从0到1带你手搓代码CPU训练一个自己的Transformer模型,保证1小时轻松复刻(github代码+数据)

从0到1带你手搓代码CPU训练一个自己的Transformer模型,保证1小时轻松复刻(github代码+数据)

烟雨平生
发布于 2026-04-14 18:48:14
发布于 2026-04-14 18:48:14
自从Transfromer架构解决了传统神经网络在处理长序列时上下文丢失和无法高效并行计算的问题,OpenAI捅破最后一层窗户纸一炮走红后,基于Transfromer的大模型如雨后春笋遍地开花。目前Transfromer大模型已经越来越快地融入我们生活,越来越多地改变我们的生活方式。

2026.1.1搭载Transformer架构的特斯拉FSDV14.2 的Model 3完成了全球首次、经由第三方数据验证的「零接管」横贯美国之旅。人类的自动驾驶,到达了全新的里程碑!
相信你肯定用过豆包、Qwen、元宝这些通用大模型,相信在2026年国内肯定有不少用户会使用特斯拉FSD垂直领域的大模型。
作为技术人,你有没有想过要训练一个自己的模型?
来吧,今天就手搓代码用PyTorch写一个训练Transformer模型的项目。
在写代码前,我们先拆解下需求,回顾下训练Transformer模型的流程。
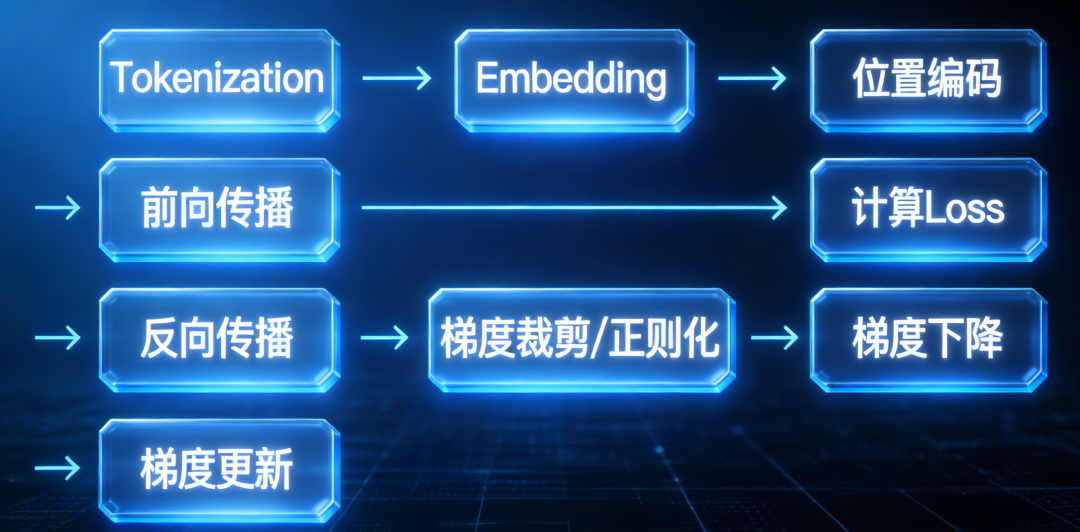
Tokenization(词元化) → Embedding(Token向量化)->位置编码 → Forward Propagation(前向传播) → 计算 Loss (损失函数值)→ 反向传播(计算梯度) → 梯度裁剪 / 正则化 → 梯度下降(优化器计算更新量) → 梯度更新(更新模型参数)
上面这些组件或操作,哪些是Transfomer架构中定义的呢?
Tokenization、Positional Encoding、Embedding、Forward Propagation这四个。
具体到工程代码实现,会使用PyTorch来实现神经网络部分,使用对象来封装变化来解耦。
定义两个Python文件:model.py,train.py
model.py中存放实现Transformer架构中的类、组件。
train.py中把整个训练过程串起来。
第一步
加载训练数据集和验证数据集:
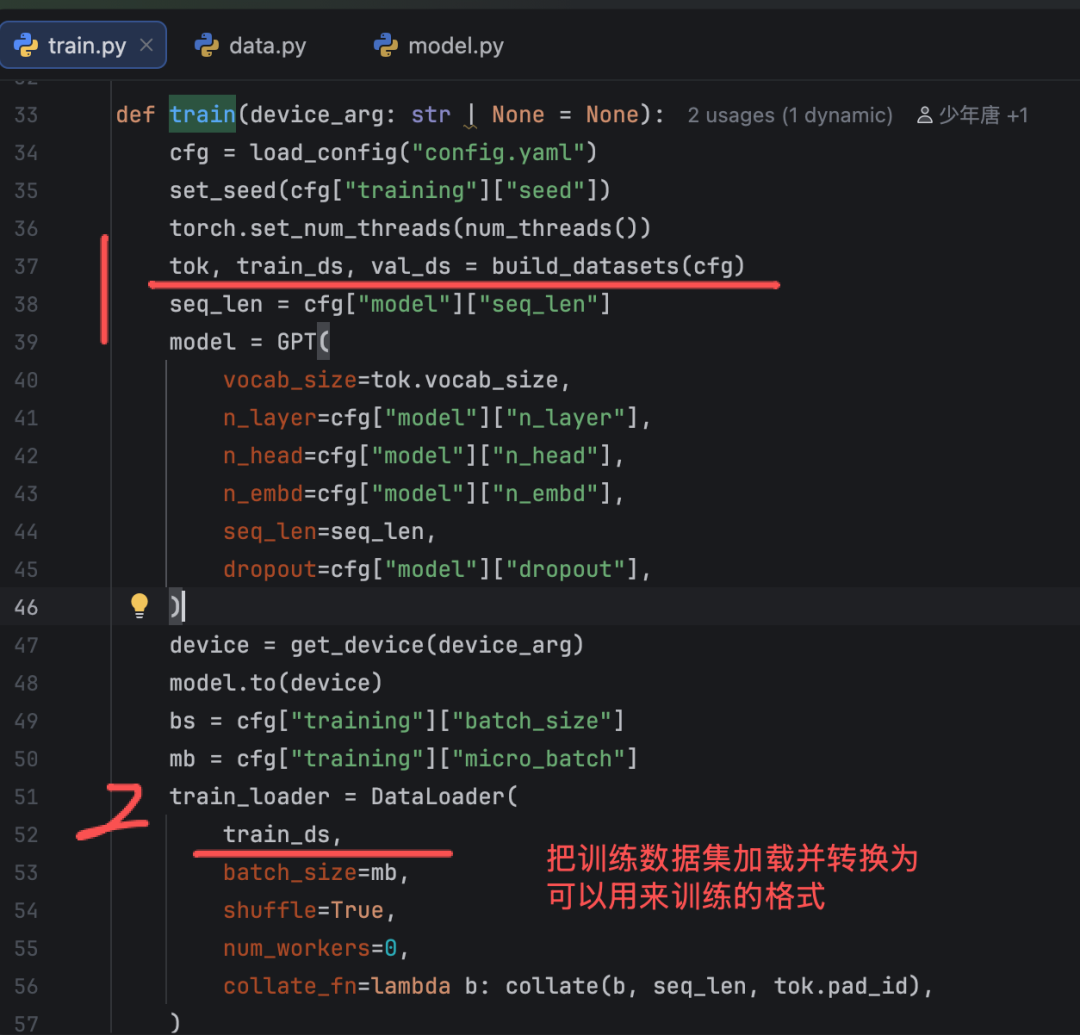
完整的代码会贴在文末。文件中直接写代码,会看起来乱,不方便阅读。
第二步
会用到PyTorch的一个API model,会执行如下训练操作:
Positional Encoding(位置编码)-> Embedding(Token向量化) → Forward Propagation(前向传播)
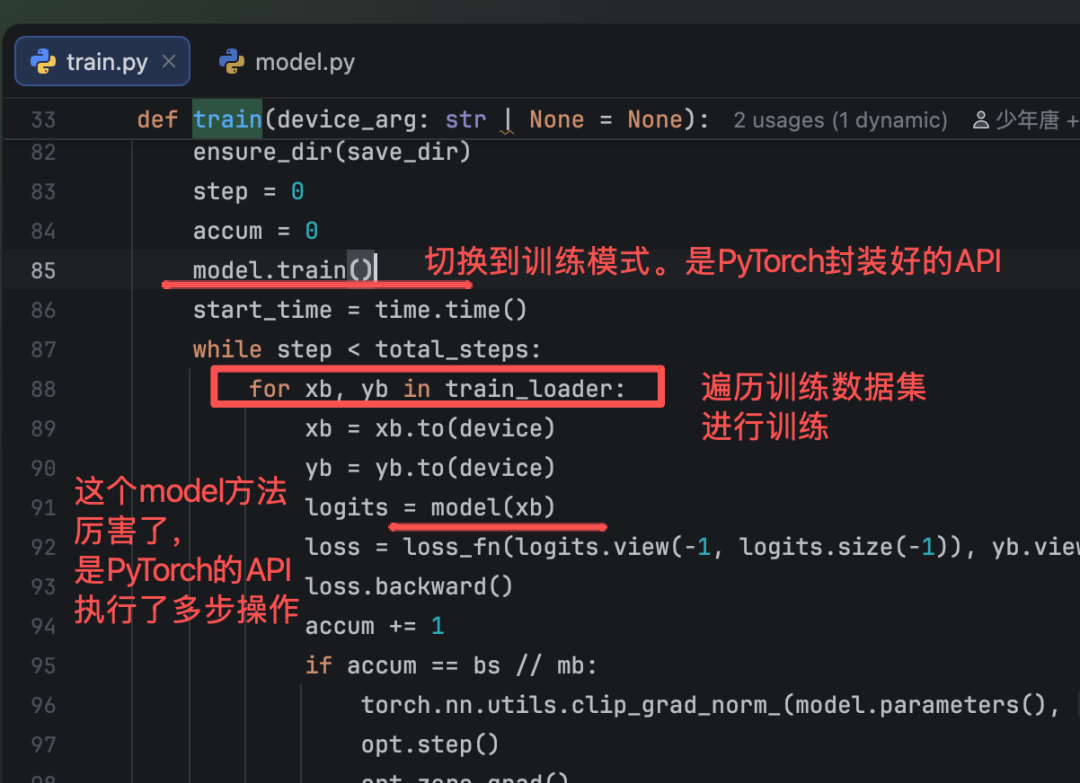
PyTorch框架很强,把大模型的训练过程封装的很好,我们自己写的代码会大量使用nn.Module的API,本次先知道PyTorch的这个API,知道这个API是干什么用的就可以了,后面开个专题来讲一来,本次不展开。
这个model怎么来的呢?
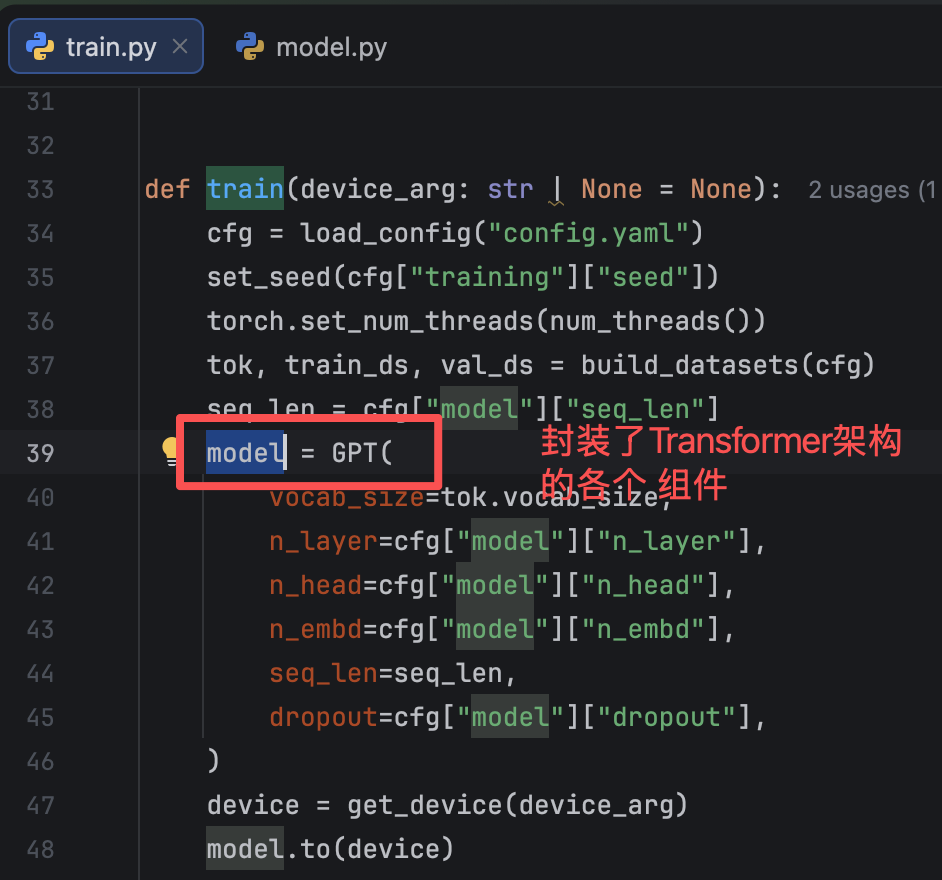
这个model方法干了什么?
logits = model(xb)输入是训练数据集的一条数据,输出是Loss。
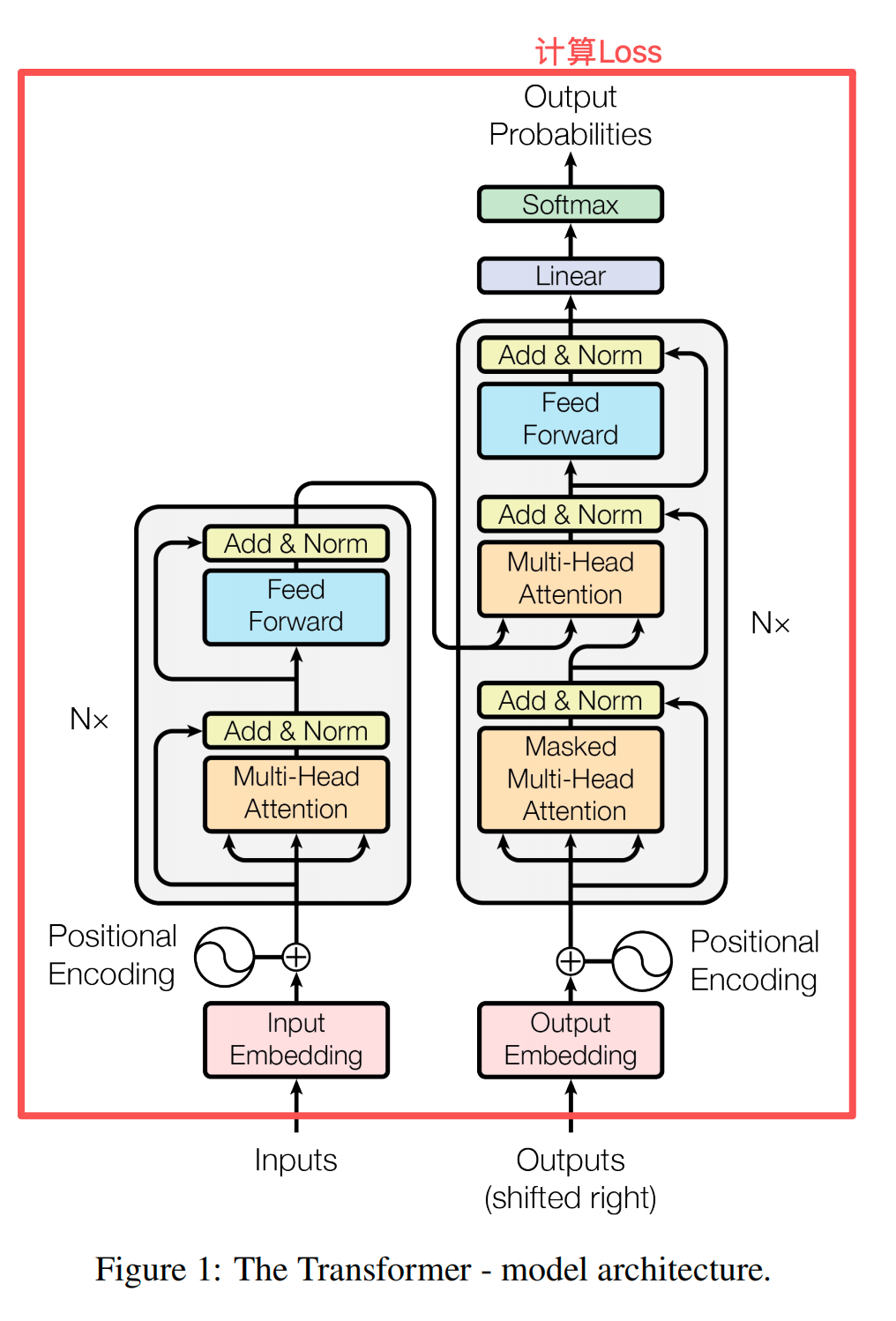
看了图,是不是有点感觉了。
这个model方法之所以有这个功能,是PyTorch使用了模板模式抽象了大模型训练的流程。
来看下我们自己在model.py中定义的
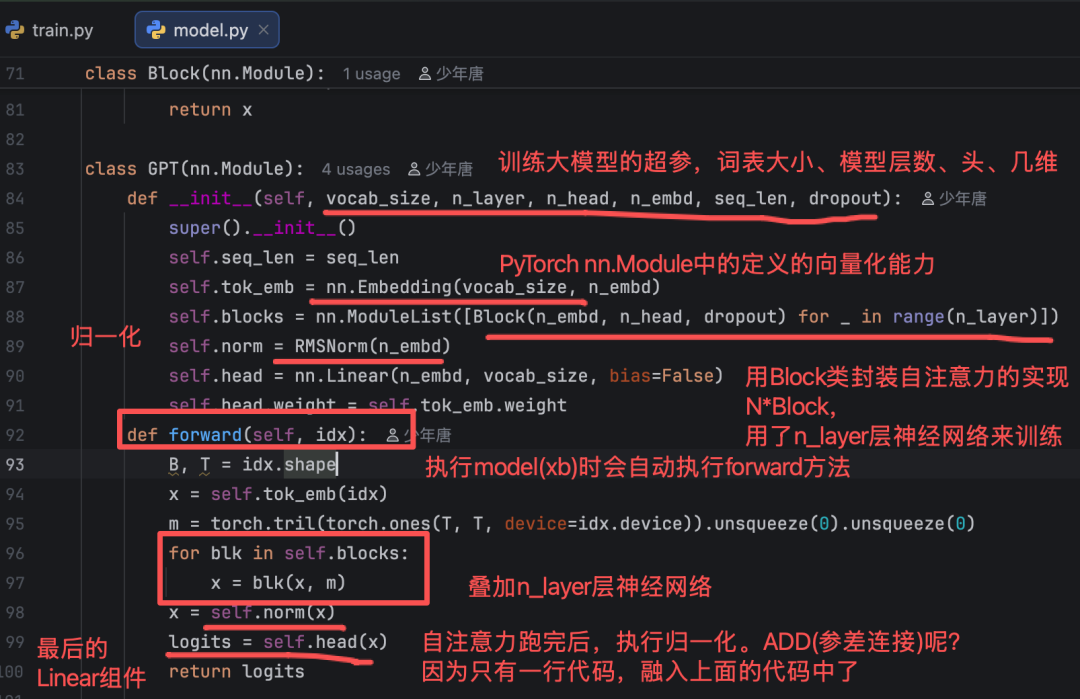
残差连接是什么?代码在哪?
残差连接(Residual Connection)是将神经网络某一层的输入直接与该层的输出相加的连接方式,核心是为信息传递构建 “短路路径”,主要解决深度神经网络中因层数增加导致的梯度消失、模型退化(性能饱和甚至下降)的问题,让深层网络更容易训练。
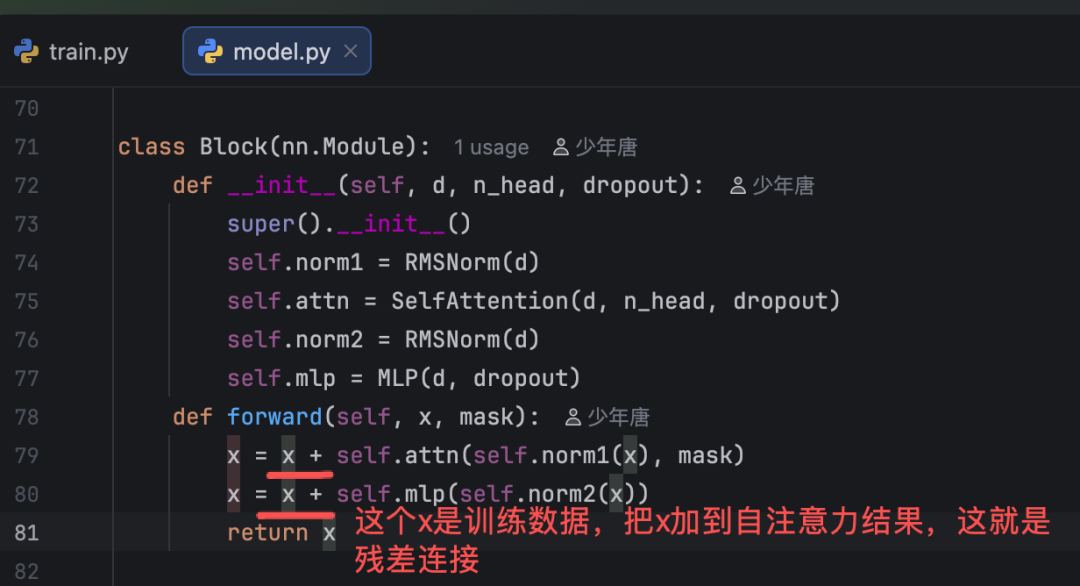
具体怎么实现呢呢?输入与层输出直接相加,构建信息 “短路路径”;
至此,Transformer架构中的创新已经跑完了。下面是开始通过的大模型的通用部分了:
反向传播(计算梯度) → 梯度裁剪 / 正则化 → 梯度下降(优化器计算更新量) → 梯度更新(更新模型参数)
慢着,Transformer架构中的Q、K、V那一段呢?看Transformer的视频中都有讲。
有的。
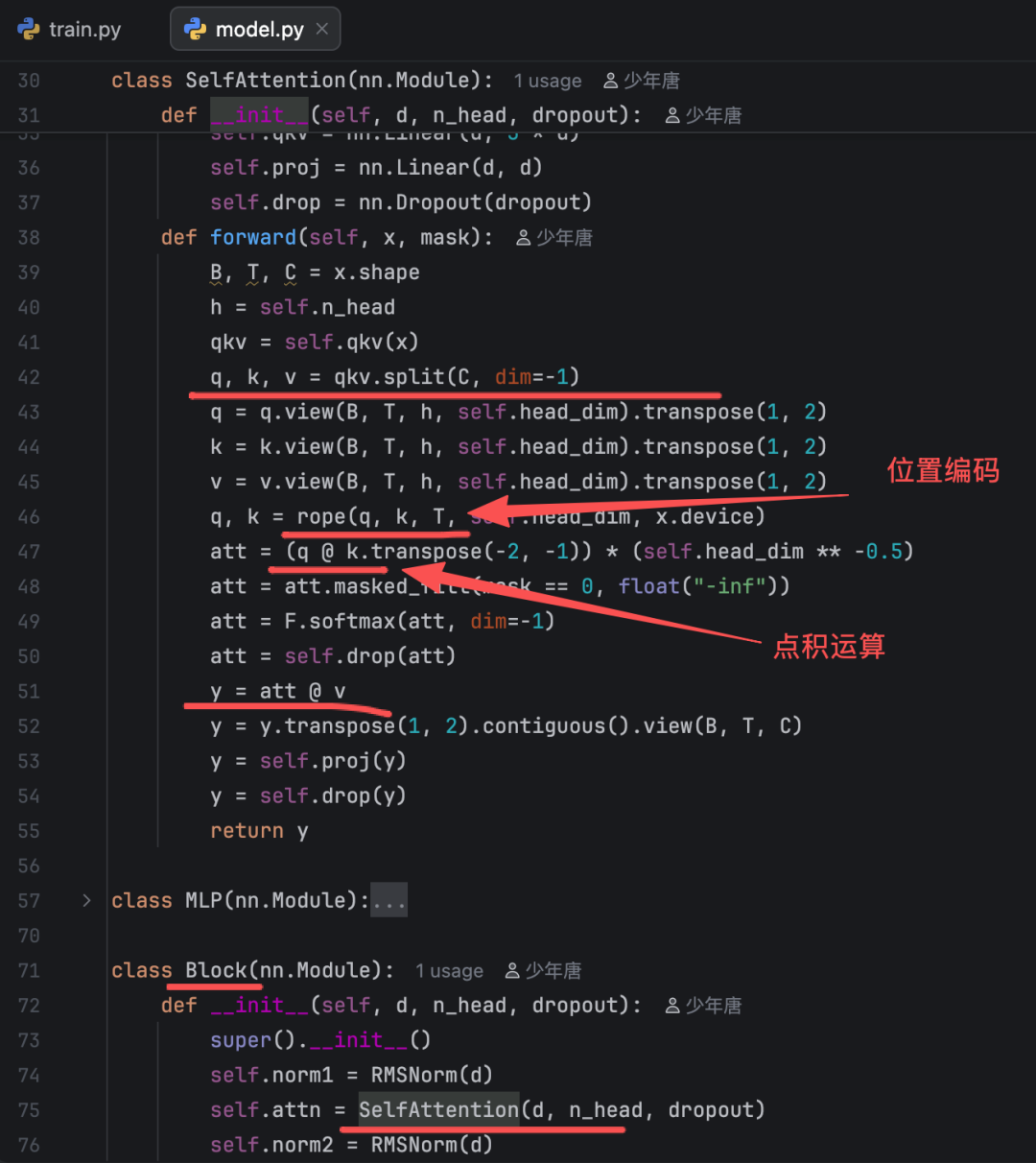
第三步:反向传播、梯度裁剪/正则化、梯度更新
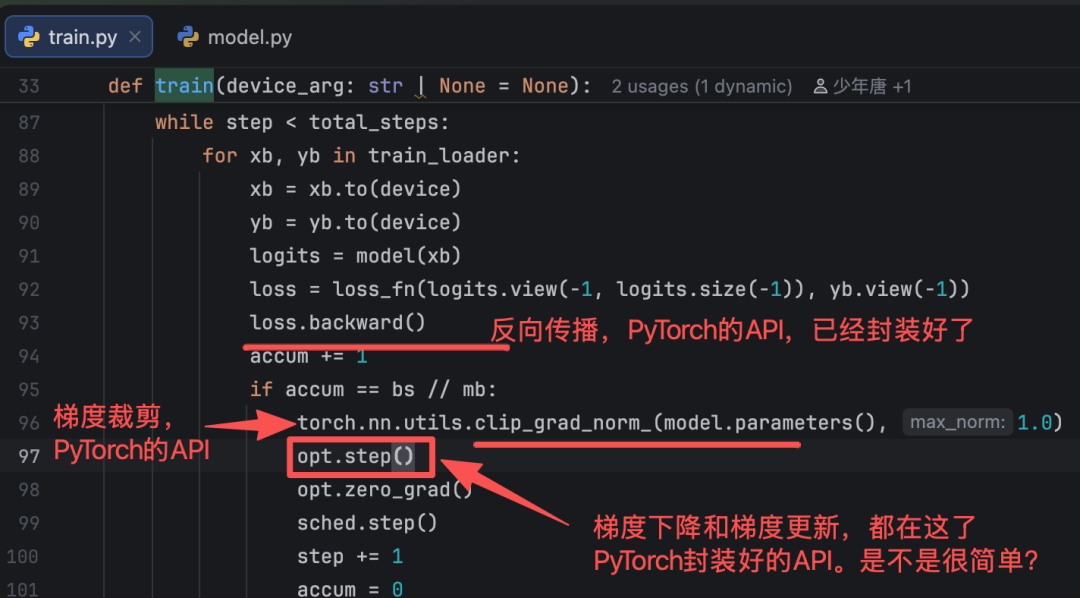
按上面的流程训练就可以了。是不是很简单?
是的就是这么简单。
代码:https://github.com/helloworldtang/GPT_teacher-3.37M-cn
复刻教程:
多次训练,都可以成功复刻,没有像之前的“炼丹”,丹方+方法都一样,但不能保证结果一样,也不想“抽卡”,每次都进行相同的操作,得到的结果不完全一样。
“自从 Transformer 出现,神经网络只剩下工程问题”
不过,这个不是重点,重点是我们可以借助已有框架很容易训练一个Transformer模型,并且可以消费级显卡训练。这样一样,我们日常生活或工作中用到的问题是不是增加了一把“锤子”了?
大家放心愉快地"炼"起来吧!!!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号