Dingo:面向 AI 数据、模型与应用的全栈质量评估工具
原创
Dingo:面向 AI 数据、模型与应用的全栈质量评估工具
原创
用户12272845
发布于 2026-04-29 10:23:47
发布于 2026-04-29 10:23:47
在大模型快速进入生产环境的今天,“数据为王”已经不再只是训练阶段的口号,而是贯穿 AI 系统全生命周期的工程准则。
从预训练语料、指令微调数据,到 RAG 检索增强生成系统、智能体应用、线上模型回答质量,任何一个环节的数据或输出质量出现问题,都可能带来性能下降、幻觉增强、安全风险甚至业务事故。
Dingo 正是为了解决这些问题而生。
Dingo 是一个 面向 AI 数据、模型与应用的综合质量评估工具。它帮助机器学习工程师、数据工程师、AI 研究者系统化地评估和改进训练数据、微调数据集以及生产级 AI 系统的质量。
项目地址:https://github.com/MigoXLab/dingo
为什么 AI 时代更需要质量评估?
在传统机器学习时代,数据质量问题已经足够棘手;到了大模型时代,这些问题被进一步放大。
我们在实际项目中经常看到以下情况:
- 预训练语料中混入大量乱码、模板噪声、网页残片和重复内容;
- SFT 数据中存在指令和回答不匹配、回答敷衍、事实错误等问题;
- RAG 系统看似能回答问题,但回答并不忠于检索到的上下文;
- 生产模型输出中夹杂幻觉、敏感信息泄露或不安全内容;
- 多模态数据中图片与文本描述不一致,影响视觉语言模型训练;
- 数据来自本地文件、数据库、S3、Hugging Face 等不同来源,清洗和评估流程难以统一。
这些问题带来的影响不仅是“数据不干净”这么简单。它们会直接影响模型训练效率、推理可靠性、安全合规和最终用户体验。
尤其是在训练和部署成本都很高的大模型时代,等到模型训练完成、系统上线之后再发现质量问题,往往已经付出了巨大的计算成本和时间成本。因此,AI 项目需要一种更系统、更自动化、更可扩展的质量评估能力。
这正是 Dingo 想要解决的问题。
Dingo 是什么?
Dingo 是一个面向 AI 场景的数据、模型与应用质量评估工具,覆盖从数据接入、规则检测、LLM 评估、Agent 评估,到报告生成、分布式执行和可视化平台的一整套流程。
它的目标可以概括为一句话:
用统一、可扩展、生产可用的方式,帮助团队发现 AI 数据和 AI 系统中的质量问题。
新版 Dingo 的能力已经覆盖多个层面:
- 训练数据质量评估:预训练语料、文本数据、结构化数据、多字段数据;
- SFT 数据评估:指令问答质量、3H 维度评估,即 Honest、Helpful、Harmless;
- RAG 系统评估:Faithfulness、Answer Relevancy、Context Precision、Context Recall、Context Relevancy 等指标;
- 幻觉检测与事实核查:支持 HHEM、Fact Check、Agent-based 事实验证;
- 多模态评估:支持图文相关性、VLM 质量评估、OCR 可视化评估;
- 安全与合规检测:PII 检测、毒性内容检测等;
- 生产系统集成:CLI、Python SDK、Spark、MCP Server、SaaS 平台。
Dingo 的核心能力
1. 多源数据接入:从文件到数据库再到云端
真实生产环境中的数据不会只存在一种地方。它可能来自本地文件,也可能来自数据库、对象存储、Hugging Face 数据集,甚至是复杂 SQL 查询结果。
Dingo 支持多种数据源:
| 数据源 | 支持能力 |
|---|---|
| 本地文件 | JSONL、CSV、TXT、Parquet |
| SQL 数据库 | PostgreSQL、MySQL、SQLite、Oracle、SQL Server |
| 云存储 | S3 及 S3 兼容存储 |
| ML 平台 | Hugging Face 数据集直接接入 |
其中,SQL 数据源尤其适合企业生产环境。Dingo 支持通过 SQLAlchemy 进行流式读取,避免一次性加载大规模数据导致内存溢出,也支持复杂 SQL 查询、连接池和资源自动清理。
这意味着你不必先把数据库里的数据导出成中间文件,再写脚本进行评估。Dingo 可以直接接入现有数据系统,成为数据治理和模型工程流水线中的一环。
2. 规则 + LLM + Agent 的混合评估体系
Dingo 的评估体系不是单一路径,而是采用了混合式设计:
- Rule-based 规则评估:速度快、成本低、确定性强;
- LLM-based 大模型评估:适合理解语义质量、复杂内容质量;
- Agent-based 智能体评估:适合事实核查、外部检索、多步推理。
规则评估:快速覆盖常见问题
Dingo 内置 30+ 规则检测能力,可以用于文本质量、格式异常、PII、重复、异常字符等问题的快速筛查。规则评估成本低,非常适合在大规模数据上做全量扫描。
例如:
- 文本是否存在异常字符;
- 内容是否不完整;
- 是否包含特殊格式错误;
- 是否存在隐私信息;
- 字段格式是否符合要求。
LLM 评估:理解语义层面的质量
对于问答是否匹配、回答是否有帮助、文本是否自然、是否符合特定任务要求等问题,单纯规则往往不够。Dingo 支持基于 OpenAI 兼容接口的大模型评估能力,既也可以联网调用API,也可以接入本地部署的模型。
对于多模态场景,Dingo 还支持 InternVL、Gemini 等视觉语言模型能力,用于图文相关性、视觉内容质量、OCR 渲染判断等评估任务。
Agent 评估:面向复杂推理和事实核查
Dingo 引入了 Agent-based 评估能力。Agent 可以调用外部工具进行多步推理和动态上下文获取。例如:
- 使用 Tavily 进行 Web Search;
- 对回答中的事实声明进行检索验证;
- 结合外部资料判断文章或回答是否存在事实错误;
- 对幻觉风险进行自适应检测。
Dingo 内置的 Agent 能力包括:
AgentFactCheck:基于 LangChain 的事实核查 Agent;AgentHallucination:面向幻觉检测的自定义工作流 Agent;ArticleFactChecker:面向长文章的两阶段事实核查,先抽取可验证声明,再结合 Web Search 和 Arxiv 并发验证。
这使得 Dingo 不仅能检查“文本像不像脏数据”,还可以进一步判断“内容是否真实可信”。
3. 面向 RAG 系统的专业评估指标
RAG 已经成为大模型应用落地的重要架构,但 RAG 系统的质量评估一直很复杂。
一个 RAG 系统可能出现多种问题:
- 检索到的上下文和问题不相关;
- 检索内容包含答案但模型没有正确利用;
- 回答看似合理,但并不忠于上下文;
- 回答与用户问题不匹配;
- 检索结果排序不理想。
Dingo 针对 RAG 场景提供了 5 个有研究支撑的核心指标:
| 指标 | 评估重点 |
|---|---|
| Faithfulness | 回答是否忠于检索上下文,用于检测幻觉 |
| Answer Relevancy | 回答是否真正回应用户问题 |
| Context Precision | 检索上下文的精确率 |
| Context Recall | 检索上下文是否覆盖必要信息 |
| Context Relevancy | 检索上下文与问题是否相关 |
这些指标参考了 RAGAS、DeepEval、TruLens 等方向的研究和实践,非常适合用于 RAG 系统上线前评估、版本对比、回归测试和持续监控。
4. 多字段评估流水线:适合真实业务数据
很多质量评估工具默认“每条数据只有一个文本字段”,但真实业务数据往往是结构化的。
例如一条商品数据可能包含:
titledescriptionisbncategoryimageseller_info
不同字段需要不同评估逻辑。isbn 需要格式校验,title 需要异常字符检测,description 可能需要文本质量评估,image 则需要图文一致性评估。
Dingo 支持多字段评估流水线,可以在一次任务中对不同字段应用不同规则:
"evaluator": [
{"fields": {"content": "isbn"}, "evals": [{"name": "RuleIsbn"}]},
{"fields": {"content": "title"}, "evals": [{"name": "RuleAbnormalChar"}]},
{"fields": {"content": "description"}, "evals": [{"name": "LLMTextQualityV5"}]}
]这对于数据库表、业务日志、标注数据、内容平台数据尤其重要。你不需要为每个字段写单独脚本,Dingo 可以在统一配置中完成多字段评估。
5. 生产级执行能力:本地快速验证,Spark 分布式扩展
Dingo 提供两种主要执行模式:
| 模式 | 适用场景 |
|---|---|
| Local Executor | 本地开发、快速调试、小中规模数据 |
| Spark Executor | 生产流水线、分布式处理、百万级以上数据 |
本地执行适合数据科学家和算法工程师快速试验,Spark 执行则适合在大规模数据生产环境中运行。
同时,Dingo 支持并发、批处理、结果保存等配置,可以灵活嵌入已有的 ETL、训练和评估流程中。
100+ 质量指标:覆盖从预训练到生产应用
新版 Dingo 提供了 100+ 评估指标,覆盖多个 AI 质量场景。
| 类别 | 示例 | 适用场景 |
|---|---|---|
| 预训练文本质量 | 完整性、有效性、相似性、安全性 | LLM 预训练语料过滤 |
| SFT 数据质量 | Honest、Helpful、Harmless | 指令微调数据评估 |
| RAG 评估 | Faithfulness、Context Precision、Answer Relevancy | RAG 系统评估 |
| 幻觉检测 | HHEM-2.1-Open、Factuality Check | 生产 AI 可靠性评估 |
| 分类评估 | 主题分类、内容标签 | 数据组织与自动标注 |
| 多模态评估 | 图文相关性、VLM 质量、OCR 可视化评估 | 视觉语言模型数据 |
| 安全评估 | PII 检测、毒性内容检测 | 隐私与安全合规 |
相比早期版本,Dingo 的评估范围已经明显扩大:它不再只是检查训练语料中的脏数据,而是逐渐覆盖整个 AI 应用质量评估链路。
快速上手 Dingo
Dingo 的安装非常简单。
# 核心包:包含规则评估、LLM 评估、MCP Server 和数据源支持
pip install dingo-python
# 如果需要 HHEM 幻觉检测模型
pip install "dingo-python[hhem]"
# 如果需要完整能力,包括 HHEM 和 Agent
pip install "dingo-python[all]"下面是一个使用 Dingo 评估 Hugging Face 数据集的例子:
from dingo.config import InputArgs
from dingo.exec import Executor
if __name__ == '__main__':
input_data = {
"input_path": "tatsu-lab/alpaca",
"dataset": {
"source": "hugging_face",
"format": "plaintext"
},
"executor": {
"result_save": {
"bad": True
}
},
"evaluator": [
{
"evals": [
{"name": "RuleColonEnd"},
{"name": "RuleSpecialCharacter"}
]
}
]
}
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
print(result)如果你更习惯命令行,也可以直接使用 CLI:
# 使用规则集评估
dingo eval --input .github/env/local_plaintext.json
# 使用 LLM 评估
dingo eval --input .github/env/local_json.json在 AI IDE 中使用:Dingo MCP Server
Dingo 还内置了 MCP Server,可以和 Cursor、Claude Desktop 等支持 MCP 的工具集成。
这意味着你可以在 AI 编程环境中直接调用 Dingo 的评估能力,让智能体帮你运行数据质量检查、查看规则细节、快速评估数据样本。
启动方式如下:
# 启动 MCP Server,默认 SSE transport,端口 8000
dingo serve
# 指定端口
dingo serve --port 9000
# 使用 stdio transport,适合 Claude Desktop 等本地集成
dingo serve --transport stdio对于希望把数据质量检查嵌入 AI Agent 工作流的团队来说,MCP Server 是一个非常有价值的新能力。它让 Dingo 不只是一个命令行工具,而可以成为 Agent 可调用的质量评估组件。
评估报告:不只告诉你好坏,还告诉你问题在哪里
Dingo 执行完成后,会生成结构化评估报告,包括:
- 总体质量分数;
- 好样本数量与坏样本数量;
- 每类问题的占比;
- 字段级别质量分布;
- 具体规则或模型评估细节;
- 可保存的 bad/good 数据列表。
报告中常见字段包括:
score:质量得分,通常等于num_good / total;num_good:高质量样本数量;num_bad:存在问题的样本数量;total:总样本数量;type_ratio:不同质量问题类型的占比。
这使得团队不仅能知道“数据质量不好”,还可以定位到底是哪些字段、哪些规则、哪些问题类型导致了质量下降。
对于 RAG、LLM 和 Agent 评估任务,Dingo 还支持均值、最大值、最小值、标准差等统计聚合,便于做版本对比和持续监控。
扩展能力:把 Dingo 变成你的领域质量评估系统
不同领域对“好数据”的定义并不完全相同。
医疗数据、金融文本、电商商品、法律文书、代码数据、学术论文,各自都有独特的质量标准。Dingo 通过注册机制提供了很强的可扩展性,你可以自定义规则、自定义 LLM Prompt,也可以自定义 Agent 和工具。
自定义规则
from dingo.model import Model
from dingo.model.rule.base import BaseRule
from dingo.io import Data
from dingo.io.output.eval_detail import EvalDetail
@Model.rule_register('QUALITY_BAD_CUSTOM', ['default'])
class DomainSpecificRule(BaseRule):
"""Check domain-specific patterns"""
@classmethod
def eval(cls, input_data: Data) -> EvalDetail:
text = input_data.content
is_valid = your_validation_logic(text)
return EvalDetail(
metric=cls.__name__,
status=not is_valid,
label=['QUALITY_GOOD' if is_valid else 'QUALITY_BAD_CUSTOM'],
reason=["Validation details..."]
)自定义 LLM 评估器
from dingo.model import Model
from dingo.model.llm.base_openai import BaseOpenAI
@Model.llm_register('custom_evaluator')
class CustomEvaluator(BaseOpenAI):
"""Custom LLM evaluator with specialized prompts"""
_metric_info = {
"metric_name": "CustomEvaluator",
"metric_type": "LLM-Based Quality",
"category": "Custom Category"
}
prompt = """Your custom prompt here..."""这种插件式架构意味着:你不需要 fork 整个项目,就可以让 Dingo 适配自己的业务质量标准。
Dingo SaaS:面向企业的数据质量评估平台
除了开源版本,Dingo 还提供企业级 SaaS 版本,用于更完整的数据质量管理和团队协作场景。
相比开源版本,Dingo SaaS 提供:
- Web UI:无需写代码即可进行可视化评估;
- 访问控制:支持 JWT 与 Google OAuth 2.0;
- 可视化报告:交互式图表、趋势分析、报告导出;
- RESTful API:便于集成到企业内部系统。
对于企业数据治理、团队协作、批量任务管理和可视化分析来说,SaaS 版本会比单纯命令行工具更适合。
功能演示
Dingo SaaS 平台提供 Quick Try 和 Full pipeline 两种评测模式,满足不同场景下的需求:
Dingo首页
Quick Try 模式 - 快速验证
- 适用场景:单条数据质量快速检查、规则调试、Prompt工程验证
- 操作流程:
- 在平台首页选择 "Quick Try"
- 选择评估指标(如 LLMTextQualityV5, RuleSpecialCharacter 等)
- 输入待评测图片/ 文本等(支持纯文本 / JSON 等格式)
- 即时获取评分和详细诊断报告
- 优势:秒级响应,无需创建实验,适合开发阶段快速迭代
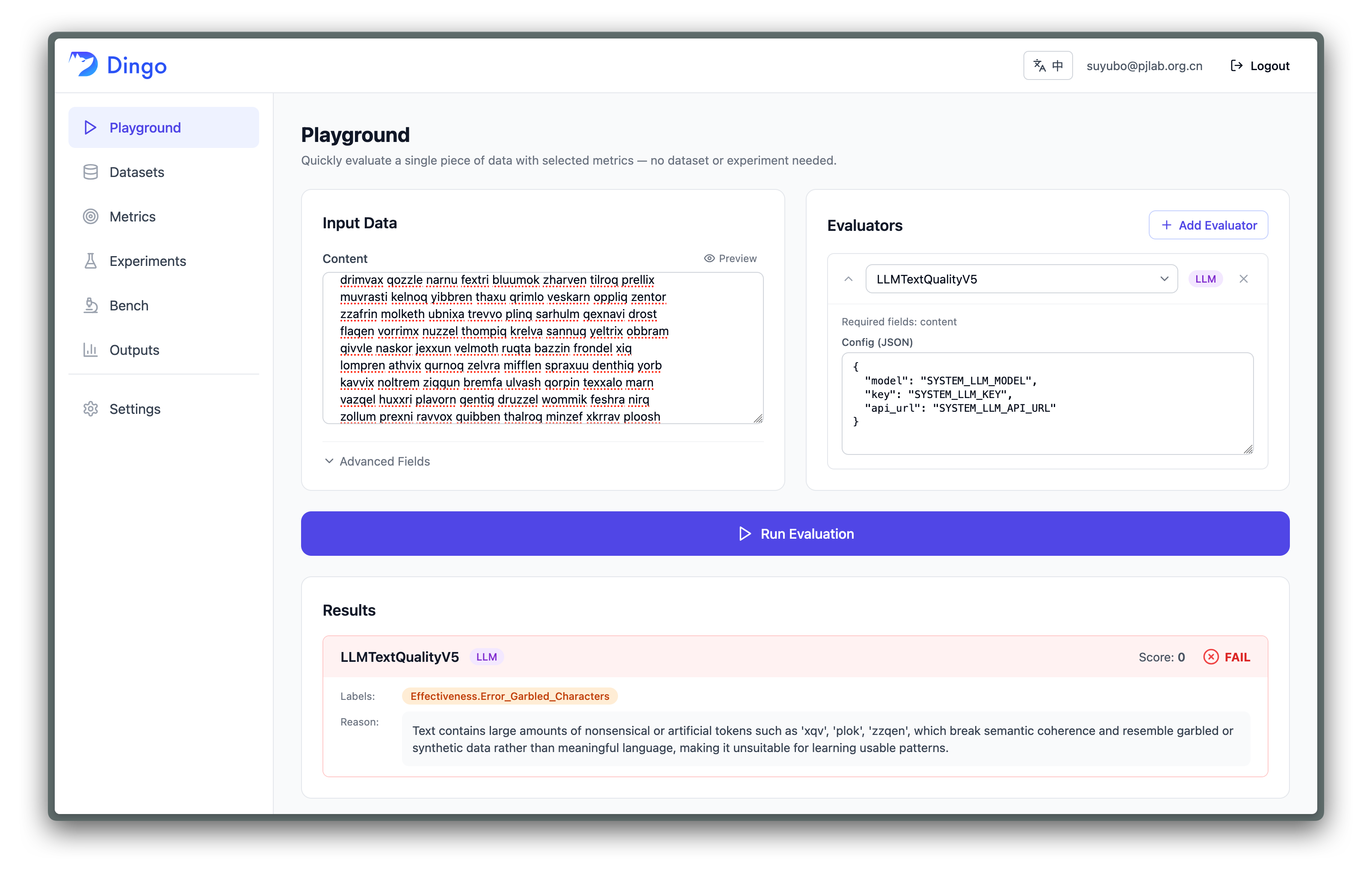
【例】使用文本质量规则检测乱码文字
Full Pipeline 模式 - 批量测试
- 适用场景:大规模数据集质量评估,、模型对比实验、生产环境监控
- 操作流程:
- 上传数据集(支持本地文件、HuggingFace仓库、Amazon S3、SQL多种数据源)
- 配置评估规则组合(可混合LLM评估器和规则评估器)
- 创建实验并执行(支持本地 / Spark 分布式执行)
- 查看可视化报告(字段级质量分布、问题样本定位、趋势分析)
- 优势:提供完整的实验管理和报告导出功能
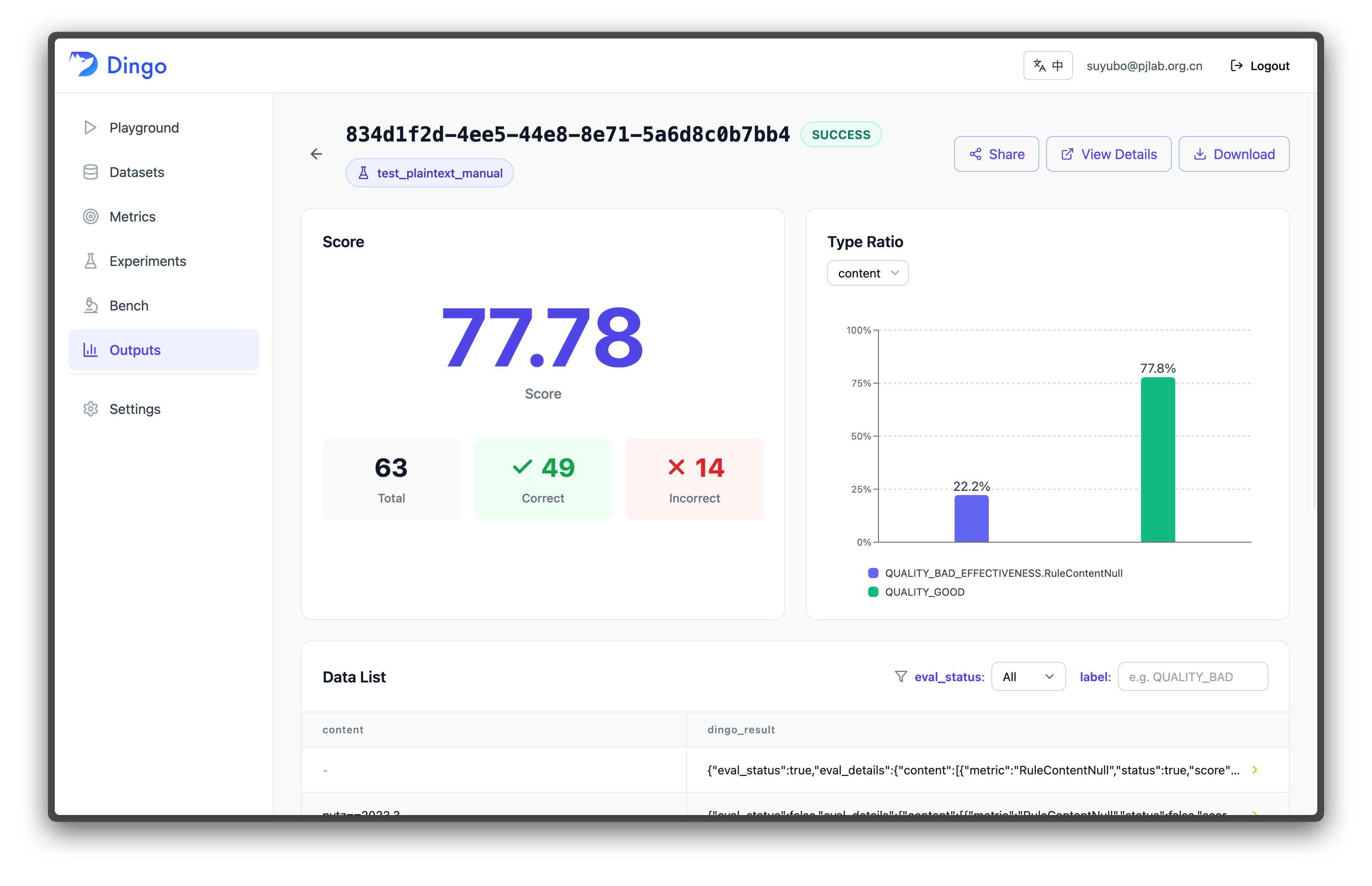
【例】对数据集的检测结果自动生成检测报告
Dingo SaaS 地址:https://dingo.openxlab.org.cn
企业版代码申请入口: https://aicarrier.feishu.cn/share/base/form/shrcnr19E0upfiA92Wm5i2eic7g
典型应用场景
场景一:预训练语料过滤
在大规模预训练前,可以先使用 Dingo 对语料做规则扫描和质量分层,识别异常字符、乱码、重复内容、低质量网页文本和安全风险内容。
规则评估可以覆盖全量数据,LLM 评估可以对抽样数据进行深度判断,从而在成本可控的情况下提升整体语料质量。
场景二:SFT 数据质量检查
对于指令微调数据,Dingo 可以帮助检查:
- prompt 和 response 是否匹配;
- 回答是否有帮助;
- 是否存在事实错误;
- 是否存在不安全内容;
- 是否符合 Honest、Helpful、Harmless 的 3H 要求。
这对于构建高质量指令数据集非常重要。
场景三:RAG 系统上线评估
RAG 应用上线前,可以用 Dingo 评估检索和生成两个环节:
- 检索内容是否相关;
- 回答是否忠于上下文;
- 上下文是否覆盖答案;
- 回答是否真正解决用户问题。
相比只看最终答案是否“看起来合理”,这种指标化评估更利于系统优化和版本迭代。
场景四:生产 AI 输出监控
对于已经上线的 AI 应用,可以将 Dingo 接入日志或数据库,定期检测模型输出质量、幻觉风险、安全问题和用户体验问题。
结合 MCP、CLI、SDK 或 SaaS,Dingo 可以成为生产 AI 系统持续质量监控的一部分。
未来展望
根据新版路线图,Dingo 后续还会继续增强以下方向:
- Agent-as-a-Judge:通过多智能体辩论降低偏差,提升复杂评估可靠性;
- SaaS 平台能力增强:提供更完整的托管评估服务、API 和仪表盘;
- 音频与视频模态支持:从文本、图像进一步扩展到更多模态;
- 多样性指标:增强数据集多样性和覆盖度评估;
- 实时监控:面向生产流水线的持续质量检查。
当然,Dingo 当前内置规则和模型方法主要覆盖常见质量问题。对于特殊业务场景,仍然建议基于 Dingo 的注册机制自定义规则、Prompt 或 Agent 工作流。
结语
AI 系统的质量,最终很大程度上取决于数据、模型输出和应用链路的质量。
Dingo 的价值在于,它把原本分散在脚本、人工检查、临时 Prompt 和实验工具中的质量评估能力,整合成了一个统一、可扩展、可生产化的工具体系。
从本地文件到数据库,从规则检测到 LLM 语义评估,从 RAG 指标到 Agent 事实核查,从 CLI 到 MCP Server 再到 SaaS 平台,Dingo 正在成为 AI 时代质量评估基础设施的一部分。
如果你正在构建大模型数据集、RAG 系统、多模态数据管线或生产级 AI 应用,Dingo 值得加入你的工具箱。
项目地址:https://github.com/MigoXLab/dingo
如果觉得项目有帮助,欢迎给 Dingo 点一个 Star,也欢迎参与社区贡献。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号