UCF AI Institute | MedRoute:RL 训练全科医生 Agent 动态路由多专科 LMM,MedQA 88.76% 超越 MAM
原创
UCF AI Institute | MedRoute:RL 训练全科医生 Agent 动态路由多专科 LMM,MedQA 88.76% 超越 MAM
原创
CoovallyAIHub
发布于 2026-04-27 13:58:51
发布于 2026-04-27 13:58:51
导读
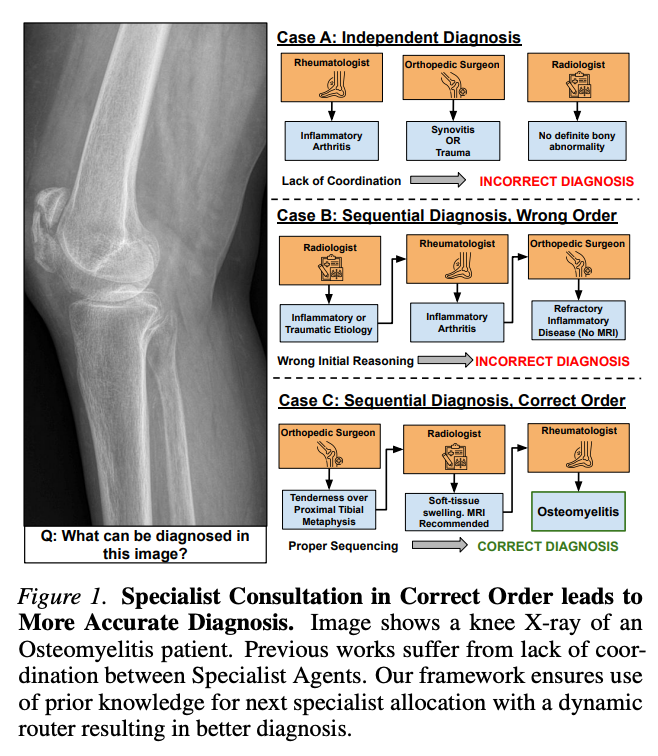
当前多模态医疗 Agent 框架(MedAgents、MDAgents、MAM)多采用静态或预定义的专家选择——Agent 池一次性定死、调用顺序固定、各专家之间缺乏前后诊断上下文传递,不符合真实临床的串联流程:全科医生(GP)先看,根据患者反馈决定下一步转诊谁,逐步收敛到诊断。论文开篇给出了一个直观例子:一张膝关节 X 光骨髓炎病例,独立诊断(Case A)因缺乏协调给出错误诊断、顺序错误(Case B)因初始推理偏差也错,只有按正确顺序的顺序诊断(Case C,骨科 → 放射科 → 风湿科)才能给出"骨髓炎"的正确结论。
中佛罗里达大学(UCF)人工智能研究所 Mubarak Shah 团队提出 MedRoute:一个三类 Agent 构成的动态多 Agent 医疗诊断框架——General Practitione(GP,RL 训练的专家分配器)+ Specialists(专科 LMM Agent 池)+ Moderator(综合诊断)。GP 的核心是一个基于 Routing Transformer + MLP 的动态路由器,用分步强化学习 + 分组优势估计训练,以最终诊断的正确性作为奖励信号。每次路由基于"输入 + 专家池 + 已咨询专家的诊断历史"决策下一个应咨询的专科,直至 GP 判定诊断充分。
在 2 个文本医疗数据集(MedQA、PubMedQA)和 3 个图文医疗数据集(PMC-VQA、DeepLesion、PathVQA)上:MedRoute 在五个数据集全部占优——MedQA 88.76% vs GPT-4.1-mini 85.86%(+2.90 个百分点;论文原文记作 ∼6%)、vs MAM 82.95%(+5.81 个百分点);DeepLesion 相对 MAM +5.47 个百分点(论文记作 ∼5.5%)。
论文信息
- 标题:MedRoute: RL-Based Dynamic Specialist Routing in Multi-Agent Medical Diagnosis
- 作者:Ashmal Vayani*, Parth Parag Kulkarni*, Joseph Fioresi, Song Wang, Mubarak Shah
- 机构:Institute of Artificial Intelligence, University of Central Florida(UCF CRCV)
- 底层 LMM:GPT-4.1-mini(所有 Agent 统一 backbone)
- 发表状态:2026 年 4 月公开
一、为什么静态多 Agent 医疗框架不够?
近年医疗 LMM 方向进展快速:BiomedGPT、Medichat-LLaMA3、LLaVA-Med在文本理解、视觉 QA、疾病分类、病灶检测、报告生成等多类任务上微调;RadFM、RadVLM聚焦放射科,ChatGLM聚焦脑卒中。但单一模型天花板明显:通用大模型过于宽泛、难以覆盖真实临床的众多子专科(神经、心血管、呼吸、内分泌等);为每个子专科单独训模型数据采集和训练成本都很高。
多 Agent 框架提供"中间路线":不必训单一超级模型,用多个专科 Agent 协作也能处理多样临床场景。但现有工作有共同缺陷:
- MedAgents (Tang et al., 2024)、MDAgents (Kim et al., 2024)用预定义专家集合和手工设计的工作流
- MAM (Zhou et al., 2025)是目前最接近 MedRoute 的先行工作——包含 GP、Specialists、Radiologist、Medical Assistant、Director,但作者指出其两个关键问题:(1)一开始就定死专家集合、过程静态;(2)专家之间独立运行、不利用前序专家的诊断作为上下文
图片来源于原论文
MedRoute 针对这两个缺陷做了两项改动:
- GP 不是固定流程而是基于 RL 训练的动态路由器,按当前诊断进度决定下一个专家
- 每次路由都输入已咨询专家的诊断历史作为关键上下文,匹配真实临床
二、方法:GP 路由器 + 专科池 + Moderator 三件套
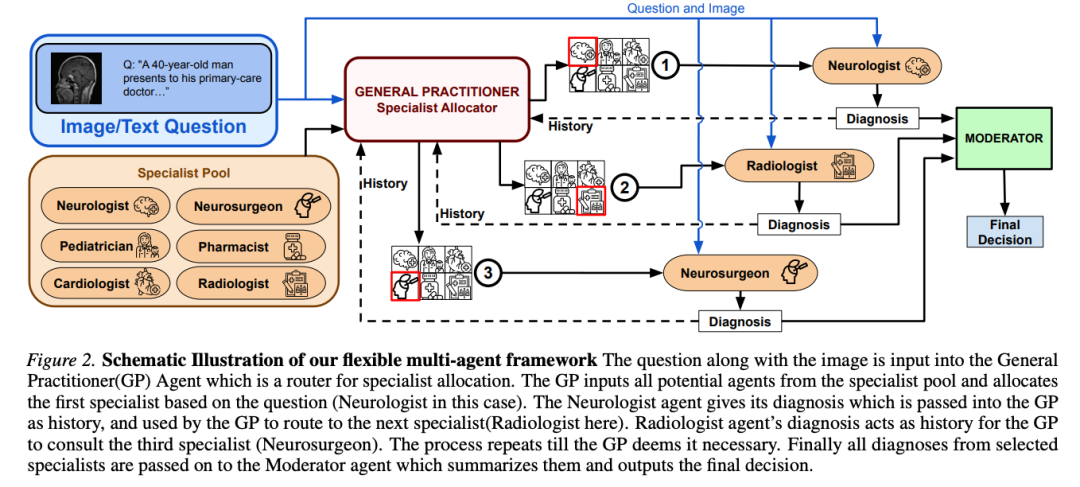
整体结构:用户输入 Image/Text 问题 → GP(Specialist Allocator)接收问题 + 图像 → 从 15 位专科(Neurologist / Pulmonologist / Neurosurgeon / Pediatrician / Gastroenterologist / Radiologist / Cardiologist / Dentist / Thoracic Surgeon / Orthopedic / Hematology / Rheumatologist / Infectious Disease Specialist / Urologist / Pharmacist)构成的专家池选第一位专家 → 该专家给出诊断 → GP 以诊断为历史输入 → 路由下一位专家 → 重复 → GP 判定足够时停止 → 所有诊断传给 Moderator→ Moderator 综合多专家输出形成统一临床判断并产出最终诊断。
图片来源于原论文
专家池构造:作者用 GPT-4.1-mini 对数据集逐题询问"这道题应该让哪 3-7 位专家回答",把所有样本的专家列表合并、按出现频率排序、取 top-k 构成最终专家池。
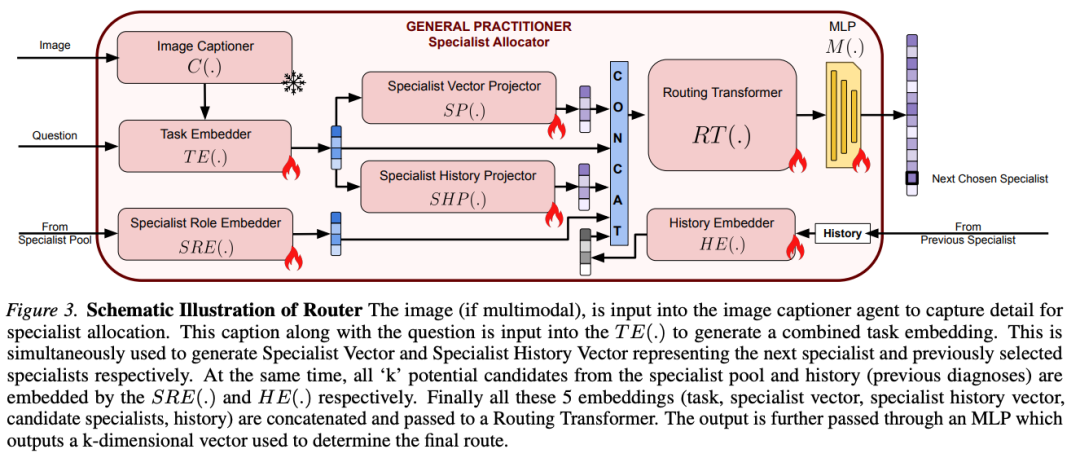
GP 路由器架构:
- Image Captioner C(·):冻结的 image-to-caption LMM(不传原图而是传 caption,降算力):im' = C(im)
- Task Embedder TE(·):把 question + image caption 合并成任务 embedding:q' = TE(q ∥ im')
- Specialist Vector Projector SP(·)和 Specialist History Projector SHP(·):从 q' 生成两个向量——下一个要选的专家表示 sv 和已选专家表示 shv
- Specialist Role Embedder SRE(·):把专家池里每个专家 s_i 嵌成 s'_i
- History Embedder HE(·):已咨询专家的诊断历史 h 嵌成 h'
- 5 个 embedding 拼接:ip = q' ∥ s'_0 ∥ s'1 ∥ ... ∥ s'{k-1} ∥ h' ∥ sv ∥ shv
- Routing Transformer RT(·)(预训练 GPT-2)输出 sp = RT(ip)
- MLP M(·)(两层 ReLU)+ softmax 得到下一个专家概率分布:sp' = softmax(M(sp))
图片来源于原论文
动态顺序诊断:首次路由时无历史、仅用输入 + 专家池;后续每步用"输入 + 专家池 + 已查询专家的诊断历史"决定下一步。GP 决定不再需要更多专家时调 Moderator 汇总所有诊断。每次推理 run 都记录完整的路由轨迹、所有专家输出、Moderator 最终决策——透明可复现。
RL 训练:
- 奖励:r = γ^l · RM(y_pred, y_gt),其中 l 是路由步数、γ = 0.98 鼓励更简短的路由(避免浪费路由到弱相关专家),RM(·) ∈ {0, 1} 由 GPT-4.1-mini 作为奖励模型基于"预测是否匹配 ground truth 的语义"判定(覆盖开放问题的语义匹配情况)
- 分组优势估计:A_t = (r_t - mean(r)) / (std(r) + ε)——对同一道题的多条轨迹做奖励归一化,避免"容易题总获高奖"使难题的路由学习信号被淹没
- 策略梯度:L_PG(θ) = -(1/G) Σ log π_θ(sp'_t | ip_t) · A_t
- 训练设置:单张 NVIDIA RTX A6000 GPU、AdamW lr=1e-5、10 epochs;每个 epoch 从训练集采样 80-100 个题、每题最多生成 8 条轨迹、遇到一条正确就停(原文"maximum of 8 traces with 80-100 samples");轨迹生成 temperature = 0.7,投影器/嵌入器输出维度 768,Routing Transformer 基于预训练 GPT-2,Routing MLP 两层 ReLU,最大上下文 2048
推理管线:GP 接收问题(+ 可选图像,经 frozen captioner 转 caption 与 text 融合成 task embedding)→ 无历史时仅基于 task + 专家池选首位专家 → 首位专家输出诊断 → 追加到共享诊断记录 + GP 历史状态 → GP 反复调 Allocator 判断是否需要更多专家 → 每步基于"任务 + 累积历史 + 可用专家"动态决策 → GP 判定无需继续咨询时,记录传给 Moderator → Moderator 综合 → 最终诊断。
三、实验结果:五个数据集全线领先
数据集:
- 文本:MedQA(1273 测试样本)、PubMedQA(1000)
- 图文:PMC-VQA(2000)、DeepLesion(4736)、PathVQA(6719)
- 所有 agent 的 backbone 统一 GPT-4.1-mini
文本数据集对比:
模型 | MedQA | PubMedQA |
|---|---|---|
Qwen3-8B | 45.39 | 20.65 |
MedAlpaca-7B | 34.53 | 19.90 |
Medichat-Llama3-8B | 45.68 | 32.81 |
GPT-4.1-mini | 85.86 | 34.50 |
MAM | 82.95 | 37.30 |
MedRoute (Ours) | 88.76 | 38.60 |
在 MedQA 上 88.76% vs GPT-4.1-mini 85.86%(+2.90 绝对百分点,论文原文记作 ∼6%),在 PubMedQA 上超 MAM +1.30 绝对百分点(论文原文记作 ∼2%)。基线规律:医疗专用模型(Medichat、MedAlpaca)总体强于通用小模型(Qwen3-8B),除了 GPT-4.1-mini 这种超大型通用模型是例外——MedRoute 在 GPT-4.1-mini 基础上再提升。
图文数据集对比:
模型 | PMC-VQA | DeepLesion | PathVQA |
|---|---|---|---|
LLaVA-OneVision | 51.15 | 40.67 | 17.93 |
Phi-3.5-vision-instruct | 41.35 | 30.95 | 13.74 |
Qwen2.5-VL | 52.66 | 43.20 | 19.46 |
BioMedGPT | 2.00 | 10.18 | 1.97 |
LLaVA-Med-v1.5-Mistral-7B | 36.29 | 33.80 | 40.56 |
GPT-4.1-mini | 58.60 | 45.42 | 40.59 |
MAM | 58.15 | 40.05 | 38.37 |
MedRoute (Ours) | 59.28 | 45.52 | 41.30 |
三个数据集全部夺冠,DeepLesion 相对 MAM +5.47 个百分点(45.52 vs 40.05)、相对 GPT-4.1-mini 仅 +0.10。医疗专用 VLM 在部分数据集上反而低于通用 VLM(BioMedGPT PMC-VQA 只有 2%)。
消融 1:路由器设计(MedQA 1273 题,Medichat-LLaMA3-8B backbone):
- Cosine Similarity 路由器(直接用 RT 输出与专家角色 embedding 相似度决策):40.61%、517 正确
- MLP 路由器(本文):42.03%、535 正确
MLP 比余弦相似度好约 1.4 个百分点——MLP 能学到非线性的专家选择策略。
消融 2:底层 LMM(MedQA 1273 题,MLP 路由器):
- Medichat-LLaMA3-8B:42.03%、535 正确
- GPT-4.1-mini:88.76%、1130 正确
底层 LMM 差距极大——GPT-4.1-mini 比 Medichat-LLaMA3-8B 绝对高 46.7 个百分点。这个消融确认了"Agent 编排的增益建立在基础模型能力之上,两者相乘才是最终表现"。
四、论文自陈的边界与未来方向
专家池手工构造:当前专家池通过 GPT-4.1-mini 预查询 + 频次排名产生,是一次性静态产物。作者在 Conclusion 明确指出未来要动态生成专家池——按具体病例在线构造相关专家集合,而不是所有病例共享一个固定池。
未接 EHR:当前只用 QA 对作为输入,没接真实电子病历(EHR)。作者预告下一步要把 EHR 纳入个性化诊断。
数据集受限:DeepLesion 原为病灶分类标签,作者手工处理成 QA 对(Appendix D.1),单正确答案的样本剩 4,736 条——评测集虽覆盖 5 个数据集但 QA 格式转换的影响有待独立验证。
奖励模型依赖 GPT-4.1-mini:RM(·) 用 GPT-4.1-mini 做二元判定(答对=1,错=0)——同一个模型既是 backbone 又是评判,存在潜在自我偏好。作者未评估这个可能的循环偏差。
五、总结与思考
MedRoute 的核心设计判断可以用一句话概括:把"哪个专家该看下一步"变成一个可学习的策略问题,而不是工程师手工设计的流程。大多数多 Agent 框架(MedAgents、MDAgents、AutoGen、CrewAI)的协作流程是硬编码的;把"流程"本身交给 RL,让数据决定"什么病人该先转诊哪个专家",更接近临床现实。
在此基础上,有几点值得进一步思考:
- "RL 训练路由器"是通用 Agent 编排范式:法律咨询、工业诊断、供应链决策都有"coordinator 动态决策 + summarizer 综合"的同构结构——Routing Transformer + MLP + 分步 RL + 分组优势估计这套机制可直接迁移
- γ=0.98 长度衰减把"少转诊早诊断"编码进奖励:比后续加"正则化项"更直接,契合节约医疗资源的现实指标
- 底层 LMM 比路由器设计重要得多:MLP vs Cosine 仅差 1.4%,GPT-4.1-mini vs Medichat 差 46.7%——落地启示是先把基础模型选对,再挖路由编排的 2-5% 提升
- Moderator 的加权机制被低估:多个专家可能给出矛盾诊断,怎么加权、何时采纳少数意见——是实践中最棘手的问题,后续应把 Moderator 也做成可学习模块
MedRoute 最大的启示:医疗 Agent 可用性短期内不在"更大的模型"或"更精细的医疗微调",而在"更接近临床流程的多 Agent 编排 + 可学习的动态路由"。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号