一时玩虾一时爽,省钱玩虾一直爽!


一时玩虾一时爽,一直玩虾一直爽。直到Token烧尽,钱包空空如也。感觉打工牛马养了一个活爹。

图片
接下来,我们谈谈如何让OpenClaw 省钱。

mermaid diagram
01
本地部署大模型
目前,最理想的方案就是本地部署大模型。然后让OpenClaw去访问本地模型接口。从而实现真正“零费用”,适用于生产环境不能联网、保密性较高的场景。但是,前期对硬件的要求是非常高的,尤其是对显卡的要求!。

图片
01 本地部署方案 Ollama
Ollama 是目前对新手最友好的本地部署工具,支持一条命令完成安装,全程几乎零门槛。

图片
下载和安装非常简单,支持一条命令安装。
●●●code
irm https://ollama.ac.cn/install.ps1 | iex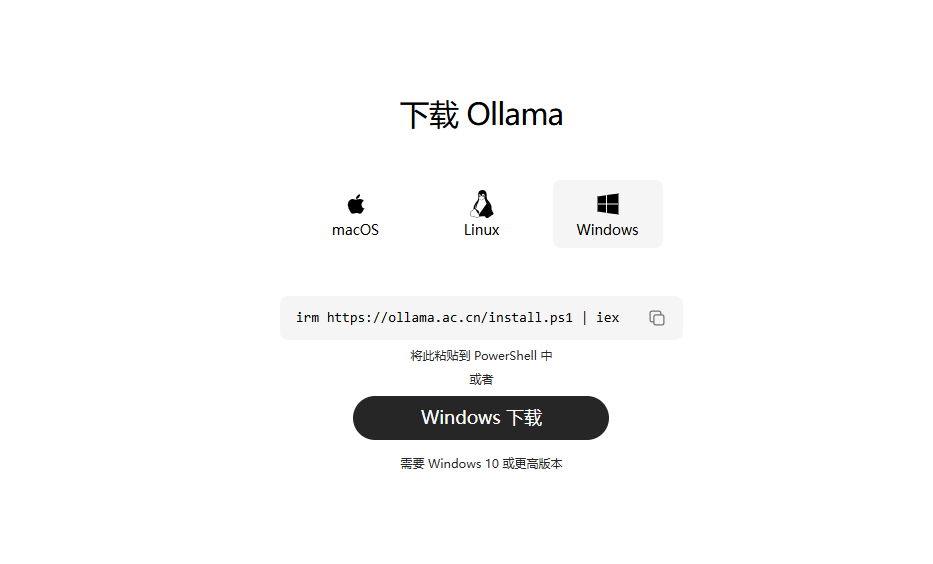
图片
安装完成后,可以在控制面板,根据自己电脑性能自行下载模型。
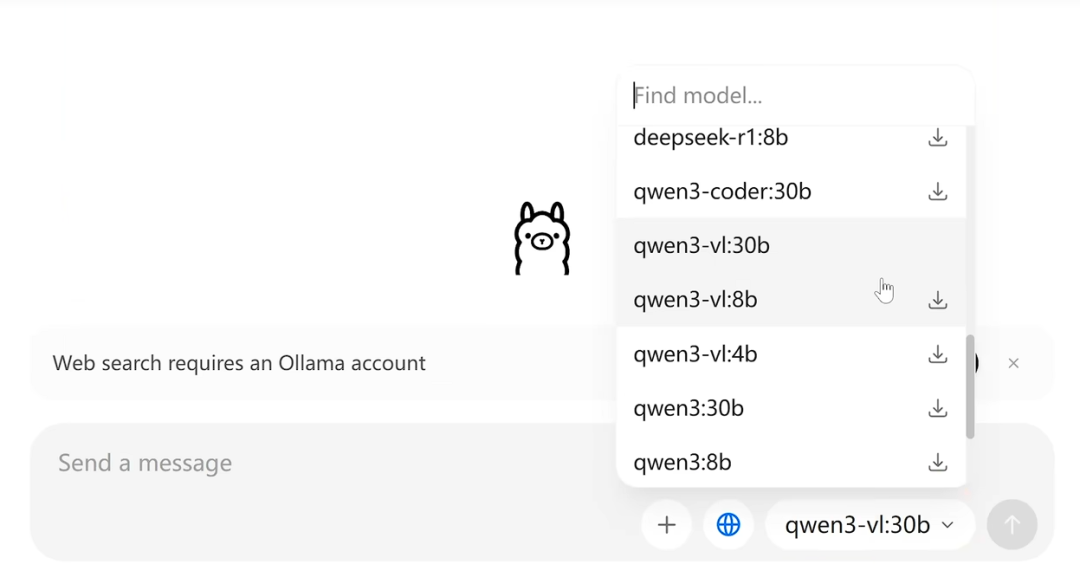
图片
模型部署完成后,在OpenClaw中执行龙虾配置项。
●●●code
openclaw config选择model-custom provider 配置API连接。
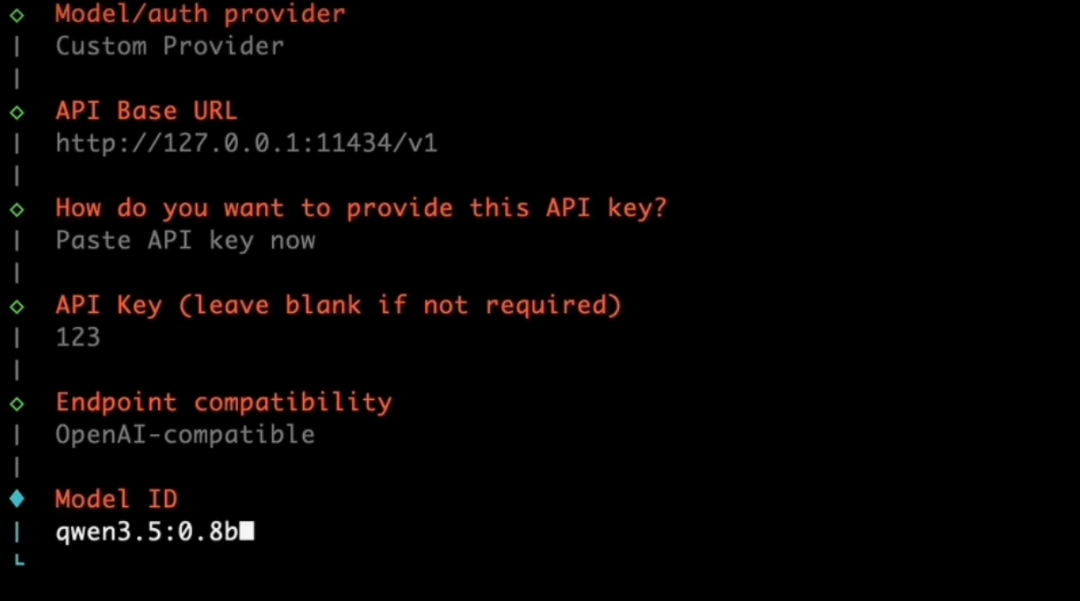
ID为模型的名字
ID为模型的名字
当然,如果你部署了在线API 你可以将接口信息发送给龙虾。让他自己配置!
完成后,重启openclaw即可!
02 本地部署方案 vLLM
vLLM 是一款高性能、易上手的大语言模型推理与部署库,核心优势是推理速度更快、显存利用率更高,更适合有一定技术基础、追求极致运行效率的用户。

图片
由于受限于本地测试环境,这里不展开详细的部署步骤,有硬件条件、有技术基础的朋友,可以参考官方文档尝试部署,体验会比基础部署方案更出色。

mermaid diagram
02
多配置Skills
如果,我们硬件确实比较拉。只能想办法让“龙虾”多做事、少思考、通过提前配置Skill,让它知道这件事怎么做?而不是做每件事都是各种思考,造成不必要的Token消耗。
同时,由于龙虾“记性”不高。今天做的事,明天就忘记怎么做了。因此凡是都是各种思考,然后是各种尝试。最终导致Token大量的消耗。
因此,我们可以先在本地编写相关脚本,通过Skill.md文件详细说明该怎样做?
这里,我们通过分析公众号文章为例。先通过Python编写对应的分析脚本,并通过MD文件说明具体的事项和步骤。
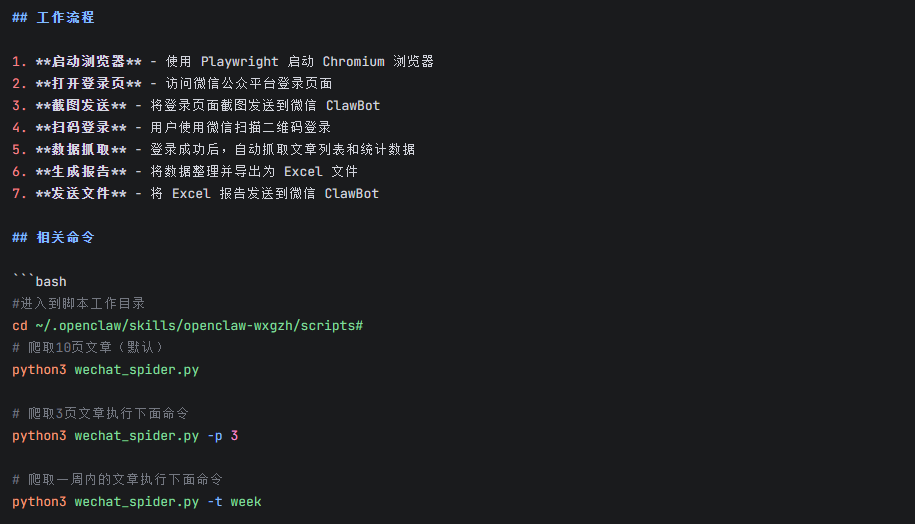
说给龙虾怎样做
说给龙虾怎样做
减少不必要的思考和操作, 避免造成大量Token消耗。
用时3分钟内便能完成任务
用时3分钟内便能完成任务
数据分析效果
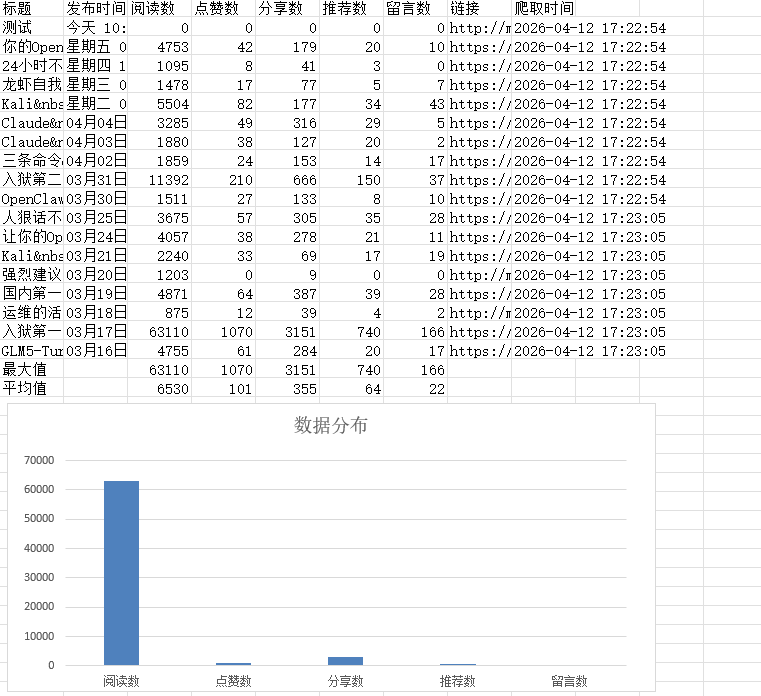
图片

mermaid diagram
03
总结
以上方案,各有优缺。当然,OpenClaw 的省钱玩法不止于此。如果你还有更好的方案,可以留言区告诉大家!
更多精彩文章 欢迎关注我们
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号