YOLO26 解耦检测头:分类回归分开做

YOLO26 解耦检测头:分类回归分开做

javpower
发布于 2026-05-08 18:55:29
发布于 2026-05-08 18:55:29
YOLO26 解耦检测头:分类回归分开做
YOLO 的检测头一直在演进。从 YOLOv5 的耦合头,到 YOLOX 的解耦头,再到 YOLO26 的默认设计。这篇文章聊聊解耦检测头这个改动。
耦合头 vs 解耦头
耦合头 (Coupled Head):分类和边界框回归共享同一个特征提取,输出时再拆开。
解耦头 (Decoupled Head):分类和回归有各自独立的分支,各算各的。
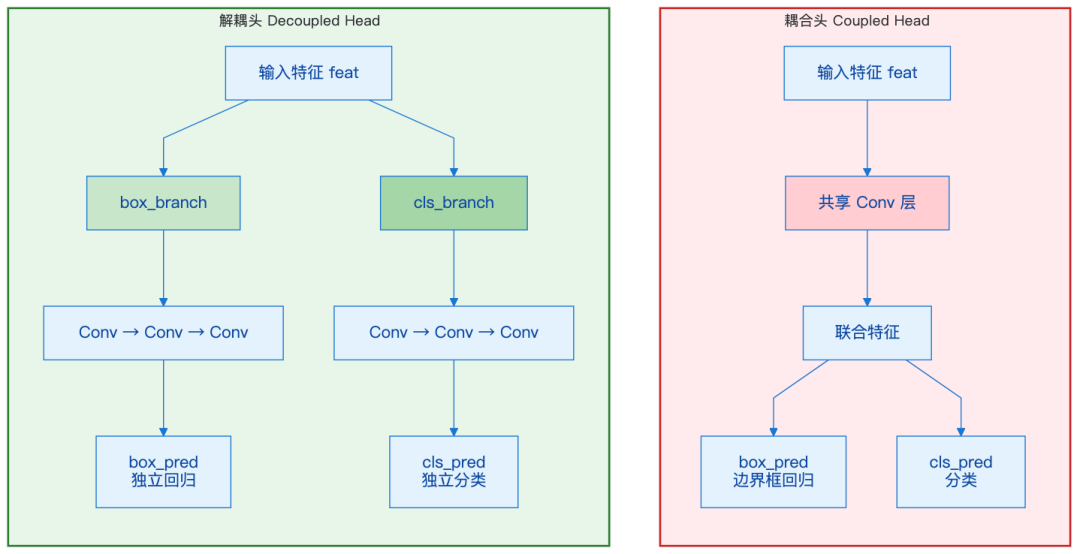
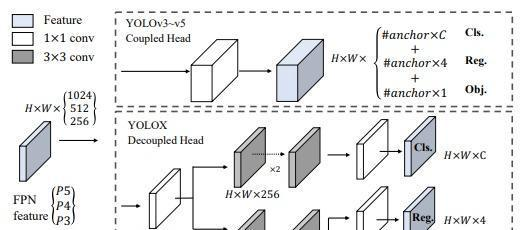
YOLOX 的论文里有张图很清楚地展示了这个区别:
解耦头为什么更好
1. 训练收敛更快
YOLOX 的实验表明,解耦头能显著加速训练收敛。在 COCO 上的训练曲线显示:
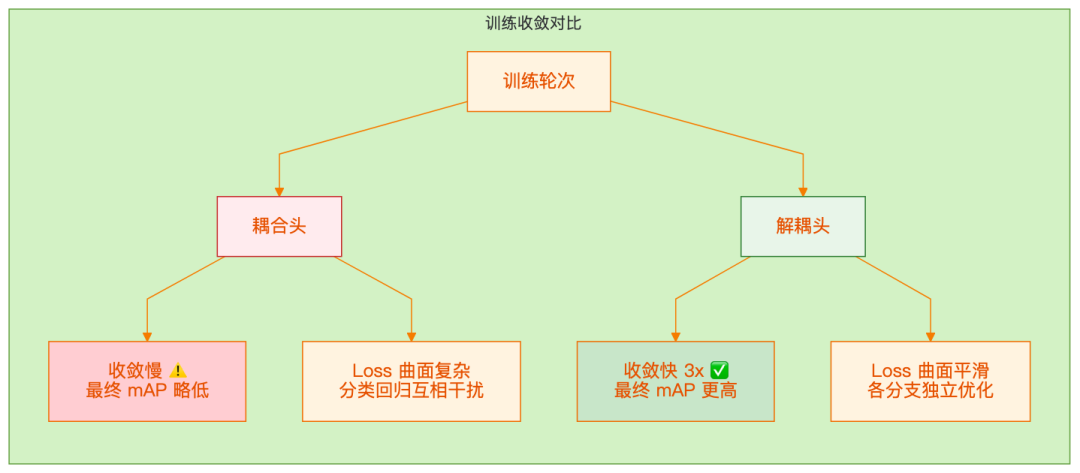
2. 分类和定位的优化不冲突
分类任务关注的是"这个目标是什么",定位任务关注的是"边界在哪里"。这两个目标的优化方向并不完全一致,强行耦合可能会互相干扰。
解耦后,每个分支可以专注于自己的任务。
3. 方便做 IoU-aware
解耦头可以更容易地加入 IoU prediction 分支,让分类分数和定位质量解耦。推理时可以用 score = cls_score * iou_score 来做更准确的排序。
YOLO26 Decoupled Head 实现
基于 YOLOX 设计的 Decoupled Head:
class DecoupledHead(nn.Module):
def __init__(self, nc=2, ch=[256, 512, 512], reg_max=16):
super().__init__()
self.nl = 3
c2 = max((16, ch[0] // 4, reg_max * 4))
c3 = max(ch[0], min(nc, 100))
# Box 分支:回归
self.cv2 = nn.ModuleList([
nn.Sequential(Conv(ch[i], c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * reg_max, 1))
for i in range(3)
])
# Cls 分支:分类
self.cv3 = nn.ModuleList([
nn.Sequential(Conv(ch[i], c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, nc, 1))
for i in range(3)
])
self.dfl = DFL(reg_max)
def forward(self, x):
for i in range(self.nl):
box = self.cv2[i](x[i]) # 各自独立计算
cls = self.cv3[i](x[i])
bs, _, h, w = box.shape
# DFL 解码
box = box.view(bs, 4, self.reg_max, h * w)
box_decoded = self.dfl(box)
decoded_boxes.append(box_decoded.transpose(1, 2))
all_scores.append(cls.view(bs, self.nc, -1).permute(0, 2, 1))
return cat([all_boxes, all_scores], dim=-1)
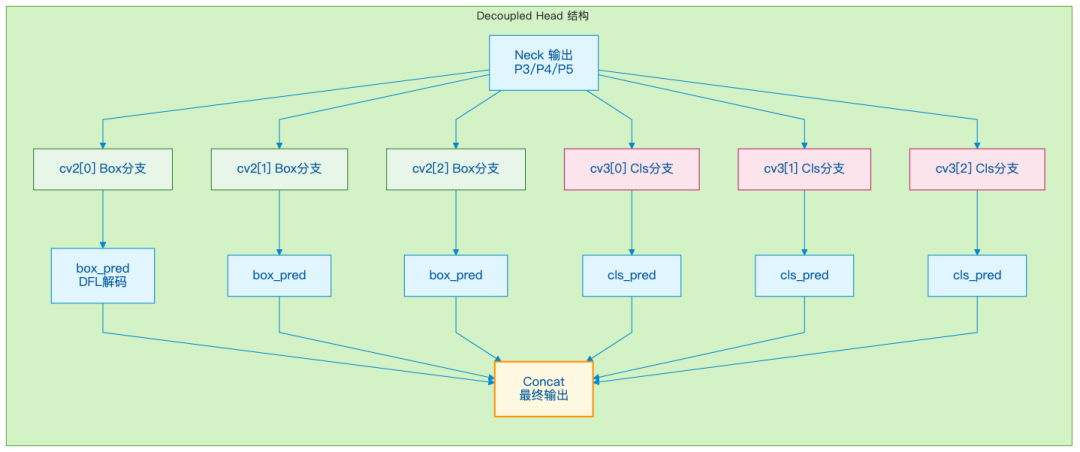
和标准耦合头的对比
YOLO26 默认用的是耦合头,Decoupled Head 是一个可选升级:
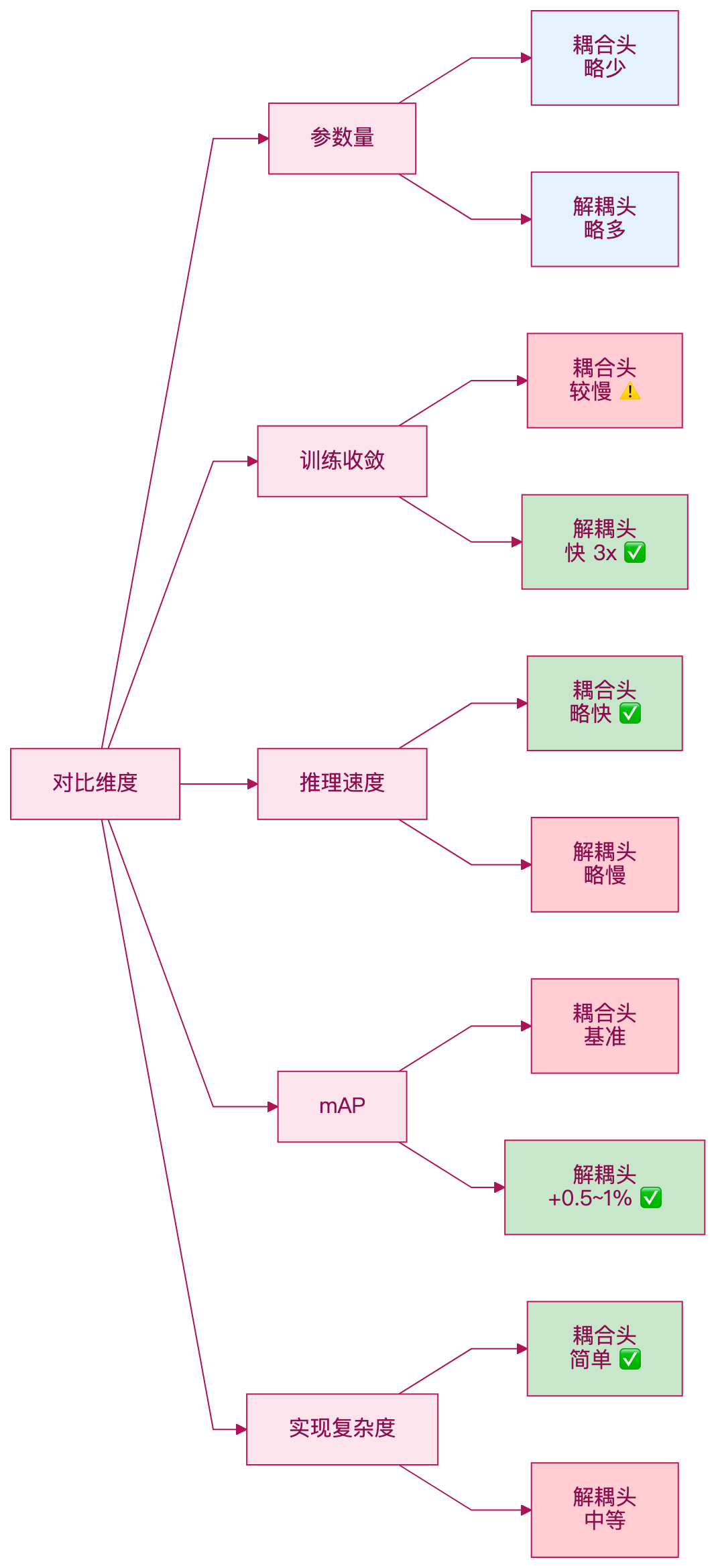
维度 | 耦合头 | 解耦头 |
|---|---|---|
参数量 | 略少 | 略多(多一套分支) |
训练收敛 | 较慢 | 快 |
推理速度 | 略快 | 略慢(多一次 forward) |
mAP | 基准 | +0.5~1% (YOLOX 实验) |
实现复杂度 | 简单 | 中等 |
实际项目里,这个差距可能没那么大。但如果训练时间充裕,解耦头是个值得尝试的改动。
训练配置
解耦头的训练配置和标准 YOLO26 差不多:
# backbone 配置
backbone_type: "yolo26m"
# 冻结策略
freeze_backbone: 0 # 或 2-4 层
# 学习率
lr0: 0.0005
weight_decay: 0.0005
# 数据增强
mosaic: 0.8
mixup: 0.1
有个细节:解耦头的分支多了,显存占用会稍微大一点。batch size 可能需要调小一些。
什么时候用解耦头
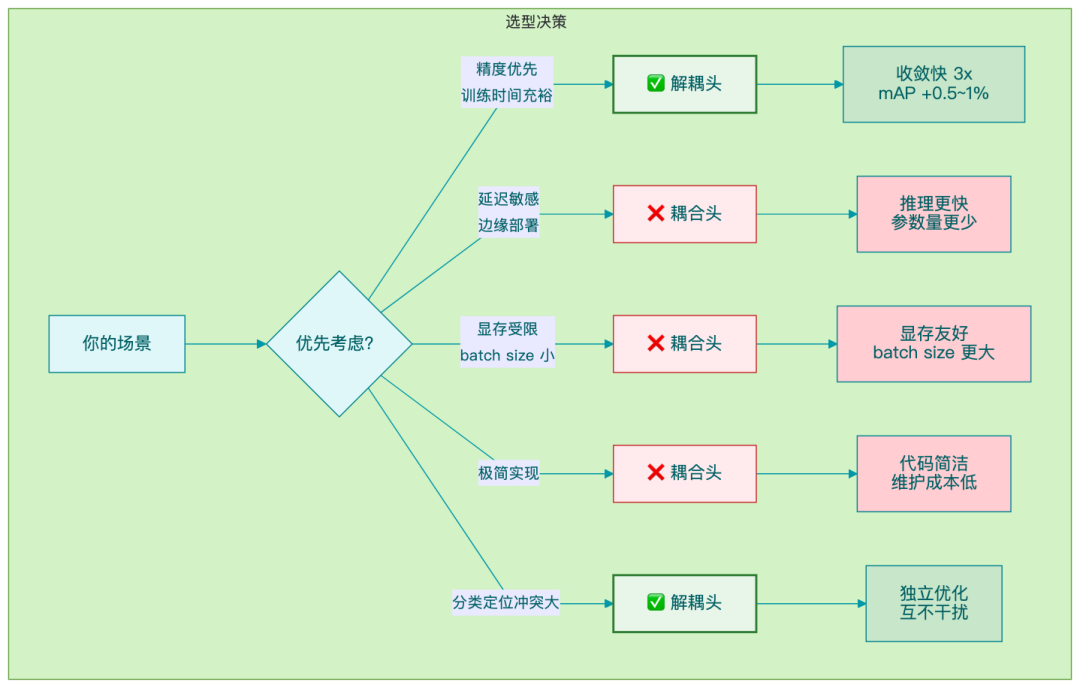
适合的场景:
- 训练时间充裕,想追求更高精度
- 分类和定位任务存在冲突的场景
- 需要更快收敛的项目
不太适合的场景:
- 边缘部署,对延迟敏感
- 显存受限,batch size 已经很小
- 追求极简实现
以上是 YOLO26 解耦检测头的一些整理。是个有效的精度提升手段,但不是必须的。根据你的场景权衡。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号