Transformer面试必看:Transformer为什么要搞多头注意力?单头注意力真的不行吗?

Transformer面试必看:Transformer为什么要搞多头注意力?单头注意力真的不行吗?

烟雨平生
发布于 2026-04-14 18:57:29
发布于 2026-04-14 18:57:29
先给出答案:
多头注意力的核心意义是从向量空间拆分为多个独立低维子空间,并行捕捉语言中语法、语义、长距离、逻辑等不同类型依赖关系,而单头只能在一个空间学一组权重、一种相似度,表达能力不足、信息互相干扰,无法满足复杂语言建模与大模型的需求,所以单头不行。
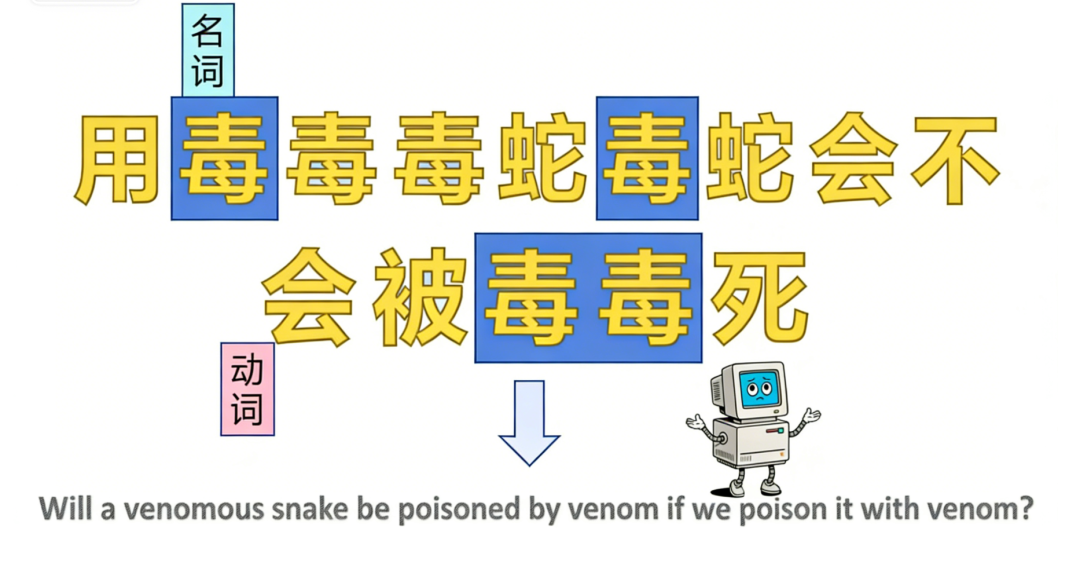
譬如让模型把“用毒毒毒蛇,毒蛇会不会被毒毒死”翻译为英语,这句话里的“毒”字一会儿是名词(毒药),一会儿是动词(下毒),一会儿又和“蛇”组成了名词(毒蛇)。如果用单头注意力去理解,很容易把所有“毒”字混为一谈,翻译出来的结果就会很离谱。
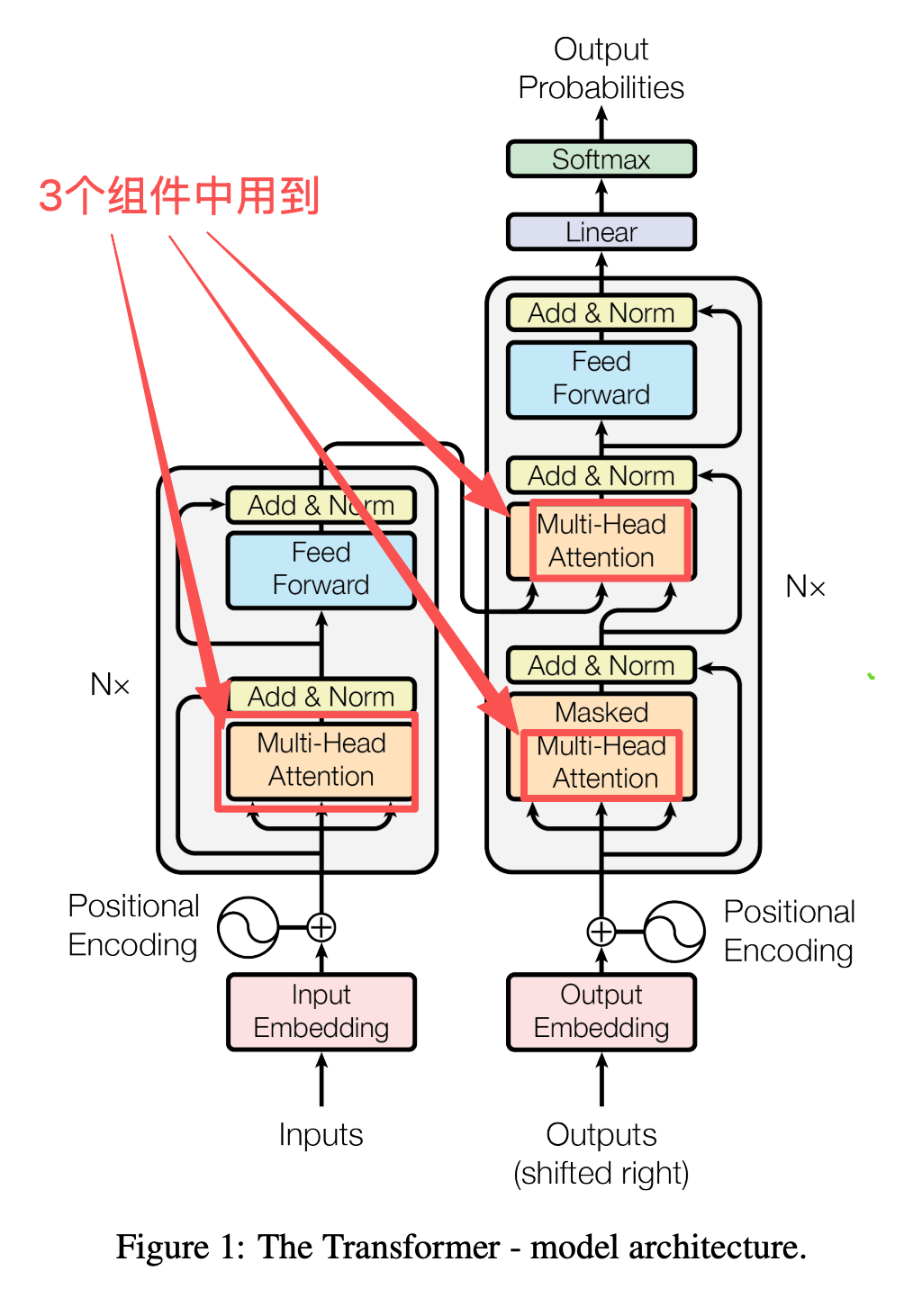
今天咱们就借着这个NLP翻译的例子,把多头注意力的核心意义讲透。在讲之前,先看下Transformer架构中哪些组件使用了多头注意力:
一、先搞懂:什么是注意力机制?
在Transformer出现之前,RNN、LSTM这类模型处理序列时,是“一步一个脚印”地往前走,很难抓住句子里长距离的依赖关系。
注意力机制的出现,就是为了解决这个问题。
Transformer灵魂1问:如何理解Attention中的Q,K,V?你会了吗?一文讲清楚
它的核心思想是:在处理每个词的时候,让模型“重点关注”句子中其他相关的词,而不是一视同仁。
比如在翻译“用毒毒毒蛇”时,当模型处理到第二个“毒”(动词),它就应该重点关注前面的“用毒”(名词),知道这是“用毒药”的动作;而处理到“毒蛇”时,又要把“毒”和“蛇”绑定,理解为“有毒的蛇”。
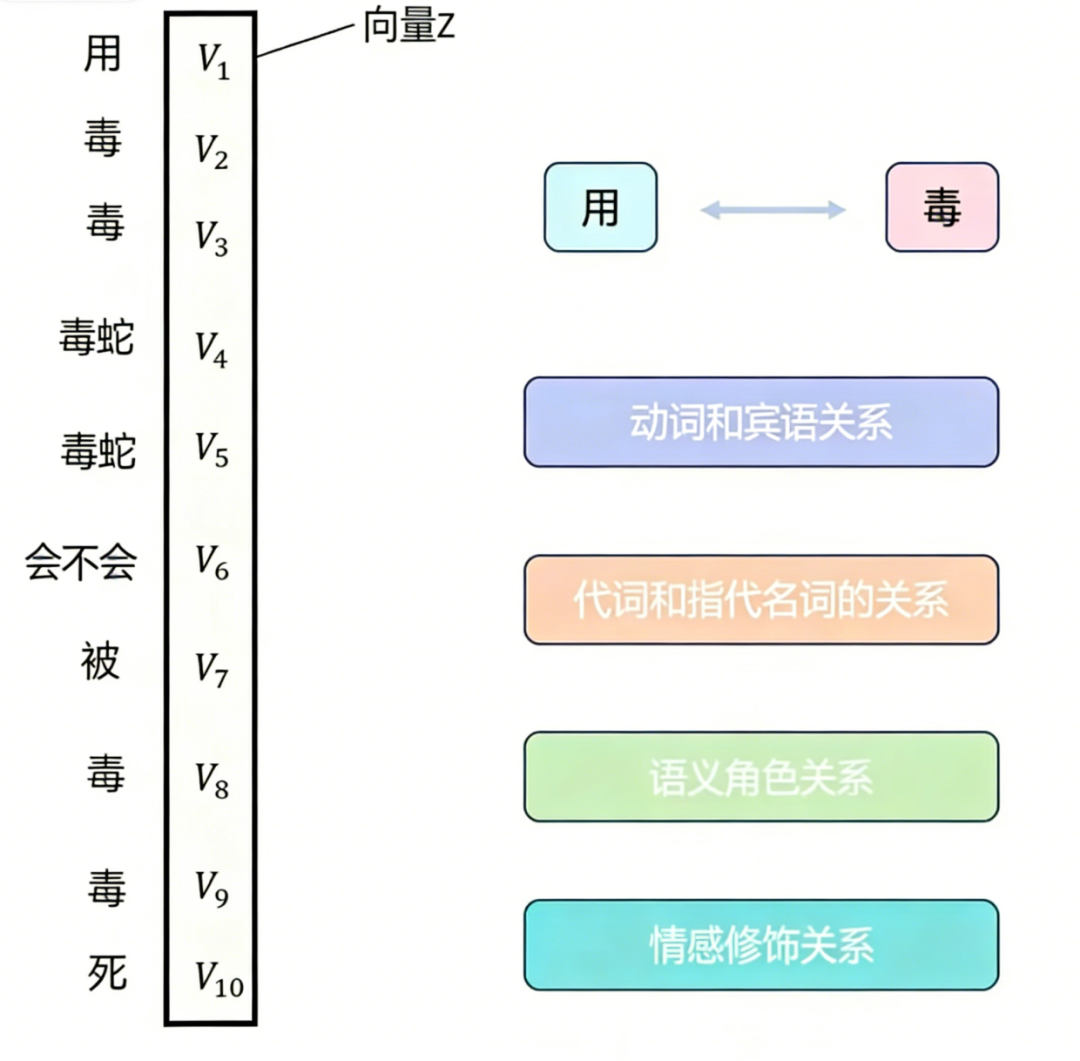
单头注意力就像一个人同时做所有事,他既要判断“毒”是名词还是动词,又要找它和其他词的关系,很容易顾此失彼。

二、多头注意力:让模型“多线程”工作
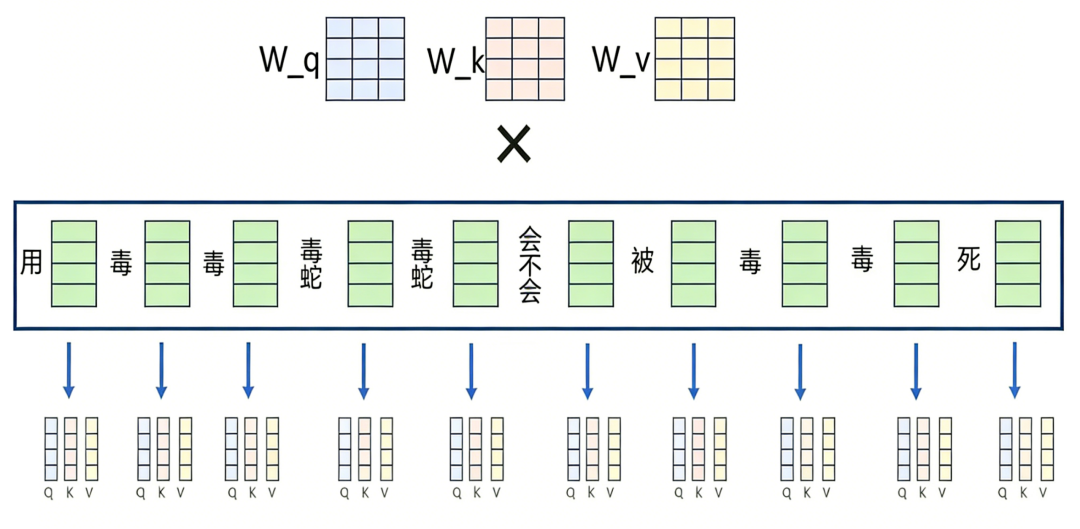
多头注意力(Multi-Head Attention),就是把原来的一个大的注意力层,拆分成了多个小的“头”(Head)。每个头都有自己的一套Q、K、V参数,负责学习不同类型的信息。

还是用“用毒毒毒蛇”这个例子来拆解:
头1(语义角色头):专门负责识别“毒”的词性和角色。它会把第一个“毒”标记为名词(工具),第二个“毒”标记为动词(动作),第三个“毒”标记为形容词(修饰蛇)。
头2(依存关系头):专门负责找词与词之间的依赖。它会发现“用毒”是“毒”这个动作的方式,“毒蛇”是“毒”这个动作的对象。
头3(长距离依赖头):专门负责捕捉长距离的联系。它会把整个句子串起来,理解到“用毒药去毒那条毒蛇”的完整逻辑。

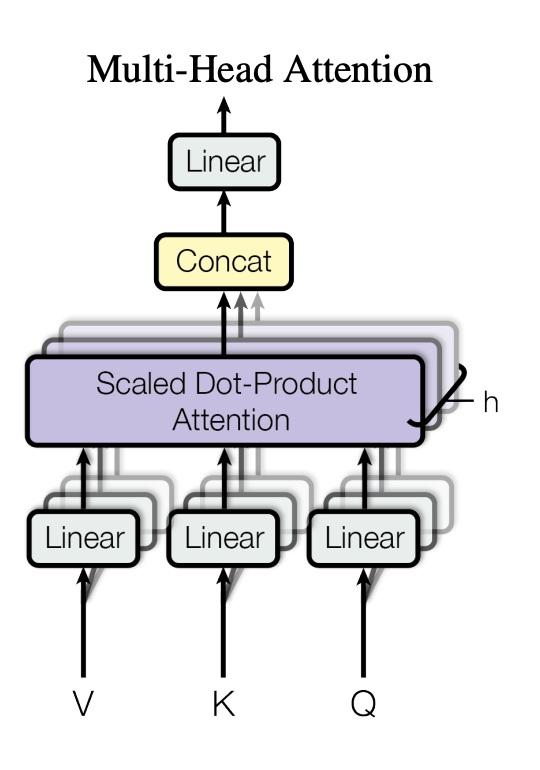
最后,模型会把所有头的输出拼接、融合起来,得到一个更全面、更丰富的表示。这就像一个团队合作,有人负责分析语法,有人负责梳理逻辑,能够从多个角度整合复杂的语义信息,最后得出一个精准的结论。
三、单头注意力为什么不行?
如果只用单头注意力,会出现什么问题呢?
1、信息过载,顾此失彼:一个头要同时处理词性、依存关系、长距离依赖等所有任务,参数的学习压力巨大,很容易在某一方面表现不佳。
2、表示单一,缺乏多样性:单头注意力只能学到一种注意力分布,无法捕捉到句子中多种并行的语义关系。比如在“毒”字的问题上,它可能只能记住“毒”是“毒药”,却忽略了它作为“下毒”这个动作的含义。
3、泛化能力差:当遇到更复杂的句子结构时,单头注意力的局限性会被无限放大,翻译的准确性会急剧下降。
所以,单头注意力不是“不行”,而是“不够好”。它能完成简单的任务,但在处理像“用毒毒毒蛇”这种充满歧义的复杂句子时,就显得力不从心了。
四、总结:多头注意力的核心意义
多头注意力的核心意义,就是通过“分而治之”的策略,让模型能够同时从多个不同的角度去理解和表示文本信息,能够从多个角度整合复杂的语义信息:
1、并行捕捉多种语义:不同的头负责学习不同类型的信息,如语法结构、语义角色、长距离依赖等。
2、丰富表示维度:多头的输出拼接后,得到的向量包含了更丰富、更多维的信息,让模型对文本的理解更深刻。
3、提升模型性能:在翻译、问答、文本生成等任务中,多头注意力显著提升了模型的准确性和鲁棒性。
回到开头的问题:“用毒毒毒蛇,毒蛇会不会被毒毒死?”
如果用多头注意力模型去翻译,它会准确地理解每个“毒”字的含义,输出流畅的英文:“Will a venomous snake be poisoned by venom if we poison it with venom?”
而单头注意力模型,很可能就会输出一个让人摸不着头脑的句子。
所以,Transformer选择多头注意力,不是为了炫技,而是为了让AI更像人一样去理解语言。
LLM模型是训练出来的,模型向量中每个数字代表的意义,也就不是人工设计的了,每个数字的含义,人类暂时还没有办法解释,甚至就连是不是一个数字代表一个特征,还是多个数字结合起来代表一个特征,人类也都还没有弄清楚。训练的时候,模型会自动识别出如何划分特征。我们不知道这些数字背后代表着什么,我们唯一知道的就是这么做效果还不错。也许这也是AI有魅力的原因之一吧 唐成,公众号:的数字化之路为什么我还是无法理解Transformer?Attention的本质是什么?为什么向量之间乘一乘就能得到Token之间的相似度了?
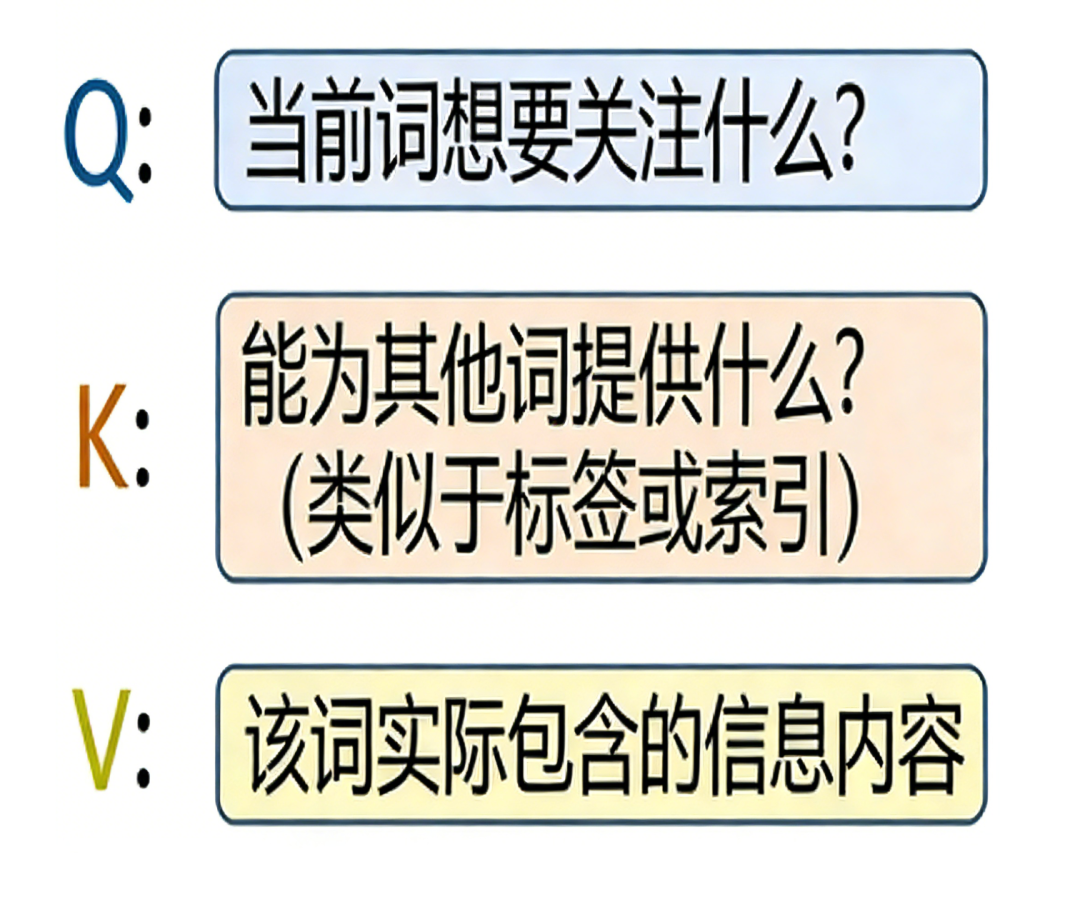
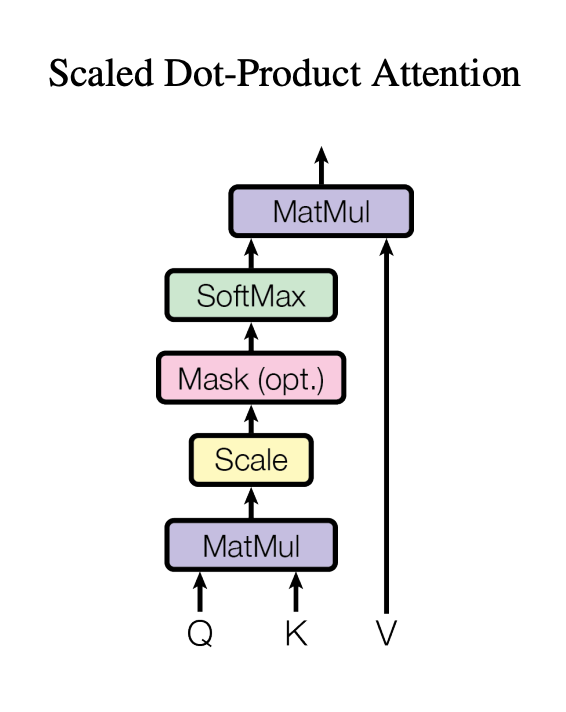
注意力计算: 为了实现这一点,模型首先用三个权重矩阵WQ, Wk, Wv分别和每一个词向量相乘,进行线性变换得到维度不变的Q、K、V向量,其中Q(Query)为查询向量,它代表当前词想关注什么;K(Key)是键向量,它代表该词能为其它词提供什么信息或是关于什么的信息,你可以把k向量看做一个标签或索引;而V(Value)则是代表该词实际包含的信息内容,它是真正被检索和聚合的信息本身。 这里的w_q、w_k和w_v是可以通过训练过程学习的一组权重值。
工作没定下来,心里时不时有点沉重,看来要加速提升能力了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号