Transformer面试必看:为什么在温度为0的情况下,LLM的两次输出依旧是不完全一样的?

Transformer面试必看:为什么在温度为0的情况下,LLM的两次输出依旧是不完全一样的?

烟雨平生
发布于 2026-04-14 18:56:43
发布于 2026-04-14 18:56:43
大家有没有过这样的经历:给AI(大语言模型LLM)发完全一样的问题,特意把temperature(温度)调到0——毕竟都说这样能让输出最确定,可两次得到的回答,还是会有细微差别?
比如问“介绍一下人工智能”,第一次它会说“人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新技术科学”;第二次呢,可能就多了“简称AI”四个字,甚至语序都会稍作调整。
这可不是AI“故意调皮”,背后藏着大模型推理的底层逻辑——既有硬核的Transformer架构原因,也有像“排队买东西”那样好理解的通俗规律。今天咱们就从Transformer推理的全流程来拆解,把这个问题彻底讲透,哪怕是非技术背景的同学,也能轻松看明白。
先给大家一个“一句话结论”,记牢就不会迷路:温度=0,只要求AI“选最有可能的答案”,但没法保证AI每次“判断哪个答案最有可能”的过程,完全一模一样。因为AI大模型的本质是“文字接龙”的概率预测机,大模型没有思想,只追求句子读着连贯,只是在做极致的数学计算。
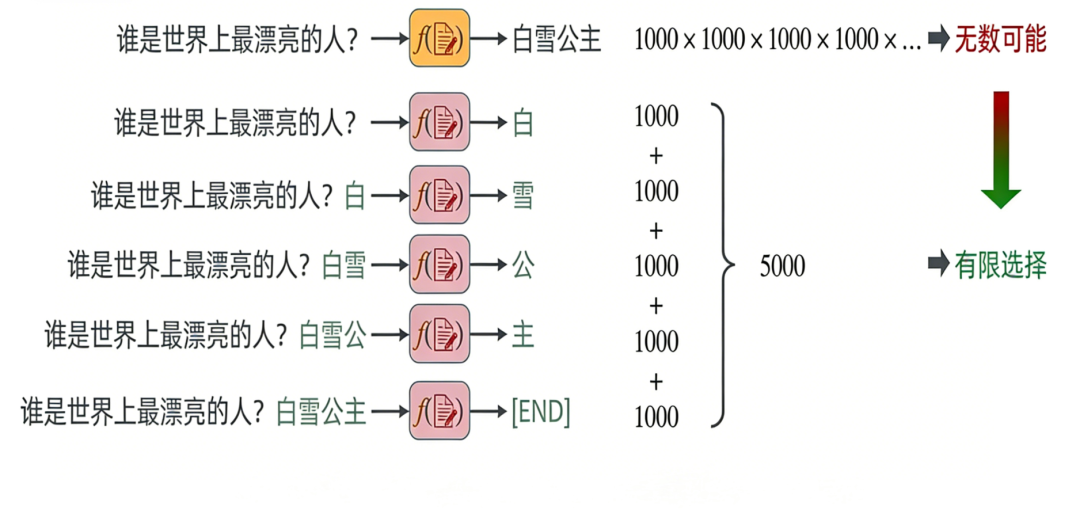
决定文字接龙预测后面一个字的因素有些多,下面我们会逐一拆解。
可以先这样简单理解:这就像你每次排队买奶茶,都想选队伍最短的那一支,但偶尔会看错“哪队更短”,最终就选了不同的队伍,道理是一样的。
在正式开始前,咱们先讲清楚什么是“温度=0”?
一、通俗版:为啥temperature=0,AI还是“说不准”?
咱们先抛开复杂的技术术语,用3个日常生活的事情,把核心原因讲得明明白白、通俗易懂。
譬如:“猜字游戏”里的“视力误差”
其实LLM生成文字的过程,就像一场“文字接龙游戏”:AI面前摆着一个“字库转盘”,每个字都对应着一个“出现概率”——比如回答“人工智能”时,“AI”的概率是30.00001%,“智能”的概率是29.99999%,两者几乎没差别。
温度=0的规则很简单:必须选转盘上概率最高的那个字,就像你玩猜奖游戏,必须选“看起来最可能中奖”的数字一样。但AI的“眼睛”(也就是它的计算过程),会有极其微小的“视力误差”——第一次看,觉得“AI”的概率更高,就选了“AI”;第二次看,因为光线、角度稍微变了一点(对应计算时的微小误差),就误以为“智能”的概率更高,进而选了“智能”。
看似只是选了不同的一个字,但后面的文字都会跟着发生变化——就像猜字游戏,第一个字猜错了,后面的字自然也会跟着错,到最后,两次输出的内容就不一样了。
譬如:“排队结账”的“顺序误差”
LLM计算“每个字的概率”,和咱们在超市结账时“算总金额”的逻辑很像:收银员要把你买的所有东西(对应AI的输入、模型参数)逐一扫码、累加,最后算出总金额(对应每个字的概率)。
温度=0,相当于要求收银员“选最便宜的商品”(对应AI选最可能的字),但收银员每次扫码的顺序,可能都不一样——比如第一次先扫牛奶、再扫面包,第二次先扫面包、再扫牛奶。虽然买的商品完全一样,但累加时难免会有尾差,“微小的舍入误差”(比如0.01元的四舍五入差异),这就可能导致最终的总金额,出现细微差别。
这种差别平时小到可以忽略不计,比如30.00元 vs 29.99元,没人会在意;但如果两个商品的价格极其接近,比如30.00001元 vs 29.99999元,这种微小的误差,就会让“哪个更便宜”的判断彻底反转,对应到AI身上,就是选了不同的字。
二、技术版:从Transformer架构,看底层原因
看完了通俗的比喻,咱们再深入技术核心——LLM的核心架构是Transformer,之所以温度调到0,输出还是不一样,本质上是因为Transformer的计算过程中,存在“不可避免的微小浮点误差”,这些误差一点点积累起来,最终就改变了AI最后的选择。
先给大家科普一个小前提:LLM进行推理时,所有计算用的都是“浮点数”(比如FP16、BF16),这种数和我们生活中的“小数”很像。而浮点数计算,天生就存在“舍入误差”——就像我们算1/3,永远只能得到0.333333...,没法精确表示,只能取一个近似值,这种误差是与生俱来的。
结合Transformer架构来看,这种误差主要来自3个核心模块,正好对应我们上面说的3个比喻,大家可以对照着理解:
1. Multi-Head Attention(多头注意力):“排队扫码”的顺序问题
Transformer的核心是“注意力机制”,简单来说,就是AI判断“哪个字和当前字最相关”的过程——比如写“人工智能”时,它要判断“AI”和“智能”哪个更相关。而这个判断过程,需要做大量的“矩阵乘法”,和超市收银员扫码累加的过程,逻辑上是相通的。
AI的计算硬件(比如GPU),为了提高计算速度,会采用“并行计算”——就像超市里安排多个收银员同时扫码结账。但问题在于,每次并行计算的“顺序”并不是固定的:比如这次是收银员A扫牛奶、收银员B扫面包,下次可能就是收银员B扫牛奶、收银员A扫面包。
浮点数加法有个很特别的特点:(a+b)+c ≠ a+(b+c)。可能有人会疑惑,比如0.1+0.2+0.3,先算0.1+0.2=0.3,再加0.3=0.6;先算0.2+0.3=0.5,再加0.1也等于0.6,看着没差别啊?但在LLM复杂的大规模计算中,这种微小的顺序差异,会一点点积累误差,慢慢变大。
这种“计算顺序的不确定性”,会让注意力机制每次输出的“相关性分数”(也就是每个字的概率),出现微小的差异。这些差异积累多了,就可能改变“哪个字最可能”的判断,AI选的字不一样,输出自然也就不一样了。
2. LayerNorm:“猜字转盘”的刻度误差
LayerNorm,层归一化,相当于Transformer里的“校准器”,它的作用是“修正”注意力机制输出的结果,避免某个字的概率过高、某个字的概率过低——比如防止“AI”的概率无限大,而“智能”的概率无限小,确保判断的合理性。
它的计算过程,需要用到“均值”和“方差”,这和我们平时算班级平均分、成绩波动的逻辑是一样的。而均值和方差的计算,同样是通过浮点数累加实现的——每次计算的顺序、精度稍有不同,得到的均值和方差,就会有微小的差异。
这就像“猜字转盘”的刻度,每次校准之后,刻度都会有极其微小的偏移——比如原本标注30.00001%的刻度,偏移后变成了29.99999%。AI再去选“最高概率”的字时,就很可能选错,进而导致输出不一样。
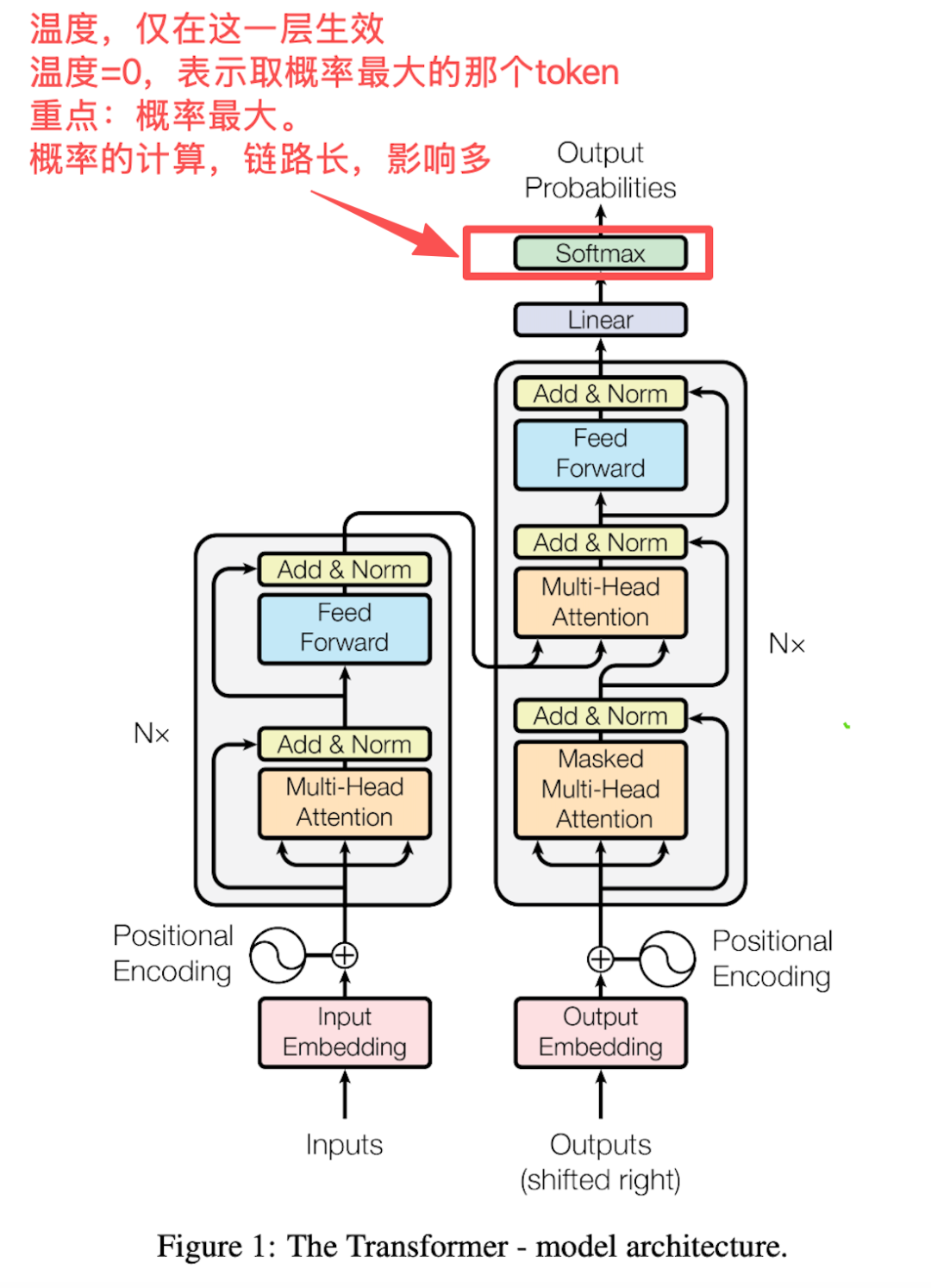
3. 输出层(Linear + Softmax)
Transformer的最后一层是“输出层”,它的作用是把前面所有模块的计算结果,转换成“每个字的概率”——比如把前面的计算结果,转换成“AI”30.00001%、“智能”29.99999%的概率分布。这个转换过程,需要用到Softmax函数,有点像把“转盘刻度”转换成“中奖概率”的过程。Temperature(温度系数)作用在最后的这个Softmax层。
哪怕前面所有模块的误差都很小,到了这一步,也可能出现偏差。比如不同的计算框架(比如PyTorch、TensorFlow)、不同的GPU驱动版本,都可能让Softmax输出的概率,出现微小的差异。
这就像我们抄作业时,最后一步写答案,哪怕前面的步骤都对,也可能因为一时的笔误,最终抄出不一样的答案,AI也是同样的道理。
三、实用技巧:如何让温度=0时,LLM两次输出完全一样?
既然核心原因是“计算过程的不确定性”,那解决办法就很简单了:锁死所有可能导致“误差”的变量,让AI每次“判断哪个字最可能”的过程,完全一模一样。这就像让收银员每次扫码的顺序、猜字转盘的刻度、抄作业的笔误,都彻底消失一样。
具体来说,需要同时做好4件事——非技术同学记结论就好,技术同学可以重点看细节:
通俗版:给AI“定死规则”
1. 给AI一个“固定的参考标准”(也就是固定随机种子),就像让猜字转盘的刻度、超市的价签,每次都保持不变,不出现任何偏差;
2. 让AI“按固定顺序做事”(禁用非确定性优化),就像让收银员每次都严格按照“牛奶→面包→鸡蛋”的顺序扫码,不允许随便改变顺序;
3. 让AI“一个人做事”(单线程、单批次),就像超市里只安排一个收银员,避免多个人并行扫码,导致顺序混乱;
4. 严格执行“选最可能的”(温度=0+贪心采样),不允许AI“凭感觉选”,就像不允许收银员随便选队伍,必须选最短的那一支。
技术版:具体操作(可直接复用)
1. 固定随机种子(锁死初始状态):
python torch.manual_seed(12345) # Python环境 torch.cuda.manual_seed_all(12345) # GPU环境 |
|---|
2. 禁用CUDA非确定性优化(锁死计算顺序):
python torch.use_deterministic_algorithms(True) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False |
|---|
3. 单线程、单批次推理(避免并行误差):设置batch_size=1,不使用流水线、多线程调度,避免并行计算带来的顺序差异;
4. 采样策略固定:严格设置temperature=0,搭配greedy decoding(贪心解码),不使用top_k、top_p等其他采样方式,确保AI只选概率最高的token。
只要做好这4件事,LLM每次推理的计算过程,就会完全一致,输出的内容自然也会100%相同。
四、延伸知识点:LLM的输出,由哪些变量控制?
理解了上面的内容,咱们再延伸一个面试高频问题:LLM的输出,到底由哪些因素决定?其实这个问题很简单,就像“做饭”一样——食材(输入)、菜谱(模型)、火候(采样参数)、厨具(推理环境),缺一不可,少了任何一样,做出来的菜都不一样。
咱们就用“做饭”这个比喻,把这些变量梳理成4大类,通俗又好记,不管是技术还是非技术同学,都能轻松记住:
1. 食材:输入与模型本身(决定“能做出什么菜”)
1.1 输入Prompt(你问AI的问题、上下文):就像做饭的食材,食材不一样,做出来的菜肯定不一样——比如你问“人工智能”和问“机器学习”,AI的输出必然会有差异;
1.2 模型权重(ckpt):就像做饭的菜谱,不同的菜谱(不同的模型,比如GPT-4和Llama 3),哪怕用的食材完全一样,做出来的菜味道也会天差地别;
1.3 系统提示/历史对话:就像做饭时的“备注”,比如“少盐、多放辣”,会直接影响AI的输出风格——比如让AI回答更简洁、更正式,或者更口语化;
1.4 分词器(Tokenizer):就像“切菜的方式”,同样的食材(输入),切得大小、粗细不一样(分词方式不同),后续的烹饪(计算)过程,也会出现差异,最终影响“菜品口感”(AI输出)。
2. 火候:采样核心参数(决定“菜的口感”)
2.1 temperature(温度):最核心的变量,就像做饭的火候大小——温度=0(小火),口感固定(AI只选最可能的答案);温度越高(火候越大),口感越随机(AI敢选概率低的字,输出越发散、多变);
2.2 top_k:就像“只选新鲜的食材”,AI只会从概率前K个token里选,避免选到“不新鲜”(概率低)的字,减少输出的随机性;
2.3 top_p(核采样):就像“选够一定重量的食材”,AI会从累积概率≥p的最小集合里选,比top_k更灵活,既能避免太随机,又能保留一定的多样性;
2.4 requency_penalty/presence_penalty:就像“少放重复的调料”,主要用来惩罚重复出现的token,避免AI变成“复读机”——比如一直重复“人工智能”,让输出更丰富。
3. 厨具:推理与浮点控制(决定“菜的稳定性”)
这就是我们前面重点讲的“误差来源”,也是决定“两次输出是否一致”的关键:随机种子、CUDA确定性开关、并行/批次大小、硬件(GPU/CPU)、框架版本、浮点数精度(FP16/BF16等)。
这就像不同的厨具(比如煤气灶和电磁炉)、不同的火候控制,会影响菜的稳定性——比如每次做出来的口感不一样,AI的推理环境不一样,输出的稳定性也会受影响。
4. 分量:生成长度控制(决定“菜的分量”)
4.1 max_new_tokens:就像“菜的分量”,直接控制AI最多能生成多少个字,比如设置max_new_tokens=100,AI就不会生成超过100个字的内容;
4.2 stop words/stop sequences:就像“菜做好的信号”,只要AI生成到指定的字(比如“谢谢”“以上就是全部内容”),就会停止生成,避免输出冗余;
4.3 eos_token_id:就像“菜熟的标志”,AI生成到这个token,就会知道“回答已经结束了”,自动停止生成,不用我们额外提醒。
五、总结
温度=0时LLM两次输出仍不完全一样,核心原因是 LLM 推理过程中(尤其 Transformer 架构的多头注意力、层归一化、输出层)存在不可避免的微小浮点计算误差,这些误差积累后可能改变最可能 token 的判断,即便温度 = 0 要求选概率最高 token,也无法保证两次判断过程完全一致。
最后用3句话,把所有知识点串起来,不管是技术同学面试,还是非技术同学理解,都足够清晰、好记:
1. temperature(温度)=0还输出不一样,核心不是温度的问题,而是LLM浮点计算的微小误差——结合Transformer架构的Attention、LayerNorm等模块,这些误差一点点积累,最终改变了“最可能token”的判断;
2. 想让两次输出完全相同,不用复杂操作,只需固定随机种子+禁用非确定性优化+单批次+贪心采样,把所有可能产生误差的来源,全部锁死就好;
3. LLM的输出,主要由4类变量控制:输入与模型、采样参数、推理环境、生成长度,就像做饭的食材、火候、厨具、分量,缺一不可,任何一样变了,输出都可能不一样。
如果觉得内容还是有点学院派,也可以只记咱们前面说的通俗比喻——LLM就像一个“认真但偶尔会看错的猜字选手”,温度=0让它只选最可能的字,但偶尔的“视力误差”,就让它选了不同的答案;而我们要做的,就是帮它“矫正视力、固定规则”,让它每次都能选对同一个字。
关注我,后续会拆解更多LLM底层科普,用通俗的语言讲透硬核技术,让技术不再难懂~
相关阅读:
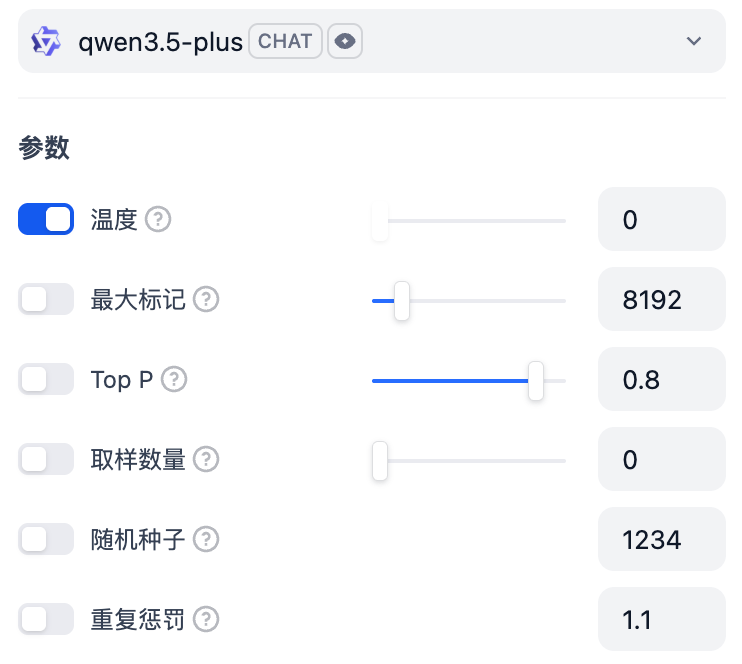
和 ChatGPT 一样的大语言模型并不是根据问题直接在无数种可能中预测出正确结果,而是只预测后面一个字,完成文字接龙,这就把一个乘法运算变成了加法运算,计算量就瞬间可控了。也就是巧妙地用分类策略解决了生成式问题。 虚一,公众号:的数字化之路浅入浅出——生成式 AI
在主流大语言模型(LLM)里,temperature(温度系数) 的取值范围和含义如下:
1. 标准取值范围
- 通常:0.0 ~ 2.0
- 部分框架支持:0 ~ 更高(如 1.5 / 2.0),超过 2.0 一般意义不大,输出会乱。
2. 不同值的效果
- 0.0:最确定、最保守、重复率高,适合代码、事实问答、翻译
- 0.1 ~ 0.3:稳定且略有变化,适合写作、总结、结构化输出
- 0.7 ~ 0.9:创意较强、多样性高,适合文案、故事、脑洞
- 1.0:默认中性,平衡稳定与创意
- > 1.0:随机性极强,容易跑题、逻辑变弱
3. 简单记法
- 要准确、严谨 → 用 0 ~ 0.3
- 要创意、多样 → 用 0.5 ~ 0.9
- 别轻易用 > 1.5,容易输出不可控。
大模型的本质是“文字接龙”的概率预测,大模型没有思想,只是在做极致的数学计算。
看文章看视频会觉得AI已经是万能的了。实际跑一下,却是连汉字都画不好,譬如“票”。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号