Transformer的并行到底体现在哪里?

Transformer的并行到底体现在哪里?

烟雨平生
发布于 2026-04-14 19:01:12
发布于 2026-04-14 19:01:12
先讲答案:Transformer的并行可以归纳为由外到内的三层无依赖并行:序列级并行、注意力级并行、FFN级并行,层层提速。
Transformer之所以能成为大模型的基石,靠的不只是强大的语义理解能力,更是对GPU并行算力的极致利用,能够并行是Transformer的伟大创新。并行,让规模成为可能;规模,让智能涌现成为现实。
Transformer的并行,核心是「训练时整个输入序列一起算」。
下面来展开讲一下。
并行体现在这三个方面:
1、序列级并行。
什么是“序列”?序列,就是按固定顺序排好的一串内容,放到NLP(自然语言处理)里,就是我们日常说的一句话、一段话。
比如:“我爱吃苹果”这句话,拆成词/Token就是【我、爱、吃、苹果】,这四个词按固定语序排好,就是一个文本序列;哪怕是长段落、整篇文章,只要是按先后顺序排列的文本单元,都属于序列。
序列级并行就是【我、爱、吃、苹果】这四个词一起过闸机,同步往前走,全程无先后、无等待,这就是序列级并行。
正是有了顶层的序列级并行,后面的多头注意力、FFN才能实现模块内并行,它是所有底层并行的前提,没有这一步,后续模块再优化也摆脱不了串行枷锁。
2、注意力模块并行。
所有Token同步进入网络后,第一个核心模块就是多头注意力,内部包含两层细分并行。
2.1 多头注意力:矩阵级批量并行,不是多头独立跑
很多人误以为“多个头就是独立小网络,分头挨个计算”,这个说法完全错误。真正的并行逻辑,是靠矩阵运算实现批量处理:
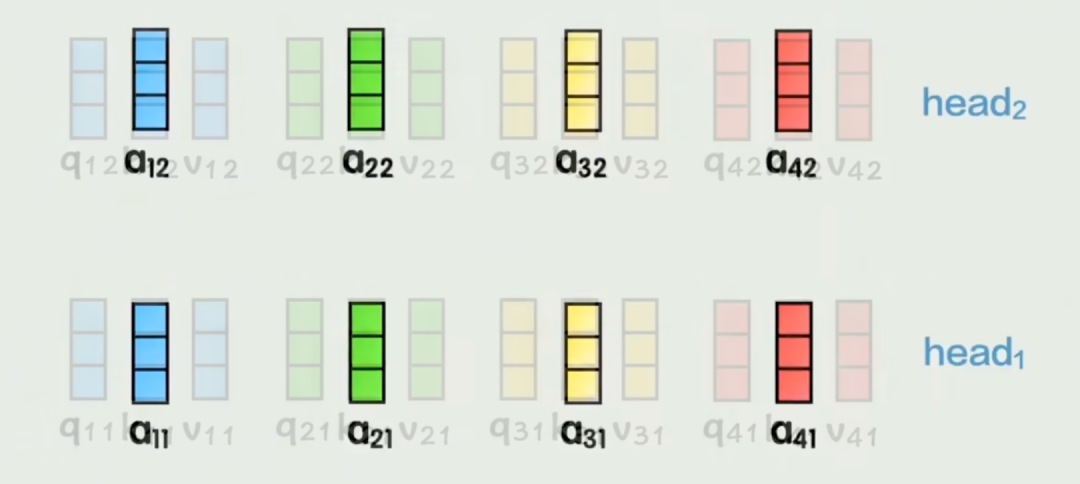
2.1.1 一次性生成所有头的Q/K/V矩阵。
所有Token同时通过线性变换,一次性算出全部注意力头的查询(Q)、键(K)、值(V)矩阵,不是算完一个头再算下一个;
2.1.2 切分多头,同步计算。
把大尺寸Q/K/V矩阵按头数切分(比如8个头切成8份),每个小头的注意力计算同时独立进行,互不干扰;
2.1.3 结果拼接。
所有头计算完成后,直接拼接结果,完成多头注意力流程。
简单地讲,多头并行是先批量算总矩阵,再分头并行处理,全程无等待,算力拉满。
preview
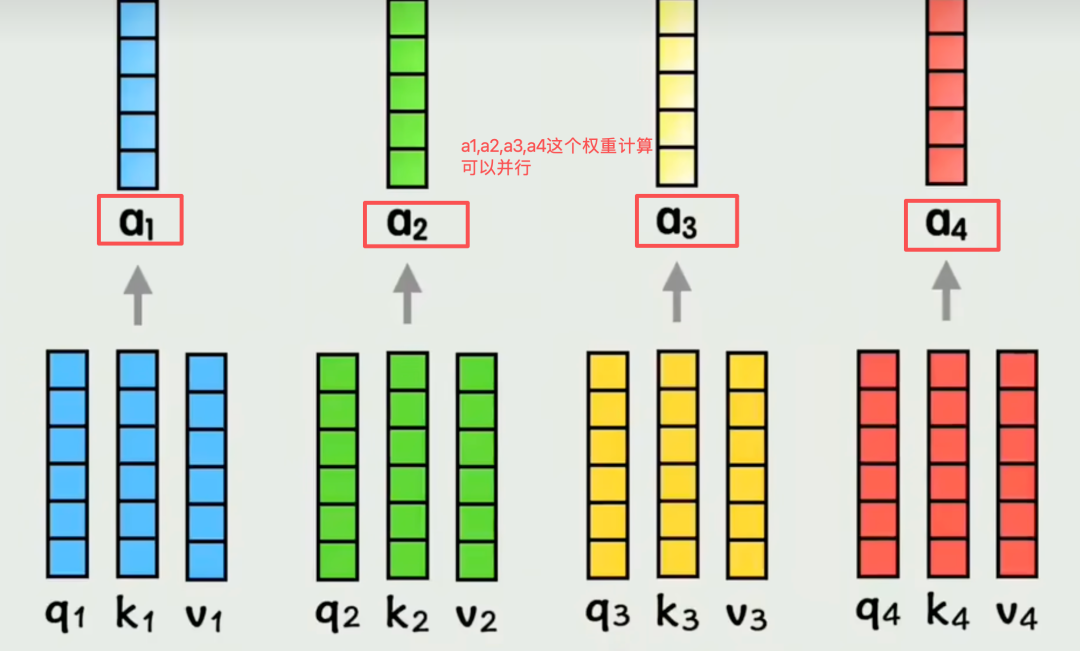
2.2自注意力:Token间全矩阵并行
自注意力是多头注意力的核心计算单元,作用是算出每个词和其他所有词的关联程度(注意力分数),全程无依赖、全并行。
preview
Transformer把一整句所有 token 同时输入,所有Token的向量同时参与运算,所有 token 的注意力加权同时完成,互不等待。注意力分数矩阵里的每一个元素(两个词的相似度),都是GPU一次性并行算出,不用逐行、逐词配对计算。比如10个词的序列,100个关联分数同时出结果,速度远超串行计算。
3. FFN逐Token并行。
FFN(Position-wise Feed-Forward Networks,前馈网络)通过“升维激活再降维”的非线性变换,对自注意力机制聚合后的上下文信息进行深度的特征提取与语义加工,是 Transformer 存储知识和提升模型表达能力的关键组件。
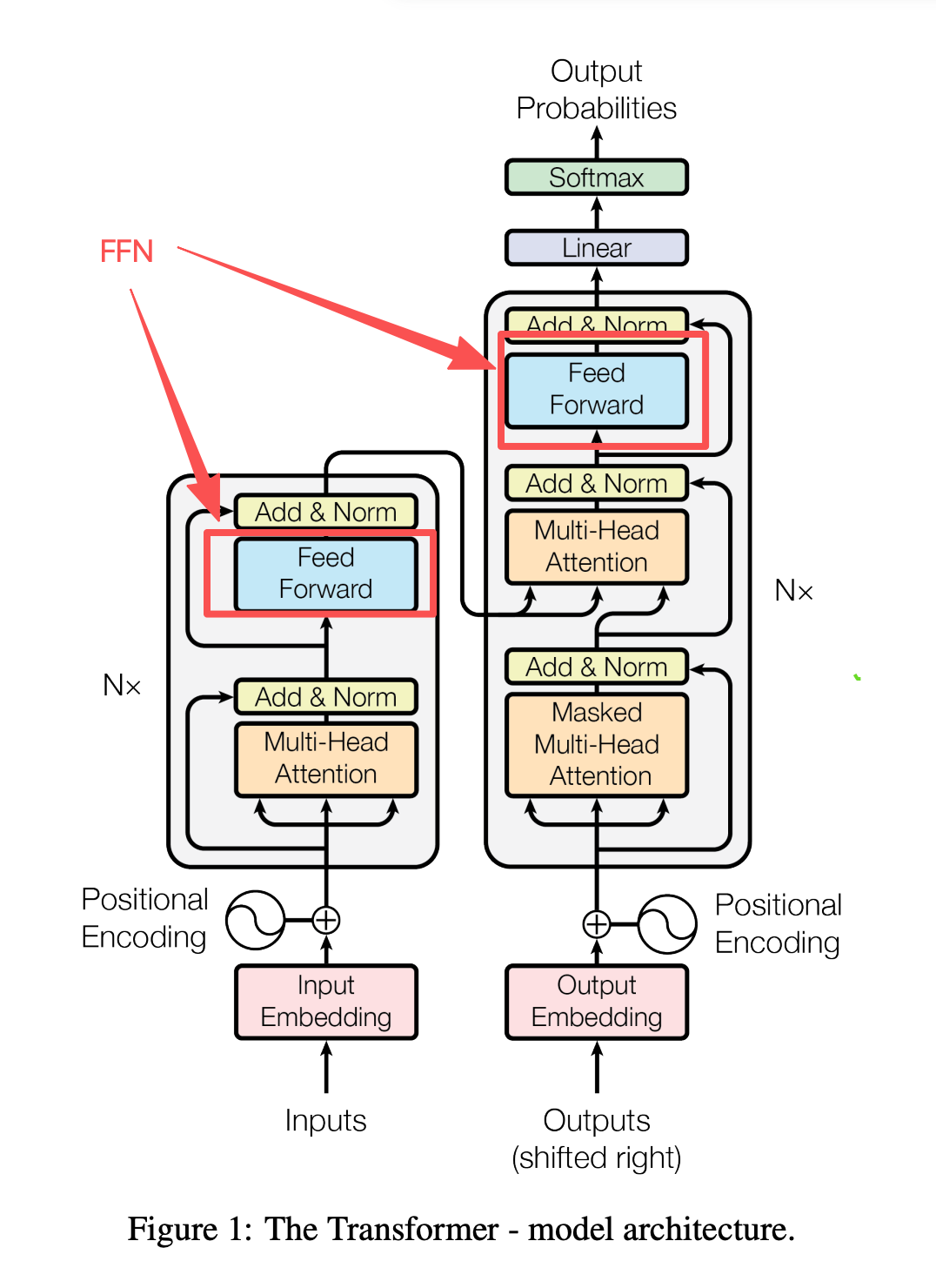
紧跟在多头注意力之后,是Transformer里最干净、最彻底的并行模块,完全依托顶层序列级并行实现。
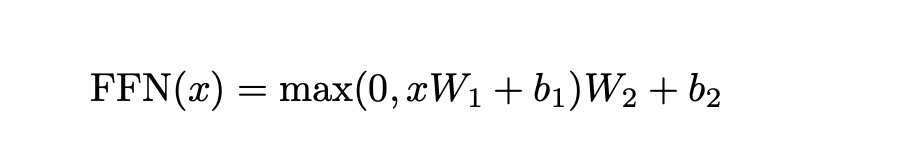
FFN结构很简单,就是两层线性变换加激活函数,它的核心特点:序列里每个Token的计算完全独立,和其他词没有任何关联,不用等其他词的计算结果。
并行逻辑:所有Token同时输入FFN,每个词单独走一遍网络流程,整合成矩阵后一次运算完成所有Token的计算,实现逐Token极致并行,完全适配GPU的并行架构。
小结
Transformer的并行性是一场由外到内、从顶向下的革命。
- 顶层:序列级并行。整个文本序列的所有Token同时输入计算,打破RNN串行枷锁,是所有并行的基础;
- 中层:是核心。注意力模块并行:包含多头注意力矩阵批量并行、自注意力Token间全矩阵并行,是模型提速的关键;
- 底层:FFN逐Token并行。每个Token独立过前馈网络,无任何交叉依赖,实现细粒度完全并行。
最后再看下定义找找感觉:
Transformer架构开创性地以自注意力机制(Self-Attention)为核心,摒弃传统循环与卷积结构,依托多头注意力(Multi-Head Attention)和位置编码(Positional Encoding)实现计算并行化,还能高效捕捉序列中的长距离依赖关系。这一创新的神经网络结构,有效解决了传统序列模型在计算与长距离依赖捕捉上的效率难题,大幅提升了前向传播与特征建模的效率,其实用性已被众多企业和研究机构验证,也由此掀起人工智能发展的全新浪潮。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号