使用 Mastra 和 Elasticsearch 构建代理式 AI 应用

使用 Mastra 和 Elasticsearch 构建代理式 AI 应用

点火三周
发布于 2026-04-15 15:14:00
发布于 2026-04-15 15:14:00
使用 Mastra 和 Elasticsearch 构建代理式 AI 应用
构建代理式 AI 应用
构建代理式 AI 应用
Agent Builder现已正式发布。您可以通过 Elastic Cloud Trial 开始使用,并在此处查看Agent Builder的文档。
本文将介绍如何使用 Mastra TypeScript框架构建与 Elasticsearch交互的代理式应用。
我们最近为mastra-ai/mastra开源项目贡献了支持,将Elasticsearch作为向量数据库。通过这一新功能,您可以在Mastra中原生使用Elasticsearch存储嵌入。除了向量,Elasticsearch还提供了一系列高级功能来满足您的上下文工程需求(例如,混合搜索和重排序)。
本文详细介绍了如何创建一个代理以实现使用Elasticsearch的检索增强生成 (RAG)架构。我们将展示一个演示项目,其中使用代理方法与存储在Elasticsearch中的科幻电影数据进行交互。项目可在elastic/mastra-elasticsearch-example中查看。
Mastra
Mastra是一个用于创建代理式AI应用的TypeScript框架。
Mastra中的项目结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
src/
├── mastra/
│ ├── agents/
│ │ └── weather-agent.ts
│ ├── tools/
│ │ └── weather-tool.ts
│ ├── workflows/
│ │ └── weather-workflow.ts
│ ├── scorers/
│ │ └── weather-scorer.ts
│ └── index.ts
├── .env.example
├── package.json
└── tsconfig.json
在Mastra中,您可以构建代理、工具、工作流和评分。
代理是一个接受输入消息并产生输出响应的类。代理可以使用工具、大型语言模型 (LLMs) 和记忆模块(图1)。
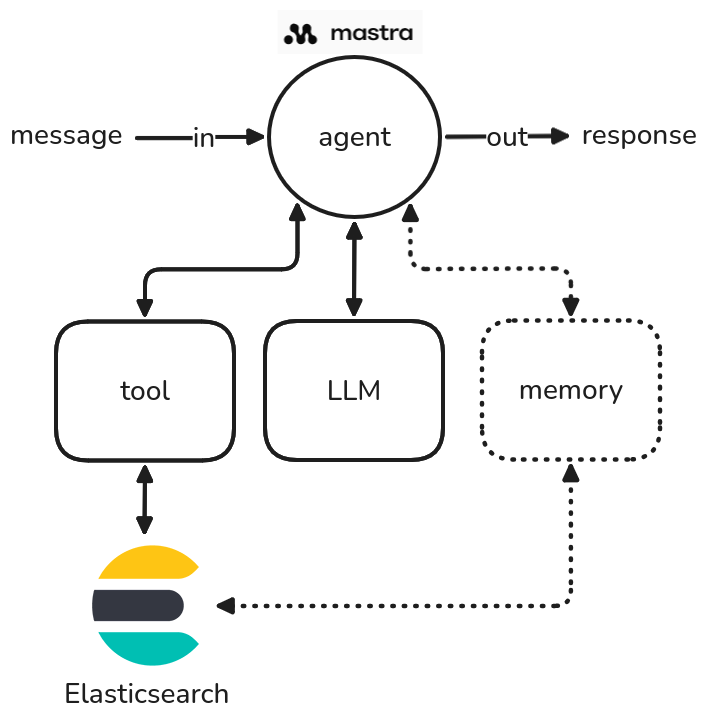
Mastra中代理工作原理的示意图。
Mastra中代理工作原理的示意图。
图1: Mastra中代理工作原理的示意图。
代理的工具允许其与“外部世界”互动,例如与Web API通信或执行内部操作,如查询Elasticsearch。记忆组件对于存储对话历史非常重要,包括过去的输入和输出。这个存储的上下文使代理能够在未来的问题中提供更有信息和相关的响应。
工作流允许您使用清晰、结构化的步骤定义复杂的任务序列,而不是依赖单个代理的推理(图2)。它们让您完全控制任务如何被分解、数据如何在它们之间流动,以及何时执行。工作流默认使用内置的执行引擎运行,也可以部署到工作流运行器。
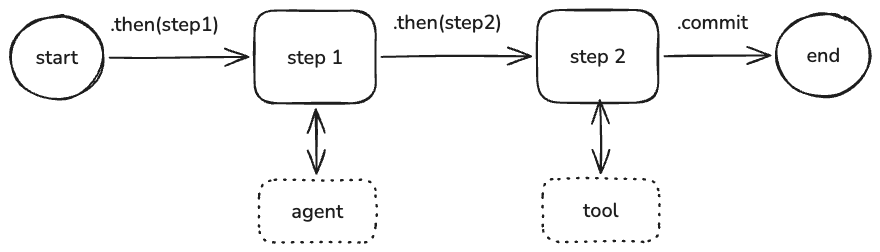
Mastra中的工作流示例。
Mastra中的工作流示例。
图2: Mastra中的工作流示例。
在Mastra中,您还可以定义评分,即使用模型评分、规则基础和统计方法评估代理输出的自动化测试。评分返回_分数_:数值(通常在0到1之间)量化输出在满足评估标准方面的表现。这些分数使您能够客观地跟踪性能、比较不同的方法,并识别AI系统中的改进区域。评分可以使用您自己的提示和评分函数进行定制。
Elasticsearch
要运行演示项目,我们需要启动一个Elasticsearch实例。您可以在Elastic Cloud上激活免费试用,或者使用start-local脚本在本地安装:
1
curl -fsSL https://elastic.co/start-local | sh
这将安装Elasticsearch和Kibana到您的计算机,并生成一个API密钥用于配置Mastra集成。
API密钥会作为前一个命令的输出显示,并存储在elastic-start-local文件夹中的**.env**文件中。
安装和配置演示项目
我们创建了一个包含演示项目源代码的elastic/mastra-elasticsearch-example库。库中的示例展示了如何在Mastra中创建一个代理,实现从Elasticsearch检索文档的RAG架构。
我们为演示提供了一个关于科幻电影的数据集。从Kaggle的IMDb数据集中提取了500部电影。
首先需要使用npm安装项目的依赖项,使用以下命令:
1
npm install
然后需要配置包含设置的**.env文件。我们可以从.env.example**文件复制结构来生成这个文件,使用以下命令:
1
cp .env.example .env
现在我们可以编辑.env文件,添加缺失的信息:
1
2
3
4
OPENAI_API_KEY=
ELASTICSEARCH_URL=
ELASTICSEARCH_API_KEY=
ELASTICSEARCH_INDEX_NAME=scifi-movies
Elasticsearch索引的名称为**scifi-movies**。如果需要,可以使用环境变量ELASTICSEARCH_INDEX_NAME进行更改。
我们使用OpenAI作为嵌入服务,这意味着需要在OPENAI_API_KEY环境变量中提供OpenAI的API密钥。
示例中使用的嵌入模型是openai/text-embedding-3-small,嵌入维度为1536。
为了降低成本,我们使用openai/gpt-5-nano模型生成最终答案。
RAG架构允许使用较不强大的(通常较便宜的)最终LLM模型,因为回答的基础工作由检索组件(此处为Elasticsearch)完成。
较小的LLM只负责两个主要任务:
- • 重构/嵌入查询: 将用户的自然语言问题转换为用于语义搜索的向量嵌入。
- • 合成答案: 将高相关性检索到的上下文块(文档/电影)合成为一个连贯的、最终的人类可读的答案,遵循提供的提示指令。
由于RAG过程提供了答案所需的准确事实上下文,最终的LLM不需要庞大或高度复杂,也不需要在其自身参数中拥有所有需要的知识(这是大型、昂贵的模型所擅长的)。它本质上是一个复杂的文本总结器和格式化工具,为Elasticsearch提供的上下文服务,而不是一个完整的知识库。这使得使用像gpt-5-nano这样的模型成为可能,从而优化成本和延迟。
在配置.env文件后,可以使用以下命令将电影导入Elasticsearch:
1
npx tsx src/utility/store.ts
您应该看到如下输出:
1
2
3
4
5
6
7
8
9
🚀 开始从500_scifi_movies.jsonl中导入500部电影...
正在导入 ░░░░░░░░░░░░░░░░░░░░░░░░ 1/500 (0%) | 成功:1 | 失败:0 | 块:1 | 预计时间:19m 33s | 当前:Capricorn One
正在导入 ░░░░░░░░░░░░░░░░░░░░░░░░ 2/500 (0%) | 成功:2 | 失败:0 | 块:2 | 预计时间:10m 32s | 当前:Doghouse
正在导入 ░░░░░░░░░░░░░░░░░░░░░░░░ 3/500 (1%) | 成功:3 | 失败:0 | 块:3 | 预计时间:7m 33s | 当前:Dinocroc
正在导入 ░░░░░░░░░░░░░░░░░░░░░░░░ 4/500 (1%) | 成功:4 | 失败:0 | 块:7 | 预计时间:6m 10s | 当前:Back to the Future
正在导入 ░░░░░░░░░░░░░░░░░░░░░░░░ 5/500 (1%) | 成功:5 | 失败:0 | 块:9 | 预计时间:5m 14s | 当前:The Projected Man
正在导入 ░░░░░░░░░░░░░░░░░░░░░░░░ 6/500 (1%) | 成功:6 | 失败:0 | 块:11 | 预计时间:4m 41s | 当前:I, Robot
...
✅ 导入在1m 46s内完成。成功:500, 失败:0, 块:693。
scifi-movies索引的映射包含以下字段:
- • embedding, dense_vector维度为1536,使用余弦相似度。
- • description, 包含电影描述的文本。
- • director, 包含导演姓名的文本。
- • title, 包含电影标题的文本。
我们使用标题加描述生成嵌入。由于标题和描述是两个独立的字段,将两者连接确保生成的嵌入向量既捕获电影的特定、独特身份(标题),又捕获丰富的描述性上下文(描述),从而更准确和全面地进行语义搜索。这种组合输入为嵌入模型提供了一个更好的单一表示,以进行内容的相似性匹配。
运行演示
您可以使用以下命令运行演示:
1
npm run dev
此命令将在localhost:4111启动一个Web应用程序以访问Mastra Studio(图3)。
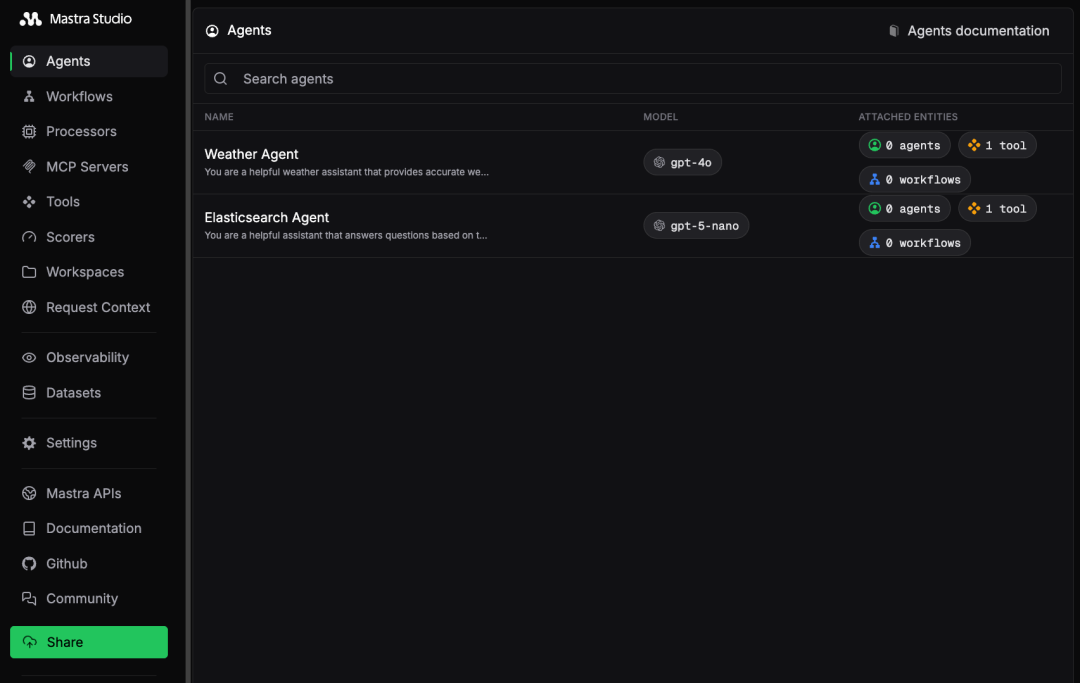
Mastra Studio中Elasticsearch Agent示例的截图。
Mastra Studio中Elasticsearch Agent示例的截图。
图3: Mastra Studio中Elasticsearch Agent示例的截图。
Mastra Studio提供了一个用于构建和测试您的代理的交互式UI,以及将您的Mastra应用作为本地服务公开的REST API。这使您可以立即开始构建,而无需担心集成。
我们提供了一个Elasticsearch Agent,使用Mastra的createVectorQueryTool作为执行Elasticsearch语义搜索的工具。这个代理使用RAG方法搜索相关文档(即电影)以回答用户的问题。
此代理使用以下提示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
您是一位乐于助人的助手,回答基于提供的上下文的问题。
请为每个响应遵循以下步骤:
1. 首先,仔细分析检索到的上下文块并识别关键信息。
2. 分解您的思维过程,说明检索到的信息如何与查询相关。
3. 仅根据检索到的上下文中的证据得出结论。
4. 如果检索到的块不包含足够的信息,请明确说明缺少的内容。
格式化您的响应为:
思维过程:
- 步骤 1: [对检索到的块的初步分析]
- 步骤 2: [基于块的推理]
最终答案:
[根据检索到的上下文得出的简洁答案]
重要提示:当被要求回答问题时,请仅根据工具提供的上下文来回答。
如果上下文不足以完全回答问题,请明确说明并停止。
不要添加超过检索到的块中存在的信息。
记住:解释您如何使用检索到的信息来得出结论。
如果您点击Mastra Studio > Agents菜单并选择Elasticsearch Agent,可以使用聊天系统测试代理。例如,您可以询问关于科幻电影的信息,问题如下:
找出5部关于UFO的电影或电视剧。
您会注意到代理会执行vectorQueryTool。您可以点击调用的工具查看输入和输出。在执行结束时,LLM会根据Elasticsearch的scifi-movies索引提供的上下文回复您的问题(图4)。
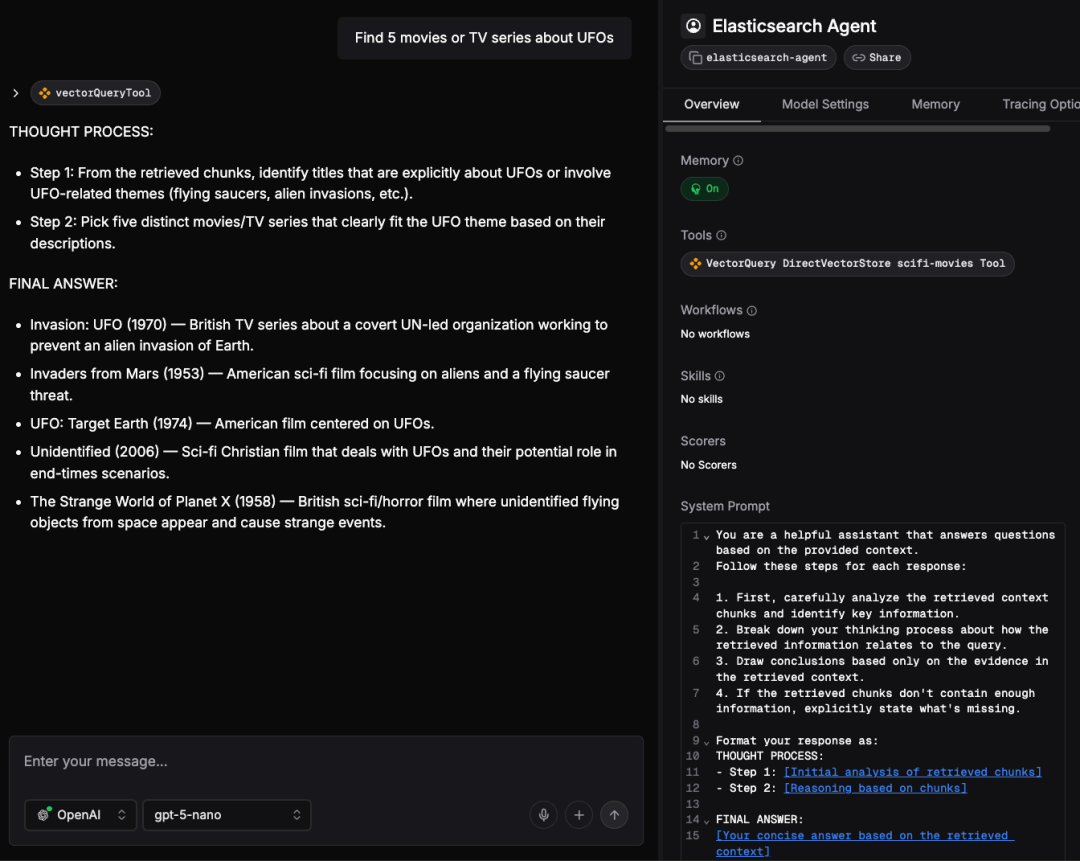
使用Elasticsearch Agent从LLM获得的响应。
使用Elasticsearch Agent从LLM获得的响应。
图4: 使用Elasticsearch Agent从LLM获得的响应。
Mastra内部执行以下步骤:
- 1. 向量转换: 用户的问题_找出5部关于UFO的电影或电视剧_使用OpenAI的
openai/text-embedding-3-small模型转换为向量嵌入。 - 2. 向量搜索: 然后使用此嵌入进行向量搜索查询Elasticsearch。
- 3. 结果检索: Elasticsearch返回一组与查询高度相关的10部电影(即与用户查询向量最近的那些电影)。
- 4. 答案生成: 检索到的电影和用户的原始问题被发送到LLM,特别是
openai/gpt-5-nano。LLM处理这些信息并生成最终答案,确保满足用户对五个结果的要求。
Elasticsearch Agent
以下是Elasticsearch Agent的源代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import { Agent } from "@mastra/core/agent";
import { ElasticSearchVector } from '@mastra/elasticsearch';
import { createVectorQueryTool } from '@mastra/rag';
import { ModelRouterEmbeddingModel } from "@mastra/core/llm";
import { Memory } from "@mastra/memory";
const es_url = process.env.ELASTICSEARCH_URL;
const es_apikey = process.env.ELASTICSEARCH_API_KEY;
const es_index_name = process.env.ELASTICSEARCH_INDEX_NAME;
const prompt = 'insert here the previous prompt';
const esVector = new ElasticSearchVector({
id: 'elasticsearch-vector',
url: es_url,
auth: {
apiKey : es_apikey
}
});
const vectorQueryTool = createVectorQueryTool({
vectorStore: esVector,
indexName: es_index_name,
model: new ModelRouterEmbeddingModel("openai/text-embedding-3-small")
});
export const elasticsearchAgent = new Agent({
id: "elasticsearch-agent",
name: "Elasticsearch Agent",
instructions: prompt,
model: 'openai/gpt-5-nano',
tools: { vectorQueryTool },
memory: new Memory(),
});
vectorQueryTool是用于实现RAG示例检索部分的工具。它使用Elastic贡献给Mastra的ElasticSearchVector实现。
代理是一个使用vectorQueryTool、提示和记忆的代理类对象。正如您所见,连接Elasticsearch到代理所需的代码非常少。
结论
本文展示了将Elasticsearch与Mastra框架集成以构建复杂的代理式AI应用的简单性和强大功能。具体来说,我们介绍了创建能够在Elasticsearch中索引的科幻电影数据语料库上进行语义搜索的RAG代理。
一个关键的结论是Elastic直接对Mastra开源项目的贡献,提供了对Elasticsearch作为向量存储的原生支持。这种集成显著降低了进入门槛,正如Elasticsearch Agent的源代码所示。使用ElasticSearchVector和createVectorQueryTool,连接Elasticsearch到您的代理的完整设置只需少量配置代码行。
Elasticsearch提供了多个高级功能以增强结果的相关性。例如,混合搜索通过结合词汇搜索和向量搜索显著提高准确性。另一个有趣的功能是使用最新Jina模型的重排序,可以在混合搜索结束时应用。要了解更多关于这些技术的信息,请参阅Elasticsearch Labs的以下文章:
- • Elasticsearch混合搜索 作者:Valentin Crettaz
- • Jina模型简介、功能及其在Elasticsearch中的用途 作者:Scott Martens
我们还鼓励您探索提供的示例,并开始使用Mastra和Elasticsearch构建您自己的数据驱动代理。有关Mastra的更多信息,您可以查看官方文档。
您认为这篇内容有帮助吗?
😔不太有帮助
😐有些帮助
😁非常有帮助
报告问题
📡 更多 Elastic & AI 可观测性干货
关注「点火三周」,第一时间获取最新技术文章
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号