Transformer灵魂1问系列:为什么Transformer架构中没有看到前向传播、计算Loss?

Transformer灵魂1问系列:为什么Transformer架构中没有看到前向传播、计算Loss?

烟雨平生
发布于 2026-04-14 18:47:31
发布于 2026-04-14 18:47:31
训练一个大模型的流程是这样的:
Tokenization → Embedding → 位置编码→ 前向传播 → 计算Loss → 反向传播→ 梯度裁剪/正则化 → 梯度下降 → 梯度更新
But,你在Transformer架构中有看到前向传播?有看到计算Loss?有看到反向传播?吗?
大家都知道Transformer架构的并行训练直接催生以算力换智力的ChatGPT,吹响了训练LLM的号角。现在LLM能遍地开花,并持续融入和改变大家的生活Transformer架构厥功至伟,功不可没。
可为什么上面这些训练流程中,在Transformer架构中,除了前两个
词元化(Tokenization)和 Token向量化(Embedding)还有位置编码,其它都没有看到!!!
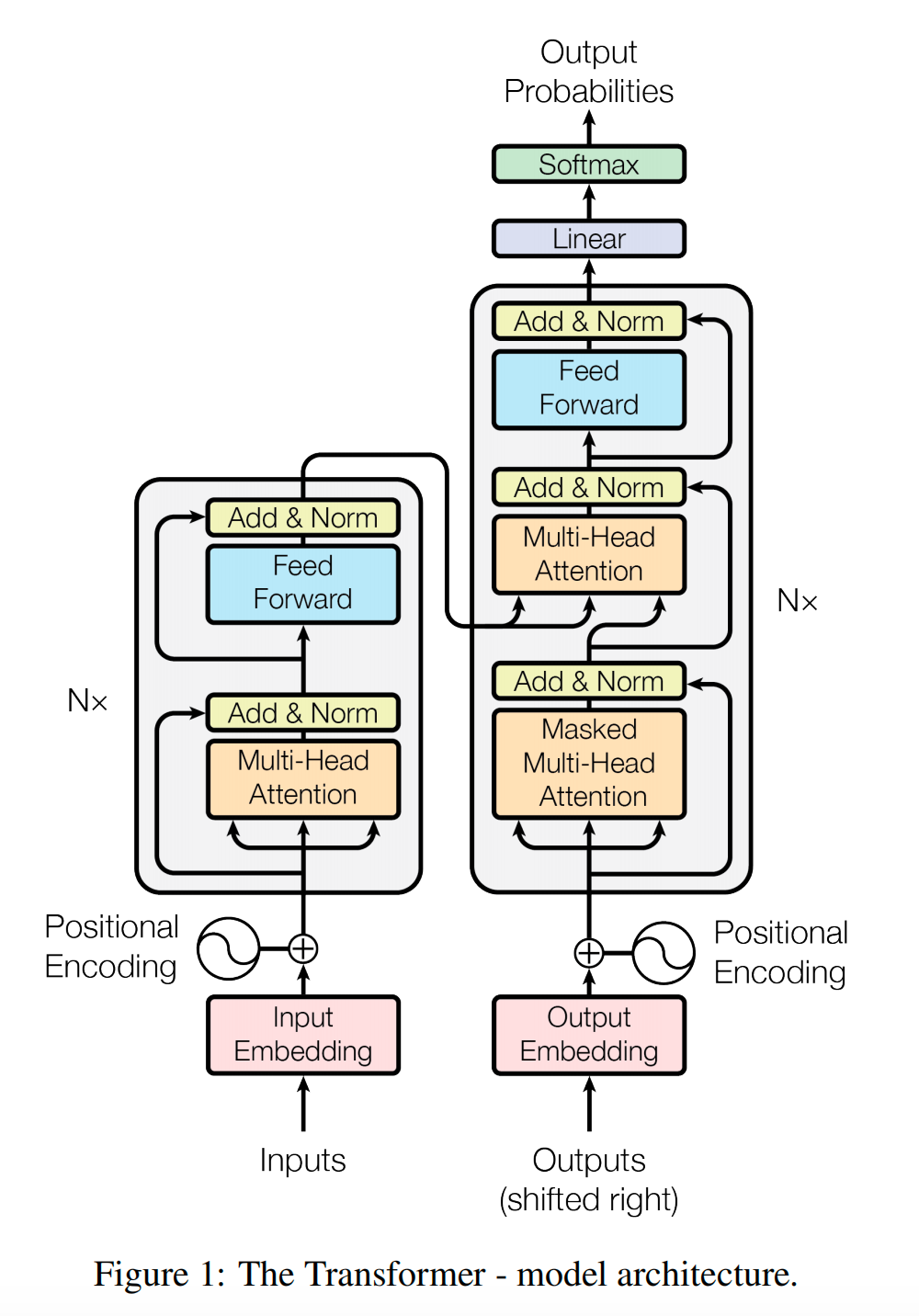
为什么呢?
前向传播、计算Loss 、反向传播 、梯度裁剪/正则化 、梯度下降 、梯度更新 这些动作都跑哪去了呢?
Transformer架构的核心层(自注意力 + FFN + 残差 & 归一化) = 大模型训练流程中的“前向传播”的核心计算部分。
更精确地说,“前向传播” 这个步骤,指的就是输入嵌入向量后,数据依次流过Transformer所有核心层,直到最终输出logits(未归一化的预测分数)的整个过程。
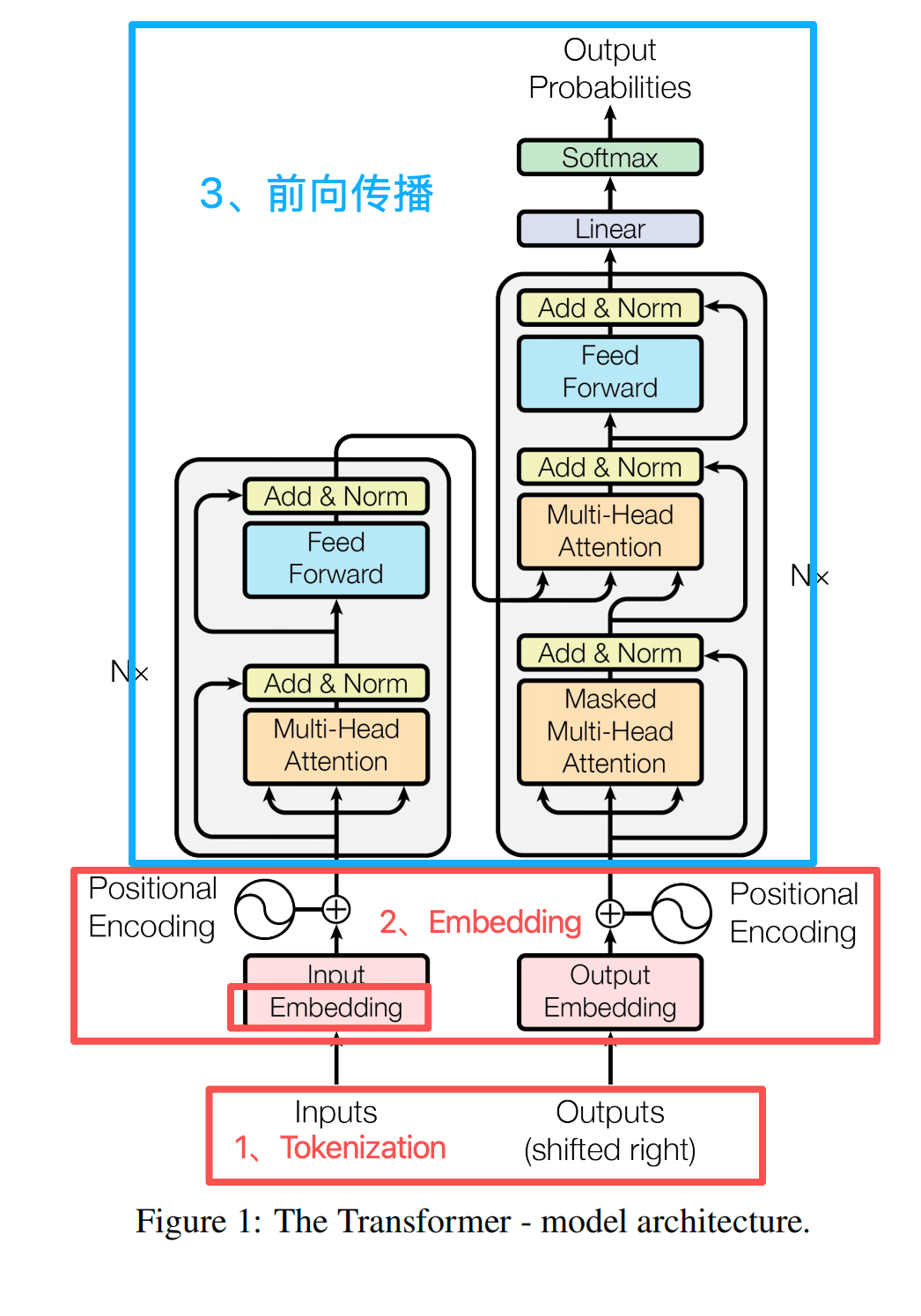
简单地讲,Transformer架构就做了三件事,除了前面的Tokenization、Embedding、位置编码,其它是在做 “前向传播” 这个动作。
为什么这样讲?
大家先想一下,Transformer架构只是改变了大模型的训练过程,在 Transformer一统大模型之前,人家RNN、CNN也训练了很多大模型的,譬如谷歌 DeepMind 开发的围棋 AI的AlphaGo是基于CNN训练出来的。
想到这,是不是有点感觉了?基于神经网络的模型早就有了,训练流程也有经典实践,Transformer只是改良了使用神经网络学习知识的过程,像注意力机制之前已经有了。就像瓦特改良了蒸汽机一样。
下面我们来拆解一下,看看具体的情况。

让我们把上面的8步训练流程和Transformer架构层一一对应起来:
- Tokenization & Embedding(词元化 & 嵌入)&位置编码
- 作用:数据处理和输入准备。将文本转化为模型能理解的数字形式。
- 对应架构:词嵌入层、位置编码层。
- 这是前向传播的“输入阶段”。
- 前向传播
- (子步骤1)多头自注意力层 + 残差连接 + 层归一化
- (子步骤2)前馈神经网络层 + 残差连接 + 层归一化
- 作用:进行核心数学计算,得到模型的预测。
- 对应架构:这就是Transformer堆叠的N个“解码器层”或“编码器层”所做的工作。每一个这样的层都包含:
- 数据会顺序通过所有N层。在最后一层之后,通常会经过一个线性输出层(将隐藏向量投影到词表大小的维度)。
- 计算 Loss
- 作用:将模型的预测与真实标签比较,量化误差。
- 对应架构:这不是一个固定的“层”,而是一个计算操作。通常使用交叉熵损失函数,对比模型输出的logits和真实的token ID。
- 反向传播及后续(优化步骤)
- 作用:根据损失,调整模型参数,使其下次预测得更准。
- 包含:反向传播(自动求导)、梯度裁剪、优化器计算、参数更新。
- 对应架构:这些是训练算法,而不是模型架构的一部分。它们作用于前向传播所涉及的所有参数(包括注意力层、FFN层、嵌入层等的权重)。
一个生动的比喻
把训练Transformer模型想象成教一个学生做选择题:
- Tokenization & Embedding&位置编码:你把一道题目(文本)翻译成学生能理解的内部语言。
- 前向传播:学生(模型)自己思考并得出一个答案。他的“思考过程”就是数据流过自注意力(综合上下文信息)和FFN(进行复杂变换)的过程。残差连接确保他思考时不会忘记题目本身,归一化让他思路稳定。
- 计算Loss:你对比学生的答案和标准答案,给出一个“分数”(损失值),表示他错得有多离谱。
- 反向传播与优化:你分析学生错在哪里(计算梯度),然后有针对性地给他讲解,修正他的思路(更新模型参数)。
总结
- Transformer架构 定义了模型是什么——它的结构、计算单元(注意力、FFN等)和连接方式(残差、归一化)。
- 训练流程 定义了如何让这个模型从数据中学习——其核心步骤“前向传播”,是让数据按架构定义的方式计算一遍。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号