【MySQL】表的增删改查
原创

Ⅰ. 新增数据
insert into table_name
[(列名, 列名, ...)]
values (value_list) [, (value_list), ...]
其中:
value_list: value, [, value, ...] 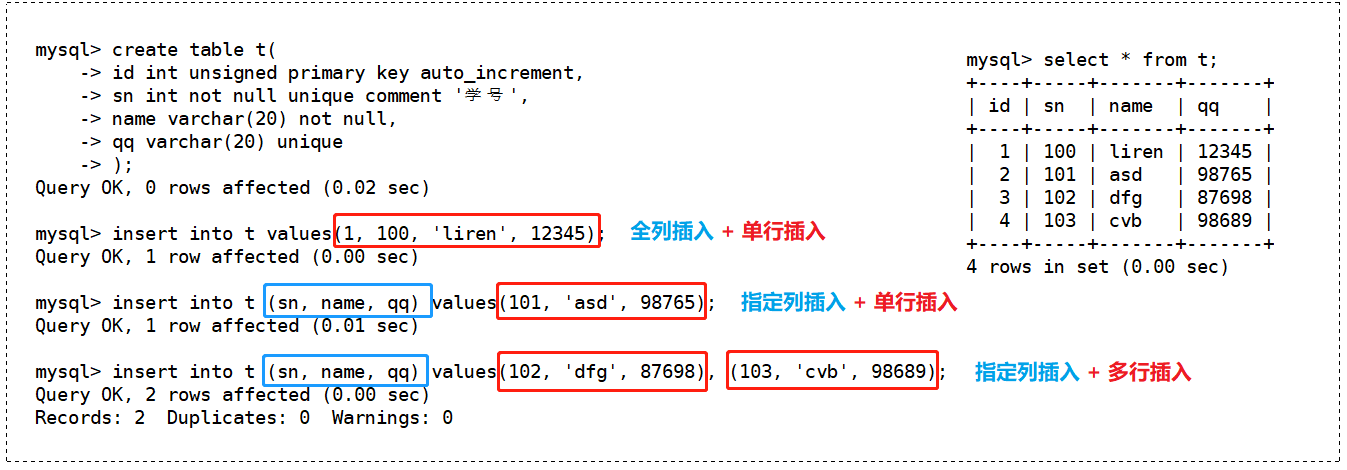
插入数据之后经常会有下面三个情况:
0 row affected:表中有冲突数据,但冲突数据的值和update的值相等,相当于没更新。1 row affected:表中没有冲突数据,数据被插入。2 row affected:表中有冲突数据,并且数据已经被更新。
测试数据:
create table if not exists exam (
id bigint,
name varchar(20),
chinese decimal(3, 1),
math decimal(3, 1),
english decimal(3, 1)
);
insert into exam (id, name, chinese, math, english) values
(1, '唐三藏', 67, 98, 56),
(2, '孙悟空', 87, 78, 77),
(3, '猪悟能', 88, 98, 90),
(4, '曹孟德', 82, 84, 67),
(5, '刘⽞德', 55, 85, 45),
(6, '孙权', 70, 73, 78),
(7, '宋公明', 75, 65, 30);SQL 查询的执行顺序总结🌟🌟🌟
FROM:确定数据来源JOIN ON:进行表连接WHERE:筛选数据GROUP BY:数据分组HAVING:筛选分组后的数据SELECT:选择返回的列DISTINCT:去除重复行ORDER BY:对结果排序LIMIT/OFFSET:限制返回行数
Ⅱ. 查询数据
select
[distinct] # 去重
{* 或者 {列名 [, 列名] ...} [as] 别名}
[from] 表名 # 要检索的表名
[where ...] # 用于指定条件来过滤结果
[group by {列名 | 表达式}] # 分组
[having ...] # 筛选分组后的数据
[order by column [asc | desc], ...] # 排序
[limit ...] # 限定筛选条数☠ 注意事项:
- 使用
DISCTINCT去重时,只有查询列表中所有列的值都相同才会判定为重复 WHERE条件中可以使用表达式,但不能使用别名。HAVING可以使用别名。这是因为MySQL在实际执行时会进行优化,但这种引用是逻辑上的,物理执行顺序仍然是HAVING先于SELECT,注意区分!- 在使用聚合函数和
group by的时候,select语句中只能使用聚合函数以及group by后面出现的字段,而其它的字段都不能出现在select语句中!
limit 的使用
# 1. 从 0 开始,筛选 n 条结果
select 列名 from 表名 [where ...] [order by ...] limit n;
# 2. 从 s 开始,筛选 n 条结果
select 列名 from 表名 [where ...] [order by ...] limit s, n;
# 3. 从 s 开始,筛选 n 条结果,比第二种用法更明确,更建议使用!
select 列名 from 表名 [where ...] [order by ...] limit n offset s;常见运算符
运算符 | 描述 | 示例 |
|---|---|---|
= | 等于 | WHERE column = value |
<=> | 等于(对于 NULL 安全) | WHERE column <=> value |
<>、!= | 不等于 | WHERE column <> value |
> | 大于 | WHERE column > value |
< | 小于 | WHERE column < value |
>= | 大于等于 | WHERE column >= value |
<= | 小于等于 | WHERE column <= value |
BETWEEN | 在指定范围内 | WHERE column BETWEEN value1 AND value2 |
IN | 在指定集合中 | WHERE column IN (value1, value2, ...) |
LIKE | 模糊匹配 | WHERE column LIKE 'pattern' |
NOT LIKE | 不模糊匹配 | WHERE column NOT LIKE 'pattern' |
IS NULL | 判断是否为 NULL | WHERE column IS NULL |
IS NOT NULL | 判断是否不为 NULL | WHERE column IS NOT NULL |
AND | 逻辑与 | WHERE condition1 AND condition2 |
&& | 逻辑与(与 AND 相同) | WHERE condition1 && condition2 |
OR | 逻辑或 | WHERE condition1 OR condition2 |
|| | 逻辑或(与 OR 相同) | WHERE condition1 || condition2 |
NOT | 逻辑非 | WHERE NOT condition |
! | 逻辑非(与 NOT 相同) | WHERE !condition |
☠ 注意事项:
- 使用
like进行模糊查询的时候,通常用%匹配任意字符(包括0个),_匹配一个字符。 - 过滤
NULL时不要使用=、!=、<>,而要用is null或者is not null,不然会直接报错。 NULL与任何值运算结果都为NULL。
联合查询
- 【内连接】就是通过
where对两种表形成的笛卡儿积进行筛选。 - 【外连接】就是不管是否为
null,也会进行连接。左外连接以左边的表为基准表,右外连接同理!格式如下所示:
select 字段名 from 表1 left join 表2 on 连接条件;- 对于同一张表的【自连接】必须要进行重命名
- 子查询通常配合
in、all、any关键字使用 - 合并查询使用
union、union all
Ⅲ. 修改数据
☠ 注意:以原值的基础上做变更时,不能使用 math += 30 这样的语法。
update 表名 set column1=value1 [, column2=value2, ...]
[where 条件]
[order by ...]
[limit ...];Ⅳ. 删除数据
delete
用于从表中删除满足指定条件的行,可以根据需要删除部分或全部数据。delete 语句是一种 DML(数据操作语言)操作,它会生成事务日志,并且可以回滚。
delete from 表名
[where 条件]
[order by ...]
[limit ...];truncate
用于删除表中的所有数据,它会将表重置为空表,但保留表的结构。truncate 语句是一种 DDL(数据定义语言)操作,它不会生成事务日志,并且不能回滚。
truncate table 表名;☠ 注意事项:
- 只能对整表操作,不能像
delete一样针对部分数据操作 - 实际上
truncate不对数据操作,所以比delete更快,但是truncate在删除数据的时候,并不经过真正的事务,所以无法回滚 - 会重置
auto_increment
Ⅴ. 插入查询结果
通过 insert 子句和 select 子句的配合,达到插入一些需要的查询结果的目的!
insert into 表名 [(列名 [, 列名 ...])] select ...Ⅵ. 聚合函数
函数名 | 描述 | 使用示例 |
|---|---|---|
COUNT() | 计算行数 | SELECT COUNT(*) FROM users |
SUM() | 计算数值总和 | SELECT SUM(salary) FROM employees |
AVG() | 计算平均值 | SELECT AVG(score) FROM tests |
MAX() | 获取最大值 | SELECT MAX(price) FROM products |
MIN() | 获取最小值 | SELECT MIN(age) FROM students |
☠ 注意事项:
COUNT(*)计算所有行数(包括NULL),COUNT(column)计算该列非NULL值的数量count(*)是 SQL 语言级别的标准,对于所有的数据库软件都通用,而网上有的文章说count(column)比count(*)效率更高,这是有争议的,因为前者都不一定适应于某个数据库软件!
Ⅶ. 内置函数
字符串函数
函数 | 描述 | 示例 |
|---|---|---|
CONCAT(str1, str2, ...) | 连接多个字符串 | CONCAT('Hello', ' ', 'World') 返回 Hello World |
LENGTH(str) | 返回字符串的字节长度 | LENGTH('Hello') 返回 5 |
CHAR_LENGTH(str) | 返回字符串的字符长度 | CHAR_LENGTH('Hello') 返回 5 |
UPPER(str) | 将字符串转换为大写 | UPPER('hello') 返回 HELLO |
LOWER(str) | 将字符串转换为小写 | LOWER('HELLO') 返回 hello |
SUBSTRING(str, pos, len) | 从字符串中提取子字符串 | SUBSTRING('Hello World', 7, 5) 返回 World |
REPLACE(str, from_str, to_str) | 替换字符串中的子字符串 | REPLACE('Hello World', 'World', 'MySQL') 返回 Hello MySQL |
TRIM(str) | 去除字符串两端的空格 | TRIM(' Hello World ') 返回 Hello World |
数值函数
函数 | 描述 | 示例 |
|---|---|---|
ABS(x) | 返回绝对值 | ABS(-10) 返回 10 |
CEIL(x) | 返回大于或等于 x 的最小整数 | CEIL(3.14) 返回 4 |
FLOOR(x) | 返回小于或等于 x 的最大整数 | FLOOR(3.14) 返回 3 |
ROUND(x, d) | 四舍五入到小数点后 d 位 | ROUND(3.1415, 2) 返回 3.14 |
RAND() | 返回 0 到 1 之间的随机数 | RAND() 返回一个随机数 |
POW(x, y) | 返回 x 的 y 次方 | POW(2, 3) 返回 8 |
SQRT(x) | 返回 x 的平方根 | SQRT(16) 返回 4 |
日期与时间函数
函数 | 描述 | 示例 |
|---|---|---|
NOW() | 返回当前日期和时间 | NOW() 返回当前日期和时间 |
CURDATE() | 返回当前日期 | CURDATE() 返回当前日期 |
CURTIME() | 返回当前时间 | CURTIME() 返回当前时间 |
DATE_ADD(date, INTERVAL expr type) | 在日期上添加时间间隔 | DATE_ADD('2025-01-01', INTERVAL 1 YEAR) 返回 2026-01-01 |
DATE_SUB(date, INTERVAL expr type) | 从日期上减去时间间隔 | DATE_SUB('2025-01-01', INTERVAL 1 YEAR) 返回 2024-01-01 |
DATEDIFF(date1, date2) | 返回两个日期之间的天数差 | DATEDIFF('2025-01-01', '2024-01-01') 返回 366 |
YEAR(date) | 返回日期的年份 | YEAR('2025-01-01') 返回 2025 |
MONTH(date) | 返回日期的月份 | MONTH('2025-01-01') 返回 1 |
DAY(date) | 返回日期的天数 | DAY('2025-01-01') 返回 1 |
其它函数
函数 | 描述 | 示例 |
|---|---|---|
USER() | 返回当前用户名 | USER() 返回当前用户名 |
DATABASE() | 返回当前数据库名 | DATABASE() 返回当前数据库名 |
VERSION() | 返回 MySQL 版本 | VERSION() 返回 MySQL 版本 |
UUID() | 返回一个通用唯一标识符 | UUID() 返回一个 UUID |
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号