艾因夏姆斯大学 | Grid-Mind:DeepSeek-R1 电网问答偏差 33 倍,三层反幻觉防御 + 11 工具做 CIA
原创
艾因夏姆斯大学 | Grid-Mind:DeepSeek-R1 电网问答偏差 33 倍,三层反幻觉防御 + 11 工具做 CIA
原创
CoovallyAIHub
发布于 2026-04-27 14:14:35
发布于 2026-04-27 14:14:35
导读
美国清洁能源转型的核心瓶颈在发电机互联队列(Interconnection Queue):2023 年底超过 2,600 GW容量在 RTO 队列中排队,平均研究周期 2.1 年 → 5.0 年,部分地区撤销率超 80%。堵点是 Connection Impact Assessment(CIA,并网影响评估)——串行跑稳态潮流、N-1 故障、瞬态稳定、电磁暂态四类分析,目前还高度依赖人工。
埃及艾因夏姆斯大学的 Mohamed Shamseldein(IEEE Senior Member,独作)提出 Grid-Mind:一个 LLM-first 的域专用 Agent——11 工具注册表 + 4 仿真后端(PandaPower/ANDES/ParaEMT/PSS/E) + 多保真度 CIA 流水线 + 三层反幻觉防御 + Prompt 级自纠正循环。IEEE 118-bus 的 50 场景评测(DeepSeek-V3):工具选择准确率 84.0%、参数解析 100%、单场景 15.89 秒、$0.002/场景;独立 56 场景自纠正套件 49/56(87.5%)、均分 89.29;歧义字段类别经澄清门修复后 TSA 从 13.3% 升到 100.0%。目前正在 IEEE Transactions on Smart Grid审稿。
论文信息
- 标题:Grid-Mind: An LLM-Orchestrated Multi-Fidelity Agent for Automated Connection Impact Assessment
- 作者:Mohamed Shamseldein(独作,IEEE Senior Member)
- 机构:Ain Shams University 电力电机系(埃及开罗)
- 发表状态:IEEE Transactions on Smart Grid 审稿中
- 专利:美国临时专利申请 App. No. 63/989,282
一、互联队列为什么会卡?CIA 这道关到底难在哪?
论文给出的数字很具体:2023 年底美国 RTO 队列 >2,600 GW容量排队、平均研究周期 2.1→5.0 年、部分地区撤销率 >80%。FERC Order No. 2023要求加速流程和推进集群研究,但 CIA 本身仍是工程瓶颈——它是以人工为主、顺序执行的过程。
现有路径的共同问题:LLM 做代码生成/注释的工作不执行仿真;ChatGrid 类"电网操作员副驾"用的是简化模型、与生产级求解器脱节;CIM、数字孪生方向做建模但没有自然语言接口;ReAct/Toolformer/ToolLLM/OpenClaw 是通用 Agent 框架、未针对电力系统做物理 grounding 和 CIA 编排。论文 Table I 横向对比显示,Grid-Mind 是首个同时覆盖"自然语言输入 + 真实求解器执行 + 多保真度级联 + 物理 grounding 违规检查 + 持久记忆 + 自纠正"六个维度的系统。
二、Grid-Mind 架构:四层堆栈 + 多保真度流水线
四层堆栈:Interface(FastAPI + Web Dashboard + Health Monitor)→ Agent(Tool Registry + Conversation Agent + LLM Backend + Lessons & Memory)→ Simulation(稳态 PF → N-1 → 瞬态 → EMT → Violation Inspector)→ Solver(PandaPower / ANDES / ParaEMT / PSS/E 四个适配器)。
Solver-Agnostic 抽象基类GridSolver定义 20+ 抽象方法覆盖案例加载、潮流求解、结果访问、故障执行与违规检查。四个适配器分工明确:PandaPower 做稳态/OPF 初筛;ANDES 做高保真时域瞬态;ParaEMT 做低短路比(SCR<3.0)的快速电磁暂态;PSS/E 面向公用事业环境(当前作兼容存根)。
违规检查器对照 NERC TPL-001 规划标准做 solver-agnostic 检测,输出 V(s) = v v ∈ check(s, ℓ),其中 ℓ 是电压/负载/相角限值四元组。硬违规和"边界"情况(默认电压 ±0.01 p.u.、负载 ±5% 容差)分开处理。
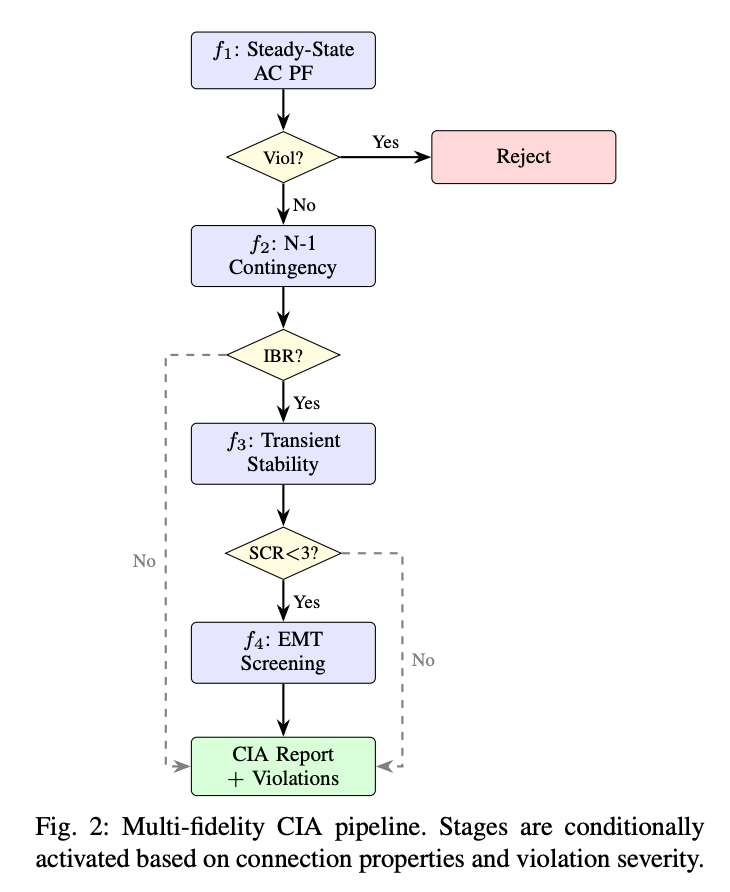
多保真度 CIA 流水线(Fig. 2)是一条四阶段瀑布:
f1 稳态 AC PF → 违规?Reject
↓ 无违规
f2 N-1 Contingency → IBR?
↓ 是
f3 Transient Stability (ANDES, 10s) → SCR<3?
↓ 是
f4 EMT Screening (ParaEMT)形式化表达 **f* = max{k : φ_k(r) = true}**。阶段验收标准见 Table II:f1 用 NORMAL 限值(电压 0.95–1.05 p.u.、热 Rate A 100%);f2 用 EMERGENCY 限值(电压 0.90–1.10 p.u.、热 Rate B 110%),且默认 "material worsening" 阈值 +2.0% max-margin erosion;f3 默认 horizon 10s,最终机角散布 ≤ 2π rad;f4 对 IBR 母线筛查 SCR_min=3.0。
除通过/失败评估外,还提供二分搜索容量工具——在 [MW_min, MW_max] 做二分、中点做完整 CIA、容差 1 MW 终止。0–500 MW 范围实际需 8–9 次迭代。
图片来源于原论文
三、LLM 作为"决策中枢":反幻觉三层防御 + 持久记忆
论文的架构哲学与传统"确定性规则为主、LLM 兜底"相反:LLM 位于决策核心,确定性规则作为安全护栏。Agent 流程(Algorithm 1)先检查 forced capacity routing 护栏、再检查 CIA 类 prompt 的必需输入澄清、然后构建含 Lessons L、memory M 的系统 prompt,LLM 链式调用最多 5 轮工具(例如 run OPF → 检查违规 → 建议缓解)、每轮 reflection 后再决定下一步、最终验证未锚定数值声明并持久化到 memory。
11 工具注册表按 OpenAI 函数调用格式暴露,分四组:Assessment(run_cia、run_cia_with_mitigation)、Analysis(run_powerflow、run_opf、inspect_violations、run_contingency)、Capacity search(find_max_capacity,强制路由+monotonicity contradiction detection)、Topology ops(list_backends、list_cases、set_backend、query_network_data)。自然语言解析抽取四元组 (b, P, τ, ι)——母线号、有功 MW、资源类型、IBR 状态;参数缺失时索要澄清,不做默认 load 回退。

图片来源于原论文
反幻觉三层防御的动因是一个具体案例:问 IEEE 118-bus 某母线最大负载时,DeepSeek-R1 回复"大约 127 MW"——实际验证限值 3.9 MW,偏差 33 倍。三层分工:
- Layer 1(Soft / 所有查询):Prompt hardening——系统指令加"绝不陈述具体 MW/pu/MVA/百分比值"除非来自 tool call 或公认标准
- Layer 2(Hard / 容量查询,Bypass-proof):确定性 pre-LLM 分类器识别容量查询,触发后绕过 LLM 直接调二分搜索
- Layer 3(Detect / 无工具调用响应):正则扫描器检测 "X MW"、"X pu" 模式,150 字符窗口内匹配"安全短语"(NERC 标准值、p.u. 定义),未匹配则追加免责声明
持久记忆仿 OpenClaw,维护仅追加结构化系统、存储跨会话的 CIA 与容量结果,支持 bus-specific / case-wide / keyword / max-capacity 四种召回。**关键点:记忆注入时标注"这些条目来自当前会话,非独立历史数据"**——防止 LLM 把会话结果当作权威"历史研究"。
Prompt 级自纠正循环不是 RL:Scenario Generator 产生四类场景(歧义/部分/完整/追问)→ Evaluator 按 S = 0.5·S_action + 0.35·S_content + 0.15·S_format打分 → Optimizer 分析失败、生成简洁可执行 lessons 追加到持久存储,形式 s_{t+1} = s_0 ⊕ L_t。适合闭源 API 模型、无需参数更新。
四、实验结果:50 场景基准 + 跨模型 + 反幻觉消融
主基准 IEEE 118-bus(118 母线、186 支路、54 发电机),评估 5 个前沿 LLM(Claude 3.5 Sonnet / GPT-4o / DeepSeek-R1 / DeepSeek-V3 / Qwen 2.5-72B,OpenRouter 统一 API、T=0)。50 场景按 Complete load/gen、Missing bus/MW/type、Multi-turn、Follow-up、Edge cases、Theory 分类(Table V)。
主实验(Table VI,DeepSeek-V3,N=50):TSA 84.0%、PA 100.0%、平均延迟 15.89s、总成本 $0.102(约 $0.002/场景)。
按类别 TSA 分解(Table VII):Ambiguous (missing) 15 题 100%、Follow-up 100%、Theory 100%、Multi-turn 83.3%、Complete generation 75%、Complete load 62.5%、Edge cases 50%。错误集中在保守澄清策略下的完整请求规范化和边界 case。
跨模型 pilot(Table VIII,Complete-Load N=8):DeepSeek-V3 TSA 62.5%、延迟 17.24s、$0.0178;DeepSeek-R1 TSA 62.5%、延迟 78.05s、$0.0840;GPT-4o TSA 0%——表现出 "over-clarification" 行为,完整请求 prompt 上反复要额外确认、不调 CIA operator。论文明确声明这仅作 directional evidence。
自纠正回归(Table IX,56 场景,2026-02-23 Iteration 1):49/56(87.5%)、均分 89.29、24 条 lessons。压力切片:Non-adversarial 32 题 96.9%、Adversarial-like 24 题 100%、总体 56 题 98.2%。
反幻觉消融(Table XI):DeepSeek-V3/R1 在该 prompt set 上即使移除 Layer 2+3,routing recall 都 100%、fabrication rate 都 0%——定量证据但论文承认并未建立最坏情况鲁棒性保证。澄清门修复(Table XII):修复后 Missing bus/MW/type 三类 TSA 从 0%/40%/0% → 全部 100%。
五、总结与思考
论文自陈五项验证边界:瞬态/EMT 验收标准是筛查启发式、不替代公用事业正式协议;基准尚非盲第三方评测;尚未与 PSS/E 或 PSLF 在大型现实系统上做端到端正确性验证;N-1 +2.0% 阈值需按 ISO/RTO 市场校准;缓解动作仅限 shunt-like 反应补偿,未覆盖拓扑变更、相位移变压器或 RAS。
三条核心设计原则值得记录:
- LLM-first 不等于 LLM-only——用确定性 pre-LLM 分类器和 post-response 扫描器包夹住 LLM 两个最危险的倾向:工具绕过和数值虚构
- 所有数值必须来自求解器——具体数字来自 solver/inspector,LLM 只做定性解释
- Prompt-level lesson 替代模型微调——对闭源 API 模型用"失败分析→蒸馏 lesson→注入系统 prompt"替代 RLHF
在此基础上,有几点值得进一步思考:
- "LLM-first + 物理 grounding" 是跨行业通用范式:任何有确定性求解器的垂直领域——流体、半导体、药物分子、建筑结构——都可以复用这套"Agent 编排 + 验证层"架构
- DeepSeek-R1 偏差 33 倍是行业级警示:推理模型在查数据库类问题上仍会"虚构合理但错误的数值",这不是模型规模能解决的,强制路由硬护栏是必需
- GPT-4o TSA 0% 是意外但重要的发现:Agent 框架内模型排序可能与通用 benchmark 完全不同,落地选型必须在具体架构内 A/B 测试
- Prompt-level self-correction 的可持续性待验证:lesson 集膨胀到上下文饱和、lesson 相互冲突是长期部署必然遇到的问题
Grid-Mind 最大启示:垂直行业的 LLM Agent 要达到可用,不在"用多大的模型",而在"把多少确定性护栏嵌进架构"。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号