中国AI又赢了!成本砍到前代1/10!DeepSeek V4为什么能这么便宜?
原创
中国AI又赢了!成本砍到前代1/10!DeepSeek V4为什么能这么便宜?
原创
企业架构师老王
发布于 2026-04-27 19:00:06
发布于 2026-04-27 19:00:06
为什么只有DeepSeek,敢把百万上下文做成全系列标配,甚至把模型权重全量开源开放给所有人用?
别家做大模型长上下文,靠的是堆显存、堆算力,用硬件成本硬扛;而DeepSeek从V2到V4,一直靠的是“从根上改算法”。
这次V4更是在自研DSA稀疏注意力基础上,升级了CSA压缩稀疏注意力+HCA重度压缩注意力的混合架构,搭配KV缓存序列维度压缩(下文会解释这两个技术),直接把百万上下文的算力需求砍到了前代的1/10,成本打穿了行业地板。
今天这篇我们给所有人讲明白:DeepSeek到底靠什么,把曾经只有顶级闭源模型才配拥有的百万上下文,变成了人人用得起的“水电煤”。
一、先搞懂:百万上下文,到底贵在哪?
我们先把大模型类比成一个老板雇的专职文员,你的prompt就是老板的需求,上下文就是你给文员的参考资料,token就是资料里的“字/词”,显存就是文员的笔记本,算力成本就是文员干活花的时间和工钱。
按行业通用1token≈0.75个汉字的换算标准,1M token上下文,相当于你直接甩给文员一本75万字的《红楼梦》,让他读完之后,精准回答你关于这本书的任何细节问题——小到林黛玉进贾府戴了什么花,大到全书人物关系的底层逻辑。
传统稠密自注意力机制下,大模型处理长文本,用的是最笨、最费钱的办法:
- 逐字抄录,笔记本直接爆仓:文员必须把书里的每一个字,原封不动抄到自己的笔记本里,75万个字就要抄75万行。上下文越长,需要的笔记本越大,普通消费级显卡根本装不下,只能靠企业级天价显卡硬扛。
- 逢问必翻全书,干活慢到离谱:你每问一个问题,文员都要把整本75万字的笔记,从头到尾一字不落地翻一遍,生怕漏了和问题相关的内容。哪怕你问的问题只和第三回有关,他也要把120回全翻完。
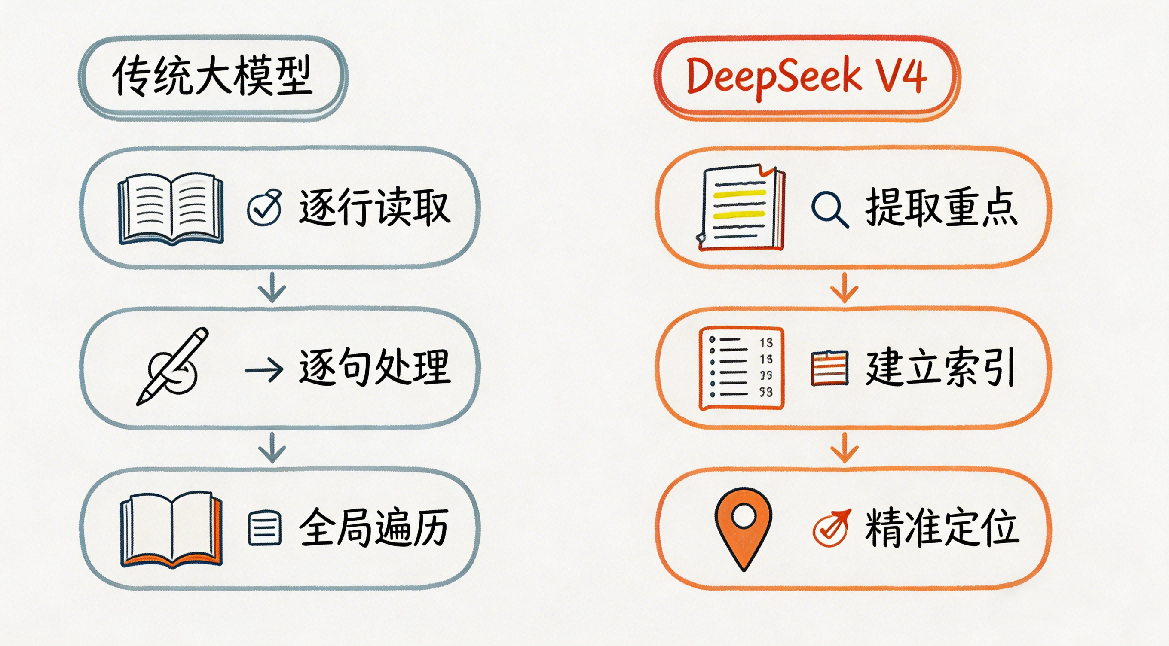
这就是传统注意力机制的致命痛点:上下文长度翻一倍,算力和显存需求直接翻4倍。
这也是为什么,百万上下文在过去一年,一直是闭源大厂的“付费高端特权”——普通人根本用不起,中小企业也扛不住这个成本。
而DeepSeek V4做的事,就是从根本上改掉了文员“记笔记、翻笔记”的笨办法,用两套创新逻辑,实现了既能精准答出所有细节,又只花1/10的笔记本和时间。
二、降维第一式:Token维度压缩,从“逐字抄书”到“一目十行抓重点”
先给大家补一个最基础的概念:Token是大模型处理信息的最小单位,你说的一句话、上传的一份文档,都会被大模型拆成一个个Token来处理,就像我们看书时的一个个字、一个个词。
传统稠密注意力机制的死穴:每个Token都要单独存、单独算。
75万个Token,就要存75份独立的笔记,做75次重复计算,没有任何取舍。就像你让文员读《红楼梦》,他连里面的“话说”“且说”“笑道”这种无意义的语气词,都要原封不动抄下来、算一遍,纯纯的无用功。
DeepSeek V4的Token维度压缩,就是让大模型学会了“一目十行抓重点”。
它不再逐字抄录,而是先把连续的Token做“信息浓缩”,把一段话、一个章节的核心信息,压缩成一个“重点笔记块”,没用的废话直接过滤,核心信息完整保留。
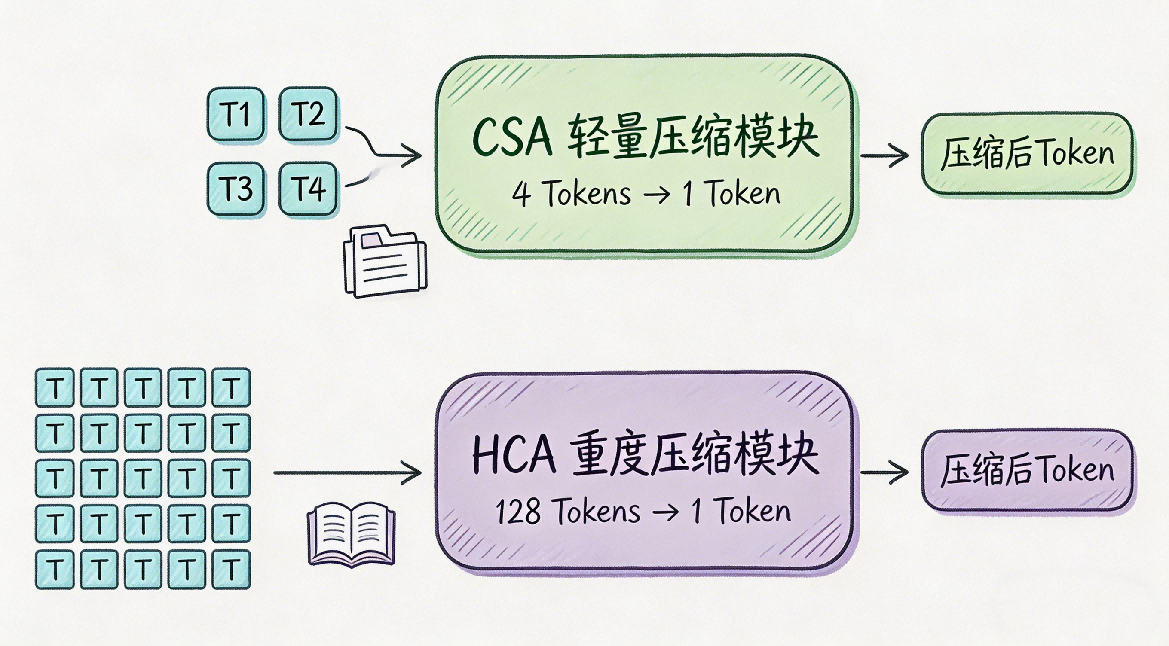
在V4的官方架构里,这套压缩逻辑分了两级,精准适配不同的信息密度,对应CSA压缩稀疏注意力和HCA重度压缩注意力,所有参数均来自官方技术报告实测:
- 轻量压缩(CSA,4个Token缩成1个):针对段落级的细节内容。 类比:文员看书时,把每4句话浓缩成1句核心笔记,既保留了所有细节,又把笔记量直接砍到了1/4。比如“黛玉方进入房时,只见两个人搀着一位鬓发如银的老母迎上来,黛玉便知是他外祖母。方欲拜见时,早被他外祖母一把搂入怀中,心肝儿肉叫着大哭起来。”4句话,直接浓缩成“黛玉进房见到外祖母,被其搂入怀中大哭”1句核心笔记,细节全在,篇幅大减。
CSA压缩稀疏注意力
- 重度压缩(HCA,128个Token缩成1个):针对全书级的框架内容。 类比:文员把每128句话,也就是一整个章节的内容,浓缩成1个超级核心笔记,记录这个章节的核心事件、人物关系、关键信息。比如《红楼梦》第三回全章,直接浓缩成“黛玉进贾府,见贾母、三春、王熙凤、宝玉,完成初入府的全流程”,把整个章节的核心框架牢牢抓住。
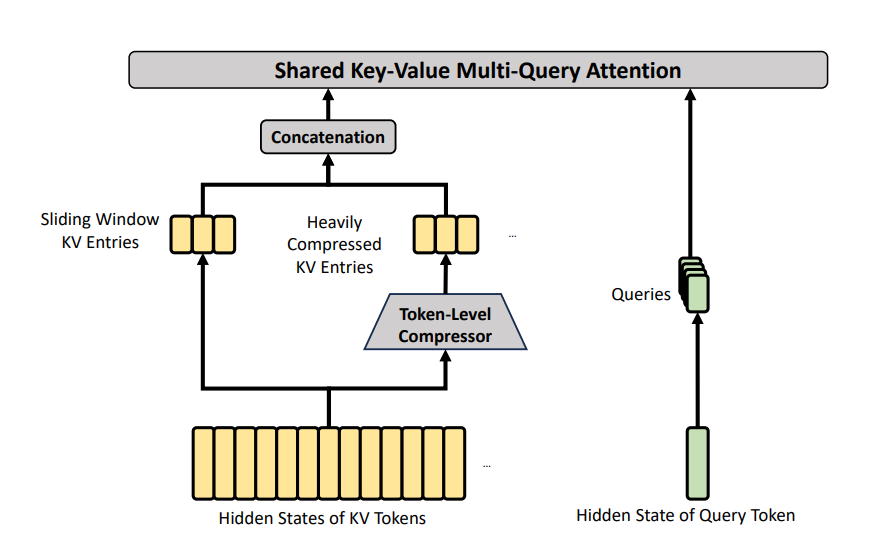
HCA重度压缩注意力
这两级压缩一结合,效果有多夸张?
官方技术报告实测数据显示:1M上下文场景下,DeepSeek V4-Flash的KV缓存(也就是文员的笔记本),只有前代V3.2的7%,Pro版也只有前代的10%。
原来装一本75万字的书,需要100G的显存,现在只需要7G,普通消费级显卡就能稳定运行,硬件成本直接砍到了零头。
最关键的是,这套压缩不是“丢信息的阉割”,而是“抓重点的提纯”。
它通过可训练的压缩权重和位置偏差,精准筛选核心信息,不会漏掉任何关键细节。
在1M上下文的权威评测MRCR里,V4-Pro的关键信息检索准确率达到83.5%,直接超越了谷歌Gemini 3.1 Pro——笔记记得少了,但重点抓得更准了。
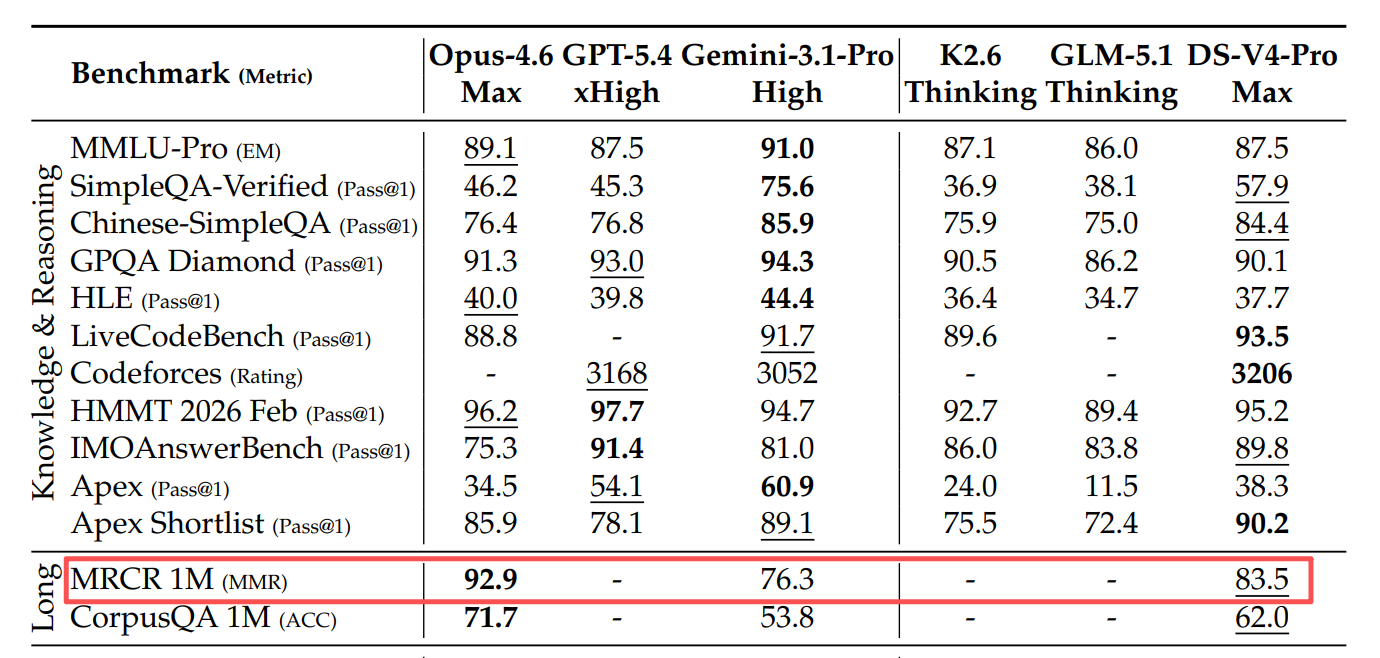
V4-Pro的关键信息检索准确率达到83.5%,直接超越了谷歌Gemini 3.1 Pro
三、降维第二式:DSA稀疏注意力,从“整本翻书”到“索引精准定位”
如果说Token压缩解决了“笔记本不够用”的问题,那DSA(DeepSeek Sparse Attention)稀疏注意力,就解决了“翻书太慢、工钱太贵”的核心痛点。
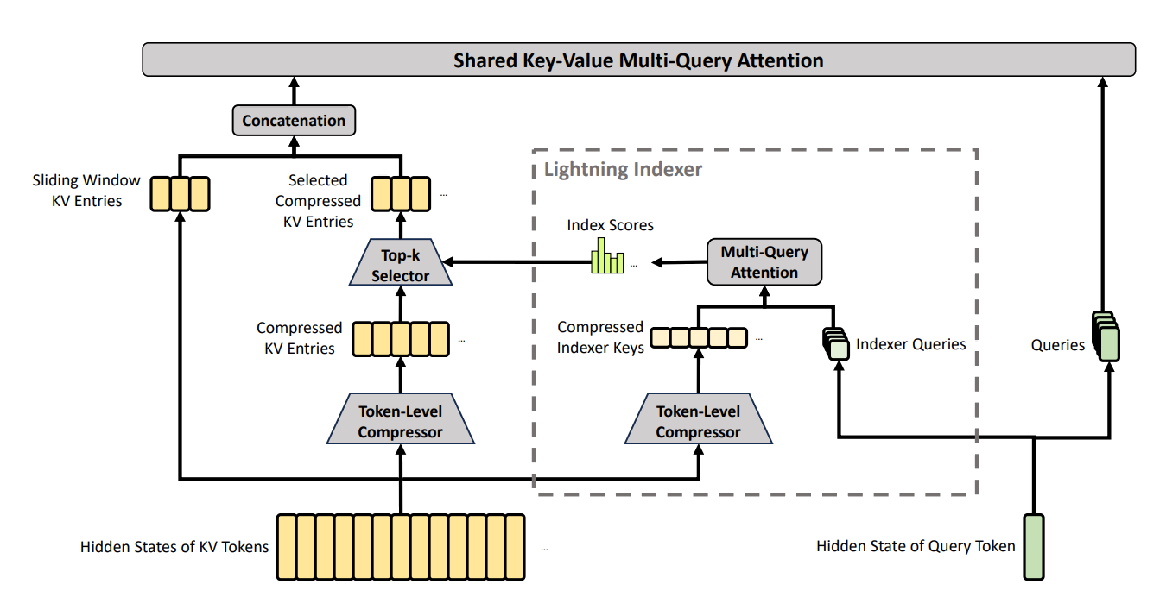
这里先说明:DSA是DeepSeek V3已落地的自研稀疏注意力架构,V4的核心升级,是在DSA基础上新增了前置KV压缩,形成了全新的CSA架构,通过「压缩+稀疏」的双重优化,把无效算力降到了极致。
我们还是回到文员的例子:你问“林黛玉进贾府穿了什么衣服?”,传统大模型的文员,必须把75万字的笔记从头到尾翻一遍,哪怕99%的内容和这个问题毫无关系,他也要挨个看一遍,生怕漏了。
这就是长上下文成本高的第二个核心原因:无效计算太多,99%的算力都花在了和问题无关的内容上。
而DeepSeek CSA架构里的Lightning Indexer闪电索引器,就是给文员的笔记,做了一套可精准检索的“闪电索引目录”,再通过DSA稀疏注意力实现精准筛选。
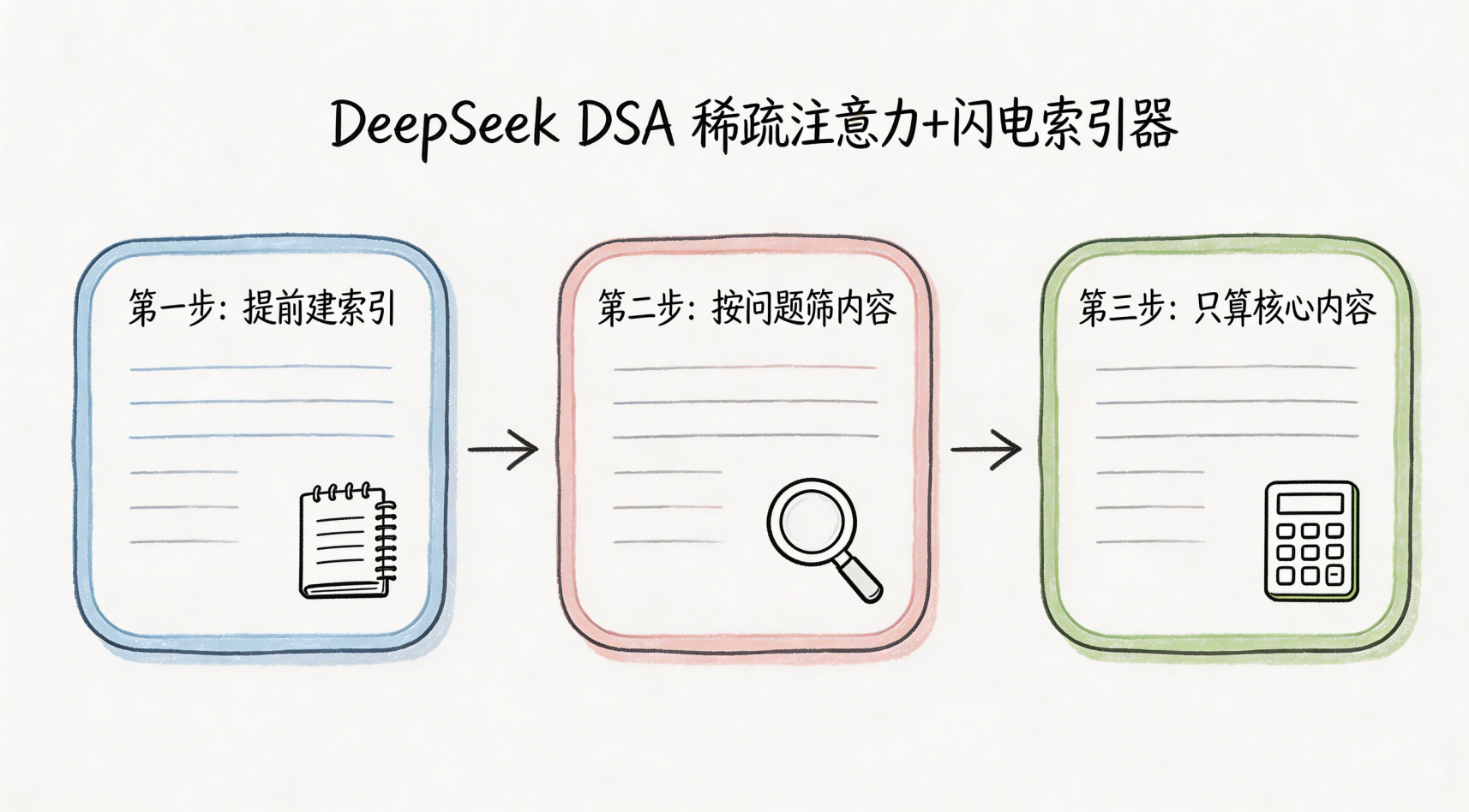
它的核心逻辑,用大白话讲就3步:
- 提前建索引:在Token压缩完成后,闪电索引器会给每一个压缩后的“重点笔记块”,都打上专属的关键词索引,做成一本完整的目录。比如“黛玉进贾府”这个压缩块,索引标签就是“林黛玉、贾府、第三回、初入府”;“王熙凤出场”这个压缩块,索引标签就是“王熙凤、第三回、出场、外貌描写”。
- 按问题筛内容:你提的问题,会先被拆解成关键词,然后通过索引目录,精准找到和问题最相关的“重点笔记块”,其他99%不相关的内容,直接跳过不看。比如问“黛玉进贾府的穿着”,直接锁定第三回的2个相关压缩块,其他119回的内容,完全不用看。
- 只算核心内容:最终,大模型通过DSA稀疏注意力,只对筛选出来的极少数核心笔记块,做完整的注意力计算,给出精准答案。
在V4的官方架构里,每个query token,Pro版会筛选出1024个核心压缩块,Flash版会筛选512个。原来要算100万个Token,现在只需要算几千个,算力消耗直接砍到了前代的零头。
官方技术报告的实测数据,直接印证了这套架构的恐怖效率:1M上下文场景下,V4-Pro单token推理的算力消耗,只有前代V3.2的27%,Flash版更是只有前代的10%。
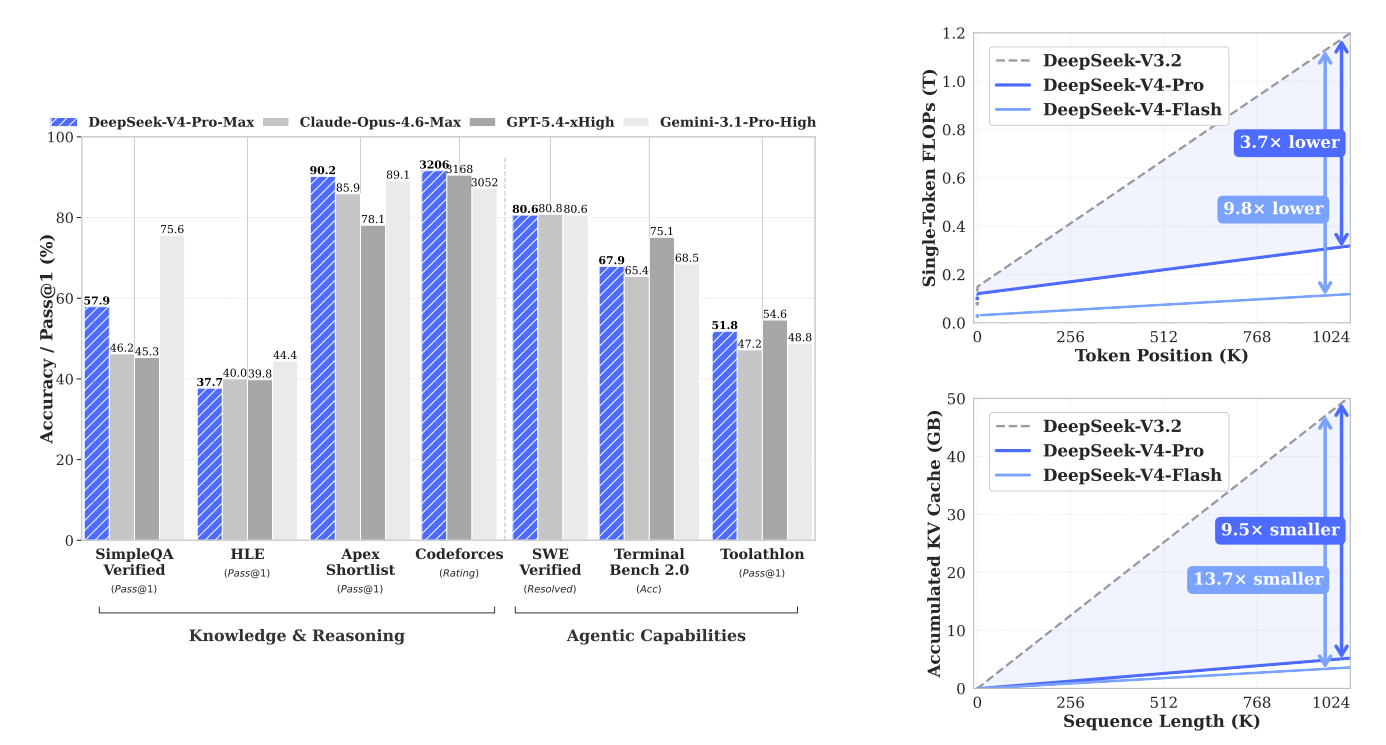
原来处理100万token要花100分钟,现在只需要10分钟,文员的工钱(算力成本),自然就跟着打了1折。
更绝的是,DeepSeek还加了一层“滑动窗口注意力”的双保险:就像文员会把最近看的几页内容,直接放在手边的桌面上,不用去翻笔记本。大模型会把文本最后128个Token的原始内容,完整保留在身边,保证最新的信息、最近的对话内容,绝对不会丢细节,响应速度更快。
四、V4-Flash到底把价格打下来了多少?
说了那么多“场面话”,我们算一笔最实在的账:DeepSeek V4,到底能帮你省多少钱?
先做两个基础说明,保证测算的严谨性:
- 行业通用换算标准为1个汉字≈1.3个token,法律文书等专业文本因标点、专业术语多,换算比例约1:1.3,为方便直观对比,下文按最简化的1:1比例测算,百万字对应百万token;
- 所有定价均采用各厂商官方公开的长上下文版本输入定价(长文本处理的核心开销),按实时汇率1美元=7.2人民币换算,V4-Flash成本按官方实测10倍算力效率提升同比测算。
我们以一家中型律所的真实场景为例:每天要处理100份合同、法务文书,单份平均5万字,单日处理量500万字,每月按22个工作日算,年处理量13.2亿字。各方案的成本对比如下:
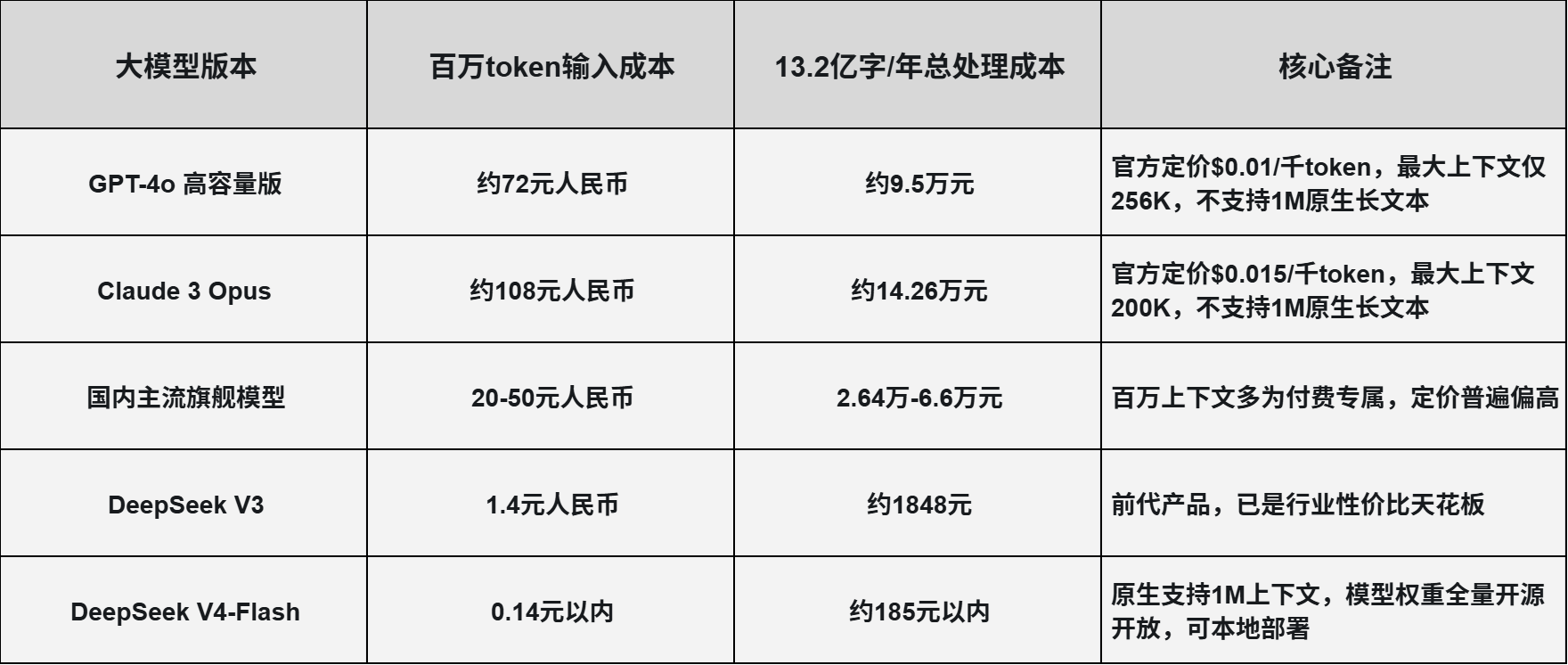
重点来了,V4-Flash是全量开源开放的,企业可以直接本地部署,不用再按token付费。按单张RTX 4090显卡(约1.2万元)测算,可稳定运行1M上下文推理,一次性硬件投入后,年处理量无额外token成本,对比闭源API年成本差距可达上千倍。
对于中小企业、开发者来说,这相当于直接把“长文本AI处理”的门槛,从几十万的服务器成本,降到了几千块的家用电脑就能跑,这才是真正的降维打击。
最后想说,DeepSeek是大模型行业的“价格屠夫”,但它从来不是靠亏本赚吆喝的内卷,而是靠底层架构的持续创新,从根源上降低了大模型的运行成本。
别家还在靠堆更大的油箱、更贵的发动机,来让车跑得更远;而DeepSeek已经发明了一套混动系统,油耗直接砍到1/10,还跑得比燃油车更快。
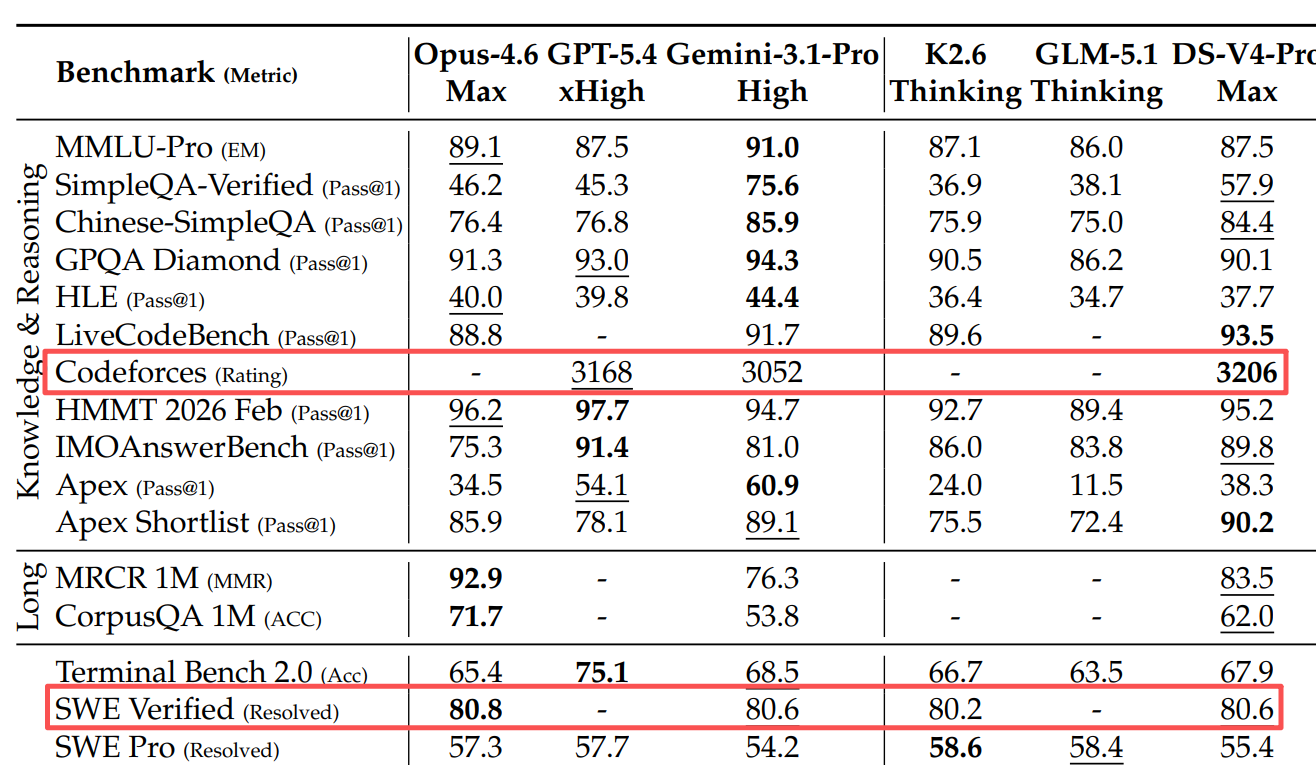
更难得的是,这套效率提升不是靠阉割精度换来的——官方实测Codeforces编程竞赛评分3206分,超越了GPT-5.4;SWE-Verified代码Agent解决率80.6%,与Claude Opus 4.6仅差0.2个百分点,真正做到了“又快、又准、又便宜”。
这才是中国AI最该走的路:不是靠参数堆砌的营销噱头,不是靠价格战的恶性内卷,而是靠实打实的底层技术创新,把顶级的AI能力,变成人人用得起、用得上的普惠工具。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号