线上问题定位神器:Arthas,已接入MCP


大家好,我是苏三,又跟大家见面了。
前言
最近经常有知识星球中球友问我:三哥,线上问题要如何才能快速排查?
CPU飙高、接口变慢、内存泄漏,每一次都是手忙脚乱,一边翻Arthas命令手册,一边对着控制台输出猜问题。
如果你是刚入行的新人,可能连该敲什么命令都不知道。
不过,这一切正在改变。
2026年,Arthas正式接入了MCP。
这意味着AI可以直接调用Arthas的所有诊断能力了。
以后排查线上问题,就变得更加简单了,只需要跟AI对话就行。
一、Java开发者的“线上救火队”
有些小伙伴在工作中可能遇到过这样的场景:线上应用突然CPU飙到100%,但本地无法复现;或者某个用户的数据出问题了,但线上无法断点调试。
这些时候,Arthas就是救火队。
它能在不修改代码、不重启应用的前提下,查看线程、方法追踪、监测入参返回值、查看类加载信息,几乎是Java线上排障的“瑞士军刀”。
传统的Arthas诊断流程:

Arthas背后的原理其实很精妙:它基于Java Instrumentation API与ASM字节码增强技术,可以在运行时动态修改类的字节码,插入监控逻辑。
你执行trace com.example.Service method时,Arthas会在该方法入口和出口处插入字节码,计算执行耗时并输出。这些字节码修改是临时的,当Arthas退出时会被还原,完全不会污染你的应用代码。
但现实也很直白:Arthas很强,门槛也很高。
你得知道该用哪个命令,得知道参数怎么写、OGNL怎么拼、如何限量避免线上刷屏,还得会“排障路径”——先拿证据,再收敛,再验证。
真正耗时的不是“敲命令”,而是每一步的决策。
二、MCP:AI时代的“USB-C接口”
MCP(Model Context Protocol,模型上下文协议)是由Anthropic在2024年11月提出并开源的标准化协议,用于连接AI助手与各种工具和数据源。
它像USB-C一样,用一个通用接口替代了各种混乱的私有连接方式。
在MCP出现之前,每个AI模型对接每个工具都需要定制集成,形成了N×M的碎片化问题。
MCP用单一接口解决了这一困境:MCP Server只需构建一次,就能被任何MCP客户端调用。
MCP架构图:
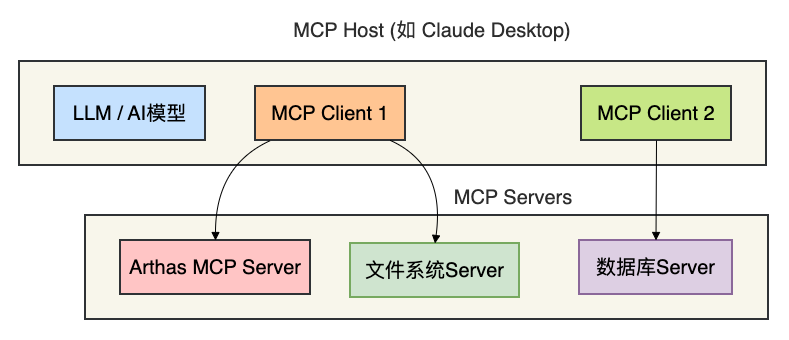
其中MCP Host是运行AI的应用(如Claude Desktop、Cursor),MCP Client负责与Server通信,MCP Server则提供诊断能力。
整个通信基于JSON-RPC 2.0,支持stdio和HTTP两种传输模式。
截至2026年初,已有超过10,000个活跃的MCP Server在生产环境运行,月SDK下载量达到9700万次。
三、Arthas + MCP
AI开始帮我们排查线上故障。
这是最激动人心的部分。
Arthas MCP Server是Arthas的一个实验性模块,通过HTTP/Netty提供统一的JSON-RPC 2.0接口,将Arthas的诊断命令封装成了AI可调用的工具。
官网地址:https://arthas.aliyun.com/doc/mcp-server.html
Arthas MCP Server架构图:
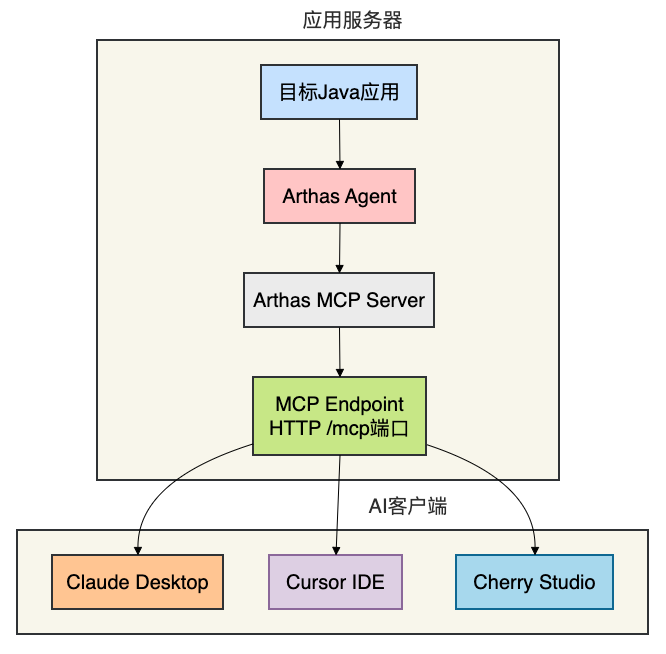
AI能直接执行这些命令并解读结果。目前已集成了26个核心诊断工具,覆盖JVM监控、类加载、方法追踪等全链路诊断需求。
这些工具被分为三大类:
类别 | 工具 | 功能 |
|---|---|---|
JVM相关(12个) | dashboard, heapdump, jvm, memory, thread, sysprop, sysenv, vmoption, perfcounter, vmtool, getstatic, ognl | 实时面板、堆转储、JVM信息、内存分析、线程诊断、系统属性、环境变量、VM参数、性能计数器、强制GC、静态字段读取、动态表达式执行 |
类加载相关(8个) | sc, sm, jad, classloader, mc, redefine, retransform, dump | 类信息查询、方法签名、反编译源码、类加载器分析、内存编译、类重定义、类重转换、字节码导出 |
监控诊断(6个) | monitor, stack, trace, watch, tt, profiler | 方法监控、调用栈输出、耗时追踪、入参返回值监控、时空隧道、火焰图生成 |
Arthas MCP Server支持两种协议模式:
STREAMABLE模式基于SSE推送流式响应,适合实时监控;
STATELESS模式是传统请求-响应,适合简单集成。
四、实战案例
下面给大家分享几个线上故障场景,看AI是如何通过Arthas MCP帮我们一步步排查问题的。
4.1 场景描述
你负责的一个订单系统,在晚上8点高峰期突然报警:**CPU使用率飙升到98%**,接口响应变慢,用户开始投诉。
你打开电脑,登录服务器,但看着黑压压的命令行,一时不知道从何查起。
这时候,你打开支持MCP的AI客户端(比如Cursor或Claude Desktop),输入一句话:
“我的订单服务CPU飙到98%,帮我排查一下是哪个线程导致的高CPU,它卡在哪里了?”
4.2 AI的“大脑”如何思考
AI接收到你的问题后,不会瞎猜,而是会按照一套内置的“故障排查剧本”来执行。
这套剧本是Arthas团队根据多年排障经验总结出来的,目前已经在Arthas Agent中实现。
AI的排查步骤(自动执行,无需你敲命令):
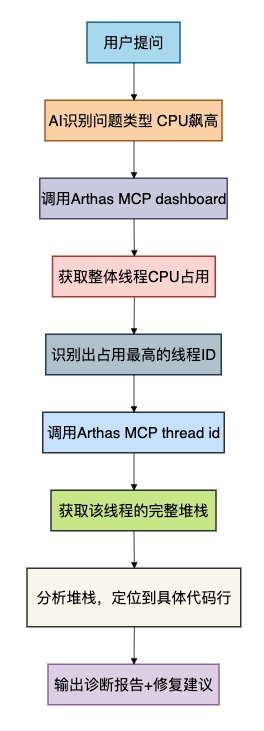
4.3 详细步骤拆解(小白也能看懂)
第一步:AI调用dashboard命令,查看整体情况
AI自动执行:call_tool("dashboard")
Arthas返回的数据类似这样(AI会自动解析):
ID NAME CPU% STATE
29 http-nio-8080-exec-8 89.2 RUNNABLE
12 DubboServerHandler-... 3.1 RUNNABLE
...(省略其他线程)
AI发现:**线程ID 29,CPU占用89.2%**,名字是http-nio-8080-exec-8,这是一个处理HTTP请求的线程。
第二步:AI调用thread命令,查看这个线程在干什么
AI自动执行:call_tool("thread", {id: 29})
Arthas返回这个线程的完整堆栈(AI会自动分析):
"http-nio-8080-exec-8" #29 prio=5 os_prio=0 tid=0x00007f8e2c001800 nid=0x4f runnable
java.lang.Thread.State: RUNNABLE
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
at java.util.regex.Pattern$GroupTail.match(Pattern.java:4719)
at java.util.regex.Pattern$Curly.match(Pattern.java:4238)
at java.util.regex.Pattern$Branch.match(Pattern.java:4606)
...(省略中间调用)
at com.example.logging.LogAspect.logAround(LogAspect.java:47)
at com.example.order.service.OrderService.getOrder(OrderService.java:123)
第三步:AI分析堆栈,定位问题根源
AI会这样分析(你可以直接看到):
分析结果:
- 线程卡在
java.util.regex.Pattern的正则匹配方法中。 - 调用链显示,问题发生在
LogAspect.java:47的日志切面里。 - 这个切面在处理某个超长字符串时,触发了一个性能极差的正则表达式(比如用了
.*贪婪匹配 + 回溯)。 - 根本原因:日志切面中有一段用于脱敏的正则代码,在处理超过10KB的JSON请求体时,发生了“灾难性回溯”,导致CPU占满。
第四步:AI给出修复建议
AI会根据分析结果,给出具体的修复建议:
建议修复方案:
- 临时措施:关闭该日志切面(通过配置动态关闭)。
- 根本修复:重写正则表达式,将
.*改为[^"]*避免回溯;或者改用String的indexOf方法替代正则。 - 增加日志切面的长度限制,超过2000字符不进行脱敏处理。
4.4 对比:没有AI时你要做什么?
如果没有AI,你需要:
- 登录服务器 → 2. 启动Arthas → 3. 敲
dashboard找高CPU线程 → 4. 记住线程ID → 5. 敲thread 29→ 6. 看到堆栈后,手动分析是哪个类哪一行 → 7. 如果是正则问题,还要去查代码 → 8. 定位到切面 → 9. 修改代码 → 10. 重新发布。
每一步都可能因为不熟悉命令而卡住。现在有了Arthas MCP,你只需要说一句话,AI就帮你把前面9步全做了,而且还会给你解释原因和建议。
4.5 更复杂的场景:AI还能做更多
除了CPU飙高,Arthas MCP还能帮你排查:
- 接口变慢:AI可以调用
trace命令,自动追踪整个调用链,找出最慢的那个方法。 - 内存泄漏:AI可以调用
heapdump生成堆转储,然后配合其他MCP Server分析大对象。 - 死锁:AI可以调用
thread -b检测死锁,并告诉你哪些线程互相等待。 - 参数异常:AI可以调用
watch命令,监控方法入参和返回值,帮你找到非法数据。
五、Arthas MCP的优缺点与适用场景
优点:
- 无需学习Arthas命令语法,用自然语言即可排查问题
- 通过MCP协议统一集成到Claude Desktop、Cursor、Cherry Studio等主流AI客户端
- 安全可控:通过Bear Token认证机制保障访问安全
- 内置26个核心诊断工具,覆盖JVM监控、类加载、方法追踪全链路
- 基于HTTP协议,可与IDE、监控系统无缝集成
缺点:
- 当前为实验性模块,功能仍在快速迭代中
- 需自行配置MCP客户端连接
- 复杂场景可能需要人工干预验证AI推断
适用场景:
- 日常线上故障快速排查
- 新人培训期辅助诊断
- 配合IDE进行代码级问题定位
- 构建企业内部AI运维助手
总结
Arthas接入MCP,标志着线上故障排查进入了“AI辅助诊断”的新阶段。
从此,你不需要再记住Arthas的命令、参数和排障路径,只需要把现象描述给AI,AI就能自动执行诊断、分析数据、输出报告。
无论是CPU飙高、接口变慢、内存泄漏还是死锁检测,Arthas MCP都能帮你用自然语言完成全链路诊断。
最重要的是:AI的“排障剧本”内置了阿里巴巴多年积累的百万级诊断经验,它知道第一步该看什么,第二步该查什么,第三步该怎么收敛。
这对于刚入行的新人来说,简直就是“随身带了一位10年经验的架构师”。
未来已来,你准备好用AI排查线上问题了吗?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号