小米二面:Redis为什么能支撑10万+ QPS?


大家好,我是苏三,又跟大家见面了。
前言
前段时间,有位小伙伴去小米面试,被问到一个经典题目:“Redis为什么能支撑10万+ QPS?”
他回答“因为它是内存数据库”,面试官追问:“Memcached也是内存数据库,为什么Redis能处理更复杂的数据结构还更快?”他一时语塞,直接挂了。
今天这篇文章专门跟大家一起聊聊这个话题,希望对你会有所帮助。
一、开篇:10万+ QPS是什么概念?
先看一组官方基准测试数据(普通笔记本环境下):
- GET请求:约 103,504 QPS
- SET请求:约 100,894 QPS
- INCR请求:约 99,662 QPS
开启Pipeline后,INCR请求的QPS可飙升至 1,061,301,突破百万。
面试官想听的,绝不是“内存快”三个字。
下面我们用一张总览图揭示Redis高性能的四大支柱:

下面我们逐一深入剖析。
二、支柱一:内存为王
Redis所有数据都存储在内存中。
一次内存访问约0.1微秒,而磁盘随机IO需要10毫秒。
内存比磁盘快10万倍。
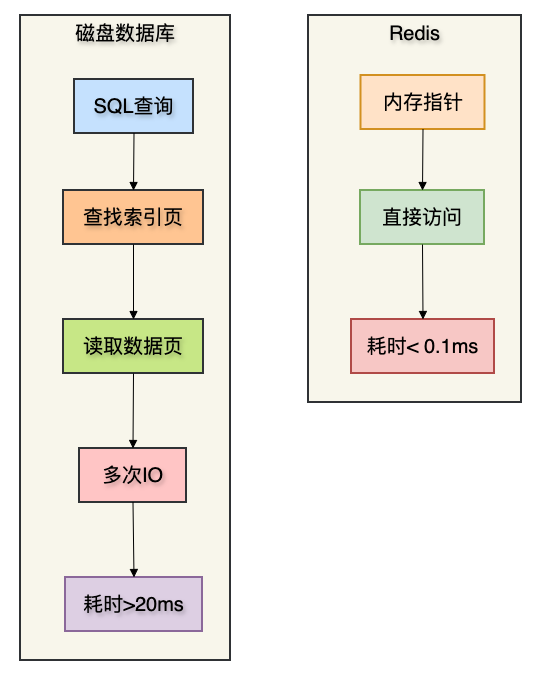
示例对比:从1000万用户中查询某个ID的信息。
MySQL即使有索引,至少需要2~3次磁盘IO(20~30ms);
Redis直接在内存中哈希查找,耗时约0.1ms。
这就是量级的差距。
三、支柱二:极致的数据结构
Redis提供了五种核心数据结构:字符串、哈希、列表、集合、有序集合。
每种结构都不是简单的封装,而是针对场景做了深度定制。
3.1 简单动态字符串(SDS)
C语言原生字符串获取长度需要遍历(O(N)),且修改时容易造成缓冲区溢出。Redis设计了SDS结构:
struct sdshdr {
int len; // 已使用长度
int free; // 未使用长度
char buf[]; // 字节数组
};
graph LR
subgraph SDS结构
A[len=5] --> B[free=2]
B --> C[buf='H''e''l''l''o''\0'...]
end
- **获取长度O(1)**:直接读
len字段。 - 杜绝缓冲区溢出:修改前检查剩余空间,不足则自动扩容。
- 空间预分配:扩展时多分配一些空闲空间,减少内存重分配次数。
3.2 压缩列表(ziplist)
当哈希表或列表的元素较少、值较小时,Redis会用连续内存块存储,称为ziplist。
它避免了指针开销,且能充分利用CPU缓存。
- 优点:内存紧凑,访问快。
- 条件:元素个数<512且值长度<64字节时自动启用。
3.3 跳表(Skip List)
有序集合(ZSET)的底层实现之一。
跳表是多级索引链表,查找时间复杂度O(logN),实现比平衡树简单。
跳表结构示意:

查找时从最高层开始,跳跃前进,效率极高。
3.4 渐进式rehash
Redis的哈希表扩容时,不会一次性将所有键值对迁移,而是分多次、渐进地搬迁。
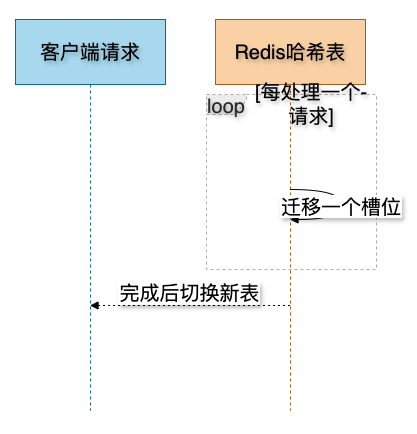
这样将搬家开销平摊到后续操作中,避免了服务卡顿。
四、支柱三:单线程 + IO多路复用
Redis处理网络请求的核心线程只有一个。
为什么单线程还能那么快?
- CPU不是瓶颈:内存操作极快,CPU等待时间很少。
- 无锁竞争:没有多线程同步开销。
- IO多路复用:一个线程通过
epoll监控成千上万个连接,有事件才处理。
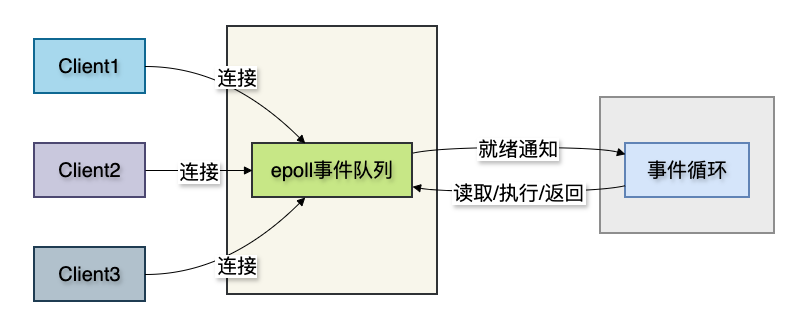
这就是Redis能支撑高并发的核心-单线程处理逻辑,多线程处理网络IO。
五、支柱四:从单线程到多核利用
Redis 6.0之前,网络读写也是单线程,在高流量时可能成为瓶颈。
6.0后引入了IO多线程,但命令执行仍然是单线程。
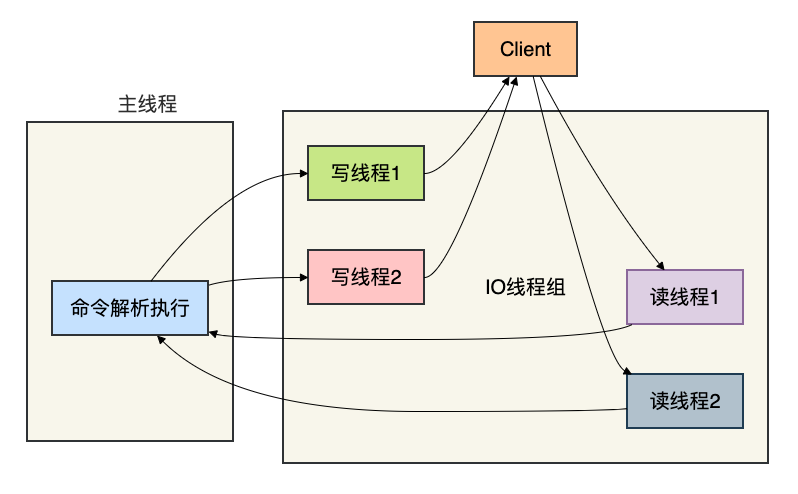
- IO读:多线程并行读取客户端请求并解析协议。
- 命令执行:主线程按顺序执行命令,保证原子性。
- IO写:多线程并行将结果写回客户端。
这样充分利用了多核CPU的网络处理能力,而核心逻辑依然简单可靠。
六、其他性能助推器
Pipeline批量操作:一次性发送多条命令,减少网络往返。
Jedis jedis = new Jedis("localhost");
Pipeline p = jedis.pipelined();
for (int i = 0; i < 1000; i++) {
p.incr("counter");
}
p.sync();
避免大Key:单个Key超过10KB可能阻塞服务。使用redis-cli --bigkeys检查。
合理持久化:压测时可关闭持久化,避免RDB/AOF干扰。
七、优缺点与适用场景
优点 | 缺点 | 适用场景 |
|---|---|---|
性能极高(10万+ QPS) | 存储成本高(内存贵) | 缓存加速 |
数据结构丰富 | 单线程命令易阻塞 | 实时计数器 |
持久化保障 | 单节点容量有限 | 分布式锁 |
高可用集群 | 大Key风险 | 排行榜/社交Feed |
总结
Redis的10万+ QPS,是四大支柱的合力结果:
- 内存存储:绕过磁盘IO。
- 极致数据结构:SDS、ziplist、跳表、渐进式rehash等深度优化。
- 单线程+IO多路复用:避免锁竞争,高效处理并发。
- 多线程IO:提升网络吞吐,保持核心简单。
知其然,更要知其所以然。
希望这篇图文并茂的深度解析,能帮你彻底理解Redis高性能的底层逻辑。
你在面试中还遇到过哪些Redis刁钻问题?欢迎评论区交流~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号