大模型微调实战:从 HuggingFace 下载到 QLoRA 部署,Java 程序员也能玩转 LLM

大模型微调实战:从 HuggingFace 下载到 QLoRA 部署,Java 程序员也能玩转 LLM

javpower
发布于 2026-05-08 18:57:33
发布于 2026-05-08 18:57:33
大模型微调实战:从 HuggingFace 下载到 QLoRA 部署,Java 程序员也能玩转 LLM
前几天有个读者私信我:"我想微调一个 Llama 3 70B,但我的 A10 只有 24GB 显存,是不是没戏了?" 我回了他三个字:QLoRA。 今天这篇文章,就把我过去一年在 LLM 微调这条路上踩过的坑、用过的工具、攒下的经验,一次性倒给你。文章最后也会有 Java 程序员微调大模型的方案。
HuggingFace 模型下载:镜像和缓存是关键
国内直接连 HuggingFace 官网下载模型,速度通常只有几百 KB/s,而且经常断线。一个 70B 模型的权重文件几百 GB,下到一半重来一次很崩溃。
解决方案
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="meta-llama/Llama-3.1-8B-Instruct",
local_dir="./models/llama-3.1-8b",
resume_download=True, # 断点续传
)
HuggingFace 的缓存目录结构如下:
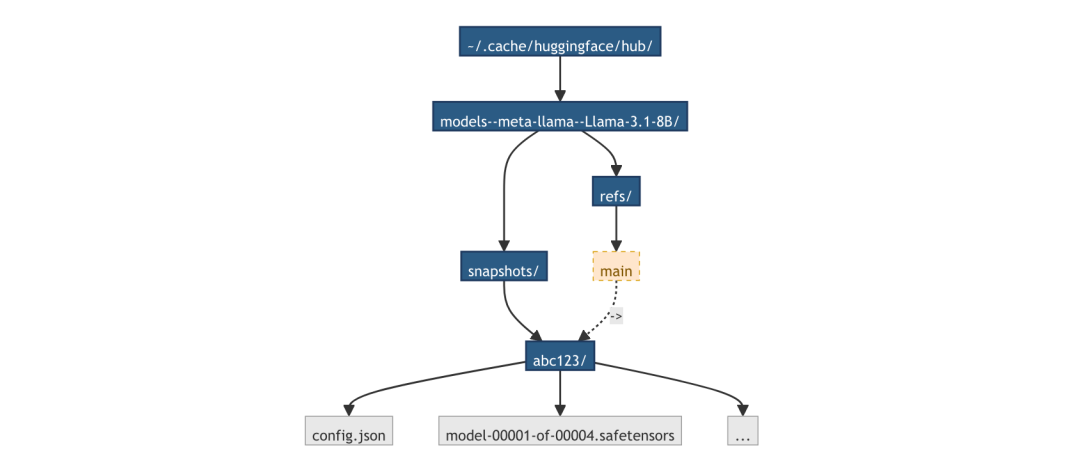
snapshot_download 会智能识别已下载的文件,不会重复下载。配合 resume_download=True,即使断网也能续传,这是生产环境必备的配置。
对话推理:Chat Template 不能省
微调完模型,推理时如果手动拼 prompt,格式和训练时不一致,模型会表现很差。
现代 LLM 都有特定的 chat template,比如 Llama 3:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B-Instruct")
messages = [
{"role": "system", "content": "你是一个专业的代码助手"},
{"role": "user", "content": "写一个快速排序"},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
输出:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
你是一个专业的代码助手<|eot_id|><|start_header_id|>user<|end_header_id|>
写一个快速排序<|eot_id|><|start_header_id|>assistant<|end_header_id|>
训练数据和推理数据必须使用相同的 template,这是很多人微调后模型效果不好的根本原因。
LoRA:只训练 0.25% 的参数
原理
假设原模型有一个权重矩阵 ,LoRA 的做法是:
其中 ,,且 (通常 )。
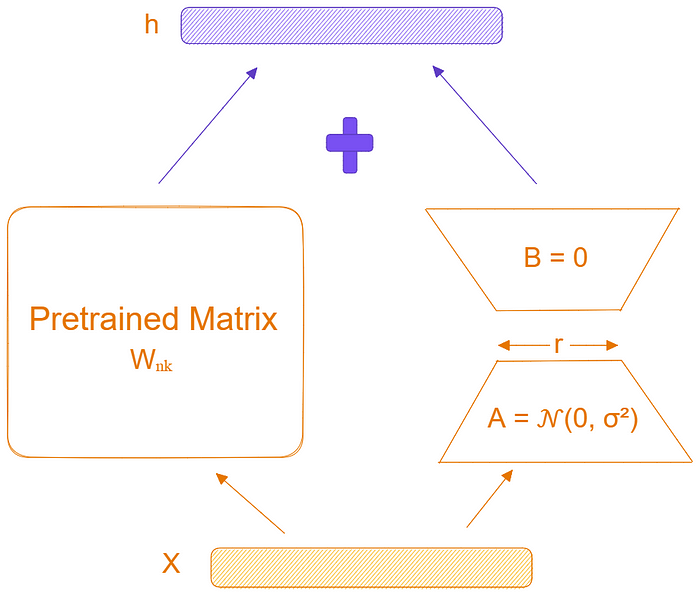
LoRA Matrix Decomposition
LoRA Matrix Decomposition
只训练 A 和 B,W 保持冻结。参数量从 降到 ,通常只有原来的 0.1%~1%。
代码
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B-Instruct",
torch_dtype=torch.bfloat16,
device_map="auto",
)
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=[
"q_proj", "v_proj", "k_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
输出:
trainable params: 20,185,088 || all params: 8,062,263,808 || trainable%: 0.2504
0.25% 的参数,就能达到全量微调 95%~99% 的效果。
QLoRA:24GB 显存跑 70B 模型
LoRA 的问题是模型权重还是 FP16/BF16,加载进显存依然很大。Llama 3 70B 的 FP16 权重需要 140GB 显存,单卡根本放不下。
QLoRA 的核心是 4-bit 量化 + 双重量化 + 分页优化器。
QLoRA Architecture
QLoRA Architecture
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-70B-Instruct",
quantization_config=bnb_config,
device_map="auto",
)
model = get_peft_model(model, lora_config)
显存对比:
方案 | 显存占用 |
|---|---|
FP32 全量 | ~28 GB |
FP16 全量 | ~14 GB |
LoRA (FP16) | ~14 GB |
QLoRA (4-bit) | ~9-12 GB |
70B 模型在 24GB 显存上跑 QLoRA,完全可行。
异步训练与实时回调
微调大模型动辄几小时,干等着看终端效率太低。
WandB 实时监控
from transformers import TrainingArguments, Trainer
import wandb
wandb.init(project="llama-finetune", name="qlora-70b-run1")
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=10,
eval_steps=100,
save_steps=500,
report_to="wandb",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_data,
eval_dataset=eval_data,
)
trainer.train()
异步训练
import asyncio
async def train_async():
loop = asyncio.get_event_loop()
await loop.run_in_executor(None, trainer.train)
return "训练完成"
task = asyncio.create_task(train_async())
适配器合并与量化部署
LoRA 训练完后得到的是 adapter 文件夹(几百 MB),不是完整模型。
./lora-adapter/
├── adapter_config.json
├── adapter_model.safetensors
推理时需要 base model + adapter 一起加载。生产环境建议合并:
from peft import PeftModel
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B-Instruct",
torch_dtype=torch.bfloat16,
)
model = PeftModel.from_pretrained(model, "./lora-adapter")
merged_model = model.merge_and_unload()
merged_model.save_pretrained("./merged-model")
合并后可以用 vLLM、TGI 等框架部署。如果显存还是不够,可以进一步量化:
格式 | 显存 | 质量损失 |
|---|---|---|
FP16 | 100% | 0% |
GPTQ-4bit | ~25% | ~1-2% |
GGUF-Q4_K_M | ~25% | ~2-3% |
GGUF-Q8_0 | ~50% | ~0.5% |
Q4_K_M 是性价比之王,显存砍 75%,质量只掉 2-3%。
完整流程
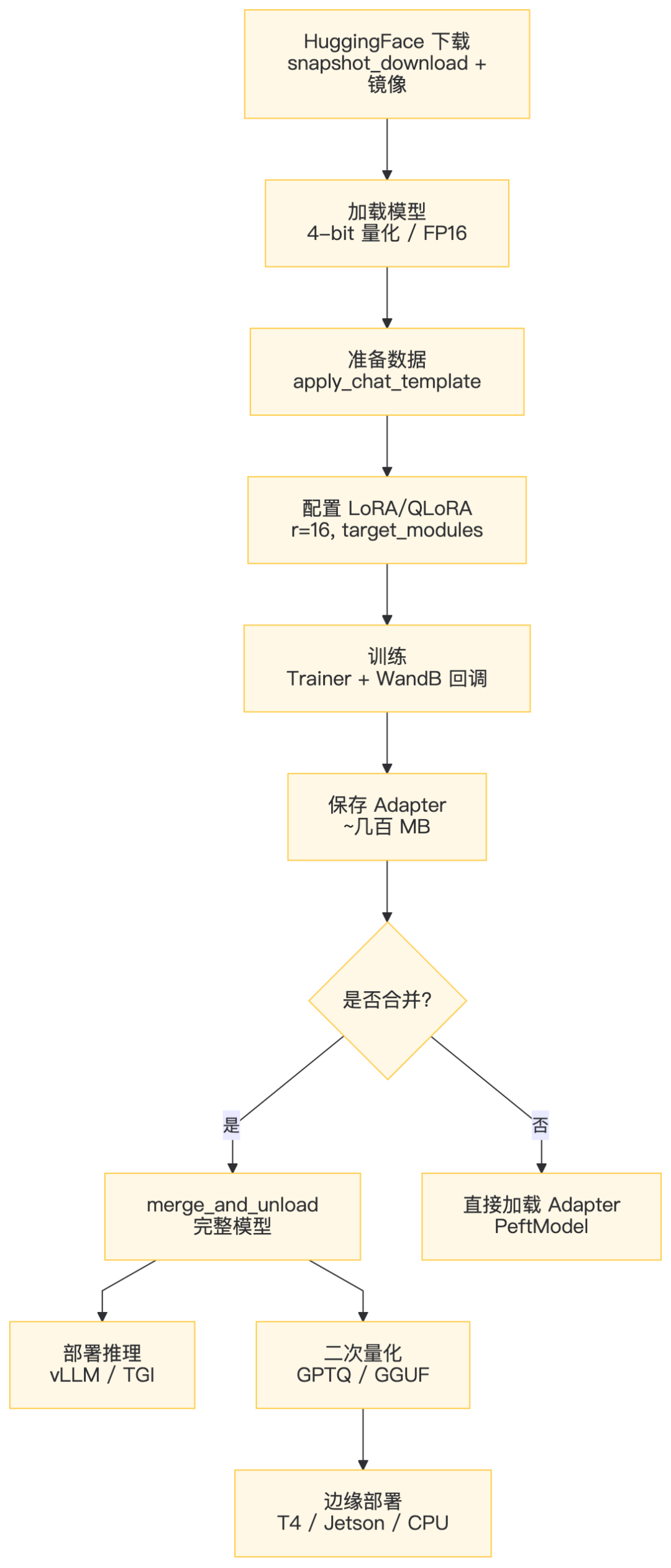
方案对比
场景 | 推荐方案 | 显存需求 |
|---|---|---|
8B 模型,单卡 24GB | LoRA (FP16) | ~14GB |
70B 模型,单卡 24GB | QLoRA (4-bit) | ~20GB |
70B 模型,多卡 A100 | LoRA (FP16) | ~140GB |
边缘部署 T4/Jetson | GPTQ / GGUF | ~8-16GB |
极致速度,大批量 | 合并后 + vLLM | 依配置 |
给 Java 程序员的工具
上面讲的都是 Python 生态的工具链。如果你的团队主力是 Java,不想切到 Python,或者想把 LLM 能力集成到现有的项目里,推荐一个项目:
jpy-ml —— 一个通过 JNI 将完整 Python ML 生态嵌入 JVM 的 Java 框架。
项目地址:https://gitee.com/javpower/jpy-ml
你不需要写 Python,直接在 Java 代码里调用:
// 从 HuggingFace Hub 下载模型(自动缓存到 ~/.jpy-ml/llm-models/)
LLMModel model = LLMModel.download("Qwen/Qwen2.5-0.5B-Instruct");
// 对话推理
ChatResponse response = model.chat(
ChatMessage.system("你是一个专业的代码助手"),
ChatMessage.user("写一个快速排序")
);
System.out.println(response.getContent());
System.out.println("Tokens: prompt=" + response.getPromptTokens()
+ " completion=" + response.getCompletionTokens());
// LoRA 微调
LLMTrainingResult result = model.fineTune()
.lora(LoRAConfig.create().rank(16).alpha(32))
.dataset("training_data.jsonl")
.config(LLMTrainConfig.create()
.epochs(3)
.batchSize(4)
.gradientAccumulation(4)
.learningRate(2e-4f)
.maxSeqLength(2048))
.run((step, log) -> {
System.out.println("Step " + step + ": " + log);
});
// 异步微调
CompletableFuture<LLMTrainingResult> future = model.fineTune()
.lora(LoRAConfig.create().rank(8).alpha(16))
.dataset("data.jsonl")
.config(LLMTrainConfig.create().epochs(2))
.runAsync((step, log) -> {
System.out.println("[异步] " + log);
});
// 合并适配器到基座模型
String mergedPath = LLMModel.mergeAdapter(
model.getModelPath(),
result.getAdapterPath(),
"/path/to/merged-model"
);
核心特点:
传统方案 | jpy-ml |
|---|---|
REST 调用 Python 服务 | 进程内运行(JNI),零网络延迟 |
手动安装 Python + pip + torch | 自动下载 Python、依赖、模型权重 |
解析无类型 JSON | 强类型结果:ChatResponse、LLMTrainingResult |
部署两个服务(Java + Python) | 单 JVM 进程,运维更简单 |
只能推理 | 推理 + 训练 + 验证 + 导出 + LLM 微调 |
对于已有 Java 技术栈的团队来说,这个方案省去了搭建 Python 环境、维护两套技术栈的成本。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号