很快的。
SFT(Supervised Fine-Tuning),有监督的微调训练
1、什么是有监督、无监督
使用有标签的数据进行训练,学习过程叫做有监督学习:
商家送货速度棒棒哒! -> 正向
送货速度可太慢了,差评。 -> 负向
使用无标签的数据进行训练,学习过程叫做无监督学习
2、Pretrain为什么叫自监督,那什么是半监督(Semi-supervised)
上面讲过的Pretrain阶段的处理方式,就叫做自监督
Pretrain + SFT 两个阶段组合起来就叫做半监督(不缺数据,但缺标签)
3、SFT阶段解决什么问题
核心问题:预训练模型(Pretrain)说起话来非常像“接话茬” ,并不是在“做任务”
如果未来你希望做什么类型的任务,就用什么样的数据去做“指令微调(Instruction Tuning)”
对话任务、分类任务、判断任务、推理任务、代码生成任务
Instruction Tuning 是 Fine Tuning 的一种,基本都是使用有监督(Supervised)学习,也就是SFT(Supervised Fine-Tuning)
4、SFT阶段一般用什么样的数据
SFT 阶段的数据量普遍不大
Llama 3 Pretrain阶段使用的数据量:
使用了15t Tokens,15万亿 Tokens
假设,每4000个 Tokens 是一个段落,37.5亿 段落
Llama 3 SFT阶段使用的数据量
大概只有几十万条
大约是预训练阶段的1/5000
至此,我们得到了一个,会做各类任务的模型
尤其是对话任务
核心问题:会做任务,和能优秀的做任务,还是有很大差距。
如何让模型回答得更优秀?要进行step2和step3反复迭代。
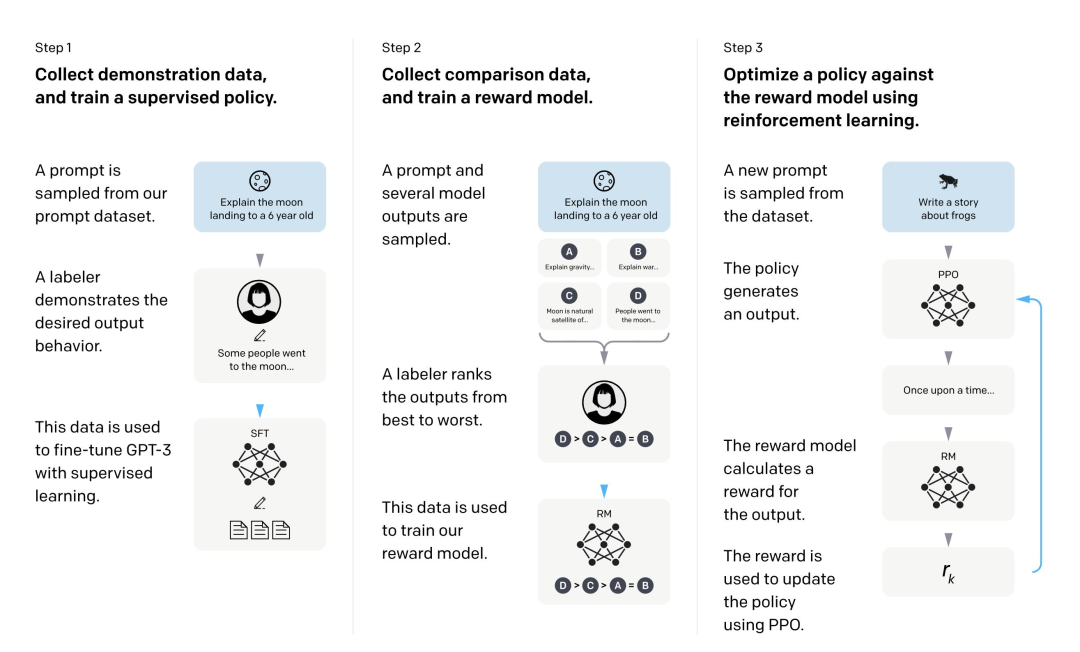
基于 PPO 的经典 RLHF(人类反馈强化学习)三阶段流程
Step 1:收集示范数据,训练监督策略(SFT)
- 目标让模型先学会基础的任务执行能力,生成符合人类基本期望的输出。
- 操作
- 从提示词数据集里采样一个任务(比如 “给 6 岁小孩解释登月”)。
- 让标注者写出符合要求的理想回答(示范数据)。
- 用这些「提示词 + 理想回答」的数据,通过监督学习(SFT)微调大模型(如 GPT-3)。
- 作用为后续的偏好对齐打下基础,让模型具备基本的任务理解和生成能力。
Step 2:收集对比数据,训练奖励模型(RM)
- 目标把人类的主观偏好转化为可量化的奖励信号,让机器能 “理解” 人类觉得什么是好的。
- 操作
- 同样采样一个提示词,让当前模型生成多个不同的回答。
- 让标注者对这些回答从最好到最差排序(比如例子里的 D > C > A = B)。
- 用这些排序后的对比数据,训练一个奖励模型(RM)。
- 作用奖励模型会给任意模型输出打分,分数越高代表越符合人类偏好。
Step 3:用强化学习(PPO)针对奖励模型优化策略
- 目标让模型在和奖励模型的交互中持续优化,生成更符合人类偏好的输出。
- 操作
- 从数据集里采样新的提示词(比如 “写一个关于青蛙的故事”)。
- 让当前策略模型生成回答。
- 用第二步训练好的奖励模型给这个回答打分(得到奖励值 rk)。
- 用 PPO 算法根据奖励值更新策略模型,让模型后续更可能生成高分输出。
- 作用这是 RLHF 的核心对齐阶段,PPO 在这里的作用是稳定地更新策略,避免模型输出突变导致训练崩溃。
Reward Model 是什么?如何与RL配合?
开始使用LLM生成的数据做训练了
评估是一个很难的事情
评估一个模型的整体能力
评估一个问题回答的如何。SFT让模型具备基础的指令遵循能力,为RM和RL提供模型底座。RLHF流程的起点是RM在前,而后续的迭代优化是 RL 生成样本在前、RM更新在后,通过“裁判-选手”的双向迭代,让模型的对齐效果持续提升。
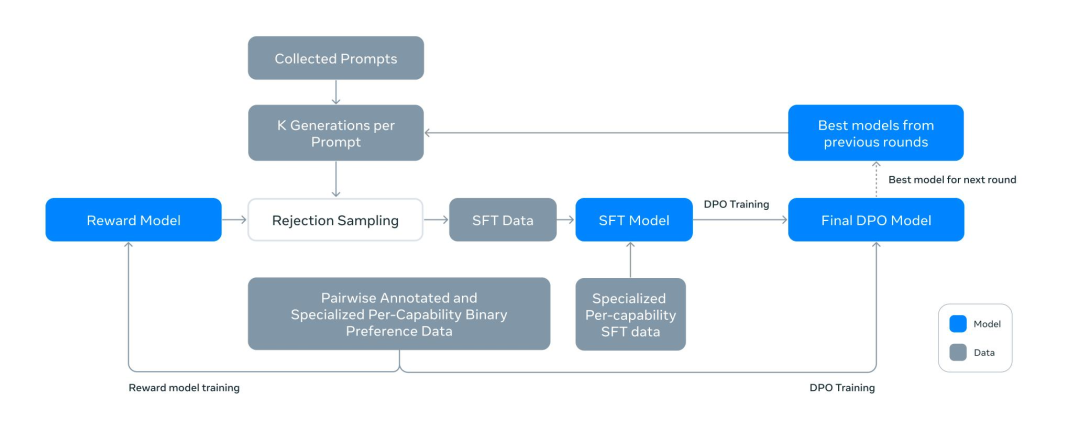
DPO(直接偏好优化)迭代训练流程
DPO(直接偏好优化)是经典 RLHF 的一种优化变体。
图中灰色块代表数据,蓝色块代表模型,整体分为「数据生成与筛选」「模型预训练」「DPO 对齐」「迭代优化」四个环节:
(1)数据生成与筛选
- 输入
- 从 “Collected Prompts”(收集的提示词数据集)中采样任务。
- 生成候选用前几轮得到的 “Best models from previous rounds”(历史最优模型),为每个提示词生成 K 个不同的回答(K Generations per Prompt)。
- 拒绝采样用 “Reward Model”(奖励模型)对 K 个候选回答打分,只保留高分回答,过滤掉低分回答,最终得到高质量的 “SFT Data”(监督微调数据)。
- 注:这里的奖励模型是用成对标注的偏好数据(Pairwise Annotated and Specialized Per-Capability Binary Preference Data)训练的,仅用于筛选数据,而非后续对齐的核心。
(2)监督微调(SFT)
- 用筛选后的 “SFT Data”,加上 “Specialized Per-capability SFT data”(特定能力的 SFT 数据),共同训练 “SFT Model”。
- 这一步的目标是让模型先具备基础的任务执行能力,同时通过高质量数据打下偏好对齐的基础。
(3)DPO 偏好对齐
- 训练好的 “SFT Model” 进入 “DPO Training” 阶段,直接用成对标注的偏好数据(和训练奖励模型的是同一批数据)进行优化。
- DPO 会通过对比损失让模型直接学习 “好回答” 与 “坏回答” 的差异,无需依赖奖励模型的打分,最终得到 “Final DPO Model”。
(4)迭代优化
- “Final DPO Model” 会被评估,成为下一轮的 “Best models from previous rounds”,回到 “生成候选” 环节继续迭代。
- 这种闭环设计能让模型的输出质量随轮次持续提升。
这张图完整展示了 GPT 类大模型从基础能力到人类对齐的四阶段训练流水线,是 OpenAI 前核心成员 Andrej Karpathy 在《State of GPT》演讲中的经典总结。
1. 预训练(Pretraining)
- 数据集万亿级互联网原始文本(低质量、超大数量)
- 核心算法语言建模(预测下一个 Token)
- 输出模型基础大模型(如 GPT、LLaMA、PaLM)
- 关键特点需要数千块 GPU 训练数月,目标是让模型掌握通用语言能力和世界知识,训练完成后即可作为基础模型部署。
2. 监督微调(Supervised Finetuning, SFT)
- 数据集人工标注的理想助手回复(10-100K 条,高质量、小数量)
- 核心算法语言建模(预测下一个 Token)
- 输出模型SFT 模型(从基础模型初始化,如 Vicuna-13B)
- 关键特点用 1-100 块 GPU 训练数天,目标是让模型学会遵循指令、生成符合人类基本期望的输出,训练完成后可直接部署。
3. 奖励建模(Reward Modeling, RM)
- 数据集人工标注的回答偏好对比(100K 条,高质量、小数量)
- 核心算法二分类任务(预测与人类偏好一致的奖励分数)
- 输出模型奖励模型(RM,从 SFT 模型初始化)
- 关键特点用 1-100 块 GPU 训练数天,目标是把人类的主观偏好转化为可量化的奖励信号,为后续强化学习提供依据。
4. 强化学习(Reinforcement Learning, RL)
- 数据集人工编写的提示词(10-10K 条,高质量、小数量)
- 核心算法强化学习(通常用 PPO,生成 Token 以最大化奖励模型的打分)
- 输出模型RL 模型(从 SFT 模型初始化,如 ChatGPT、Claude)
- 关键特点用 1-100 块 GPU 训练数天,目标是让模型在与奖励模型的交互中持续优化,生成更符合人类偏好的输出。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号