从零玩转 LangChain:新手入门指南+完整可运行github源码(文末有token福利,先到先得)

从零玩转 LangChain:新手入门指南+完整可运行github源码(文末有token福利,先到先得)

烟雨平生
发布于 2026-04-14 19:15:19
发布于 2026-04-14 19:15:19
前言:为什么要学 LangChain?
你有没有这样的困惑:
- 想用大模型做点实际业务,但不知道从哪下手
- 调 API 调了一堆,代码越来越乱
- 想让 AI 帮你查数据库、调接口,但不知道怎么让 AI "动手"
- 看着别人做的 AI 应用眼红,自己只会调 chat 接口
LangChain 就是来解决这些问题的。
简单说,LangChain 是一个 "搭积木"的框架,帮你把大模型、数据库、API、工具等组件拼在一起,快速构建 AI 应用。
一、LangChain 是什么?
1.1 一句话解释
LangChain = 大模型 + 工具链 + 记忆 + 逻辑编排
它让你不用从零开始写 AI 应用,而是像搭乐高一样组装各种模块。
1.2 为什么要用 LangChain?
不用 LangChain | 用 LangChain |
|---|---|
自己写 API 调用、重试、超时 | 一行代码调用 LLM |
自己管理对话历史、上下文 | 内置 Memory 模块 |
自己实现 Function Call 逻辑 | Tools 自动绑定 |
自己写 Agent 决策逻辑 | Agent 开箱即用 |
自己处理流式输出 | Callback 自动处理 |
一句话:LangChain 让你专注于业务逻辑,而不是基础设施。
二、从简单到复杂:八大场景实战
本文完整配套项目见文末
场景一:LLM 直接调用
解决的问题:最基本的 AI 对话能力
代码示例
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
load_dotenv() # 从 .env 文件加载 API Key
# 创建 LLM 实例(使用 DeepSeek)
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_base="https://api.deepseek.com/v1",
openai_api_key=os.getenv("DEEPSEEK_API_KEY"),
temperature=0.7
)
# 直接调用
response = llm.invoke("你好,请介绍一下你自己")
print(response.content)流式输出
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_base="https://api.deepseek.com/v1",
openai_api_key=os.getenv("DEEPSEEK_API_KEY"),
streaming=True
)
for chunk in llm.stream("用三句话介绍 Python"):
print(chunk.content, end="", flush=True)关键点
使用环境变量:不要硬编码 API Key。生产环境配置在配置中心即可。
# .env 文件
DEEPSEEK_API_KEY=sk-xxx温度参数:
temperature=0:确定性输出,适合代码生成temperature=0.7:创造性输出,适合写作
场景二:Function Call(工具调用)
解决的问题:让 AI 能调用外部工具(查天气、查数据库、调 API)
原理图
用户问题:"北京今天天气怎么样?"
↓
LLM 分析:需要调用天气工具
↓
返回工具调用:get_weather(city="北京")
↓
你的代码执行工具,返回结果
↓
LLM 整理答案:"北京今天晴天,温度 15°C"代码示例
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# 1. 定义工具
@tool
def get_weather(city: str) -> str:
"""查询指定城市的天气"""
weather_data = {
"北京": "晴天,温度 15°C",
"上海": "多云,温度 18°C",
}
return weather_data.get(city, f"{city}:暂无天气数据")
# 2. 绑定工具到 LLM
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_base="https://api.deepseek.com/v1",
openai_api_key=os.getenv("DEEPSEEK_API_KEY")
)
llm_with_tools = llm.bind_tools([get_weather])
# 3. 调用
response = llm_with_tools.invoke("北京今天天气怎么样?")
# 4. 检查是否需要调用工具
if response.tool_calls:
for tool_call in response.tool_calls:
print(f"需要调用工具:{tool_call['name']}")
print(f"参数:{tool_call['args']}")关键点
- 工具描述很重要:LLM 根据描述决定是否调用
- 工具数量:建议控制在 10 个以内
场景三:Memory(对话记忆)
解决的问题:让 AI 记住之前的对话内容
代码示例
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_base="https://api.deepseek.com/v1",
openai_api_key=os.getenv("DEEPSEEK_API_KEY")
)
history = InMemoryChatMessageHistory()
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有帮助的助手。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
chain = prompt | llm
def chat(input_text: str) -> str:
response = chain.invoke({
"history": history.messages,
"input": input_text
})
history.add_user_message(input_text)
history.add_ai_message(response.content)
return response.content
# 多轮对话
chat("你好,我叫小明")
chat("我叫什么名字?") # AI 会记住"小明"场景四:RAG
解决的问题:让 LLM 回答它训练数据中没有的问题,有助于解决LLM事实类幻觉。
RAG(Retrieval-Augmented Generation,检索增强生成) 流程
用户问题:"公司的报销流程是什么?"
↓
1. 检索:从知识库中找相关文档
↓
2. 构建 Prompt:问题 + 相关文档
↓
3. 生成:LLM 基于文档回答代码示例
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# 1. 文档切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, # 每块最大字符数
chunk_overlap=50 # 块之间的重叠
)
chunks = text_splitter.split_text(documents)
# 2. 创建向量数据库
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.from_texts(chunks, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 3. 构建 RAG 链
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
prompt = ChatPromptTemplate.from_template("""
根据以下上下文回答问题:
{context}
问题:{question}
""")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | RunnableLambda(format_docs), "question": RunnablePassthrough()}
| prompt
| llm
)
response = rag_chain.invoke("什么是 RAG?")场景五:结构化输出
解决的问题:让 LLM 返回结构化数据,而不是自由文本
代码示例
from pydantic import BaseModel, Field
from typing import List
from langchain_core.output_parsers import PydanticOutputParser
# 定义数据模型
class ProductInfo(BaseModel):
"""商品信息"""
name: str = Field(description="商品名称")
price: float = Field(description="价格")
category: str = Field(description="分类")
features: List[str] = Field(description="特点列表")
# 创建解析器
parser = PydanticOutputParser(pydantic_object=ProductInfo)
# 构建 Prompt
prompt = ChatPromptTemplate.from_template("""
{format_instructions}
请分析以下产品:{product}
""")
chain = prompt | llm | parser
# 执行
result = chain.invoke({
"product": "iPhone 15",
"format_instructions": parser.get_format_instructions()
})
# result 是 ProductInfo 对象
print(result.name) # "iPhone 15"
print(result.price) # 6999.0
print(result.features) # ["A16芯片", ...]场景六:Agent(智能体)
解决的问题:让 AI 自主决策、自主选择工具
Agent 工作流程
用户问题:"帮我查下茅台股票,然后分析下值不值得买"
↓
Agent 思考:这个任务需要两个步骤
↓
步骤 1:调用 get_stock 获取股价
↓
步骤 2:调用 analyze_stock 分析投资价值
↓
Agent 整理答案代码示例
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# 定义工具
@tool
def get_stock_price(symbol: str) -> str:
"""查询股票实时价格"""
return f"{symbol} 当前价格 1850.5 元"
@tool
def analyze_stock(symbol: str) -> str:
"""分析股票投资价值"""
return f"{symbol} PE 估值合理,建议关注"
# 绑定工具
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_base="https://api.deepseek.com/v1",
openai_api_key=os.getenv("DEEPSEEK_API_KEY")
)
tools = [get_stock_price, analyze_stock]
llm_with_tools = llm.bind_tools(tools)
# 调用
response = llm_with_tools.invoke("查下茅台股票价格")场景七:LangGraph(多 Agent 协作)
解决的问题:复杂任务需要多个角色协作完成
架构图
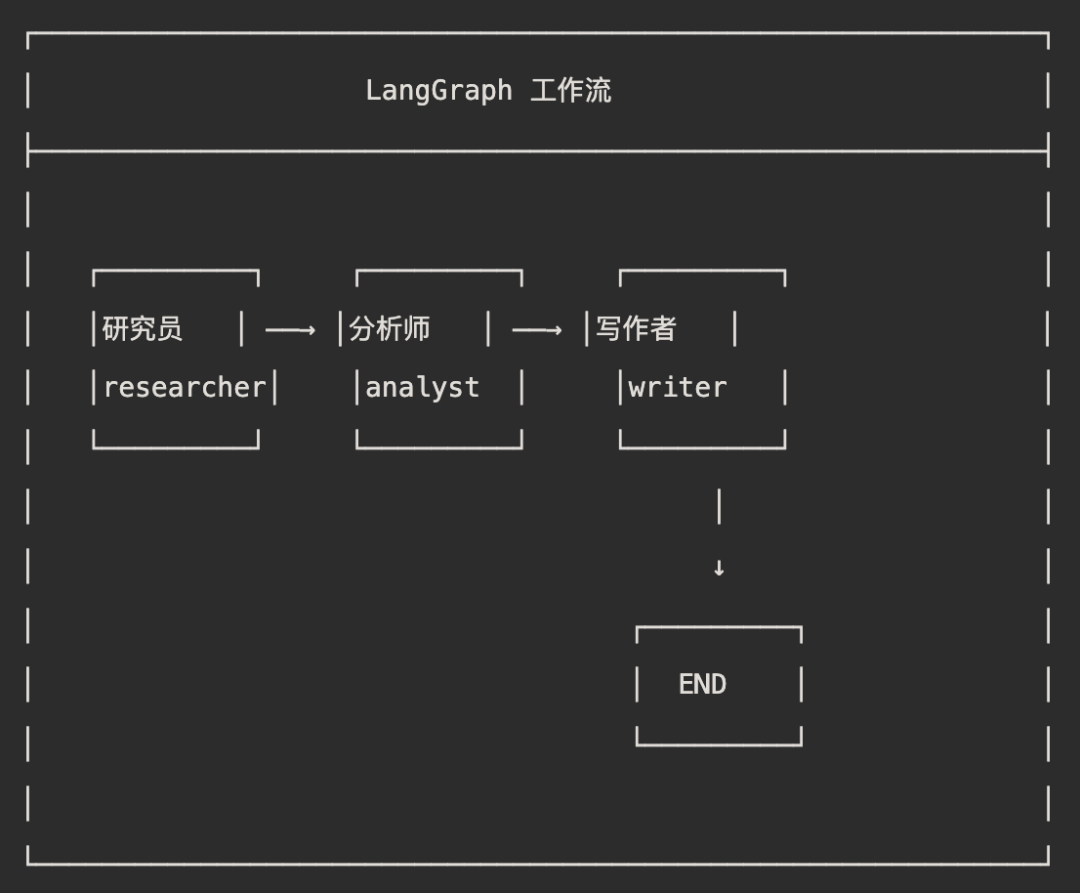
代码示例
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated, Sequence
from langchain_core.messages import BaseMessage
from operator import add
# 定义状态
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add]
next_agent: str
# 创建图
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("researcher", researcher_node)
workflow.add_node("analyst", analyst_node)
workflow.add_node("writer", writer_node)
# 定义流程
workflow.set_entry_point("researcher")
workflow.add_edge("researcher", "analyst")
workflow.add_edge("analyst", "writer")
workflow.add_edge("writer", END)
# 编译执行
app = workflow.compile()
result = app.invoke({"messages": [HumanMessage(content="分析茅台股票")]})场景八:并发处理
解决的问题:批量任务加速、用户体验优化
asyncio 异步调用
import asyncio
async def process_batch(questions):
"""并发处理多个问题"""
tasks = [llm.ainvoke(q) for q in questions]
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
questions = ["问题1", "问题2", "问题3"]
results = asyncio.run(process_batch(questions))RunnableParallel(同一输入,多任务并发)
from langchain_core.runnables import RunnableParallel
parallel_chain = RunnableParallel(
summary=summary_prompt | llm,
sentiment=sentiment_prompt | llm,
keywords=keywords_prompt | llm,
)
result = parallel_chain.invoke({"text": "需要分析的文本"})三、场景选择指南
根据复杂度选择:
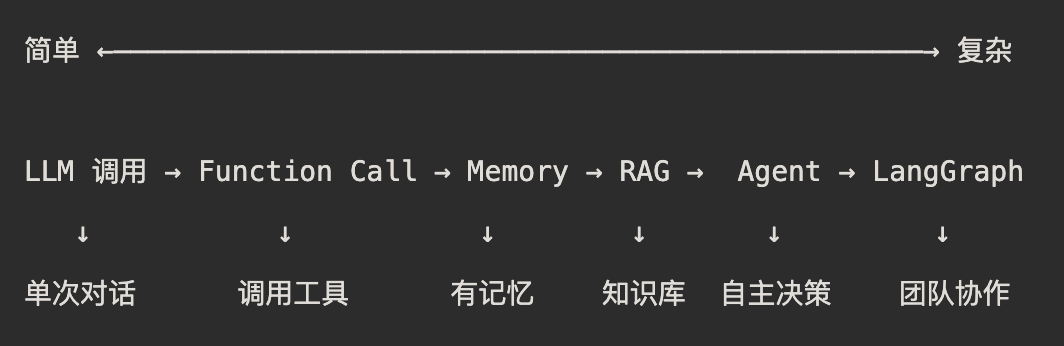
根据需求选择
你的需求 | 推荐方案 |
|---|---|
简单对话 | LLM 直接调用 |
查询外部数据 | Function Call |
多轮对话 | Memory |
公司内部知识库 | RAG |
需要结构化数据 | Structured Output |
复杂任务自动分解 | Agent |
多角色协作 | LangGraph |
批量处理 | 并发处理 |
四、配套项目
本文所有代码都可以在配套项目中找到:
GitHub: https://github.com/helloworldtang/langchain-tutorials
快速开始:
git clone https://github.com/helloworldtang/langchain-tutorials.git
cd langchain-tutorials
# 安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 安装依赖
uv sync
# 配置环境变量
cp .env.example .env
# 编辑 .env,填入你的 DEEPSEEK_API_KEY
# 运行示例
uv run python demos/01_llm.py
五、参考资料
- LangChain 官方文档 https://docs.langchain.com/oss/python/langchain/overview
- LangGraph 文档 https://docs.langchain.com/oss/python/langgraph/overview
- DeepSeek API https://platform.deepseek.com/usage
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号