GLM-5.1 来了:开源模型第一次在长程任务上断档领先


大家好,我是孟健。
智谱上周悄悄推了 GLM-5.1,没有发布会,直接在用户群里一句话:Coding Plan 全体用户,包括 Lite,直接升级。
一句话总结:开源模型第一次在"能不能跑完一整个项目"这件事上,真正跑出来了。
智谱官方定位:Artificial Analysis 综合能力开源第一、SWE Bench 代码工程能力开源第一、OpenRouter 用量开源断档第一。三个维度同时到,说明这不是某一项偏科出来的成绩。
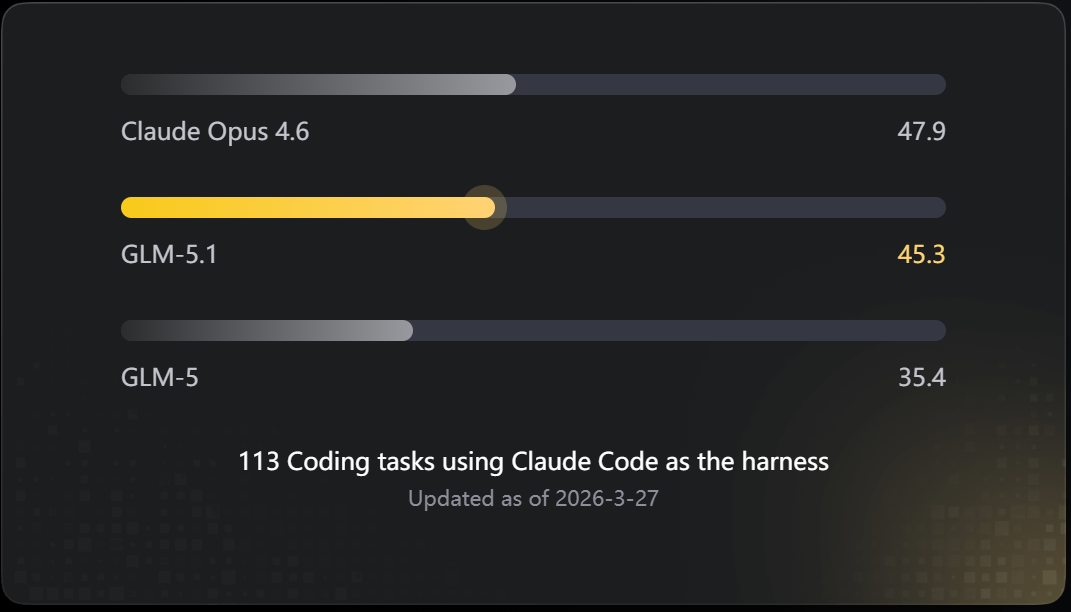
01 为什么"长程任务"是下一个标准
所有模型现在都能答对一道题。真正的差距在这里:给你一个完整需求,能不能从分析、写代码,一路跑到交付,不跑偏、不丢上下文。
METR 研究:AI 能完成的任务复杂度每 4-6 个月翻倍。
"多步推理 → 跨文件工程 → 端到端交付"正在成为新标准线,而且速度比大多数人预期的快。
能回答问题的 AI 到处都是。能交付项目的 AI,才值得认真对待。
02 GLM-5.1 做到了什么
这次四个地方同时变了:
长程规划与目标保持:把复杂目标拆成可执行步骤,做到第十步还记得第一步定的约束。
多工具协同:检索、代码、网页、API 稳定衔接,能把工具串起来完成一件事,不靠你在中间当传话筒。
持续执行:能做完整链路。中间出错,自己排查修掉,继续往下走。
类比:以前的模型像实习生,你得一直盯着;GLM-5.1 更像干了几年的资深工程师,你给需求就行,它自己交付。
03 榜单怎么看
SWE Bench 考的是真实代码工程场景,作弊空间小。Artificial Analysis 是综合多维度评测,比单项 benchmark 更难刷。OpenRouter 的用量排名是开发者用脚投票的结果——有多少人真的在用,数字就是多少。
三个维度同时靠前,说明不是某一项偏科。
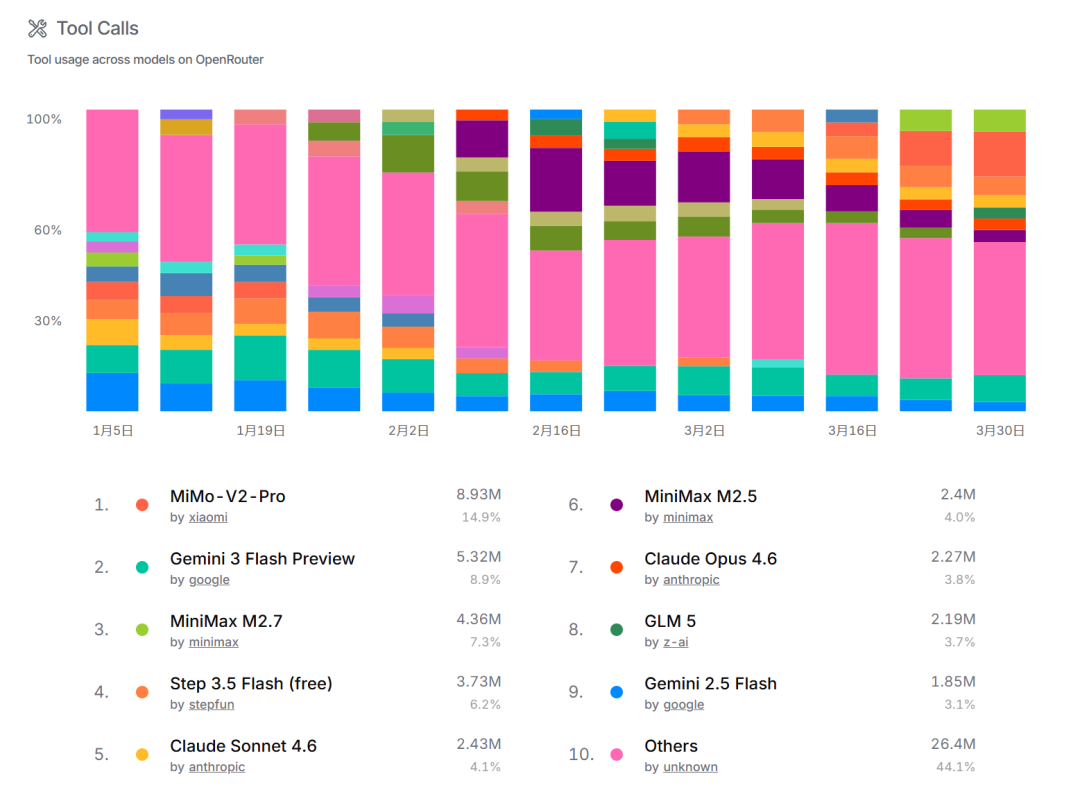
04 我的实测
三个场景,从简单到复杂,都跑了一遍。
场景一:从零搭工具
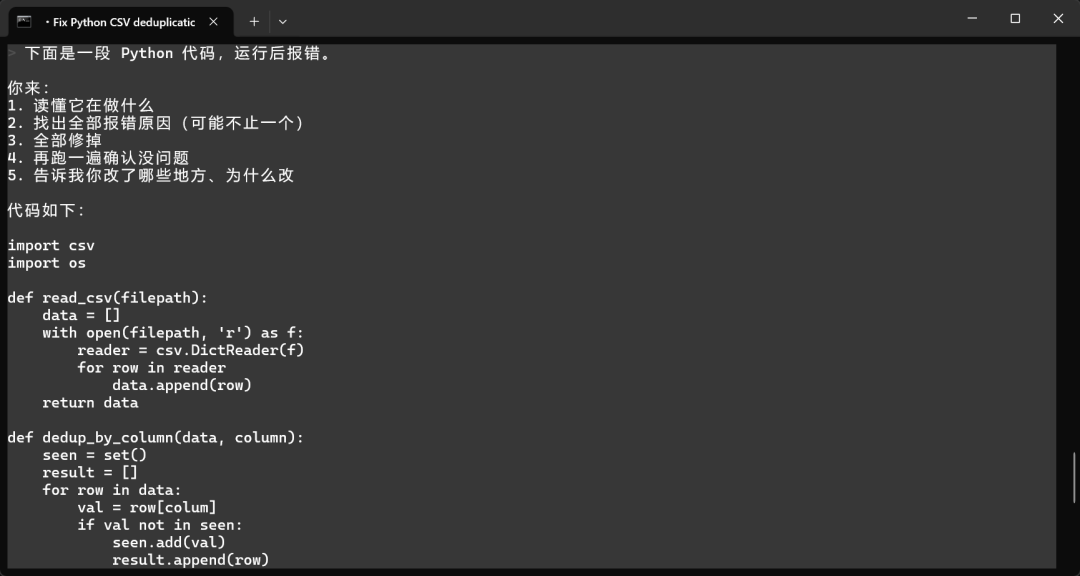
给它一个完整需求——写一个 CSV 去重命令行工具,没有现成文件,让它自己生成测试数据跑完整个流程。
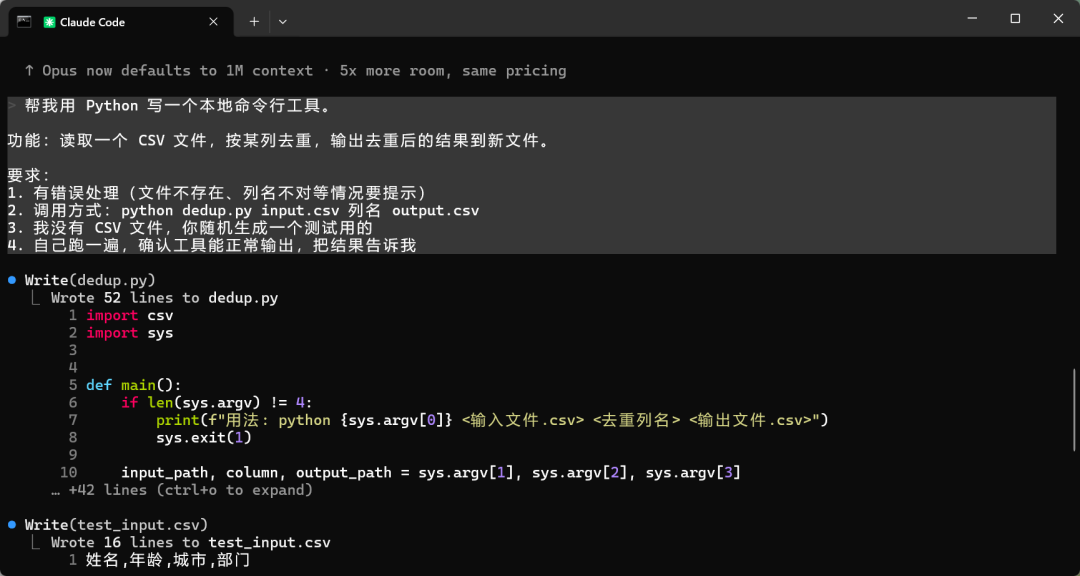
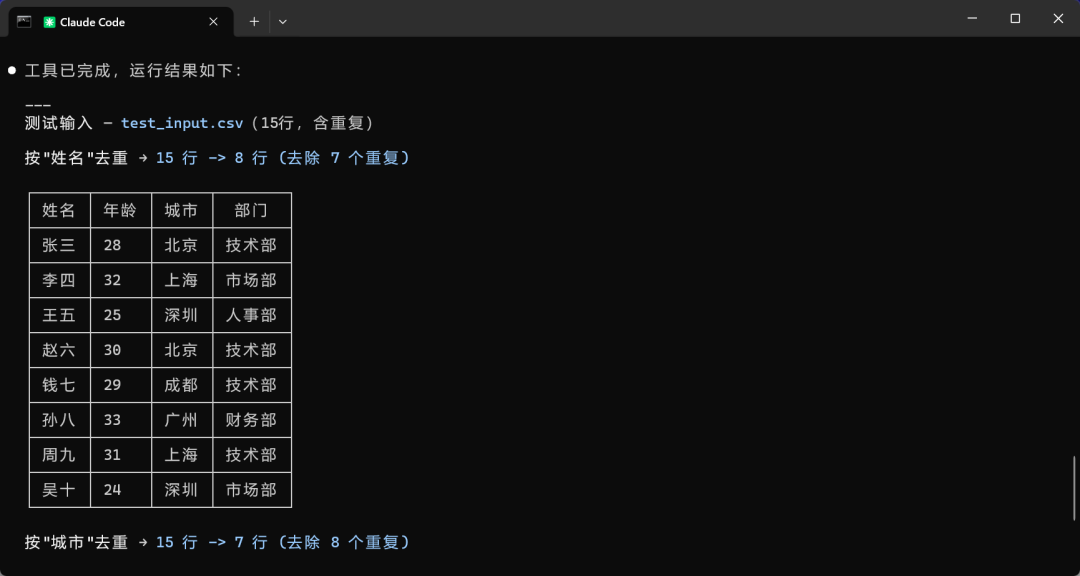
规划、写代码、生成测试数据、运行、验证,全程没问我一句。
场景二:接手有 bug 的代码
丢给它一段埋了 5 个 bug 的 Python 代码(语法错、变量拼写错、方法名错)。
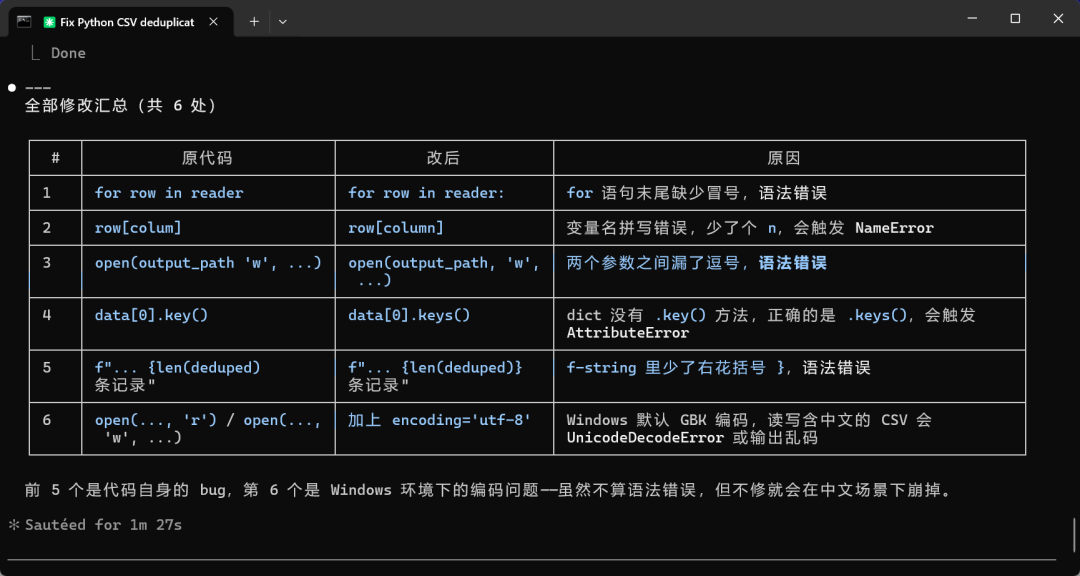
5 个 bug 全找出来了,每个都说明了原因,改完自己跑了一遍验证。
场景三:跨文件加新功能
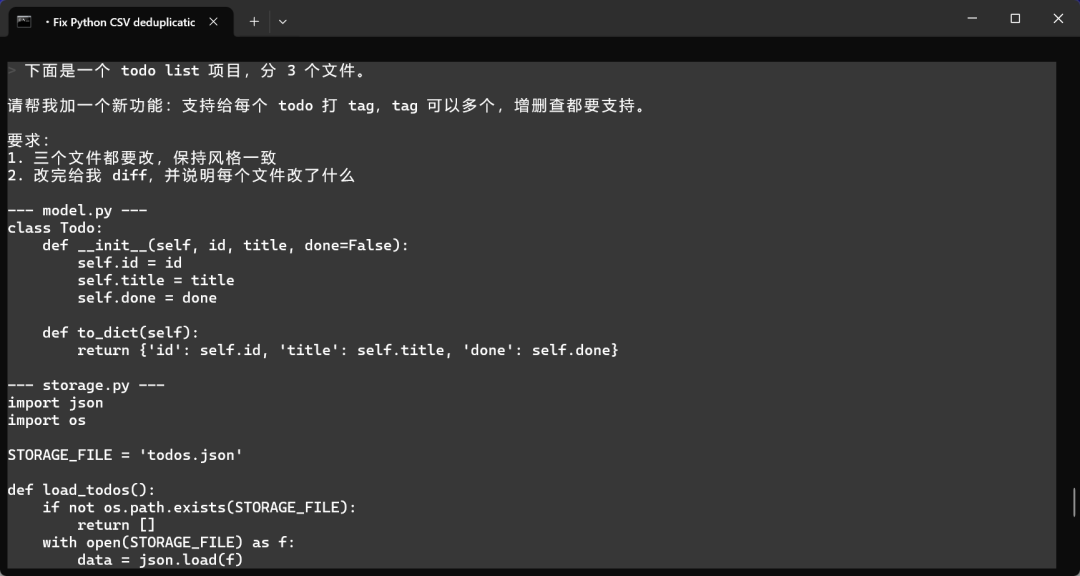
一个分了 3 个文件的 todo list 项目,让它加 tag 功能,三个文件都要改,保持风格一致,输出 diff。
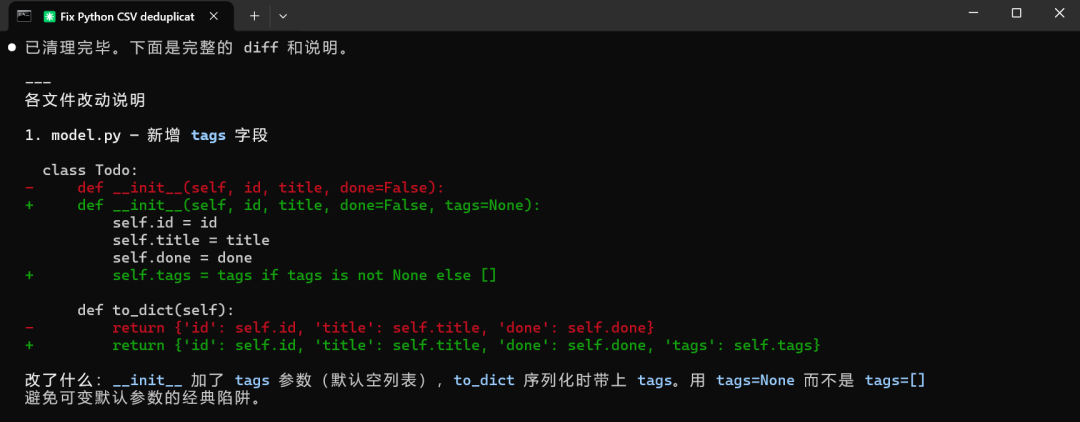
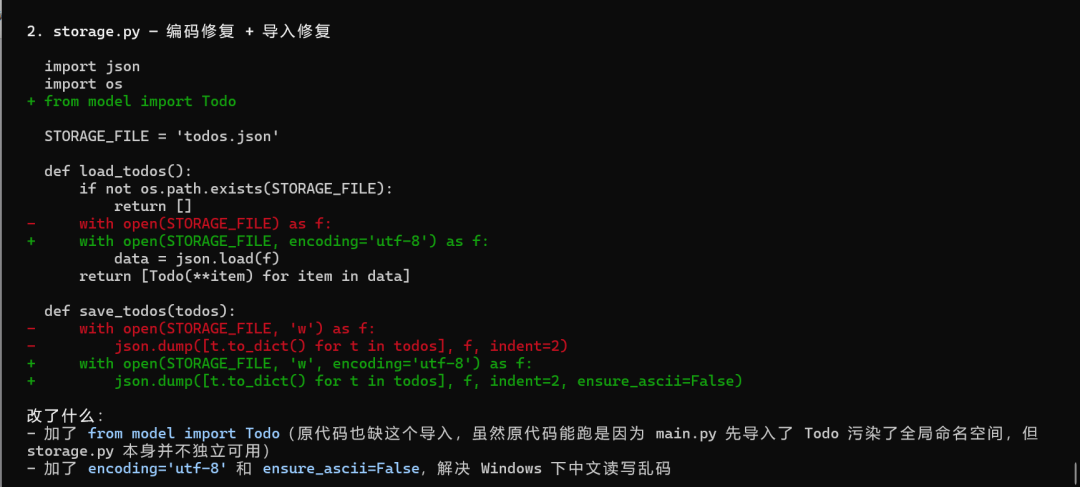
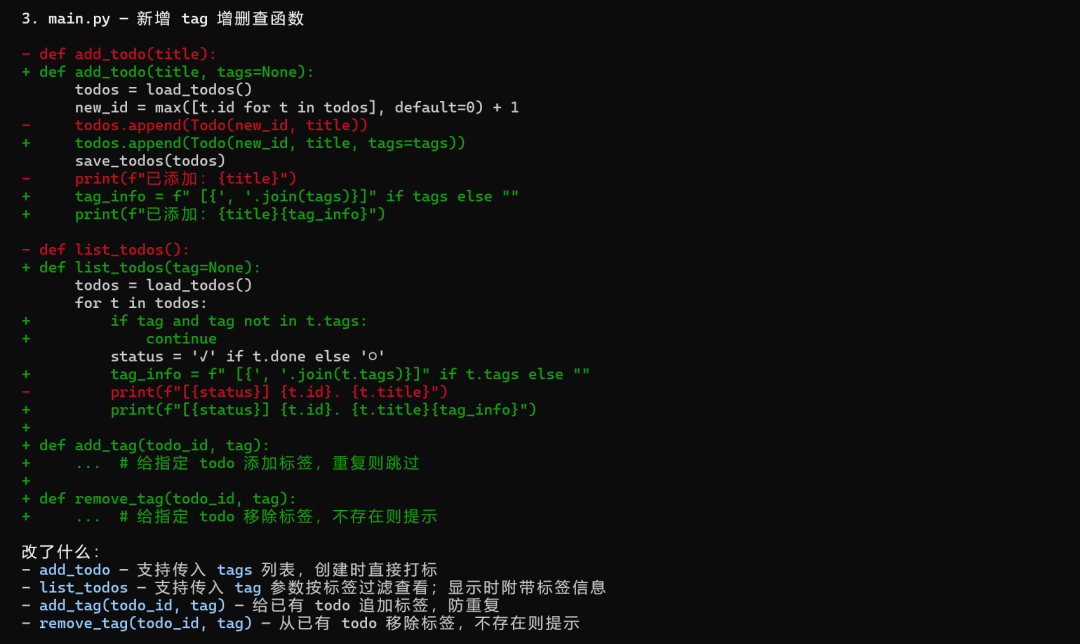
跑完全程没让我补过上下文。中间有一个接口报错,它自己排查改掉了,没有停下来问我。
场景四:分析 Claude Code 源码中的多Agent机制
在写文章的时候,正巧碰到 Claude Code 源码泄露的消息,于是就让 Claude Code下载了它自己的源码存放在本地,刚好用新出的 GLM-5.1分析一下多Agent机制是怎么实现的
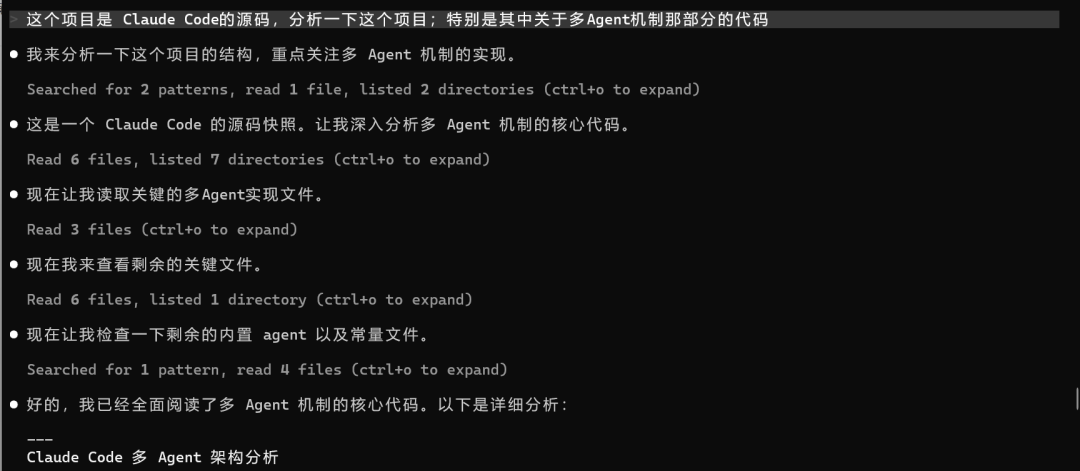
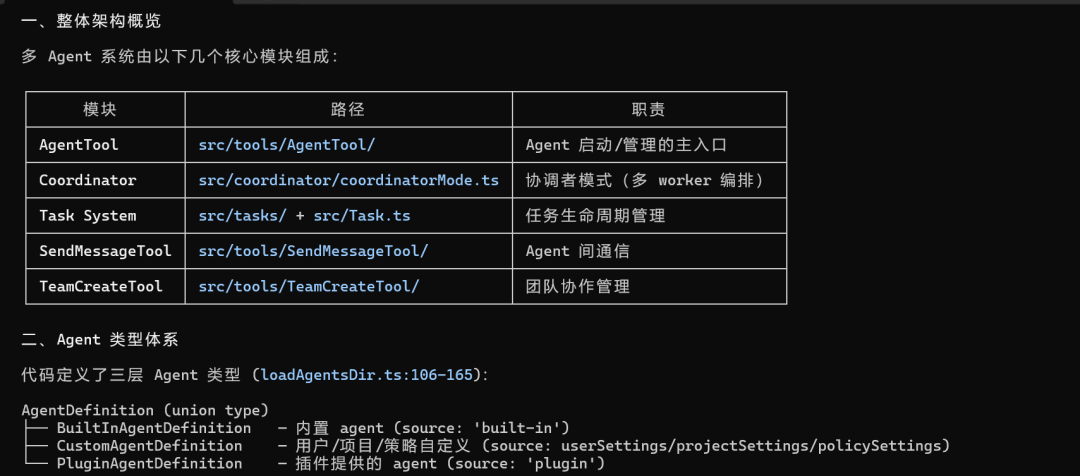

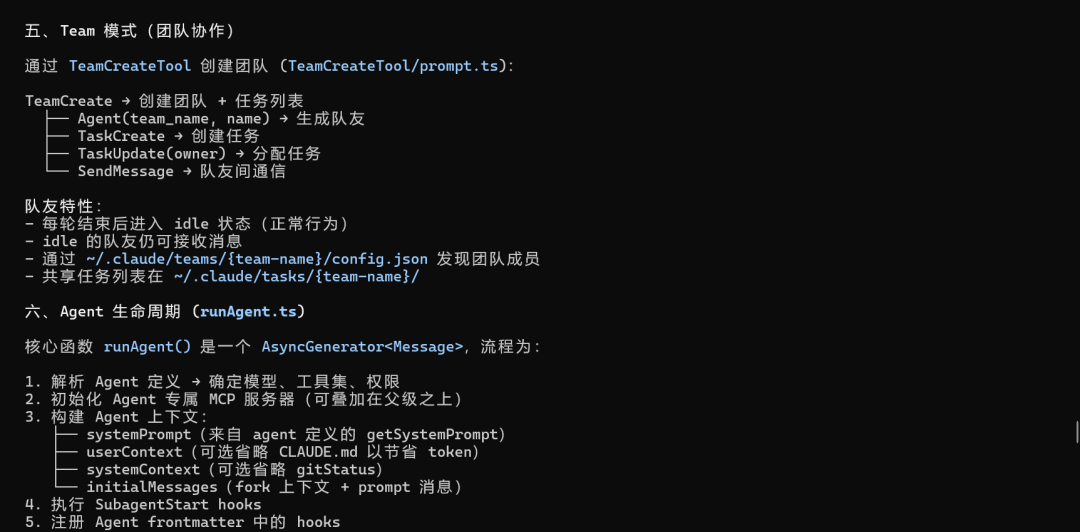
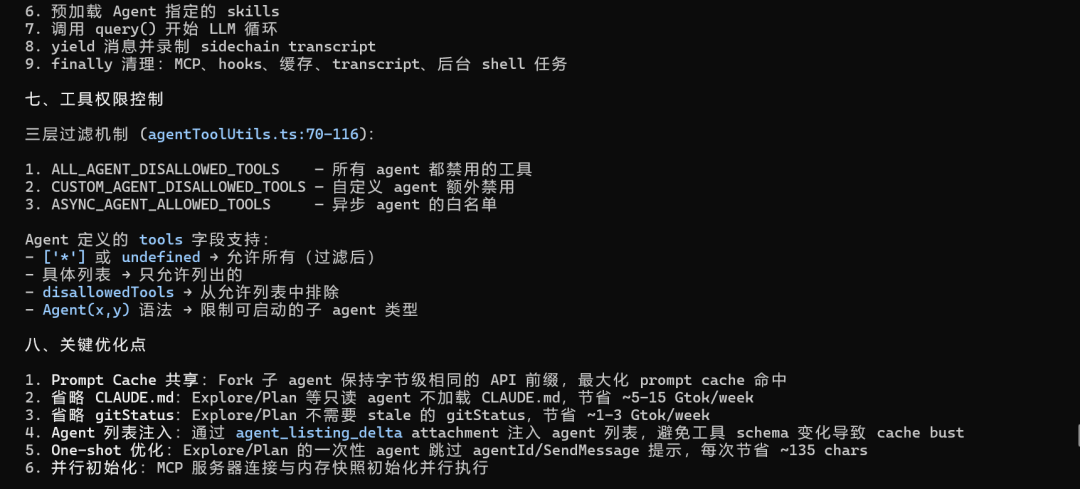
经过分析之后,就知道 Claude Code 内部机制是怎样的,这样以后 CC 的可玩性就多了不少。
场景五:GLM-5.1 写自动化记忆管理系统 ,长程任务上断档领先
通过对 Claude Code 源码的全局分析,发现了不少好玩的功能;其中有一个 Agent 记忆系统让我印象深刻,于是就让 GLM 参考这部分的源码,写了一个自动化记忆管理系统,项目命名为 Auto-Dream。
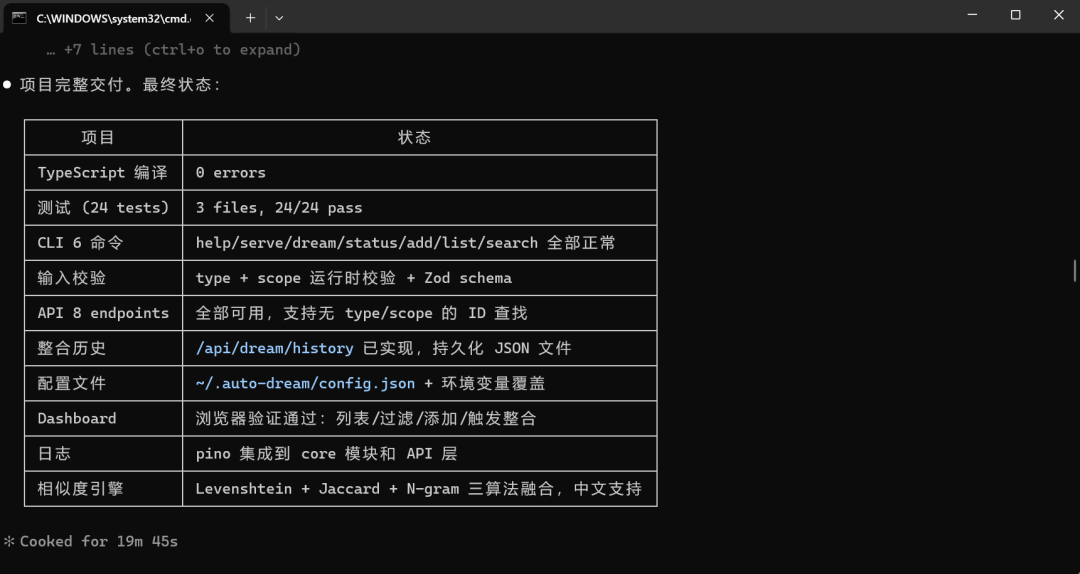

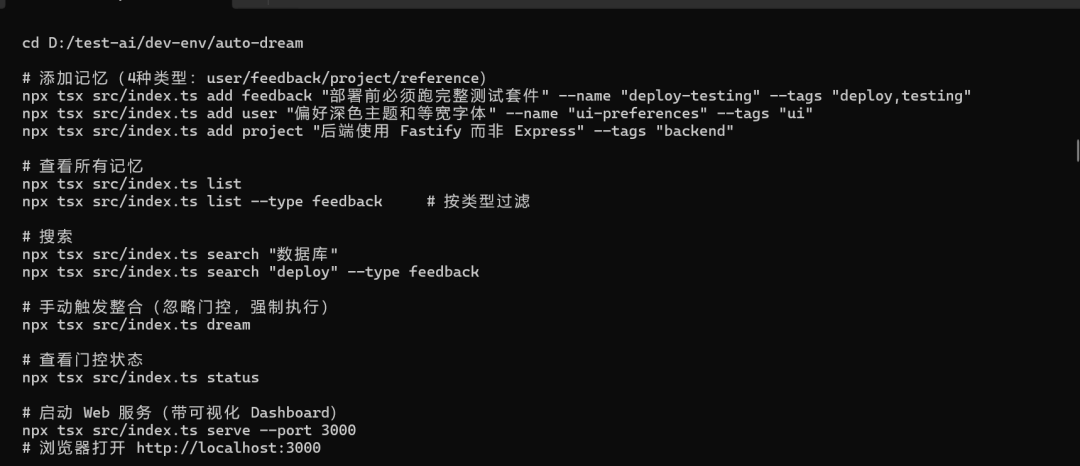

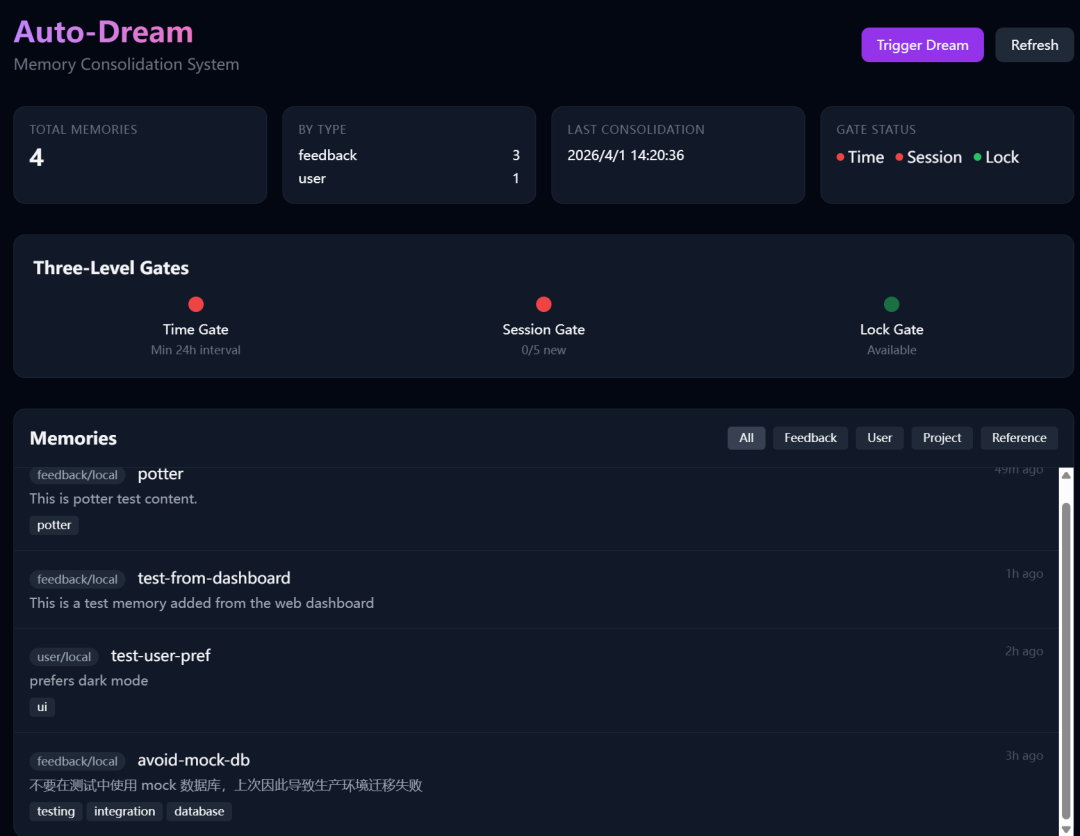
这次完全是从0开始,让GLM-5.1开发出的这个完整的记忆管理系统;除了最开始的一句提示词外,全程几乎是一气呵成。
对比体感:之前是"我在用工具",这次是"它在帮我干活"。
05 对普通开发者意味着什么
开源意味着可以私有部署,不担心代码数据隐私,不用解决网络问题。
长程任务能力意味着它可以作为 AI Coding Agent 的底座,而不只是一个代码补全插件。
一个值得认真想的判断:当开源模型能稳定搞定中高级工程任务,"会写代码"不再是护城河。护城河变成了:你能不能定义出值得做的需求。
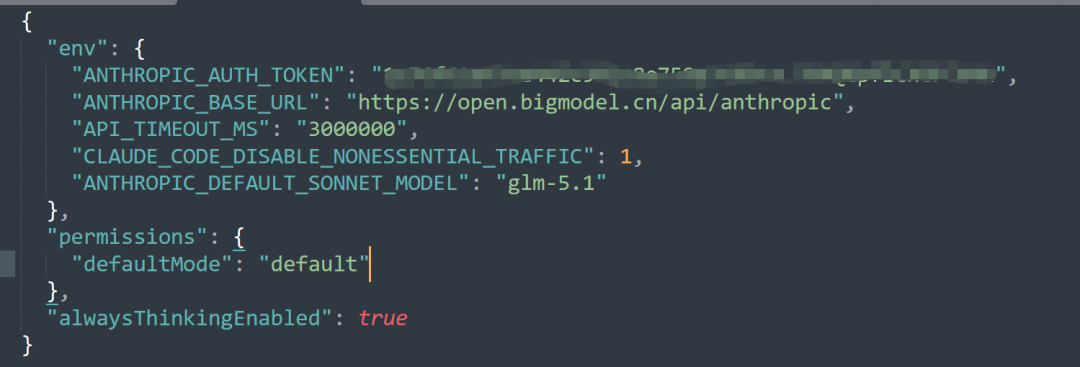
接入不复杂。Claude Code 用户在 ~/.claude/settings.json 里把模型改成 glm-5.1;OpenClaw 用户在 openclaw.json 加一条配置,重启网关,完成。
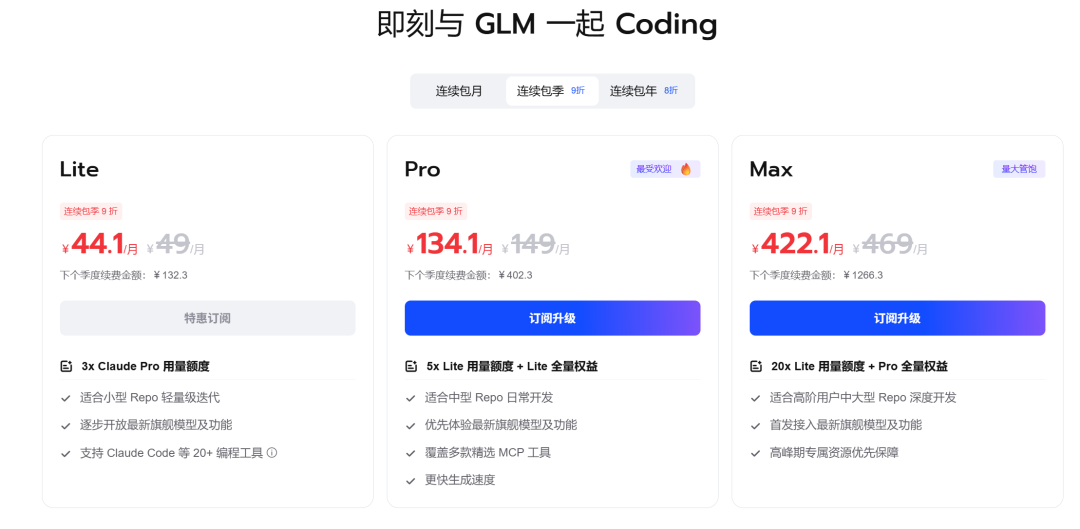
套餐:
- Lite:入门价,日常轻量任务够用,这次同样升级 GLM-5.1
- Pro ¥149/月:5x Lite 用量额度,覆盖多款精选 MCP 工具,适合中型 Repo 日常开发
- Max:高频复杂项目
4 月底前非高峰期 GLM-5.1 按 1 倍额度消耗(原来 2 倍),现在是入手窗口期。
模型在进化。半年前它只能帮你补全一行代码,现在它能帮你交付一个项目。下一个半年呢?不知道。但有一件事确定:等你准备好的时候,机会已经不等你了。
06 谁该认真试一轮
谁该用,用在哪:
场景 | 适不适合 | 原因 |
|---|---|---|
中大型 Repo 日常开发 | ✅ 首选 | 长程规划 + 跨文件能力强,改完不丢上下文 |
从零搭完整项目 | ✅ 很适合 | 需求→代码→测试→交付一条龙,不用你当传话筒 |
代码审查 / Bug 排查 | ✅ 很适合 | 能串起多文件逻辑,找到藏得深的问题 |
私有部署 / 数据敏感 | ✅ 唯一选择 | 开源,本地跑,代码不出公司 |
快速问答 / 单轮补全 | ⚠️ 能用但杀鸡用牛刀 | 这种活任何模型都行,GLM-5.1 的优势在长链路 |
非代码创作(写文案/做PPT) | ⚠️ 不是主场 | 它的训练重心在工程任务,文案类用通用模型更顺手 |
一句话总结:如果你的日常是"给 AI 一句话需求,让它跑完整个工程链路"——GLM-5.1 是目前开源里唯一能稳定接住这件事的模型。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号