小米 MiMo 为什么这么能打,架构里藏着什么秘密?

小米 MiMo 为什么这么能打,架构里藏着什么秘密?

老周聊架构
发布于 2026-05-08 18:38:41
发布于 2026-05-08 18:38:41
发布当天,直接冲上了 OpenRouter 闭源模型榜首。
技术圈炸了。有人说这是营销,有人说是真功夫。
我的判断是:架构上确实有东西。
这篇文章,把 MiMo-V2 的核心技术方案拆开来看。看完你就明白,它的亮眼成绩不是靠运气。
一、MoE 架构:把"大模型"变小的秘密
大模型最大的矛盾是什么?
参数越多,能力越强;但参数越多,推理成本越高。 跑一个 700B 的全参数模型,光显存就能劝退 99% 的使用场景。
MiMo 选的路是 MoE,混合专家架构。
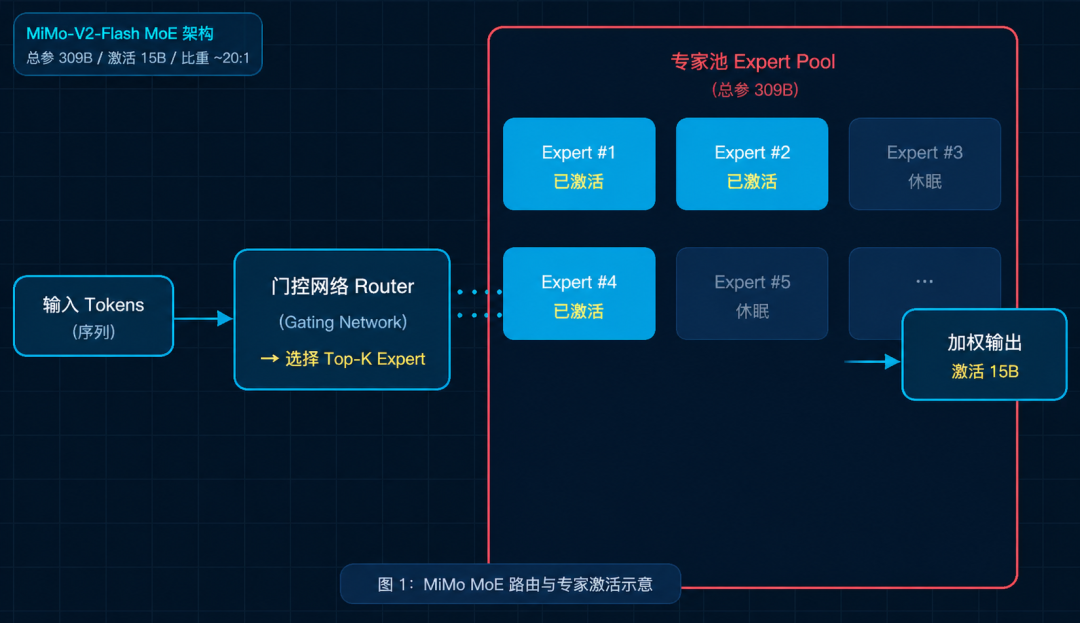
MiMo-V2-Flash 的总参数量是 309B,听起来非常庞大。但每次推理只激活 15B 参数,其余专家处于"休眠"状态。
这就像一家医院有 100 位专科医生,但每次接诊只叫来 5 位。医院规模大,但运营成本低。
总参 309B、激活 15B,比例约为 20:1。 这个激活比在同级别模型里属于第一梯队。
核心原理不复杂:门控网络(Router) 根据输入内容判断该激活哪些专家。每个 token 只分发给少数 Expert,再由这些 Expert 分别计算后加权输出。
真正难的是 Expert 的调度策略和负载均衡。太集中,模型退化为单专家模式;太分散,每个 Expert 学不到足够的专业能力。MiMo 在这块做了针对性优化,从评测结果看,调度效率确实达到了预期水平。
二、Hybrid Attention:全局视野和局部效率的平衡
纯 Transformer 的全局 Attention 是长序列场景的性能杀手。self-attention 的计算量随序列长度的平方增长,跑到 32K token 时,Attention 本身就成了瓶颈。
Flash Attention 解决了计算效率,但解决不了信息密度问题。
MiMo-V2-Flash 引入了混合注意力机制:全局注意力与滑动窗口注意力按 1:5 的比例搭配。
全局注意力负责跨区域的信息融合,让模型能看到句子开头和结尾之间的关联。滑动窗口注意力负责局部语义的精确捕捉,5 层窗口注意力交替堆叠,等效感受野其实并不小,但每层的计算量被严格控制在局部范围内。
换句话说,全局负责"抬头看路",局部负责"低头干活"。两者结合,在保持推理速度的同时,长上下文的理解质量不会出现明显下滑。
这个思路并不新鲜,但能把 1:5 这个配比调对,需要大量实验积累。

三、Agent 原生训练:不是能考试,是能干活
很多人测完 MiMo-V2 后的反馈很一致:代码能力强,Agent 场景下任务完成率高。
这不是偶然。
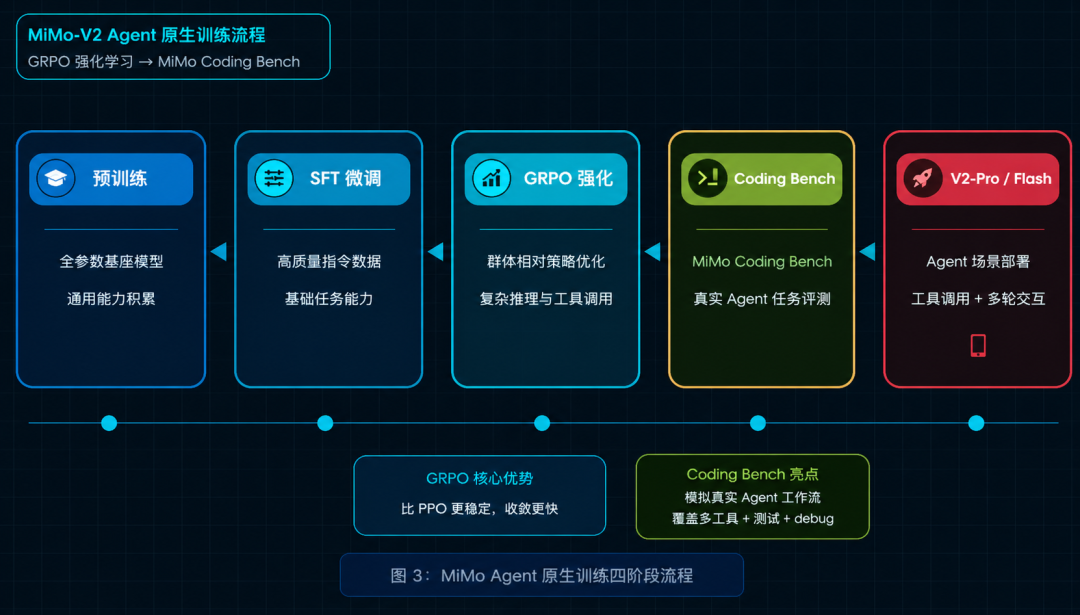
MiMo 团队在训练方法上做了两件关键的事。
第一件事是用 GRPO 做强化学习优化。 GRPO 是 DeepSeek 在 2025 年初提出的群体相对策略优化方法,比传统 PPO 更稳定、收敛更快。MiMo 在此基础上融合了当年的新论文成果,后发优势明显。
第二件事是自建了 MiMo Coding Bench 评测集。 这套基准专门衡量模型在复杂编程任务中的表现,模拟的是真实 Agent 工作流:理解需求、读代码库、写代码、跑测试、改 bug。
传统评测集如 HumanEval 考的是独立函数生成,和真实编程场景差距很大。MiMo Coding Bench 把这个问题扳过来了。
结果就是:MiMo 在需要多轮交互、长程规划、工具调用的场景下表现格外突出。它是按"能干活"的思路训出来的,不是按"能考试"的思路训出来的。
四、为什么是小米
一个手机公司,为什么能在开源模型这件事上打出成绩?
答案要从 人才和场景 两个维度找。
MiMo 的技术负责人 罗福莉 是业内公认的强化学习方向顶级工程师,曾主导过若干重要模型的核心研发。团队规模不大,但 核心人员的密度很高。
场景方面,小米的 AIoT 生态(手机 + IoT 设备 + 智能座舱) 天然就是 Agent 的落地温床。模型能力越强,设备联动体验越好,这个飞轮一旦转起来,数据反哺模型迭代的速度会比纯云端公司快很多。
4 月 23 日,MiMo-V2.5 系列又更新了代码评测基准,继续强化 Agent 场景的能力护城河。这不是一次性的动作,是按路线图在推进的。
五、总结
MiMo 的核心优势,不是某个单点技术突破,而是三点组合:
第一,MoE 架构选得对,总参大但激活小,性价比高。
第二,Hybrid Attention 比例调得准,长上下文场景下速度和质量兼顾。
第三,训练路线明确面向 Agent 场景,不跟风卷评测榜,卷的是真实任务完成率。
这三点加在一起,就是那句"表现突出"的底气。
大模型赛道从来不缺"霸榜一个月"的选手,缺的是能连续拿出稳定迭代能力的团队。小米这一轮,至少证明了自己不只是玩票。
下一期,我们接着聊 MiMo-V2.5 新出的模型,看看它和 DeepSeek、Qwen 同台竞技时各自的优劣在哪。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号