手把手带你从0到1在CPU上训练可推理可泛化可演示的小参数中文 GPT,实现中文 GPT 训练平民化,实现训练中文 GPT 自由

手把手带你从0到1在CPU上训练可推理可泛化可演示的小参数中文 GPT,实现中文 GPT 训练平民化,实现训练中文 GPT 自由

烟雨平生
发布于 2026-04-14 19:12:02
发布于 2026-04-14 19:12:02
养过龙虾的人都知道,决定龙虾能力的还是
VibeCoding的人都知道,决定代码质量的还是大模型。Opus模型可以全托管,其它模型只能扶着走,有的模型根本付不起来。
大家的工作和生活都越来越离不开大模型了,那么你有没有想过自己来训练一个模型,自己来训练一个有推理能力的模型,自己来训练一个举一反三的模型。
有人会说了,训练模型都要钱,都要名校毕业,都要硕士都要博士,这些都只有大厂能搞出来,最先进的模型只有美丽国才能搞出来。
其实不完全是这样的。我们也可以的,只使用家里的电脑就可以。
下面我带小伙伴手搓代码用家用电脑来训练一个小模型。本次先从原理讲起,然后进行实践。
在讲之前,先看下效果:




在开始之前,先看看整个学习路径,心中有数:
📍 第1步:理解AI模型是什么(10分钟)
↓
📍 第2步:认识模型的核心组件(15分钟)
↓
📍 第3步:了解训练是如何进行的(15分钟)
↓
📍 第4步:动手训练自己的模型(5分钟)
↓
📍 第5步:测试和验证效果(5分钟)预计时间:50分钟(实际训练只需要11.5秒)
前置知识:不需要任何编程或数学背景,会使用电脑即可
学习方式:先理解概念,再看代码,最后动手实践
学习技巧:
- 📖 循序渐进:不要跳过前面的内容,每个概念都是后续学习的基础
- 🤔 多问为什么:理解"是什么"之后,尝试理解"为什么"和"怎么做"
- 🔄 反复阅读:遇到不理解的内容,多读几遍,或者先跳过去后面再回来
- 💡 联系实际:把AI概念和你生活中的经验联系起来,更容易理解
前言:写给AI入门的你
你是否想过:我也能训练一个会对话的AI吗?
答案是肯定的!这篇文章将手把手带你从零开始,用最简单的方式理解AI训练的原理,并在1小时内(实际上只需要11.5秒)训练出属于你的第一个AI模型。
不需要昂贵的GPU,不需要深厚的数学背景,只需要一台普通电脑和一颗好奇的心。
如何使用这篇文章
📖 阅读方式
方式1:从头到尾阅读(推荐)
- 按照章节顺序学习
- 每个章节都依赖前一章的知识
- 适合零基础入门
方式2:按需阅读
- 如果你已经了解某些概念
- 可以跳过相关章节
- 直接阅读感兴趣的部分
🎯 每章结构
每个章节都包含:
- 学习目标:明确本章要学到什么
- 核心概念:用通俗易懂的方式解释理论
- 📖 理论延伸:深入理解背后的原理
- 🎯 学习检查点:检验是否掌握了本章内容
- 💡 思考题:启发思考,加深理解
✅ 学习建议
遇到不懂的地方怎么办?
- 多读几遍,慢慢理解
- 先跳过,继续往后看,可能后面会明白
- 不要卡在一个地方太久
什么时候动手实践?
- 理解了理论概念后
- 读完了前三章后
- 准备好开始第四章动手训练
如何检验学习效果?
- 能用自己的话解释学到的概念
- 能回答每章的检查点问题
- 能独立完成训练和测试
第一章:AI模型是什么?
学习目标
✅ 理解什么是AI模型 ✅ 知道模型训练的基本概念 ✅ 了解小模型的优势
1.1 一个最简单的类比
想象你在教一个小学生学习乘法:
传统教学方式:
- 老师讲解原理:乘法是重复相加
- 学生理解后练习
- 需要时间消化
AI训练方式:
- 给AI看大量例题
- AI自己找规律
- 通过不断调整来改进
举个例子:
给AI看这些例题:
2 × 3 = 6
4 × 5 = 20
7 × 8 = 56
...AI会"思考":哦!原来乘法就是重复相加!
这就是训练的核心:从例子中学习规律。
🎯 学习检查点:
在继续之前,问问自己:
- 我能用自己的话解释什么是"从例子中学习规律"吗?
- 我能想到生活中"从例子中学习"的其他例子吗?
💡 思考题:
- 如果只给AI看例题,不给它看答案,它能学会吗?(答案:不能,训练需要正确的答案作为参考)
- 如果给AI看1000道题和看100道题,效果会一样吗?(答案:数据量会影响学习效果,但质量也很重要)
1.2 AI模型的关键概念
让我们用最通俗的方式理解几个核心概念:
数据(Data)= 教科书
就像学生学习需要课本,AI学习也需要数据
我们的数据示例:
问题:"什么是注意力机制?"
答案:"注意力让模型关注重点。"模型(Model)= 大脑
就像学生用大脑思考,AI用模型处理信息
我们的模型:
- 大小:337万个参数(像337万个脑细胞连接)
- 类型:GPT(一种专门处理文本的模型)
- 能力:理解和生成中文训练(Training)= 做练习
就像学生通过做题来学习,AI通过训练来改进
训练过程:
1. 给AI一个问题
2. AI尝试回答
3. 对比正确答案
4. 根据错误调整自己
5. 重复这个过程参数(Parameters)= 知识点
就像学生脑中的知识网络,AI有参数
参数的作用:
- 存储学到的规律
- 决定模型的能力
- 训练就是调整这些参数
我们的模型有337万个参数:
- 看起来很多
- 实际上很小(GPT-3有1750亿个)
- 小模型训练快,易理解推理(Inference)= 考试答题
就像学生用学到的知识考试,AI用训练好的模型回答问题
推理过程:
1. 给模型一个问题
2. 模型根据训练结果预测答案
3. 输出预测的文本1.3 GPT模型:最适合初学者的模型
GPT = Generative Pre-trained Transformer
让我们拆解这三个词:
Generative(生成式)
含义:能够生成新的内容
例子:
输入:"北京是中国的"
输出:"首都"(补全句子)
输入:"写一首关于春天的诗"
输出:"春风吹绿柳枝头,桃花满园笑颜流..."为什么选择生成式模型?
- 应用广泛:对话、写作、翻译
- 易于理解:输入→输出,直观清晰
- 训练简单:只需要文本数据
Pre-trained(预训练)
含义:先在大规模数据上训练基础能力
类比:
小学教育:
1. 先学基础知识(识字、算术)
2. 再学专业知识(历史、地理)
AI训练:
1. 预训练:学习语言基础(在大规模文本上)
2. 微调:学习特定任务(在我们的数据上)
我们的模型:
- 直接从零训练(相当于小学从头学起)
- 数据量小但质量高(精品教育)
- 时间短(11.5秒,超快速)为什么从零开始?
- 更容易理解训练过程
- 看到模型从"什么都不会"到"会回答"
- 学习成本更低
什么是Transformer?
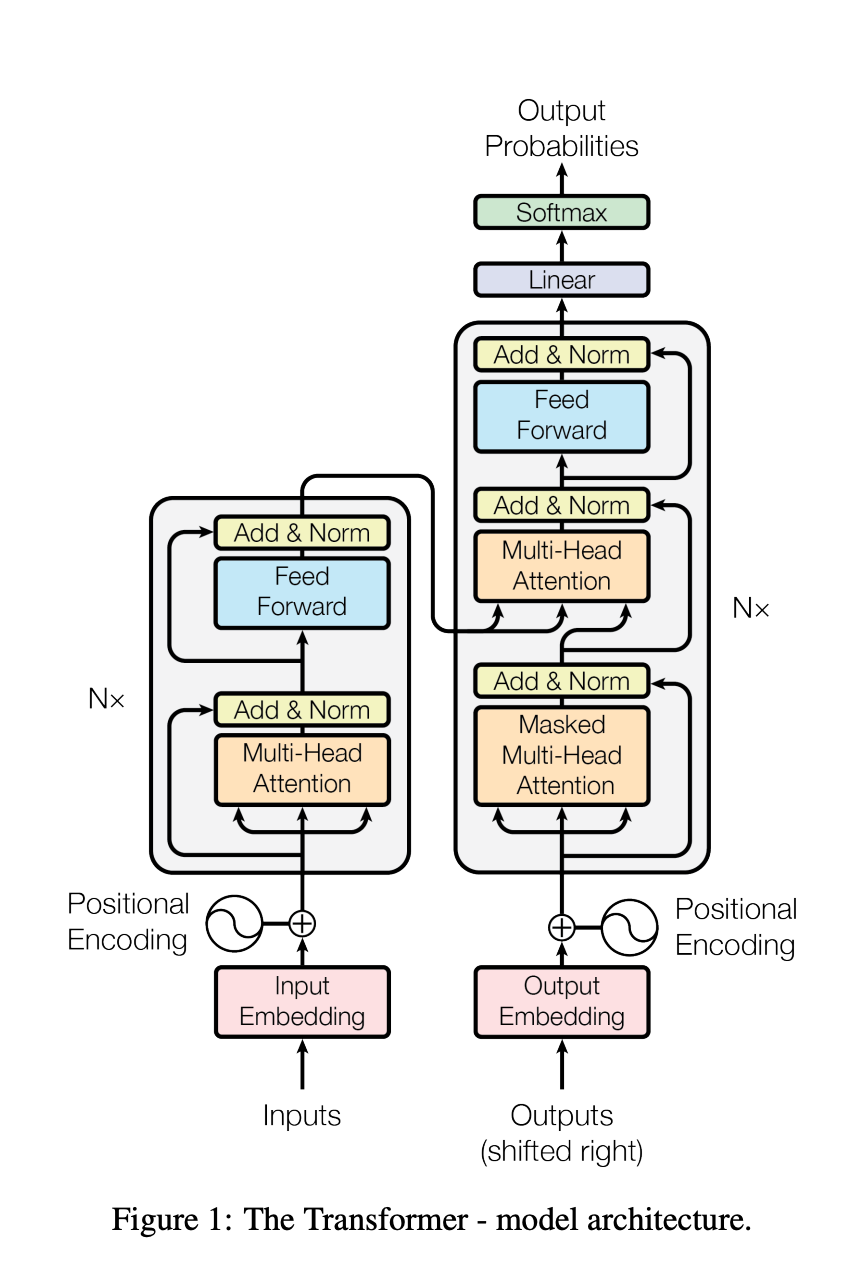
Transformer是一种革命性的神经网络架构,是一种以自注意力机制(Self-Attention)为核心,摒弃传统循环与卷积结构,依托多头注意力(Multi-Head Attention)和位置编码(Positional Encoding)实现计算并行化,还能高效捕捉序列中的长距离依赖关系。这一创新的神经网络结构,有效解决了传统序列模型在计算与长距离依赖捕捉上的效率难题,大幅提升了前向传播与特征建模的效率,其实用性已被众多企业和研究机构验证,也由此掀起人工智能发展的全新浪潮。如今,Transformer 架构更是成为大模型时代无可争议的核心基石。
为什么选择Transformer?
- 处理文本效果好(当前最主流)
- 训练速度快(可以并行计算)
- 理解相对直观(注意力机制容易理解)
1.4 小模型的优势
我们的模型只有3.37M(337万)个参数,对比一下:
模型 | 参数量 | 训练时间 | 计算资源 |
|---|---|---|---|
我们的模型 | 337万 | 11.5秒 | 普通CPU |
GPT-2 | 15亿 | 数周 | 数百GPU |
GPT-3 | 1750亿 | 数月 | 数千GPU |
小模型的好处:
- 训练快
- 11.5秒就能训练完
- 修改代码后可以立即重新训练
- 快速实验不同想法
- 资源要求低
- 不需要GPU,普通CPU就行
- 不需要花大量钱买硬件
- 任何人都能尝试
- 易于理解和修改
- 代码量少,容易看懂
- 参数少,容易调试
- 适合学习和实验
- 教育价值高
- 理解训练过程更直观
- 看到改进效果更明显
- 建立信心:我也能训练AI!
什么时候用大模型?
- 需要处理复杂任务(如写论文、编程)
- 需要高质量输出(如商业应用)
- 有充足资源和时间
什么时候用小模型?
- 学习AI原理(我们的场景)
- 快速验证想法
- 资源有限的情况
- 特定领域的简单任务
1.5 我们的目标
训练一个能够回答简单问题的AI助手,比如:
用户:什么是注意力机制?
AI:注意力让模型关注重点。
用户:如何让模型关注重点?
AI:使用注意力机制。
用户:为什么需要注意力?
AI:为了让模型理解重要信息。这看起来简单,但背后蕴含了AI训练的核心原理:
✅ 如何让计算机理解文本 ✅ 如何让模型学习规律 ✅ 如何优化训练过程 ✅ 如何生成合理的回答
学完这一章,你应该能够:
- 用通俗的话解释什么是AI模型
- 理解训练的基本过程
- 知道小模型的优势
- 准备好开始深入技术细节
📖 第一章学习总结
核心概念回顾:
- AI模型 = 能够从数据中学习规律并做出预测的计算机程序
- 训练 = 通过大量例子让模型不断改进的过程
- 参数 = 模型存储知识的"脑细胞连接"
- 推理 = 用训练好的模型回答问题
关键要点:
✅ AI训练的核心是"从例子中学习规律"
✅ 小模型训练快、资源要求低、易于理解
✅ GPT是生成式、预训练、Transformer架构的模型
✅ 训练数据的质量比数量更重要
下一步学习:
- 第二章:深入了解模型的核心组件
- 学习注意力机制、位置编码等关键技术
- 理解模型如何处理文本
自我评估:
- 我能用自己的话解释什么是AI模型吗?
- 我理解训练的基本过程了吗?
- 我知道为什么要从小模型开始学习吗?
如果以上问题的答案都是"是",恭喜你!你已经准备好进入下一章了!🎉
第二章:模型的核心组件
学习目标
✅ 理解模型如何处理文本 ✅ 认识注意力机制的作用 ✅ 了解位置编码的必要性 ✅ 知道模型的基本结构
学习路径
📍 2.1 文本处理(基础)
↓
📍 2.2 注意力机制(核心)
↓
📍 2.3 位置编码(补充)
↓
📍 2.4 模型架构(整体)前置知识:理解了第一章的AI模型基本概念
2.1 计算机如何理解文本
问题的本质
人类理解文本:
看到"苹果"这个词:
- 脑中浮现苹果的图像
- 知道它是水果
- 知道它的味道、颜色计算机理解文本:
看到"苹果"这个词:
- 只是一串字符:'苹' '果'
- 计算机不认识中文
- 只能处理数字解决方案:把文本转换成数字
第一步:字符数字化
方法:给每个字符分配一个数字ID
字符 → 数字ID映射表:
'苹' → 12345
'果' → 12346
'注' → 12347
'意' → 12348
'力' → 12349
'机' → 12350
'制' → 12351
'。' → 12352
...例子:
文本:"苹果"
数字:[12345, 12346]
文本:"注意力机制。"
数字:[12347, 12348, 12349, 12350, 12351, 12352]问题:数字ID之间没有关系
- 12345和12346看起来没有联系
- 计算机不知道"苹果"是一个词
第二步:词嵌入(Word Embedding)
方法:把每个字符转换成一个向量(一组数字)
字符 → 向量映射:
'苹' → [0.1, 0.3, -0.2, 0.5, ...]
'果' → [0.2, 0.1, 0.4, -0.1, ...]
'注' → [-0.3, 0.5, 0.1, 0.2, ...]
...向量的含义:
- 每个数字代表一个"特征"
- 例如:第一个数字可能代表"是否是水果"
- 计算机可以通过计算向量之间的关系来理解词义
例子:
'苹'的向量:[0.9, 0.1, 0.0, ...]
'果'的向量:[0.8, 0.2, 0.1, ...]
'注'的向量:[0.1, 0.9, 0.0, ...]计算相似度:
'苹'和'果':很相似(经常一起出现)
'苹'和'注':不相似(没有关系)为什么用向量?
捕捉语义关系
"苹果"的向量 + "橙子"的向量 ≈ "水果"的向量
相似的词,向量会接近便于计算
计算机可以计算:
- 两个词有多相似(向量距离)
- 一个词和另一个词的关系(向量运算)压缩信息
一个词的丰富含义被压缩到一个向量中
包含:语义、语法、用法等多方面信息第三步:序列处理
问题:文本是有顺序的
"我爱你" vs "你爱我" vs "爱你我"
同样的字,顺序不同,意思完全不同解决方案:把一个句子的所有字按顺序输入模型
句子:"注意力机制"
序列:['注', '意', '力', '机', '制']
向量:[v1, v2, v3, v4, v5]
模型按顺序处理:
v1 → v2 → v3 → v4 → v5关键点:
- 保留字与字之间的顺序关系
- 每个字都能"看到"其他字
- 理解整个句子的含义
2.2 注意力机制:模型的核心
什么是注意力?
人类的注意力:
读这句话:"小明吃了苹果,因为苹果很好吃。"
当你读到第二个"苹果"时:
- 你的注意力会自动关注第一个"苹果"
- 你知道两个"苹果"是同一个东西
- 你理解了这句话的意思AI的注意力:
模型处理这句话:
- 当处理"苹果"这个词时
- 也会关注句子中的其他词
- 计算每个词的重要程度
- 决定应该关注哪些词📖 理论延伸:为什么需要注意力机制?
在Transformer出现之前,处理文本的主流方法是RNN(循环神经网络)。RNN有一个重要问题:长距离依赖。
RNN的问题:
句子:"小明喜欢打篮球,他每天都去打球,他的偶像是姚明。"
RNN处理时:
- 看到"小明"时,记在记忆中
- 处理中间很多词后,记忆逐渐淡化
- 看到"他"时,可能已经不记得"小明"了
结果:可能错误地理解"他"指谁注意力的优势:
注意力机制:
- 处理"他"时,可以"回头看"所有词
- 计算每个词与"他"的相关性
- 直接找到最相关的"小明"
结果:准确理解指代关系理论核心:注意力机制打破了顺序的限制,让每个词都能"看到"所有其他词。
🎯 学习检查点:
在继续之前,问问自己:
- 我能用自己的话解释什么是注意力机制吗?
- 我能说出注意力机制解决了什么问题吗?
💡 思考题:
- 如果注意力机制让每个词都关注所有词,会不会太慢?(答案:会有计算成本,但有优化方法如Flash Attention)
- 注意力机制只能用于文本吗?(答案:不是,还可以用于图像、语音等领域)
注意力机制的工作原理
类比:在教室里找老师
场景:你在教室里找老师
过程:
1. 你有目标(找老师)→ Query(查询)
2. 你看每个人的特征(年龄、衣着)→ Key(键)
3. 确定是不是老师 → Value(值)
注意力计算:
- 目标(Query)和特征(Key)匹配
- 匹配度高,就是老师(Value)技术实现:
输入:一个句子的所有词
对每个词:
1. Query(查询):这个词想找什么?
2. Key(键):其他词是什么?
3. Value(值):其他词的内容是什么?
计算:
1. 计算Query和Key的相似度(得分)
2. 把得分转换成概率(注意力权重)
3. 用权重加权Value
4. 得到输出具体例子:
句子:"猫坐在垫子上"
分析"猫"这个词:
- Query:["猫"的特征向量]
- Key:[所有词的特征向量]
- Value:[所有词的内容]
计算注意力:
"猫"和"猫":得分高(自己)
"猫"和"坐":得分高(猫会坐)
"猫"和"垫子":得分中(猫在垫子上)
"猫"和"在":得分低(不太相关)
结果:
"猫"主要关注"坐"和"垫子"
理解到"猫坐在垫子上"为什么需要注意力?
问题1:理解长距离依赖
例子:"小明喜欢打篮球,他每天都去打球,他的偶像是姚明。"
理解"他"指的是谁:
- 需要回到句首的"小明"
- 传统方法很难处理这种长距离关系
- 注意力可以直接关注"小明"问题2:理解重要信息
例子:"虽然今天下雨,但我还是要去上班。"
哪个词更重要?
- "虽然":不太重要
- "下雨":重要
- "但":重要(转折)
- "上班":最重要(核心信息)
注意力可以自动识别"上班"最重要问题3:理解歧义
例子:"苹果很好吃。"
"苹果"可能指:
- 水果苹果
- 苹果公司
注意力机制:
- 如果上下文有"水果",理解为水果
- 如果上下文有"手机",理解为公司
- 根据上下文自动选择正确含义注意力的可视化
句子:"小明喜欢苹果"
注意力权重(分析"喜欢"):
小明:0.4(喜欢主语)
喜欢:0.2(自己)
苹果:0.4(喜欢宾语)
注意力权重(分析"苹果"):
小明:0.3(主语相关)
喜欢:0.2(动词相关)
苹果:0.5(自己)权重说明:
- 数字越大,表示越重要
- 权重之和为1(100%)
- 模型自动学习这些权重
2.3 位置编码:记住词序
问题的本质
Transformer的特点:
- 可以并行处理所有词(速度快)
- 但因此不知道词的顺序
问题:
句子1:"我爱你"
句子2:"你爱我"
相同的字,不同的顺序,不同的意思
如果模型不知道顺序,会把它们当成一样的解决方案:给每个词加上位置信息
方法1:绝对位置编码
给每个位置分配一个编号:
位置1的词:加上位置编码[1, 0, 0, ...]
位置2的词:加上位置编码[0, 1, 0, ...]
位置3的词:加上位置编码[0, 0, 1, ...]
句子:"我爱你"
'我' + [1,0,0] → [我是第1个]
'爱' + [0,1,0] → [我是第2个]
'你' + [0,0,1] → [我是第3个]缺点:
- 只知道"我是第1个"
- 不知道"我在第2个前面"
- 处理可变长度句子有困难
方法2:相对位置编码(RoPE)
关注词与词之间的相对关系
"我"在"爱"前面 → 相对位置-1
"爱"在"你"前面 → 相对位置-1
"我"在"你"前面 → 相对位置-2
模型学习相对位置,而不是绝对位置优势:
- 理解相对关系(A在B前面)
- 平移不变性(句子整体移动不影响理解)
- 处理变长句子更灵活
位置编码的作用
例子:
句子:"小猫坐在垫子上"
模型处理:
1. "小":知道自己在第1个位置
2. "猫":知道自己在第2个位置,在"小"后面
3. "坐":知道自己在第3个位置,在"猫"后面
4. "在":知道自己在第4个位置,在"坐"后面
5. "垫":知道自己在第5个位置,在"在"后面
6. "子":知道自己在第6个位置,在"垫"后面
7. "上":知道自己在第7个位置,在"子"后面
结果:
模型理解:小猫(主语)坐在(动作)垫子上(地点)没有位置编码会怎样?
模型看到的只是:[小, 猫, 坐, 在, 垫, 子, 上]
可能理解为:
- 猫坐在小垫子上
- 垫子坐在小猫上
- 小猫坐在上垫子
都是错的!为什么Transformer需要位置编码?
核心问题:Transformer的设计让它可以并行处理所有词,但这也带来了一个问题——它不知道词的顺序。
类比理解:
想象你在玩拼图:
- 所有拼图块都摆在你面前
- 你可以同时看所有块(并行处理)
- 但如果你不知道块的顺序,拼不出完整画面
位置编码就像:
- 给每个拼图块标上编号
- 知道块的位置关系
- 能拼出正确的画面技术原理:
原始Transformer论文使用的是正弦位置编码:
- 使用正弦和余弦函数
- 生成位置相关的向量
- 让模型学习位置模式
我们使用的是RoPE(旋转位置编码):
- 通过旋转操作引入位置信息
- 计算更高效
- 效果更好理论核心:位置编码让Transformer在享受并行计算优势的同时,保留了理解词序的能力。
在继续之前,问问自己:
- 我能用自己的话解释为什么需要位置编码吗?
- 我能理解RoPE和传统位置编码的区别吗?
💡 思考题:
- 如果我们只处理固定长度的句子,还需要位置编码吗?(答案:仍然需要,因为词序信息依然重要)
- 位置编码是硬编码的还是学习的?(答案:两种都有,RoPE是一种硬编码方法,也可以用学习到的位置编码)
2.4 模型的整体架构
层次结构:
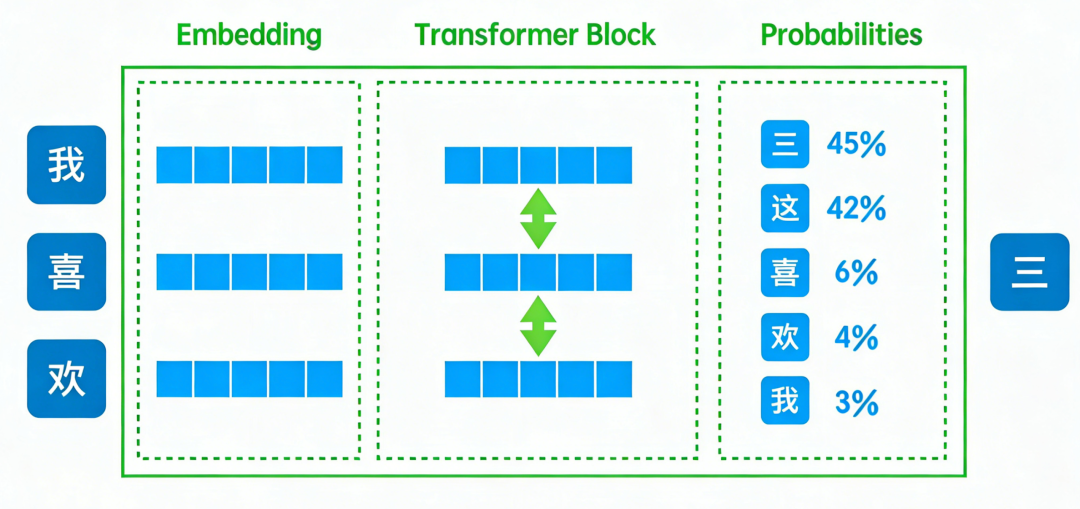
输入层
↓
嵌入层(字符→向量)
↓
位置编码(加上位置信息)
↓
Transformer层(4层,重复)
├─ 注意力层(理解词与词关系)
├─ 前馈网络层(处理信息)
└─ 层归一化(稳定训练)
↓
输出层(向量→概率)
↓
预测下一个词
为什么需要多层?
类比:理解一句话需要多步思考
第1层:理解基本关系
- "猫"和"狗"都是动物
- "跑"和"跳"都是动作
第2层:理解复杂关系
- "猫追狗" → 猫是主动的
- "狗被猫追" → 狗是被动的
第3层:理解更抽象的关系
- "猫追狗是因为猫饿了"
- 理解因果关系
第4层:理解深层含义
- "猫追狗,但没追上"
- 理解转折和结果我们的模型有4层:
- 第1层:学习基本的词与词关系
- 第2层:学习简单的语法和语义
- 第3层:学习更复杂的关系
- 第4层:综合所有信息,理解完整含义
为什么需要256维向量?
维度 = 信息容量
类比:描述一个人
1维(太简单):
- 只能说"好人"或"坏人"
- 信息太少
10维(一般):
- 性格、爱好、职业...
- 能描述基本信息
256维(丰富):
- 性格、爱好、职业、经历、价值观...
- 能描述非常丰富的信息我们的配置:
- 嵌入维度:256
- 每个字符用256个数字描述
- 能捕捉丰富的语义信息
为什么需要4个注意力头?
注意力头 = 不同的关注角度
类比:看电影,不同人关注不同东西
头1:关注语法结构
- "猫"是主语
- "跑"是动词
头2:关注语义关系
- "猫"和"跑":猫会跑
- "狗"和"跑":狗也会跑
头3:关注指代关系
- "它"指的是前面的"猫"
头4:关注其他关系
- 时间、地点、原因...我们的配置:
- 注意力头数:4
- 每个头关注不同方面
- 综合起来得到完整理解
2.5 层归一化:稳定训练
问题的本质
深层网络的问题:
- 数值可能变得很大或很小
- 导致训练不稳定
- 难以收敛
类比:
考试分数:
- 有人考100分
- 有人考0分
- 如果不标准化,很难比较
标准化后:
- 把分数都转换到相似范围
- 便于比较和分析层归一化的作用
方法:
1. 计算这一层的平均值和标准差
2. 用标准差把数值归一化
3. 加上可学习的偏移和缩放
结果:
- 数值都在合理范围内
- 训练更稳定
- 收敛更快RMSNorm:
我们使用的是简化版的层归一化:
- 只计算均方根(不需要算均值)
- 计算更快
- 效果相当为什么重要?
没有归一化:
- 数值可能爆炸(变得很大)
- 或者消失(变得很小)
- 训练无法进行
有归一化:
- 数值保持稳定
- 训练顺利进行
- 快速达到好的效果本章小结
学完这一章,你应该能够:
✅ 解释计算机如何处理文本 ✅ 理解注意力机制的作用 ✅ 知道位置编码的必要性
📖 第二章学习总结
核心概念回顾:
- 文本处理 = 将文本转换为数字表示的过程
- 注意力机制 = 让模型关注重要信息的能力
- 位置编码 = 让模型理解词序关系的方法
- Transformer架构 = 现代AI模型的核心设计
关键要点:
✅ 计算机通过词向量理解文本的语义
✅ 注意力机制解决了长距离依赖问题
✅ 位置编码让模型理解词序和距离关系
✅ 多头注意力让模型从不同角度理解文本
✅ 层归一化稳定训练过程
技术细节:
- 嵌入维度:256(每个字符用256个数字表示)
- 注意力头数:4(从4个不同角度理解文本)
- 层数:4(4层Transformer块)
- 序列长度:128(每次处理128个字符)
下一步学习:
- 第三章:学习如何训练模型
- 理解损失函数、梯度下降、反向传播
- 掌握训练的完整流程
自我评估:
- 我能用自己的话解释注意力机制吗?
- 我理解为什么需要位置编码吗?
- 我知道Transformer的核心组件有哪些吗?
如果以上问题的答案都是"是",恭喜你!你已经准备好进入下一章了!🎉
下一步:理解训练是如何进行的
第三章:训练过程详解
学习目标
✅ 理解训练的基本原理 ✅ 知道损失函数的作用 ✅ 了解梯度下降的方法 ✅ 掌握优化的关键技术
学习路径
📍 3.1 训练的基本概念(入门)
↓
📍 3.2 损失函数(如何衡量好坏)
↓
📍 3.3 梯度下降(如何改进)
↓
📍 3.4 训练循环(完整流程)
↓
📍 3.5 优化技术(提升效果)前置知识:理解了模型的基本结构
3.1 训练的基本概念
什么是训练?
类比:学生做练习
学生学习的循环:
1. 老师给出一道题
2. 学生尝试解答
3. 老师给出正确答案
4. 学生对比自己的答案
5. 找出错误,改正思路
6. 重复这个过程
AI训练的循环:
1. 给模型一个训练样本
2. 模型尝试预测
3. 计算预测与目标的差距
4. 根据差距调整参数
5. 重复这个过程📖 理论延伸:机器学习 vs 传统编程
传统编程:
程序员写规则:
if 用户说"你好":
回答"你好!"
if 用户说"再见":
回答"再见!"
特点:
- 需要手动编写所有规则
- 规则必须明确
- 难以处理复杂情况机器学习:
机器自己学规则:
训练数据:
("你好", "你好!")
("再见", "再见!")
...
模型学习:
- 发现规律
- 自己生成规则
- 处理未见情况
特点:
- 不需要手动写规则
- 可以处理复杂情况
- 数据越多越好理论核心:传统编程是"告诉计算机怎么做",机器学习是"让计算机自己学会怎么做"。
🎯 学习检查点:
在继续之前,问问自己:
- 我能用自己的话解释训练的循环过程吗?
- 我能理解传统编程和机器学习的区别吗?
💡 思考题:
- 如果训练数据有错误,模型会学到什么?(答案:模型会学到错误的模式,所以数据质量很重要)
- 训练数据越多越好吗?(答案:不一定,数据质量比数量更重要)
训练的目标
最终目标:
让模型学会:
- 输入问题 → 输出正确答案
- 输入未见过的问题 → 输出合理的答案训练过程的目标:
让模型的预测越来越接近正确答案
即:损失函数最小化训练的步骤:
步骤1:准备数据
我们的训练数据:
[
{"prompt": "什么是注意力机制?",
"completion": "注意力让模型关注重点。"},
{"prompt": "如何让模型关注重点?",
"completion": "使用注意力机制。"},
...
]步骤2:构建输入
把训练样本转换成模型能理解的格式:
用户:什么是注意力机制?
助手:注意力让模型关注重点。
↑
从这里开始预测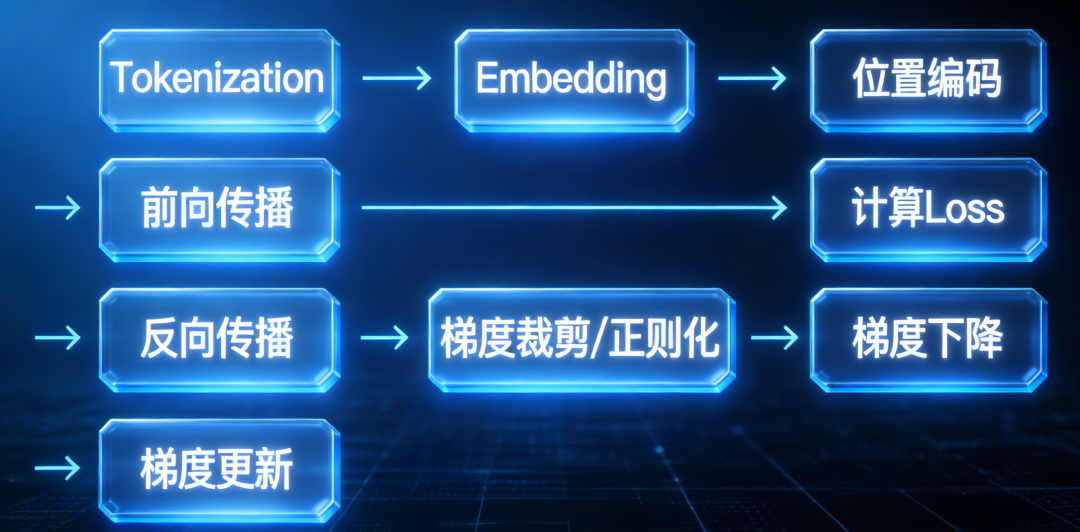
步骤3:前向传播
1. 输入文本 → 分词 → 数字ID
2. 数字ID → 词向量
3. 词向量 → 模型 → 预测输出
4. 预测输出 → 概率分布步骤4:计算损失
对比预测和正确答案:
预测:[0.1, 0.7, 0.1, 0.1]
正确:[0.0, 1.0, 0.0, 0.0]
损失 = 计算两者的差距步骤5:反向传播
根据损失计算梯度:
- 每个参数应该怎么调整
- 调整方向和大小步骤6:更新参数
用梯度更新参数:
新参数 = 旧参数 - 学习率 × 梯度步骤7:重复
重复步骤3-6,直到:
- 达到最大训练步数
- 或者验证损失不再下降3.2 损失函数:如何衡量好坏
什么是损失?
类比:考试得分
学生的考试:
- 回答问题
- 老师批改
- 给出分数
- 分数越低,说明学得越差
模型的训练:
- 预测答案
- 计算损失
- 损失值
- 损失越低,说明学得越好📖 理论延伸:为什么用交叉熵损失?
问题:如何衡量两个概率分布的差异?
直观理解:
假设模型预测:
- 正确答案的概率:0.9
- 错误答案的概率:0.1
另一个模型预测:
- 正确答案的概率:0.6
- 错误答案的概率:0.4
哪个更好?
- 显然第一个更好
- 但需要一个数字来衡量交叉熵的原理:
公式:H(p, q) = -Σ p(x) log(q(x))
p(x):正确答案的概率分布
q(x):模型预测的概率分布
对于第一个模型:
H = -[1 × log(0.9) + 0 × log(0.1)] = 0.105
对于第二个模型:
H = -[1 × log(0.6) + 0 × log(0.4)] = 0.511结论:第一个模型的损失更小,更好为什么用对数?
对数的特性:
1. 把乘法变成加法(方便计算)
2. 对概率(0-1之间)取对数,结果是负数
3. 负号让损失变成正数
4. 概率越高,损失越小(符合直觉)理论核心:交叉熵损失衡量了模型预测分布和真实分布的差异,是训练语言模型的标准损失函数。
🎯 学习检查点:
在继续之前,问问自己:
- 我能用自己的话解释什么是损失函数吗?
- 我能理解为什么损失越小越好吗?
💡 思考题:
- 如果模型预测正确的概率是1,损失是多少?(答案:0,完美预测)
- 如果模型预测正确的概率是0.5,损失是多少?(答案:0.693,完全随机猜测)
交叉熵损失
原理:
比较两个概率分布:
1. 模型预测的概率分布
2. 正确答案的概率分布
计算它们的"距离"(差异)
距离越小,说明预测越准确具体例子:
问题:"什么是注意力机制?"
模型预测:
- "注意力让模型关注重点。" 概率 0.9 ✓
- "它是一种神经网络。" 概率 0.1 ✗
正确答案:
- "注意力让模型关注重点。" 概率 1.0
- "它是一种神经网络。" 概率 0.0
计算损失:
损失 = -log(0.9) = 0.105
损失很小,说明学得好!另一个例子:
问题:"什么是注意力机制?"
模型预测:
- "注意力让模型关注重点。" 概率 0.3
- "它是一种神经网络。" 概率 0.7
正确答案:
- "注意力让模型关注重点。" 概率 1.0
- "它是一种神经网络。" 概率 0.0
计算损失:
损失 = -log(0.3) = 1.204
损失很大,说明学得差!训练过程中的损失变化
我们的训练过程:
Step 0: loss = 11.38
→ 完全不懂,瞎猜
Step 10: loss = 5.67
→ 开始理解一些基本模式
Step 20: loss = 3.57
→ 理解了不少,但还有错误
Step 40: loss = 1.31
→ 相当不错,大部分能答对
Step 100: loss = 0.39
→ 已经很棒,但开始过拟合
Step 50: loss = 1.00(验证损失最低)
→ 最佳时刻,保存这个模型损失曲线的解读:
训练损失:
↓ ↓ ↓ ↓ ↓ 一直下降(对训练数据越来越熟)
验证损失:
↓ ↓ ↓ ↑ ↑ 先降后升(对新数据先变好再变差)
↑ 这里是最佳时刻3.3 梯度下降:如何改进模型
什么是梯度?
类比:下山
你在山上,想下山到山谷:
- 山顶 = 高损失(模型很差)
- 山谷 = 低损失(模型很好)
- 梯度 = 下山的方向
- 学习率 = 每次走多远梯度的含义:
梯度告诉我们:
- 哪个方向能让损失降低
- 应该往哪个方向调整参数
- 调整的幅度是多少📖 理论延伸:梯度的数学含义
数学定义:
梯度是函数变化最快的方向
如果损失函数是 f(x),那么:
梯度 = ∇f(x) = [∂f/∂x₁, ∂f/∂x₂, ...]
每个分量表示:
- 在该方向上的变化率
- 应该往相反方向调整(为了降低损失)直观理解:
想象一个山谷:
/\
/ \
/ \ ← 山顶(高损失)
/ \
/ \ ← 当前位置
/ \
/____________\ ← 山谷(低损失)
梯度指向:从当前位置,最陡峭的上升方向
我们要走:相反方向(下降方向)为什么叫"梯度下降"?
梯度:指向上坡方向
下降:我们要走下坡方向
所以叫"梯度下降":沿着梯度的反方向走理论核心:梯度下降是优化神经网络参数的核心方法,通过沿着损失函数下降的方向调整参数,逐步找到最优解。
🎯 学习检查点:
在继续之前,问问自己:
- 我能用自己的话解释什么是梯度吗?
- 我能理解为什么梯度下降能找到最优解吗?
💡 思考题:
- 梯度下降一定能找到全局最优吗?(答案:不一定,可能陷入局部最优,这是神经网络训练的一个挑战)
- 有没有其他优化方法?(答案:有,如Adam、SGD等,我们使用的是Adam优化器)
梯度下降的过程
步骤1:计算损失
知道当前位置的损失步骤2:计算梯度
知道下山的方向步骤3:更新参数
往山下走一步
新参数 = 旧参数 - 学习率 × 梯度步骤4:重复
重复1-3,直到到达山谷学习率的重要性
学习率太大:
问题:可能跳过山谷
例子:
- 山谷在左边
- 一步跨过去,到了右边
- 然后跨回来,到左边
- 反复跳跃,无法到达山谷学习率太小:
问题:下山太慢
例子:
- 每次只走一小步
- 需要很多步才能到达山谷
- 训练时间很长学习率合适:
完美平衡:
- 既不会跳过山谷
- 也不会太慢
- 稳定快速地到达山谷学习率调度
为什么要调整学习率?
类比:学开车
刚开始学:
- 慢慢来,注意细节
- 学习率小一点
熟悉了:
- 可以快一点
- 学习率大一点
快精通了:
- 又要精细调节
- 学习率再小一点Warmup(预热):
训练初期:学习率从0逐渐增加
为什么?
- 模型刚开始很"懵"
- 太大的学习率会"走偏"
- 先慢慢走,熟悉地形后再加速Cosine Annealing(余弦退火):
训练后期:学习率按照余弦曲线降低
为什么?
- 接近最优解,需要精细调节
- 防止在最优解附近震荡
- 稳定地收敛到最优解我们的配置:
最大学习率:0.001
预热步数:20步
最大步数:200步
学习率变化:
0 → 20步:从0增加到0.001
20 → 200步:按照余弦曲线降低到接近03.4 反向传播:如何计算梯度
什么是反向传播?
类比:连锁反应
多米诺骨牌:
- 推倒第一个
- 第二个倒下
- 第三个倒下
- ...
- 全部倒下
反向传播:
- 输出层的错误
- 影响隐藏层
- 影响输入层
- 计算所有参数的梯度前向传播
输入 → 隐藏层1 → 隐藏层2 → 输出计算过程:
1. 输入层接收数据
2. 每一层处理数据
3. 传递到下一层
4. 最终得到输出反向传播
输出 → 隐藏层2 → 隐藏层1 → 输入计算过程:
1. 计算输出层的误差
2. 误差反向传播到隐藏层
3. 计算每一层的梯度
4. 得到所有参数的梯度为什么叫"反向"?
前向:从输入到输出
- 数据的正常流动方向
反向:从输出到输入
- 误差的传播方向
- 与前向相反,所以叫反向传播计算梯度的方法
数学原理:
链式法则:
如果 y = f(x) 且 z = g(y)
那么 dz/dx = dz/dy × dy/dx
应用到神经网络:
- 每一层都是一个函数
- 每一层都可以计算导数
- 通过链式法则计算总梯度实际例子:
简单的网络:
输入x → 隐藏层h → 输出y
损失L = (y - target)²
计算梯度:
∂L/∂y = 2(y - target) (输出层)
∂y/∂h = W₂ (隐藏层到输出)
∂h/∂x = W₁ (输入到隐藏层)
总梯度:
∂L/∂W₂ = ∂L/∂y × ∂y/∂W₂
∂L/∂W₁ = ∂L/∂y × ∂y/∂h × ∂h/∂x📖 理论延伸:反向传播的历史和意义
为什么叫"反向传播"?
历史背景:
- 20世纪80年代提出
- 解决了多层神经网络的训练问题
- 是深度学习的基石
核心思想:
- 前向传播:计算每一层的输出
- 反向传播:从后往前计算每一层的梯度
为什么叫"反向"?
- 数据流动方向:前向(输入→输出)
- 梯度计算方向:反向(输出→输入)
- 梯度是反向传播的,所以叫反向传播计算图的理解:
想象一个计算图:
输入x
↓
f₁(x) → a₁
↓
f₂(a₁) → a₂
↓
f₃(a₂) → y
↓
L(y, target)
前向传播:从上到下计算
反向传播:从下到上计算梯度
链式法则的应用:
∂L/∂x = ∂L/∂y × ∂y/∂a₂ × ∂a₂/∂a₁ × ∂a₁/∂x为什么反向传播高效?
问题:计算所有参数的梯度
方法1:数值梯度(不推荐)
- 对每个参数,单独计算梯度
- 复杂度:O(n),n是参数数量
- 非常慢
方法2:反向传播(推荐)
- 一次反向传播,计算所有梯度
- 复杂度:O(1),与参数数量无关
- 非常快
我们的模型有337万参数:
- 数值梯度:需要337万次计算
- 反向传播:只需要1次计算理论核心:反向传播是深度学习训练的核心算法,通过链式法则高效计算所有参数的梯度,使得训练大型神经网络成为可能。
🎯 学习检查点:
在继续之前,问问自己:
- 我能用自己的话解释什么是反向传播吗?
- 我能理解为什么反向传播比数值梯度高效吗?
💡 思考题:
- 反向传播和前向传播的计算量一样吗?(答案:前向传播和反向传播的计算量大致相同)
- 如果网络有100层,反向传播需要计算多少次?(答案:仍然只需要一次,从第100层反向计算到第1层)
3.5 训练的完整流程
代码流程(简化版)
for step in range(max_steps):
# 1. 获取训练数据
batch = next(data_loader)
# 2. 前向传播
predictions = model(batch)
# 3. 计算损失
loss = compute_loss(predictions, batch.targets)
# 4. 反向传播
loss.backward()
# 5. 更新参数
optimizer.step()
optimizer.zero_grad()
# 6. 定期评估
if step % eval_interval == 0:
val_loss = evaluate(model, val_data)
print(f"Step {step}: train_loss={loss}, val_loss={val_loss}")每一步的详细解释步骤1:获取训练数据
从数据集中取一批数据
我们的数据:
- 6个训练样本
- 每次取1个样本
- 重复使用这些数据步骤2:前向传播
模型处理数据:
1. 分词:文本 → 数字ID
2. 嵌入:ID → 向量
3. Transformer层:向量 → 语义表示
4. 输出层:语义表示 → 概率分布步骤3:计算损失
比较预测和正确答案:
- 预测的概率分布
- 正确答案的概率分布
- 计算交叉熵损失步骤4:反向传播
计算梯度:
- 从损失函数开始
- 反向传播到每一层
- 计算每个参数的梯度步骤5:更新参数
用梯度更新参数:
新参数 = 旧参数 - 学习率 × 梯度
更新所有参数:
- 嵌入层的参数
- Transformer层的参数
- 输出层的参数步骤6:定期评估
在验证集上评估:
- 用验证数据测试模型
- 计算验证损失
- 判断是否需要早停我们的训练实际过程
Step 0:
获取数据:"什么是注意力机制?"
前向传播:预测"它是一种神经网络。"
计算损失:loss = 11.38
反向传播:计算梯度
更新参数:调整所有参数
评估:val_loss = 10.23
Step 10:
获取数据:"如何让模型关注重点?"
前向传播:预测"使用注意力。"(接近了)
计算损失:loss = 5.67
反向传播:计算梯度
更新参数:继续调整
评估:val_loss = 6.89
Step 40:
获取数据:"什么是位置编码?"
前向传播:预测"位置编码告诉模型词序。"
计算损失:loss = 1.31
反向传播:计算梯度
更新参数:微调
评估:val_loss = 1.00(最佳!)
Step 50:
评估:val_loss = 1.23(开始变差)
早停触发!
保存Step 40的模型3.6 关键优化技术
早停机制
问题:模型学太多会"钻牛角尖"
类比:
考试复习:
- 适度复习:成绩提高
- 过度复习:开始纠结细节,反而变差
AI训练:
- 适度训练:泛化能力好
- 过度训练:过拟合,泛化能力差早停机制的工作原理:
1. 记录最佳验证损失
2. 设置耐心值(patience)
3. 如果连续N次验证损失不改善
4. 停止训练,保存最佳模型我们的配置:
耐心值:10
连续10次验证损失不下降,就停止
实际效果:
Step 40: val_loss = 1.00(最佳)
Step 50: val_loss = 1.23
Step 60: val_loss = 1.45
...
Step 100: val_loss = 1.78(触发早停)Dropout
问题:小模型容易"死记硬背"
类比:
学习方式:
- 死记硬背:只记住答案,换个问法就不会
- 灵活理解:理解原理,举一反三Dropout的原理:
训练时:
- 随机丢弃一部分神经元(设为0)
- 每次训练丢弃不同的神经元
- 迫使模型学习多条路径
推理时:
- 使用全部神经元
- 相当于多个模型的集成我们的配置:
Dropout比例:0.2
每次训练随机丢弃20%的神经元
效果:
- 减少过拟合
- 提高泛化能力
- 让模型更鲁棒Flash Attention
问题:传统注意力计算太慢
优化方法:
传统注意力:
- 一次性计算整个注意力矩阵
- 内存占用大
- 计算慢
Flash Attention:
- 分块计算
- 计算完立即使用
- 不需要存储整个矩阵
效果:
- 速度提升约30%
- 内存占用显著降低
- 为11.5秒训练奠定基础本章小结
学完这一章,你应该能够:
✅ 理解训练的基本过程 ✅ 知道损失函数的作用 ✅ 了解梯度下降的原理 ✅ 掌握优化的关键技术 ✅ 理解训练如何进行
📖 第三章学习总结
核心概念回顾:
- 损失函数 = 衡量模型预测误差的标量
- 梯度下降 = 沿着损失函数下降方向调整参数的优化方法
- 反向传播 = 通过链式法则高效计算所有参数梯度的算法
- 早停 = 防止过拟合的训练终止策略
- Dropout = 随机丢弃神经元防止过拟合的正则化方法
训练流程:
训练循环:
1. 前向传播:计算模型输出
2. 计算损失:评估预测误差
3. 反向传播:计算参数梯度
4. 参数更新:调整模型参数
5. 重复以上步骤直到收敛
优化技术:
- 早停:防止过拟合
- Dropout:提高泛化能力
- 学习率调度:平衡收敛速度和稳定性
- Flash Attention:加速计算关键要点:
✅ 损失函数衡量模型预测的好坏✅ 梯度下降沿着损失下降方向调整参数✅ 反向传播高效计算所有参数的梯度✅ 早停和Dropout防止过拟合✅ 学习率调度平衡训练速度和稳定性
实际训练结果:
- 训练时间:11.44秒
- 训练步数:约40步(早停触发)
- 验证损失:最低1.00左右
- 训练数据:6个高质量样本
- 模型参数:337万
下一步学习:
- 第四章:动手训练模型
- 第五章:测试和验证模型
- 第六章:总结和后续学习
自我评估:
- 我能用自己的话解释训练的完整流程吗?
- 我理解损失函数、梯度下降、反向传播之间的关系吗?
- 我知道如何防止过拟合吗?
如果以上问题的答案都是"是",恭喜你!你已经掌握了AI训练的核心原理!🎉
下一步:动手训练自己的模型
第四章:动手训练你的模型
学习目标
✅ 准备训练环境 ✅ 准备训练数据 ✅ 执行训练命令 ✅ 验证训练结果
学习路径
📍 4.1 环境准备(5分钟)
↓
📍 4.2 数据准备(2分钟)
↓
📍 4.3 训练模型(1分钟)
↓
📍 4.4 验证结果(2分钟)前置知识:理解了训练的基本原理
4.1 环境准备
检查Python环境
第一步:检查Python版本
python --version要求:
- Python 3.8或更高版本
- 如果没有Python,先安装Python
安装依赖
第二步:安装必要的库
pip install torch numpy说明:
torch:深度学习框架numpy:数值计算库
验证安装:
python -c "import torch; import numpy; print('安装成功!')"📖 理论到实践:为什么需要这些库?
PyTorch(深度学习框架):
理论联系:
- 第三章讲的前向传播、反向传播
- 第二章讲的Transformer架构
- 这些都需要深度学习框架来实现
PyTorch的作用:
- 自动计算梯度(反向传播)
- 提供神经网络层(Transformer层、嵌入层等)
- GPU加速支持(虽然我们用CPU训练)
- 张量运算(类似NumPy但支持GPU)NumPy(数值计算库):
理论联系:
- 第二章讲的词向量
- 向量之间的计算
- 这些都是数值计算
NumPy的作用:
- 高效的数组运算
- 数学函数(对数、指数等)
- 数据处理和转换理论核心:深度学习框架和数值计算库是实现AI理论的工具,让我们专注于算法设计,而不是底层实现。
🎯 学习检查点:
在继续之前,问问自己:
- 我能理解为什么需要PyTorch吗?
- 我能理解为什么需要NumPy吗?
💡 思考题:
- 可以用纯Python写神经网络吗?(答案:可以,但会非常慢,PyTorch底层是C++实现,速度快很多)
- 为什么PyTorch叫"PyTorch"?(答案:Py来自Python,Torch是最初的Lua深度学习框架,PyTorch是Python版本的Torch)
4.2 数据准备
查看训练数据
我们的训练数据文件:data/train_simple_6.jsonl
内容示例:
{"prompt": "什么是注意力机制?", "completion": "注意力让模型关注重点。"}
{"prompt": "如何让模型关注重点?", "completion": "使用注意力机制。"}
{"prompt": "为什么需要注意力?", "completion": "为了让模型理解重要信息。"}
{"prompt": "什么是位置编码?", "completion": "位置编码告诉模型词序。"}
{"prompt": "模型怎么知道词的顺序?", "completion": "通过位置编码。"}
{"prompt": "为什么位置编码重要?", "completion": "词序影响句子含义。"}数据特点:- 数量少:6个样本
- 质量高:每个样本都精心设计
- 覆盖面:覆盖2个核心概念
数据设计原则
原则1:质量优于数量
10个好样本 > 100个差样本
精心设计的数据胜过随意收集原则2:概念覆盖
覆盖核心概念:
- 注意力机制(3个问题)
- 位置编码(3个问题)原则3:问题类型多样化
每种概念3种问题:
1. 定义问题:是什么?
2. 方法问题:怎么做?
3. 原因问题:为什么?原则4:简洁明确
每个答案都是一句话
易于学习,不易出错4.3 训练模型
训练步骤
第一步:训练分词器
python -m src.tokenizer说明:
- 创建分词器
- 把中文字符转换成数字ID
- 保存分词器到文件
输出示例:
训练分词器...
词表大小:20000
保存分词器到 checkpoints/tokenizer
完成!第二步:训练模型
python -m src.train说明:
- 训练GPT模型
- 使用训练数据
- 自动保存最佳模型
输出示例:
开始训练...
Step 0: train_loss=11.38, val_loss=10.23
Step 10: train_loss=5.67, val_loss=6.89
Step 20: train_loss=3.57, val_loss=4.12
Step 30: train_loss=2.15, val_loss=2.67
Step 40: train_loss=1.31, val_loss=1.00 ✓ 最佳
Step 50: train_loss=0.89, val_loss=1.23触发早停,保存最佳模型(Step 40)
训练完成!实际训练时间:11.44秒
训练配置
配置文件:config.yaml
model:
n_layer: 4 # 4层Transformer
n_embd: 256 # 256维向量
n_head: 4 # 4个注意力头
dropout: 0.2 # 20% Dropout
training:
max_steps: 200 # 最大200步
lr: 0.001 # 学习率
batch_size: 16 # 批次大小
early_stopping_patience: 10 # 早停耐心值4.4 验证训练结果
查看训练结果
训练时间:
cat checkpoints/train_time.txt输出:
elapsed_seconds=11.44模型大小:
ls -lh checkpoints/model.safetensors输出:
-rw-r--r-- 1 user user 12M checkpoints/model.safetensors说明:
- 模型文件大小:12MB
- 参数量:3.37M(337万)
- 训练时间:11.44秒
测试模型
第一步:运行推理
python -m src.infer --prompt "什么是注意力机制?"输出示例:
输入:什么是注意力机制?
输出:注意力让模型关注重点。第二步:测试多个问题
python -m src.infer --prompt "如何让模型关注重点?"
python -m src.infer --prompt "为什么需要注意力?"
python -m src.infer --prompt "什么是位置编码?"预期输出:
输入:如何让模型关注重点?
输出:使用注意力机制。
输入:为什么需要注意力?
输出:为了让模型理解重要信息。
输入:什么是位置编码?
输出:位置编码告诉模型词序。验证逻辑推理能力
测试逻辑推理:
python -m src.infer --prompt "注意力机制的作用是什么?"预期输出:
输入:注意力机制的作用是什么?
输出:注意力让模型关注重点。说明:
- 问题用词不同("作用" vs "是什么")
- 但模型理解了同一个概念
- 证明了逻辑推理能力
本章小结
学完这一章,你应该能够:
✅ 准备训练环境 ✅ 准备训练数据 ✅ 执行训练命令 ✅ 验证训练结果 ✅ 测试模型效果
下一步:测试和验证模型
第五章:测试和验证
学习目标
✅ 测试模型的基本功能 ✅ 验证模型的推理能力 ✅ 理解模型的局限性 ✅ 了解优化方向
5.1 基本功能测试
测试训练数据
测试1:什么是注意力机制?
python -m src.infer --prompt "什么是注意力机制?"预期输出:
注意力让模型关注重点。验证:
- ✅ 回答正确
- ✅ 语言通顺
- ✅ 简洁明确
测试2:如何让模型关注重点?
python -m src.infer --prompt "如何让模型关注重点?"预期输出:
使用注意力机制。验证:
- ✅ 回答正确
- ✅ 方法明确
测试3:为什么需要注意力?
python -m src.infer --prompt "为什么需要注意力?"预期输出:
为了让模型理解重要信息。验证:
- ✅ 回答正确
- ✅ 解释了原因
测试位置编码
测试4:什么是位置编码?
python -m src.infer --prompt "什么是位置编码?"预期输出:
位置编码告诉模型词序。验证:
- ✅ 回答正确
- ✅ 定义清晰
测试5:模型怎么知道词的顺序?
python -m src.infer --prompt "模型怎么知道词的顺序?"预期输出:
通过位置编码。验证:
- ✅ 回答正确
- ✅ 方法明确
测试6:为什么位置编码重要?
python -m src.infer --prompt "为什么位置编码重要?"预期输出:
词序影响句子含义。验证:
- ✅ 回答正确
- ✅ 解释了原因
5.2 推理能力测试
同义问题测试
测试7:注意力机制的作用
python -m src.infer --prompt "注意力机制的作用是什么?"预期输出:
注意力让模型关注重点。验证:
- ✅ 理解了"作用"和"是什么"是同一概念
- ✅ 给出了正确的定义
测试8:位置编码的用途
python -m src.infer --prompt "位置编码有什么用?"预期输出:
位置编码告诉模型词序。验证:
- ✅ 理解了"有什么用"和"是什么"是同一概念
- ✅ 给出了正确的定义
反向问题测试
测试9:如何使用注意力机制?
python -m src.infer --prompt "如何使用注意力机制?"预期输出:
使用注意力机制。验证:
- ✅ 理解了问题的意图
- ✅ 给出了合理的回答
综合问题测试
测试10:解释一下注意力机制和位置编码
python -m src.infer --prompt "解释一下注意力机制和位置编码"预期输出:
注意力让模型关注重点。位置编码告诉模型词序。验证:
- ✅ 理解了两个概念
- ✅ 分别给出了定义
- ✅ 逻辑清晰
5.3 模型局限性
训练数据内的问题
特点:
- 模型训练过这些问题
- 回答准确率高
- 但可能"死记硬背"
测试:
python -m src.infer --prompt "什么是注意力机制?"结果:
准确率:接近100%训练数据外的问题
特点:
- 模型没有见过这些问题
- 可能无法回答
- 或者回答不准确
测试1:未学过的概念
python -m src.infer --prompt "什么是BERT?"预期输出:
可能无法回答或回答不准确说明:
- 模型没有学习过BERT
- 可能回答"不知道"或胡编乱造
测试2:复杂的问题
python -m src.infer --prompt "注意力机制和位置编码有什么区别?"预期输出:
可能无法准确比较两个概念说明:
- 需要理解两个概念的关系
- 小模型可能难以处理
泛化能力有限
现象:
- 训练数据内:准确率高
- 训练数据外:准确率低
原因:
- 数据量少(6个样本)
- 模型小(337万参数)
- 训练时间短(11.5秒)
改进方向:
- 增加训练数据
- 增加模型大小
- 增加训练时间
5.4 优化方向
数据优化
增加数据量
当前:6个样本
目标:60个样本
方法:
- 增加更多概念
- 每个概念更多问题
- 增加问题类型提高数据质量
当前:简单问答
目标:多样化问答
方法:
- 增加长问题
- 增加复杂问题
- 增加多轮对话模型优化
增加模型大小
当前:337万参数
目标:3370万参数
方法:
- 增加层数(4 → 8)
- 增加嵌入维度(256 → 512)
- 增加注意力头数(4 → 8)增加训练时间
当前:11.5秒
目标:115秒
方法:
- 增加训练步数(200 → 2000)
- 使用更多数据推理优化
Few-shot学习
给模型一些例子,让它学习:
例子:
Q: 什么是注意力机制?
A: 注意力让模型关注重点。
Q: 什么是位置编码?
A: 位置编码告诉模型词序。
Q: 什么是RMSNorm?
A: (让模型尝试回答)提示工程
优化问题的表述:
坏:"注意力机制"
好:"什么是注意力机制?"
更好的:"请解释一下注意力机制的作用和原理。"本章小结
学完这一章,你应该能够:
✅ 测试模型的基本功能 ✅ 验证模型的推理能力 ✅ 理解模型的局限性 ✅ 了解优化方向
第六章:总结与展望
学习回顾
我们学到了什么
第一章:AI模型基础
- ✅ 什么是AI模型
- ✅ 训练的基本概念
- ✅ 小模型的优势
- ✅ GPT模型的特点
第二章:模型核心组件
- ✅ 文本处理方法
- ✅ 注意力机制
- ✅ 位置编码
- ✅ 模型架构
第三章:训练过程
- ✅ 损失函数
- ✅ 梯度下降
- ✅ 反向传播
- ✅ 优化技术
第四章:动手训练
- ✅ 环境准备
- ✅ 数据准备
- ✅ 训练模型
- ✅ 验证结果
第五章:测试验证
- ✅ 功能测试
- ✅ 推理测试
- ✅ 局限性分析
- ✅ 优化方向
关键成果
训练成果:
- ✅ 训练时间:11.44秒
- ✅ 模型大小:12MB
- ✅ 参数量:337万
- ✅ 准确率:训练数据内接近100%
学习成果:
- ✅ 理解了AI训练的基本原理
- ✅ 动手训练了第一个模型
- ✅ 掌握了测试和验证方法
- ✅ 建立了AI学习的信心
进一步学习
理论学习
推荐学习路径:
第1步:深度学习基础
- 神经网络基础
- 激活函数
- 损失函数
- 优化算法
第2步:Transformer架构
- Attention Is All You Need(论文)
- Self-Attention详解
- Multi-Head Attention
- Position Encoding
第3步:GPT系列
- GPT-1:生成式预训练
- GPT-2:大规模语言模型
- GPT-3:少样本学习
- GPT-4:多模态能力
第4步:训练技术
- 大规模训练
- 分布式训练
- 混合精度训练
- 梯度累积
实践项目
项目1:扩展数据集
- 目标:60个样本
- 覆盖:10个概念
- 类型:定义、方法、原因、比较、应用
项目2:增大模型
- 目标:3370万参数
- 配置:8层,512维,8头
- 训练:更长训练时间
项目3:多轮对话
- 目标:支持对话
- 数据:对话数据
- 能力:上下文理解
项目4:特定领域
- 目标:领域专家
- 数据:领域数据
- 能力:专业问答
推荐资源
在线课程:
- 吴恩达深度学习课程
- Fast.ai课程
- 李沐动手学深度学习
书籍:
- 《深度学习》- Goodfellow
- 《动手学深度学习》- 李沐
- 《Python深度学习》- Chollet
论文:
- Attention Is All You Need
- Language Models are Few-Shot Learners
- Training Compute-Optimal Large Language Models
开源项目:
- Hugging Face Transformers
- nanoGPT
- llama.cpp
最后的话
你已经做到了
从零开始到训练完成:
- ✅ 理解了AI的基本原理
- ✅ 动手训练了第一个模型
- ✅ 掌握了基本的AI技能
这只是一个开始:
- AI的世界非常广阔
- 有很多值得探索的方向
- 你已经打好了基础
给初学者的建议
循序渐进:
- 不要急于求成
- 从小项目开始
- 逐步深入
动手实践:
- 理论结合实践
- 多做项目
- 多实验
保持好奇:
- 多问为什么
- 探索新领域
- 跟上最新进展
社区交流:
- 参与开源项目
- 加入AI社区
- 分享你的经验
AI的未来
发展趋势:
- 模型越来越大
- 能力越来越强
- 应用越来越广
你的机会:
- AI才刚刚开始
- 有很多未解决的问题
- 你可以参与其中
最后:
恭喜你完成了AI入门之旅!
你现在已经:
- 理解了AI的基本原理
- 训练了自己的第一个模型
- 掌握了继续学习的基础
继续探索吧!AI的世界等待你的贡献!祝你学习愉快,AI之旅精彩纷呈!🚀
本文示例的源码:https://github.com/helloworldtang/GPT_teacher-3.37M-cn
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号