DeepSeek-V4更新:百万 token 上下文、1.6T MoE、FP4+FP8 混合精度、Pro-Max 与 Flash-Max 全面解析

DeepSeek-V4更新:百万 token 上下文、1.6T MoE、FP4+FP8 混合精度、Pro-Max 与 Flash-Max 全面解析

福大大架构师每日一题
发布于 2026-04-28 19:36:14
发布于 2026-04-28 19:36:14

在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
2026年4月24日,DeepSeek-AI正式发布DeepSeek-V4系列预览版本,该系列包含两款强大的混合专家(Mixture-of-Experts, MoE)语言模型——DeepSeek-V4-Pro与DeepSeek-V4-Flash,同时配套推出DeepSeek-V4-Flash-Base、DeepSeek-V4-Pro-Base两个基础版本,全方位覆盖不同推理需求场景。作为开源大模型领域的重要更新,DeepSeek-V4系列在架构优化、推理效率、任务适配性上实现多重突破,支持百万token上下文长度,在代码、数学、推理、智能体等多类任务中表现亮眼,甚至在部分基准测试中逼近领先闭源模型,成为当前开源大模型领域的标杆之作。本文将对DeepSeek-V4全系列模型进行全面、详细的拆解,涵盖模型简介、架构升级、下载方式、评测结果、使用方法等核心内容,助力开发者快速掌握模型特性、高效上手部署。
一、DeepSeek-V4系列核心模型整体概述
DeepSeek-V4系列是DeepSeek-AI推出的新一代MoE架构语言模型,核心定位是“高效能、长上下文、多场景适配”,预览版本包含四款核心模型,分别为DeepSeek-V4-Flash、DeepSeek-V4-Flash-Base、DeepSeek-V4-Pro、DeepSeek-V4-Pro-Base,其中DeepSeek-V4-Flash与DeepSeek-V4-Pro为核心功能版本,Base版本则提供基础模型支持,满足不同开发者的轻量化或定制化需求。
两款核心功能模型(DeepSeek-V4-Flash与DeepSeek-V4-Pro)均采用混合专家(MoE)架构,支持百万token(1M)的上下文长度,这意味着模型能够处理超长文本输入,适配长文档分析、多轮对话、代码审计等复杂场景。二者的核心差异集中在参数量与性能定位上:DeepSeek-V4-Pro总参数量达1.6T,激活参数量49B,主打高性能、全场景覆盖;DeepSeek-V4-Flash总参数量284B,激活参数量13B,主打轻量化、高效推理,在控制资源占用的同时兼顾性能表现。
值得注意的是,DeepSeek-V4-Pro与DeepSeek-V4-Flash均支持三种推理强度模式,可根据实际任务需求灵活切换,同时推出Max推理模式(DeepSeek-V4-Pro-Max、DeepSeek-V4-Flash-Max),进一步挖掘模型推理潜力,其中DeepSeek-V4-Pro-Max稳居当前最佳开源模型之列,大幅缩小了与领先闭源模型的差距。
二、DeepSeek-V4系列核心架构与优化升级
DeepSeek-V4系列在架构设计与训练优化上引入多项关键创新,核心目标是提升长上下文处理效率、训练稳定性与模型表达能力,具体升级点如下:
2.1 混合注意力架构:大幅提升长上下文处理效率
为解决长上下文场景下推理效率低、资源占用高的痛点,DeepSeek-V4系列设计了混合注意力机制,创新性地结合压缩稀疏注意力(Compressed Sparse Attention, CSA)与重度压缩注意力(Heavily Compressed Attention, HCA),实现了长上下文处理效率的显著提升。
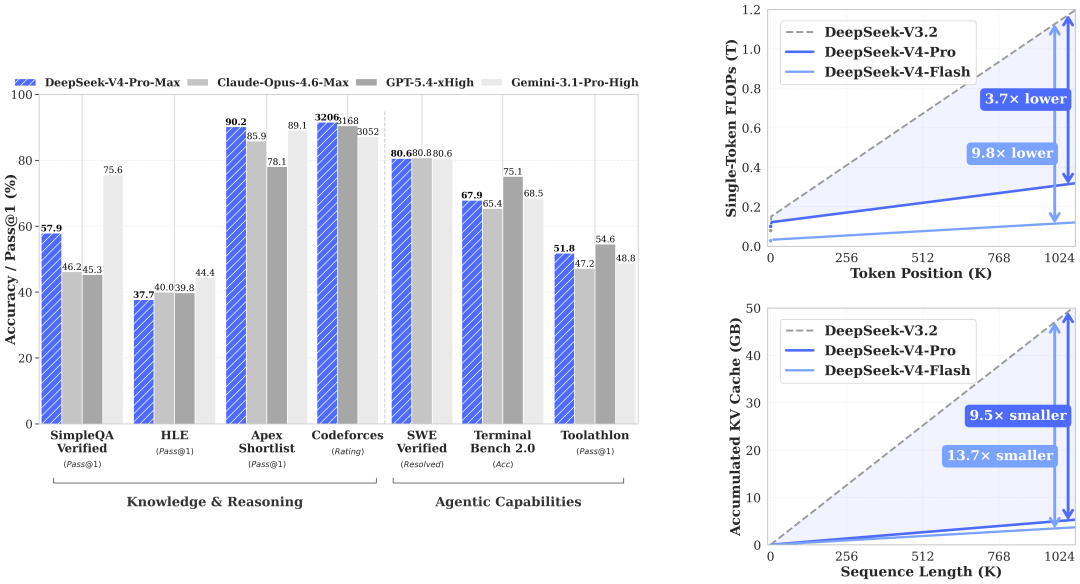
该架构的核心优势的在于“精准压缩、高效计算”:通过CSA与HCA的协同作用,在保留关键信息的前提下,对注意力权重进行合理压缩,减少冗余计算。官方测试数据显示,在百万token上下文场景下,DeepSeek-V4-Pro相比上一代模型DeepSeek-V3.2,仅需27%的单token推理FLOPs(浮点运算次数)和10%的KV缓存,极大降低了长上下文推理的资源消耗,让百万token级别的长文本处理变得更加高效、可行。
2.2 流形约束超连接(mHC):增强跨层信号传播稳定性
在传统残差连接的基础上,DeepSeek-V4系列引入了流形约束超连接(Manifold-Constrained Hyper-Connections, mHC),进一步优化模型的跨层信号传播机制。传统残差连接虽能缓解梯度消失问题,但在深层模型中仍存在信号衰减、传播不稳定的问题,影响模型的表达能力与训练效果。
mHC通过引入流形约束,对跨层信号传播进行规范与增强,在保留模型原有表达能力的同时,显著提升了跨层信号传播的稳定性,让深层模型的训练更加顺畅,有效避免了训练过程中出现的梯度爆炸、模型退化等问题,为模型性能的提升奠定了架构基础。
2.3 Muon优化器:实现更快收敛与更高训练稳定性
训练优化器是大模型训练的核心组件,直接影响模型的收敛速度、训练稳定性与最终性能。DeepSeek-V4系列采用全新的Muon优化器,相比传统优化器(如Adam、SGD),Muon优化器在收敛速度与训练稳定性上实现双重提升。
通过优化学习率调度、梯度更新策略,Muon优化器能够让模型在训练过程中更快收敛,减少训练迭代次数,同时有效抑制训练过程中的波动,提升训练稳定性,确保模型能够充分学习训练数据中的特征,进一步挖掘模型的性能潜力。
2.4 预训练与后训练:打造多领域专业能力
DeepSeek-V4系列的两款核心模型(DeepSeek-V4-Flash与DeepSeek-V4-Pro)均在超过32T高质量、多样化token上进行了预训练,涵盖文本、代码、数学、知识问答等多个领域,确保模型具备扎实的基础能力。
在预训练基础上,模型经过全面的后训练流程,采用两阶段范式,精准培养模型的领域专家能力:第一阶段,通过监督微调(SFT)和基于GRPO的强化学习(RL),独立培养模型在不同领域的专业能力,让模型在代码、数学、推理等特定领域形成核心优势;第二阶段,通过在线策略蒸馏(on-policy distillation)对模型进行统一整合,将多个领域的专业能力融合到单一模型中,实现“全领域覆盖、各领域精通”的效果,让模型能够适配多样化的任务需求。
2.5 Max推理模式:挖掘模型性能极限
DeepSeek-V4-Pro-Max是DeepSeek-V4-Pro的最大推理努力模式,经过针对性优化,显著提升了开源模型的知识能力,稳居当前最佳开源模型之列。该模式下,模型在代码基准测试中达到顶尖水平,在推理与智能体任务上大幅缩小了与领先闭源模型之间的差距,成为开源模型中少有的能够与闭源模型同台竞技的存在。
与此同时,DeepSeek-V4-Flash-Max作为DeepSeek-V4-Flash的Max推理模式,在拥有更大推理预算的情况下,可实现与Pro版本相当的推理性能,能够满足中高端推理需求;但由于其参数规模较小(总参数量284B,激活参数量13B),在纯知识类任务和最复杂的智能体工作流上,性能略逊于Pro版本,适合对资源占用有要求、推理难度适中的场景。
三、DeepSeek-V4全系列模型下载指南
DeepSeek-V4系列四款模型均支持通过HuggingFace与ModelScope两个平台下载,其中DeepSeek-V4-Flash-Base与DeepSeek-V4-Pro-Base还支持通过ModelScope SDK和Git命令下载,具体下载信息与操作步骤如下,开发者可根据自身需求选择合适的下载方式。
3.1 全系列模型下载信息汇总
以下是DeepSeek-V4系列四款模型的核心参数与下载地址汇总,清晰呈现各模型的差异与下载渠道,方便开发者快速查询:
模型名称 | 总参数量 | 激活参数量 | 上下文长度 | 精度 | 下载渠道 |
|---|---|---|---|---|---|
DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 混合 | HuggingFace | ModelScope |
DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 混合* | HuggingFace | ModelScope |
DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 混合 | HuggingFace | ModelScope |
DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 混合* | HuggingFace | ModelScope |
注:FP4 + FP8 混合精度说明:MoE专家参数使用FP4精度;其余大部分参数使用FP8精度,该精度设置在保证模型性能的前提下,进一步降低了模型的存储与推理资源占用。
3.2 DeepSeek-V4-Flash-Base下载方法
当前DeepSeek-V4-Flash-Base的贡献者未提供更详细的模型介绍,模型文件和权重可通过“模型文件”页面获取,也可通过以下两种方式直接下载:
3.2.1 ModelScope SDK下载
首先需要安装ModelScope SDK,然后通过代码调用实现模型下载,具体步骤如下:
# 安装ModelScope
pip install modelscope
# SDK模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-V4-Flash-Base')执行上述代码后,模型将自动下载到指定目录(默认目录可通过ModelScope配置调整),下载完成后即可用于本地部署与推理。
3.2.2 Git下载
通过Git命令直接克隆模型仓库,获取模型文件与权重,具体命令如下:
# Git模型下载
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-V4-Flash-Base.git克隆完成后,进入对应目录即可获取模型的全部文件与权重,适合需要手动配置模型参数的开发者。
3.3 DeepSeek-V4-Pro-Base下载方法
与DeepSeek-V4-Flash-Base类似,DeepSeek-V4-Pro-Base未提供详细模型介绍,模型文件和权重可通过以下两种方式下载:
3.3.1 ModelScope SDK下载
安装ModelScope SDK后,通过以下代码下载模型:
# 安装ModelScope(若已安装可跳过)
pip install modelscope
# SDK模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-V4-Pro-Base')3.3.2 Git下载
使用Git命令克隆模型仓库,具体命令如下:
# Git模型下载
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-V4-Pro-Base.git3.4 核心模型(DeepSeek-V4-Flash/Pro)下载说明
DeepSeek-V4-Flash与DeepSeek-V4-Pro可直接通过HuggingFace或ModelScope平台下载,访问对应平台的模型页面,按照平台提示操作即可完成下载。其中,ModelScope平台的模型地址分别为:
- DeepSeek-V4-Flash:可通过ModelScope搜索“deepseek-ai/DeepSeek-V4-Flash”获取下载链接;
- DeepSeek-V4-Pro:可通过ModelScope搜索“deepseek-ai/DeepSeek-V4-Pro”获取下载链接。
下载完成后,模型文件可直接用于本地推理、微调等任务,无需额外的权重转换(若有特殊需求,可参考后续“本地运行”部分的说明)。
四、DeepSeek-V4系列模型详细评测结果
为全面验证DeepSeek-V4系列模型的性能,官方进行了多维度的基准测试,涵盖基础模型评测、指令微调模型评测、与前沿模型对比、不同推理模式对比四个维度,测试数据全面、详实,能够清晰反映各模型的性能表现与优势场景。以下是完整的评测结果解析:
4.1 基础模型评测结果
基础模型评测主要针对DeepSeek-V3.2-Base、DeepSeek-V4-Flash-Base、DeepSeek-V4-Pro-Base三款模型,从架构、参数量、世界知识、语言与推理、代码与数学、长上下文六个维度进行测试,具体结果如下表所示:
基准测试(指标) | 样本数(Shots) | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|---|
架构 | - | MoE | MoE | MoE |
激活参数量 | - | 37B | 13B | 49B |
总参数量 | - | 671B | 284B | 1.6T |
世界知识 | ||||
AGIEval (EM) | 0-shot | 80.1 | 82.6 | 83.1 |
MMLU (EM) | 5-shot | 87.8 | 88.7 | 90.1 |
MMLU-Redux (EM) | 5-shot | 87.5 | 89.4 | 90.8 |
MMLU-Pro (EM) | 5-shot | 65.5 | 68.3 | 73.5 |
MMMLU (EM) | 5-shot | 87.9 | 88.8 | 90.3 |
C-Eval (EM) | 5-shot | 90.4 | 92.1 | 93.1 |
CMMLU (EM) | 5-shot | 88.9 | 90.4 | 90.8 |
MultiLoKo (EM) | 5-shot | 38.7 | 42.2 | 51.1 |
Simple-QA verified (EM) | 25-shot | 28.3 | 30.1 | 55.2 |
SuperGPQA (EM) | 5-shot | 45.0 | 46.5 | 53.9 |
FACTS Parametric (EM) | 25-shot | 27.1 | 33.9 | 62.6 |
TriviaQA (EM) | 5-shot | 83.3 | 82.8 | 85.6 |
语言与推理 | ||||
BBH (EM) | 3-shot | 87.6 | 86.9 | 87.5 |
DROP (F1) | 1-shot | 88.2 | 88.6 | 88.7 |
HellaSwag (EM) | 0-shot | 86.4 | 85.7 | 88.0 |
WinoGrande (EM) | 0-shot | 78.9 | 79.5 | 81.5 |
CLUEWSC (EM) | 5-shot | 83.5 | 82.2 | 85.2 |
代码与数学 | ||||
BigCodeBench (Pass@1) | 3-shot | 63.9 | 56.8 | 59.2 |
HumanEval (Pass@1) | 0-shot | 62.8 | 69.5 | 76.8 |
GSM8K (EM) | 8-shot | 91.1 | 90.8 | 92.6 |
MATH (EM) | 4-shot | 60.5 | 57.4 | 64.5 |
MGSM (EM) | 8-shot | 81.3 | 85.7 | 84.4 |
CMath (EM) | 3-shot | 92.6 | 93.6 | 90.9 |
长上下文 | ||||
LongBench-V2 (EM) | 1-shot | 40.2 | 44.7 | 51.5 |
从基础模型评测结果可以看出:
1. 参数量优势:DeepSeek-V4-Pro-Base总参数量(1.6T)和激活参数量(49B)远超另外两款模型,为其性能优势奠定了基础;DeepSeek-V4-Flash-Base虽然激活参数量(13B)最小,但整体性能优于上一代模型DeepSeek-V3.2-Base,体现了架构优化的价值。
2. 世界知识表现:三款模型中,DeepSeek-V4-Pro-Base在所有世界知识类基准测试中均表现最佳,尤其是Simple-QA verified(55.2)、FACTS Parametric(62.6)等指标,大幅领先于另外两款模型;DeepSeek-V4-Flash-Base在C-Eval(92.1)、CMMLU(90.4)等中文知识测试中表现突出,适合中文场景应用。
3. 语言与推理表现:三款模型整体表现接近,DeepSeek-V4-Pro-Base在HellaSwag(88.0)、WinoGrande(81.5)等推理类指标中略胜一筹,DeepSeek-V4-Flash-Base在DROP(88.6)指标中表现最佳,体现了轻量化模型的推理优势。
4. 代码与数学表现:DeepSeek-V4-Pro-Base在HumanEval(76.8)、MATH(64.5)等核心指标中表现最佳,适合复杂代码与数学任务;DeepSeek-V4-Flash-Base在CMath(93.6)指标中表现突出,在基础数学任务中具备优势;DeepSeek-V3.2-Base在BigCodeBench(63.9)指标中领先,但其整体代码能力不及DeepSeek-V4系列模型。
5. 长上下文表现:DeepSeek-V4-Pro-Base(51.5)> DeepSeek-V4-Flash-Base(44.7)> DeepSeek-V3.2-Base(40.2),充分体现了DeepSeek-V4系列在长上下文处理上的优化效果,尤其是Pro版本,能够更好地适配超长文本场景。
4.2 指令微调模型:三种推理模式详解
DeepSeek-V4-Pro和DeepSeek-V4-Flash均支持三种推理强度模式,不同模式针对不同的任务场景设计,具备不同的特点与回复格式,开发者可根据任务需求灵活选择,具体如下表所示:
推理模式 | 特点 | 典型应用场景 | 回复格式 |
|---|---|---|---|
Non-think | 快速、直观的响应 | 日常例行任务、低风险决策 | 总结 |
Think High | 有意识的逻辑分析,速度较慢但更准确 | 复杂问题求解、规划 | <think> 思考过程 总结 |
Think Max | 将推理能力发挥到极致 | 探索模型推理能力的边界 | 特殊系统提示 + <think> 思考过程 总结 |
三种推理模式的核心差异在于“推理深度”与“响应速度”的平衡:Non-think模式追求高效,适合简单、高频的日常任务;Think High模式兼顾速度与准确性,适合中等复杂度的推理与规划任务;Think Max模式追求极致准确性,适合复杂、高风险的任务,能够充分挖掘模型的推理潜力。
4.3 DeepSeek-V4-Pro-Max与前沿模型对比
为验证DeepSeek-V4-Pro-Max的性能水平,官方将其与当前主流前沿模型(Opus-4.6 Max、GPT-5.4 xHigh、Gemini-3.1-Pro High等)进行对比测试,涵盖知识与推理、长上下文、智能体能力三个维度,具体结果如下表所示:
基准测试(指标) | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | K2.6 Thinking | GLM-5.1 Thinking | DS-V4-Pro Max |
|---|---|---|---|---|---|---|
知识与推理 | ||||||
MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.1 | 86.0 | 87.5 |
SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 36.9 | 38.1 | 57.9 |
Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 75.9 | 75.0 | 84.4 |
GPQA Diamond (Pass@1) | 91.3 | 93.0 | 94.3 | 90.5 | 86.2 | 90.1 |
HLE (Pass@1) | 40.0 | 39.8 | 44.4 | 36.4 | 34.7 | 37.7 |
LiveCodeBench (Pass@1) | 88.8 | - | 91.7 | 89.6 | - | 93.5 |
Codeforces (Rating) | - | 3168 | 3052 | - | - | 3206 |
HMMT 2026 Feb (Pass@1) | 96.2 | 97.7 | 94.7 | 92.7 | 89.4 | 95.2 |
IMOAnswerBench (Pass@1) | 75.3 | 91.4 | 81.0 | 86.0 | 83.8 | 89.8 |
Apex (Pass@1) | 34.5 | 54.1 | 60.9 | 24.0 | 11.5 | 38.3 |
Apex Shortlist (Pass@1) | 85.9 | 78.1 | 89.1 | 75.5 | 72.4 | 90.2 |
长上下文 | ||||||
MRCR 1M (MMR) | 92.9 | - | 76.3 | - | - | 83.5 |
CorpusQA 1M (ACC) | 71.7 | - | 53.8 | - | - | 62.0 |
智能体能力 | ||||||
Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 66.7 | 63.5 | 67.9 |
SWE Verified (Resolved) | 80.8 | - | 80.6 | 80.2 | - | 80.6 |
SWE Pro (Resolved) | 57.3 | 57.7 | 54.2 | 58.6 | 58.4 | 55.4 |
SWE Multilingual (Resolved) | 77.5 | - | - | 76.7 | 73.3 | 76.2 |
BrowseComp (Pass@1) | 83.7 | 82.7 | 85.9 | 83.2 | 79.3 | 83.4 |
HLE w/ tools (Pass@1) | 53.1 | 52.0 | 51.6 | 54.0 | 50.4 | 48.2 |
GDPval-AA (Elo) | 1619 | 1674 | 1314 | 1482 | 1535 | 1554 |
MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 66.6 | 71.8 | 73.6 |
Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 50.0 | 40.7 | 51.8 |
从对比结果可以看出,DeepSeek-V4-Pro-Max在多个维度表现亮眼,核心优势如下:
1. 知识与推理:在Chinese-SimpleQA(84.4)、LiveCodeBench(93.5)、Codeforces(3206)、Apex Shortlist(90.2)等指标中表现突出,其中LiveCodeBench和Codeforces指标超越多数前沿模型,体现了其在中文知识和代码领域的核心优势;在GPQA Diamond(90.1)、HMMT 2026 Feb(95.2)等指标中接近顶尖水平,知识储备与推理能力强劲。
2. 长上下文:在MRCR 1M(83.5)、CorpusQA 1M(62.0)指标中表现优异,虽然不及Opus-4.6 Max,但远超Gemini-3.1-Pro High,充分体现了其百万token上下文的处理能力,适合长文档分析等场景。
3. 智能体能力:在SWE Verified(80.6)、BrowseComp(83.4)、MCPAtlas Public(73.6)等指标中表现出色,与领先模型差距较小,能够较好地适配智能体相关任务,具备较强的工具调用与任务执行能力。
整体而言,DeepSeek-V4-Pro-Max作为开源模型,在多个核心指标上逼近甚至超越部分闭源模型,大幅缩小了开源与闭源模型之间的差距,成为当前开源大模型的佼佼者。
4.4 不同推理模式下的性能对比
为清晰呈现不同推理模式对模型性能的影响,官方测试了DeepSeek-V4-Flash与DeepSeek-V4-Pro在三种推理模式下的表现,涵盖知识与推理、长上下文、智能体能力三个维度,具体结果如下表所示:
基准测试(指标) | V4-Flash Non-Think | V4-Flash High | V4-Flash Max | V4-Pro Non-Think | V4-Pro High | V4-Pro Max |
|---|---|---|---|---|---|---|
知识与推理 | ||||||
MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 | 82.9 | 87.1 | 87.5 |
SimpleQA-Verified (Pass@1) | 23.1 | 28.9 | 34.1 | 45.0 |
模型地址:modelscope.cn/collections/deepseek-ai/DeepSeek-V4
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号