INTEL:FMM CXL内存扩展


阅读收获
- 掌握CXL内存扩展的核心价值:理解其如何突破物理插槽限制,实现内存容量与带宽的线性扩展,以及在AI训练和内存数据库场景下的具体应用方式
- 理解硬件分层 vs 软件分层的本质差异:通过Intel实测数据,洞察硬件级缓存行调度为何在高压负载下比操作系统软件方案更具性能优势
- 获得TCO优化的量化参考:了解不同容量配置下CXL方案的成本节省比例(24%-40%),以及DDR4旧资产复用的实际可行性
- 洞察CXL生态成熟度:从SAP HANA、MongoDB等企业级应用和Intel、Astera Labs、澜起等芯片厂商的生态布局,判断该技术的商用就绪状态
全文概览
当前AI大模型和内存数据库的爆发式增长,正在让数据中心面临前所未有的“内存饥荒”——单机内存容量受限、带宽瓶颈加剧、TCO成本飙升。传统DDR5受限于CPU引脚数量和主板布线,已难以满足万亿参数AI模型的内存需求。
在FMS25存储峰会上,Intel联合多家生态伙伴展示了CXL内存扩展技术的最新商用进展。不同于传统的软件分层方案,英特尔推出的Flat Memory Mode(平坦内存模式)通过硬件级缓存行粒度调度,将CXL远端内存与本地DRAM融合为统一的内存池,在实现7.5TB超大容量的同时,仅带来4%的性能损耗。更关键的是,该方案可为企业节省高达40%的内存采购成本。
本文将深入解析CXL内存扩展的技术原理、TCO优化策略,以及硬件控制模式与软件分层方案的性能对比,为存储架构师和技术决策者提供可落地的参考。
👉 划线高亮 观点批注
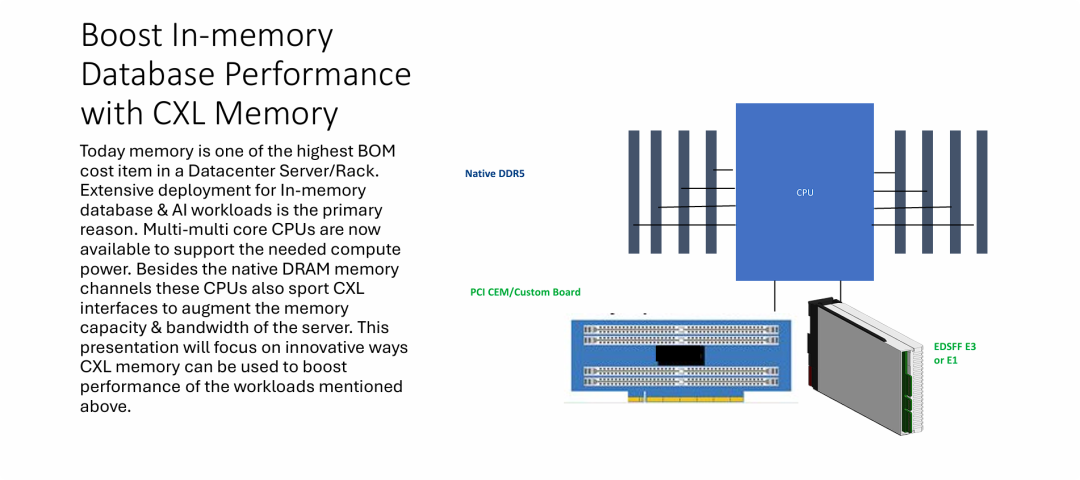
当前计算领域内存扩展的瓶颈、CXL 内存扩展的灵活样式
- 突破物理插槽限制的内存池化扩展: 传统的 DDR 通道受限于 CPU 引脚数量和主板布线复杂性,难以持续增加容量。CXL 技术允许通过 PCIe 物理链路扩展内存,使服务器能够突破“Native DDR5”的限制,大幅提升单机挂载的物理内存上限。
- 多样化的硬件形态支持(Form Factors): 图片明确展示了 CXL 内存不局限于传统的 DIMM 插槽,还可以采用 PCIe 插卡(AIC) 或 EDSFF(E1/E3) 规格。这意味着数据中心可以像增加硬盘一样,通过机箱前置框架或标准 PCIe 位来灵活增加内存容量。
- 解决 AI 与内存数据库的成本/性能矛盾: 内存数据库和 AI 计算对容量极其渴求。CXL 内存通过提供一种在“昂贵的本地 DRAM”与“低速的 SSD”之间的 扩展层(Expansion Tier),在维持高性能的同时,通过更灵活的分配和扩展方式优化了数据中心高昂的内存 BOM 成本。
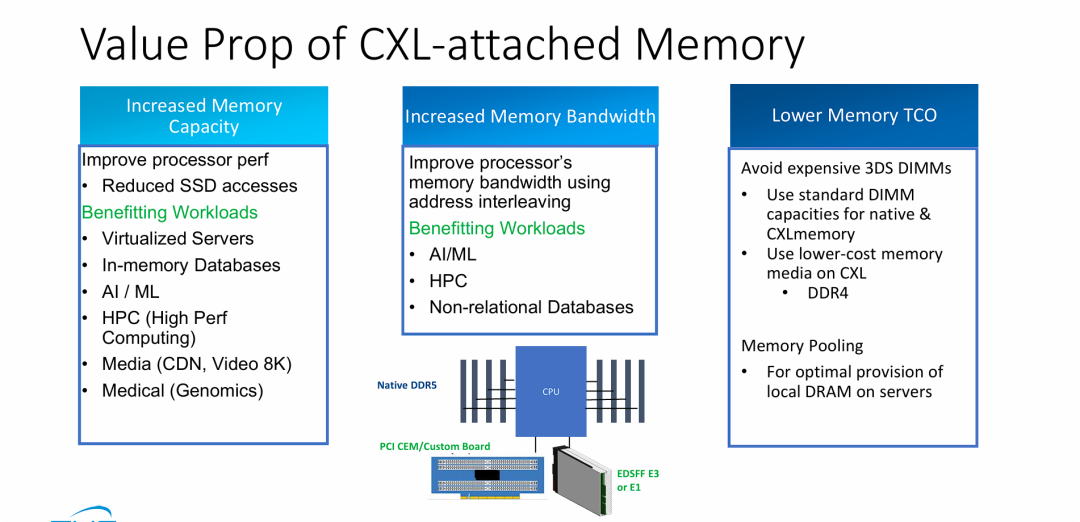
CXL 扩容内存的价值
- 性能瓶颈的突破: CXL 不仅解决了“放不下”数据的问题(容量),还通过地址交织技术解决了“读写不够快”的问题(带宽),这对于当前万亿参数规模的 AI 模型至关重要。
- 成本结构的重塑(TCO 优化): 这是该图片最核心的商业信息。通过 CXL,企业可以使用多根廉价的标准内存条或上一代介质(如 DDR4)来替代单根昂贵的超大容量 3DS DDR5 内存,从而显著降低硬件成本。
- 资源利用率的极致化: 提到的“内存池化”预示了从“单机内存”向“机柜级内存资源池”的演进,这种动态分配能力是云服务商降低运营成本的关键。

CXL 内存扩展的 TCO 测算
- 打破“大容量=超高溢价”的行业铁律: 在传统架构下,为了追求单机高容量,必须采购单价不成比例跳涨的大容量 DIMM。CXL 的核心贡献在于它提供了“增加通道”的能力,让系统可以用多根“平价小容量内存”组合出“海量内存池”,从而规避了内存厂商的溢价策略。
- 容量需求越高,CXL 的经济效益越明显: 从表格趋势看,节省比例从 24% 一路攀升至 39%。这说明在 AI 训练或大规模虚拟化等需要 4TB 以上内存的极端场景下,CXL 不再是可选项,而是降低硬件成本的必选项。
- 支持环保与存量资产复用: 图中提到的“DDR4 RDIMM 复用”是一个非常务实的观点。它允许数据中心在升级到 DDR5 平台时,通过 CXL 桥接芯片继续发挥旧内存的余热,这不仅降低了 TCO,也符合当前绿色数据中心的发展趋势。
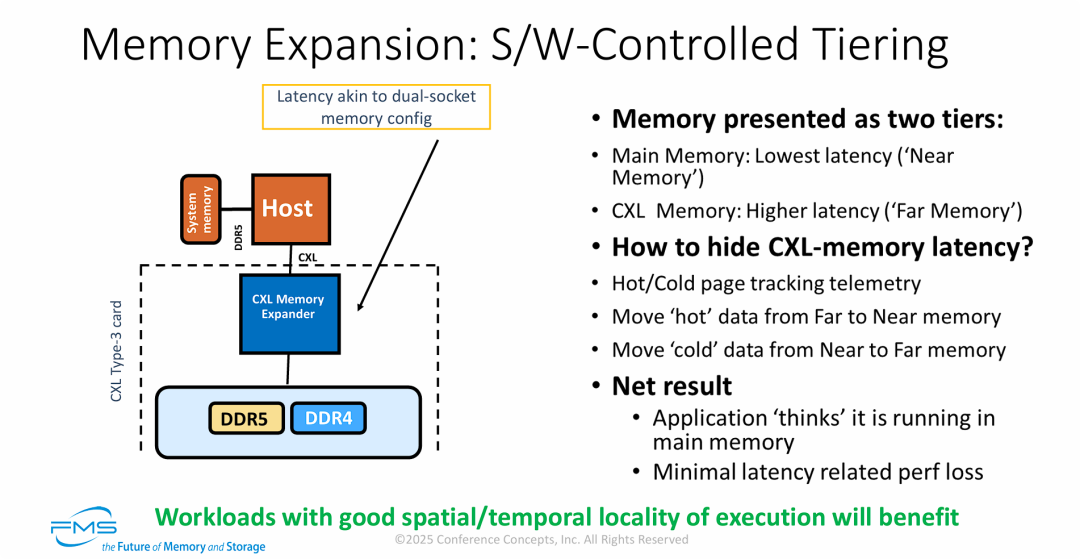
CXL 内存引入后 缓存与时延策略
- 近端与远端的异构内存分层体系: CXL 在数据中心引入了“远端内存 (Far Memory)”的架构概念。虽然 CXL 协议本身极其高效,但不可避免地存在总线物理延迟。将高速本地 DRAM 作为“缓存层/近端”,将大容量 CXL 内存(甚至是 DDR4)作为“容量层/远端”,是平衡 TCO(总拥有成本)与系统性能的必然设计。
- 软件定义的冷热数据动态调度是关键: 硬件只是提供了扩展的物理通道,真正让 CXL 内存发挥“类本地内存”性能的核心在于操作系统或 Hypervisor 层的内存页遥测与智能调度算法。通过后台持续将“热数据”升阶至本地 DRAM,系统在应用无感知的情况下成功“隐藏”了 CXL 的长尾延迟。
- 高度依赖数据访问的局部性原理: 图片的底部结论非常关键。软件分层机制(类似缓存命中逻辑)的效率取决于工作负载的特征。如果 AI 推理、图数据库或内存数据库的数据访问呈现高度的“时间局部性”(刚被访问的数据很快再次被访问)和“空间局部性”(相邻数据被连续访问),热数据迁移的命中率就会极高,从而完美掩盖远端内存的物理延迟。
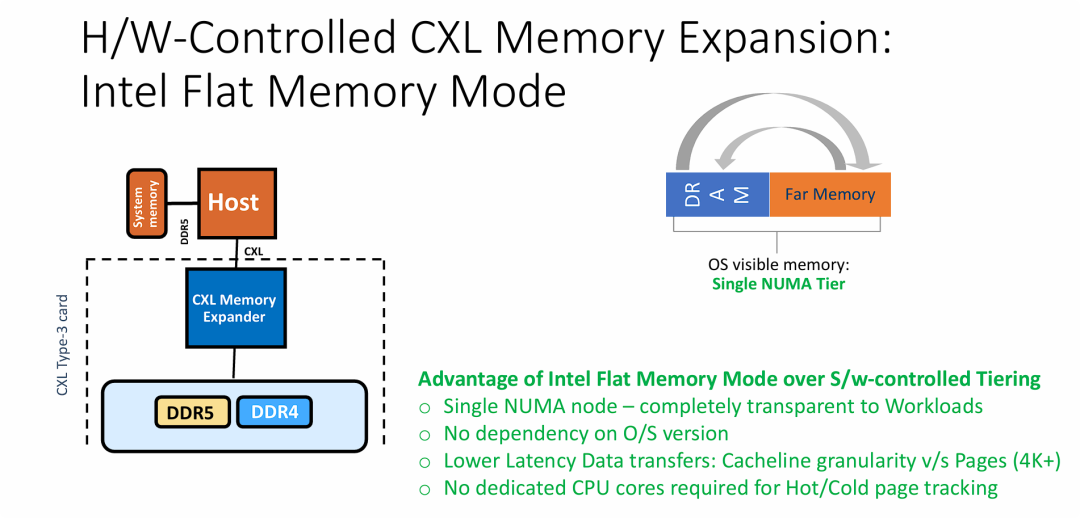
Intel Flat 内存模式 核心技术
- 实现架构级别的“即插即用”与无缝兼容: 与需要特定操作系统支持或应用改造的软件分层不同,硬件控制模式向 OS 呈现的是一个统一的、扁平的 NUMA 节点。这种“完全透明”的特性使得旧版操作系统或传统的数据库应用无需任何代码修改,就能直接享受到 CXL 带来的海量内存扩展。
- 细粒度调度大幅降低长尾延迟: 软件分层依赖 OS 移动 4KB 或更大的内存页 (Page),这在应对突发的小数据访问时效率低下且延迟高。英特尔该模式将数据调度的粒度缩小到 CPU 缓存行 (Cacheline) 级别,这种微观层面的硬件级数据搬运,能极其敏捷地响应访问需求,显著降低了数据在 DRAM 和 CXL 远端内存之间移动的延迟开销。
- 算力零损耗(释放 CPU 资源): 传统的软件层面冷热数据追踪需要消耗额外的 CPU 周期。硬件控制模式将繁重的内存遥测和数据迁移工作完全卸载 (Offload) 到了底层硬件硬件/内存控制器上,这意味着服务器可以将 100% 的 CPU 核心算力用于核心业务计算(如 AI 训练或复杂查询),从而提升了整体系统的能效比。

基于 INTEL Flat 内存 SAP HANA 数据库测试
- “平坦内存模式”的硬件缓存机制被真实业务验证有效: 面对 7.5TB 如此庞大的 SAP HANA 内存数据库,采用 50% 的低速/高延迟 CXL DDR4 替代原生高速 DDR5,竟然只带来了 4% 的性能损耗。其背后的核心原因是“近端内存未命中率”极低(<1%),这证明了英特尔硬件级微架构在预测和调度数据局部性方面表现优异,绝大多数访问都精准命中在了本地高速 DDR5 中。
- 极端的 TCO 优化策略(40%+ 成本直降): 在传统架构下,为了构建 8TB 单机内存节点,企业只能被迫采购溢价极高的单根 256GB DDR5 内存。该方案通过引入 CXL,允许降级使用单根 128GB 的 DDR5,并“废物利用”上一代相对廉价的 DDR4 组建远端容量层,这不仅规避了存储厂商的高容量溢价,更是绿色计算和资产复用的经典案例。
- CXL 生态已进入企业级商用的成熟期: 图片底部披露的软硬件生态极具分量。从底层的芯片(Intel Xeon 6, 澜起 CXL 控制器),到顶层的核心企业级应用(SAP HANA),再到最终的云端部署环境(Azure),这表明 CXL 内存层级技术(Memory Tiering)已经跨越了概念验证(PoC)阶段,具备了在最严苛的生产环境中大规模落地的能力。
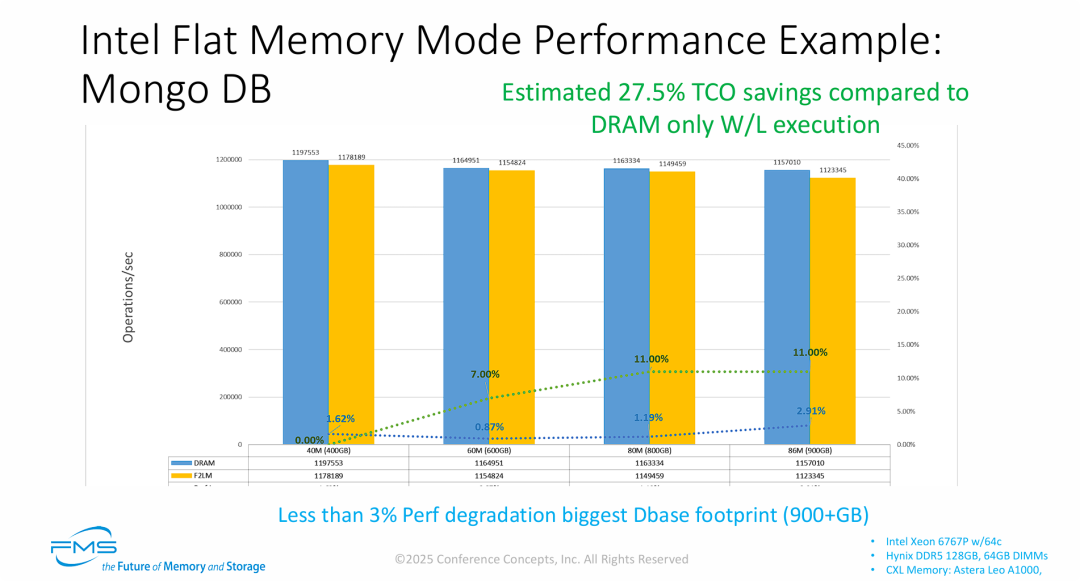
基于 INTEL Flat 内存 MongoDB 数据库测试
- 攻克 NoSQL 的随机访问难题(性能韧性强): MongoDB 这类文档型数据库的特点是数据访问的随机性强,对内存延迟极为敏感。测试结果显示,即便在接近 1TB 的内存容量下,CXL 平坦内存模式依然能将每秒操作数(OPS)的衰减控制在 3% 以内。这有力地证明了底层硬件级别的“缓存行粒度调度”在应对复杂、非连续内存访问时的极高效率。
- 稳健的商业回报预期(27.5% TCO 节省): 相比于上一张 SAP HANA 极致的 40% 节省,这里 27.5% 的 TCO 节省依然是一个极其可观的数字。它向数据中心架构师证明,引入 CXL 技术并非仅仅为了跑分,而是能在各种主流企业级应用中实打实地削减硬件采购预算。
- CXL 芯片生态供应链的繁荣与成熟: 这是一个非常值得关注的产业细节:前一张幻灯片使用的是澜起科技 (Montage) 的 CXL 控制芯片,而本张幻灯片使用的是硅谷独角兽 Astera Labs 的 Leo A1000 控制芯片。两家不同的头部 CXL 芯片厂商,配合 Intel Xeon 6 处理器,都跑出了极佳且稳定的性能数据。这标志着 CXL Type-3 内存扩展生态已经摆脱了单一厂商的束缚,形成了成熟、可靠且多元化的供应链体系。
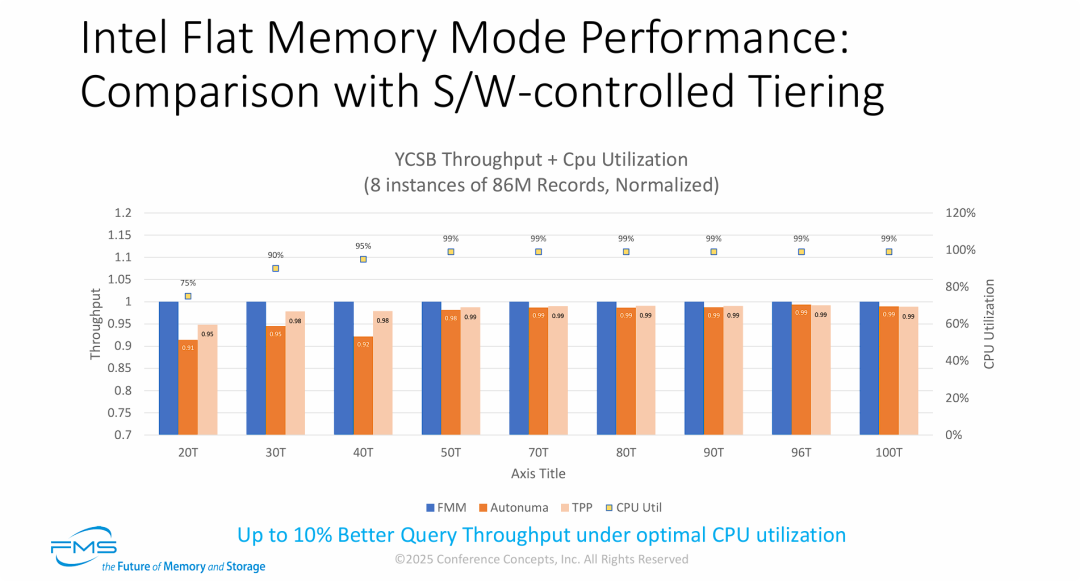
对比了硬件主导的内存分层(FMM) 与操作系统软件主导的内存分层在实际高压工作负载下的性能差异
- 硬件调度的敏捷性在突发负载中优势尽显: 在 20T 到 40T 的区间(CPU 处于 75%-95% 的准满载状态),软件分层方案出现了明显的吞吐量掉队(落后 5%~9%)。这是因为基于“页面 (Page)”迁移的软件追踪机制存在滞后性,而 FMM 基于硬件底层的“缓存行 (Cacheline)”微观调度,能够极其敏锐地响应内存访问热点的变化,避免了性能的瞬时衰减。
- 算力零损耗打破了高并发下的性能“天花板”: 当并发线程达到 50T 及以上时,CPU 资源已被业务彻底榨干(利用率 99%)。在这种情况下去运行复杂的软件内存调度算法(Autonuma/TPP),必然会与核心业务(数据库查询)发生算力争抢。FMM 的核心优势在于它将内存调度完全卸载 (Offload) 到了内存控制器硬件上,实现了 CPU 的“零负担”,因此在极限高压下依然能保持更高的吞吐极值。
- 软件优化难以逾越物理架构的鸿沟: 图中可以看出,较新的软件技术 TPP 确实比老旧的 Autonuma 表现更好(例如在 20T 时从 0.91 提升到了 0.95)。然而,无论软件算法如何精进,只要调度动作还需要跨越操作系统内核层,就必然产生额外的延迟开销。这印证了 CXL 生态向底层硬件控制(Hardware-controlled Tiering)演进是追求极致性能的唯一正确解。
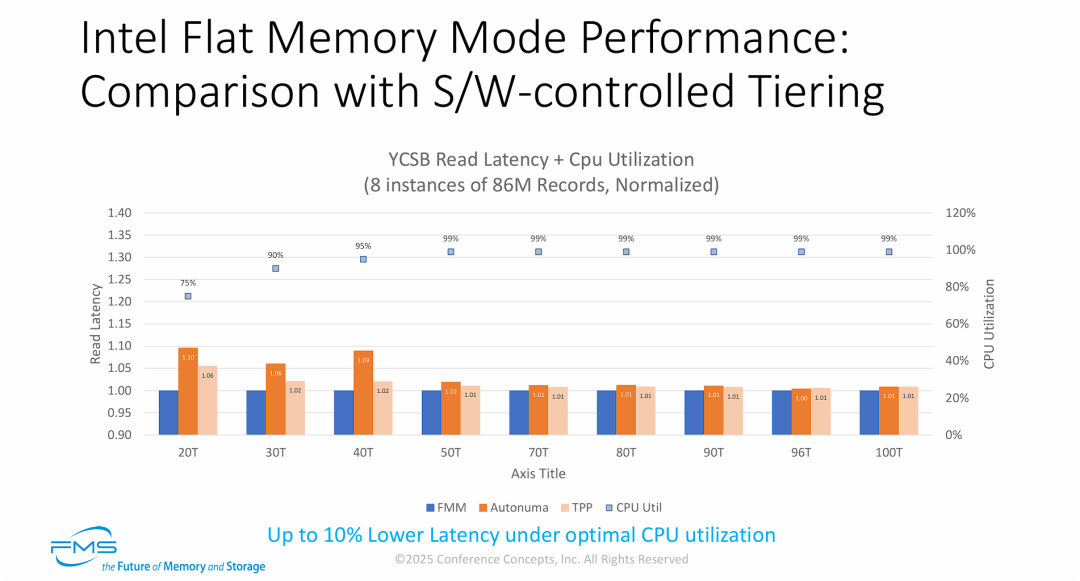
结合上一张“吞吐量”图表,这份“读延迟”数据进一步巩固了硬件主导 CXL 内存池化的技术优势。
- 硬件级微观调度是消除“长尾延迟”的克星: 在 20T-40T 的日常高并发场景下(CPU 75%-95%),软件分层机制(Autonuma)暴露出了严重的延迟惩罚(高达 10%)。这是因为操作系统在进行 4KB 甚至更大颗粒度的“内存页 (Page) 迁移”时,会引发显著的上下文切换和总线锁定开销。而 FMM 依赖底层硬件进行细粒度的“缓存行 (Cacheline)”搬运,完美规避了这种软件开销,保持了极低且稳定的读取延迟。
- TPP 虽有进步,但“越过 OS 内核”才是终极解法: 图表客观地显示,较新的软件技术 TPP(浅橙色)在控制读延迟方面比老旧的 Autonuma(橙色)要好得多(惩罚从 10% 降到了 6%)。但这依然无法改变其作为“软件层”的物理局限。要为延迟极其敏感的现代内存数据库(如 Redis, SAP HANA)提供极致性能,将调度逻辑硬化到 CPU/内存控制器的硅片中(FMM)是唯一的终极解法。
- 系统极限满载下的延迟趋同现象(物理瓶颈转移): 一个非常有趣的现象是,当并发达到 50T 及以上,CPU 利用率彻底锁死在 99% 时,三种方案的读延迟差距急剧缩小(均在 1.00 - 1.02 之间)。这并非软件方案变快了,而是因为在极度拥塞下,系统的最大瓶颈已经从“内存访问延迟”转移到了“CPU 算力饥荒”。这反向证明了,在系统处于正常且健康的最佳利用率(Optimal CPU utilization, <95%)时,FMM 的降延迟价值最为凸显。
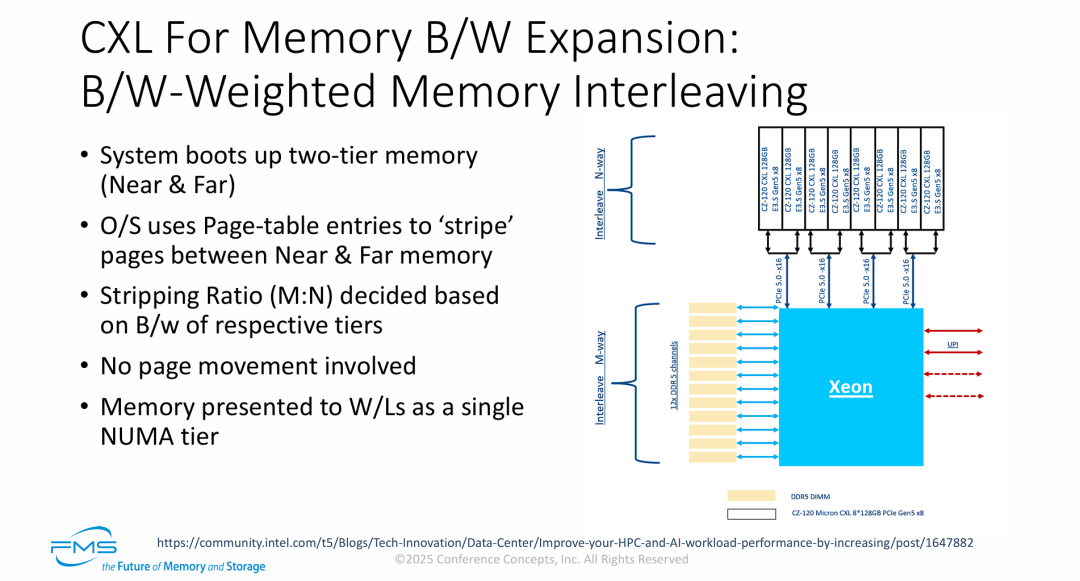
如何利用 CXL 架构来大幅度提升服务器的总内存带宽 (Bandwidth, B/W)
- 突破“内存带宽墙”的并发读取策略: 在 AI 训练和高性能计算(HPC)中,算力往往受限于内存喂数据的速度(带宽瓶颈)。该方案通过“内存交织”,让 CPU 在读写数据时,能够同时并发调用本地的 12 通道 DDR5 带宽和新增的 4 路 PCIe 5.0 x16 CXL 带宽,实现了系统总内存吞吐量的物理级叠加。
- “零额外开销”的静态负载均衡: 图中特别强调了“不涉及页面移动”。这代表它与之前依赖监控冷热数据并不断来回搬运数据的动态分层(Tiering)技术截然不同。这种基于带宽权重的条带化是静态分配的,数据写入时就按比例打散。因此,它不消耗额外的 CPU 算力去追踪热点,也没有数据迁移带来的延迟抖动,开销极低。
- 异构硬件的软件级抽象: 将速度不同的原生 DRAM 和 CXL 内存融合,最大的挑战是木桶效应。该方案利用操作系统的页表管理和加权算法(强大的能力强的多干活,弱的少干活),成功将异构的物理硬件对上层应用彻底屏蔽,伪装成了一块速度极快、容量极大的单一 NUMA 内存池。
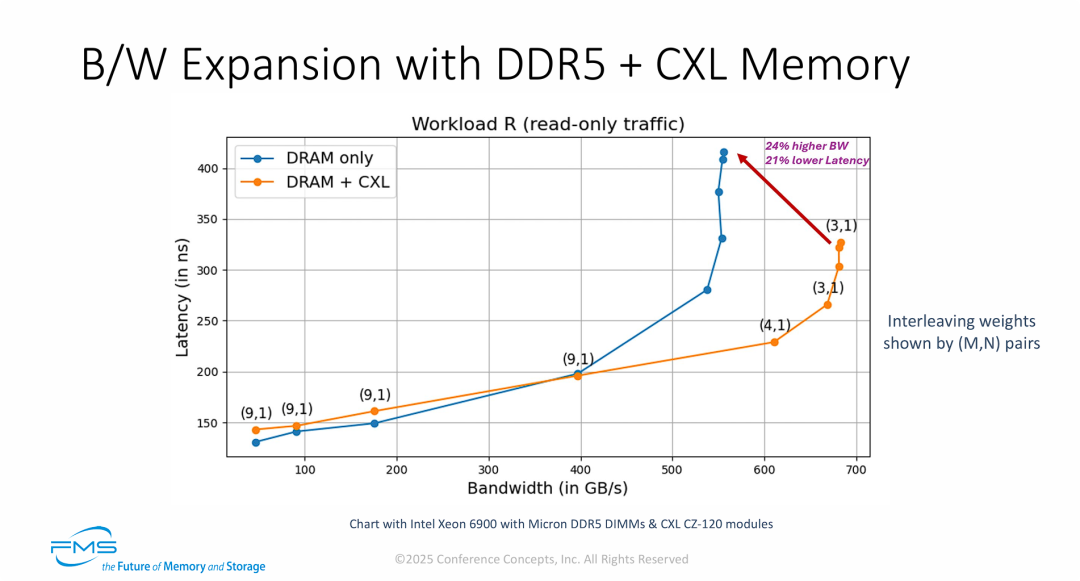
CXL 在解决现代数据中心“数据饥荒”时的核心技术价值:
- 成功突破“内存带宽墙”的物理极限: 随着 CPU 核心数暴增和 AI 模型参数量的膨胀,算力的提升速度远大于内存通道数量的增加。图中的蓝色曲线证明了传统架构在面对高吞吐需求时极其脆弱。CXL 扩展相当于直接为数据中心拓宽了“高速公路”,将系统总吞吐上限硬生生推高了 24%,让多核 CPU 不再需要因为等待数据而空转。
- 高并发下的反直觉胜利(用带宽换延迟): 一个常见的物理直觉是“CXL 会增加延迟”。但红色的核心结论打破了这一认知:在系统处于极限高并发状态时,DRAM+CXL 架构反而让延迟下降了 21%。其底层逻辑在于,当并发请求海量涌入时,“排队拥堵时间 (Queueing Delay)”远比“物理传输时间”更致命。CXL 增加的额外通道起到了极佳的泄洪作用,大幅降低了排队延迟。
- 动态自适应的软硬件协同调优: 图中的 (M,N) 交织权重变化非常有技术含量。从 (9,1) 逐步过渡到 (3,1),说明在系统负载较轻时,操作系统刻意将 90% 的流量压在低延迟的本地 DRAM 上;而当遭遇海量吞吐压力时,系统动态调整策略,让 CXL 承担更大比例(1/4)的流量。这种智能的比例动态调整,是确保全负载区间性能平滑的关键。

- CXL 跨越了“炒作期”,迈入实质性商用阶段: 总结中强调了“生态系统的显著成熟”。结合前面展示的多家厂商(Intel, Astera Labs, Montage, Micron, Hynix)和成熟应用(SAP HANA, MongoDB)的数据,这表明 CXL 已经不再是停留在白皮书上的概念,而是具备了完整的硬件供应链和软件验证,可以直接转化为企业的 TCO 降本工具。
- “硬件定义内存”成为行业共识: 英特尔的“平坦内存模式”并拉踩“软件分层”,标志着在追求极致性能的存储架构中,将复杂的内存路由与调度逻辑卸载 (Offload) 到硬件底层(CPU/内存控制器)已经成为行业公认的最优解。
- 精准踩中生成式 AI 的核心痛点 (RAG 加速): 最后的行动号召中提到了“加速 AI RAG 数据库”。在当前的大模型时代,企业级 AI 极度依赖 RAG 技术来读取私有知识库,这需要极其庞大的向量数据库和极高的瞬时内存读取带宽。这里指出 CXL 内存交织技术是解决这一痛点的关键钥匙,完美地将 CXL 这项存储技术与当前最火热的 AI 商业化落地需求绑定在了一起。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- 在您的实际业务场景中,内存容量的瓶颈是否已经影响到AI推理或数据库性能?引入CXL内存扩展方案时,您最优先考虑的是性能、兼容性还是成本因素?
- 硬件主导的内存分层(FMM)与操作系统软件分层方案,您认为哪种更适合当前的数据中心架构?这是否意味着软件层面的内存调度优化将逐渐被硬件卸载所取代?
- 考虑到CXL生态的多厂商供应链已经形成(Intel、Astera Labs、澜起等),企业在选型时应如何平衡技术领先性与供应链风险,以确保未来3-5年的架构可持续性?
原文标题:Boost In-memory Database Performance with CXL Memory[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #CXL内存扩展
---【本文完】---
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号