从现象到根因,一篇讲透Transformer视角下“复读机” 现象

从现象到根因,一篇讲透Transformer视角下“复读机” 现象

烟雨平生
发布于 2026-04-14 18:55:33
发布于 2026-04-14 18:55:33
在日常使用大语言模型生成内容时,你是否遇到过这样的场景:输入一段提示词,模型却输出了大量无意义的重复文本,像一台失控的 “复读机”—— 词汇反复堆砌、语义断裂空洞,甚至陷入循环无法自拔。

这种 “复读机问题” 并非简单的 bug,而是模型架构、训练机制、解码策略、上下文分布共同作用的结果。
下面从现象、技术分析、根因探究、解决方案、类似问题对比五个维度,把 AI 重复问题讲透。
一、现象:AI “复读机” 的典型表现
“复读机问题” 在 AI 生成内容中主要有以下几种典型形态:
- 词汇 / 短语级重复:单个词、固定短语连续重复,形成无意义文本串,例如 “当代当代当代带有触及及...”。
- 句子级循环:相似句子不断复述,只改少量字,核心信息无增量,读者完全无法获取有效信息。
- 长文本越写越重复:开头正常,中后期逐渐 “卡壳”,重复密度飙升,最终陷入语义空洞的循环。
- 语义空洞化:生成文本篇幅很长,但没有实质内容,只是在重复相同的语义框架,没有新的观点或信息。
这类现象不仅影响体验,在内容创作、代码生成、技术写作中会直接导致输出不可用。
二、技术分析:从 Transformer 视角看 “为什么会重复”
大模型的 “复读”,本质是Transformer 在解码阶段的注意力与概率分布异常。
1. Transformer 解码基本流程
自回归生成(AR)流程:
每一步根据已生成文本(上下文)预测下一个 token;
- 靠Masked Multi-Head Attention看到前面所有 token;
- 看不到未来 token;输出概率分布 → 选 token → 拼回上下文 → 继续下一步。
一旦某一步开始重复,上下文就会被 “污染”,后续生成更容易继续重复,形成正反馈循环。
2. 注意力机制如何 “推波助澜”
当上下文出现重复 token,注意力权重会高度集中在这些重复位置;
- 模型误以为 “重复是高概率、高可信模式”,强化继续重复的倾向;
- 多头注意力中如果某几头专注于 “局部重复模式”,会直接拉偏下一词预测。
3. 架构特性如何放大问题
Transformer的核心组件,如LayerNorm、Softmax和残差连接,共同塑造了注意力分布的 “尖峰化” 趋势:
- 残差连接
- 让重复信号更容易累积,直接叠加到下一层表征,强度被放大。
- LayerNorm
- 会 “提纯” 分布,对已经偏高的重复 token 概率做归一化,进一步拉大与其他 token 的差距。
随着网络层数加深,注意力熵下降,分布变得越来越尖锐,模型从 “均匀探索” 变成 “死死盯住少数 token”,直接锁死重复。
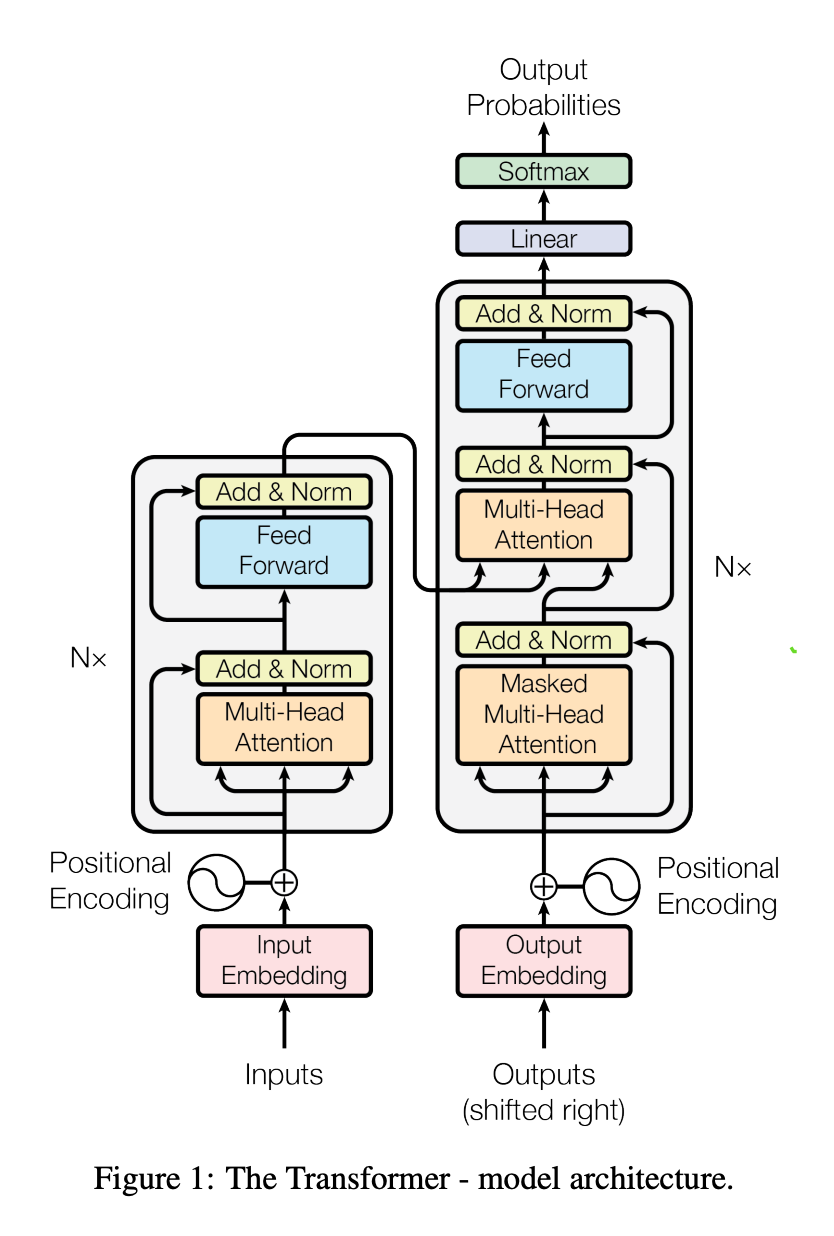
简单说:Transformer不是 “故意复读”,而是它的架构天生更容易陷入局部重复稳态。
三、根因探究:从架构到工程,全链路定位
1. Transformer 架构先天特性(底层根因)
- 残差连接让重复信号更容易累积
- 重复token经过残差通道,直接叠加到下一层表征,强度被放大。
- LayerNorm 会 “提纯” 分布
- 对已经偏高的重复 token 概率做归一化,进一步拉大与其他 token 的差距。
- 注意力熵坍塌
- 深层网络注意力分布越来越尖锐,从 “均匀探索” 变成 “死死盯住少数 token”,直接锁死重复。
2. 训练数据与预训练根因
训练语料中存在大量重复、低质量、模板化文本;
模型学到 “重复 = 常见模式”;
长文本训练不足,对上下文累积污染抵抗力弱。
3. 解码策略根因(最常见工程原因)
用贪婪解码 / 束搜索,缺乏随机性;
温度 temperature 过低,模型保守、趋同;
未开启重复惩罚 (repetition penalty);
上下文窗口塞满重复内容,形成 “自激循环”。
4. 提示词与用户输入根因
- Prompt 本身冗长、重复、逻辑模糊;
- 要求超长文本,但未给 “递进结构” 约束;
- 示例(Few-shot)本身就有重复文风。
四、解决方案:从 Transformer 原理出发的可落地思路
本次把方案分成架构级、训练级、解码级、提示词级、后处理级,越往下越能立刻用。
1. 架构层面(从根源缓解注意力尖峰)
- 提升注意力熵:在注意力计算中加入温和熵正则,避免分布过尖;
- 改进归一化:使用更稳定的 Norm 策略,减缓分布 “锐化”;
- 多头多样性约束:让不同头关注不同片段,避免全体聚焦重复 token;
- 局部注意力 / 滑动窗口:减少对远处重复 token 的关注强度。
这部分是大厂优化重复问题的核心技术方向。
2. 训练与数据层面
清洗数据,过滤高重复、低信息密度文本;
长文本任务用位置编码优化 + 窗口训练;
在预训练 / 微调中加入反重复目标,显式降低重复概率。
3. 解码层面(最有效、立刻能用)
- 开启重复惩罚
- 对已出现 token 施加惩罚,打破循环。
- 合理设置采样参数
- 避免纯贪婪解码
少用greedy/beam_search,这类最容易复读。
- 截断异常上下文
- 检测到连续重复,主动重置部分上下文。
4. Prompt 工程层面
明确禁止:禁止重复、禁止循环、每句话提供新信息
给结构:总分总、递进、问题-分析-结论
给范例:用无重复高质量示例引导文风
5. 后处理层面
- 规则去重:连续 n-gram 重复自动合并 / 改写;
- 重打分:用判别模型对候选片段做 “多样性打分” 重排。
五、类似问题讲解:复读机不是孤例
把 “复读” 放到 Transformer 生成故障谱系里,你会一眼看懂本质

六、总结
AI “复读机” 不是玄学,而是Transformer 注意力机制、残差连接、LayerNorm、解码策略、上下文分布共同导致的可解释现象。
从架构看:注意力熵越低,越容易复读;
从解码看:越保守、越无惩罚,越容易复读;
从解决看:重复惩罚 + 合理采样 + 清晰 Prompt是性价比最高的组合。
理解了 Transformer,你就不再把重复当成 “模型抽风”,而是可控可优化的生成行为。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号