构建和评估文本超图的方法

构建和评估文本超图的方法

CreateAMind
发布于 2026-05-11 20:13:14
发布于 2026-05-11 20:13:14
Make Any Collection Navigable: Methods for Constructing and Evaluating Hypergraph of Text
构建和评估文本超图的方法
https://arxiv.org/pdf/2604.25906


摘要
网络比简单的文档集合更有用的一个原因是,超链接所创建的结构使得能够从一个网页灵活地导航到另一个网页。然而,超链接通常是手动创建的,且无法完全捕捉语料库的隐含语义结构。是否存在一种通用方法使任意集合可导航?近期的工作通常将这一问题形式化为构建文本超图(Hypergraph of Text, HoT),它为支持导航和浏览提供了形式化的数学结构。然而,如何构建和评估文本超图仍然是一个挑战。在本文中,我们提出并研究了几种构建HoT的方法。我们还提出了一种新的定量指标——努力比率(effort ratio),用于评估所构建HoT的结构质量。实验结果表明,即使简单的TF-IDF基线方法在我们提出的努力比率指标上也能与基于LLM的方法相媲美。
1 引言
尽管过去几十年信息检索领域取得了巨大进步,但在分散的集合中发现和导航相关内容仍然是一个挑战。虽然大语言模型(LLM)的最新进展在一定程度上解决了这一挑战(特别是通过直接支持问答),但对其可靠性的担忧[14]以及它们无法获取最新信息限制了其实用性。如何使用户能够直接访问并发现最相关的原始信息仍然是一个开放的挑战。
虽然搜索引擎和像ChatGPT这样的LLM工具有助于帮助人们找到相关信息,但它们要求用户构建有效的查询或问题,因此在存在词汇鸿沟时限制了其实用性。此外,它们在帮助用户发现相关但未知的信息方面作用有限。
浏览被提出作为一种克服这些困难的方法,它使用户能够探索信息空间,而无需任何关于如何构建查询、文档集合中使用何种词汇,或集合中究竟包含什么内容的先验知识。与LLM问答系统相比,浏览允许更大程度的用户自主性和更清晰的信息出处,同时比传统搜索允许更多的意外发现。这些特征使其成为探索式信息检索或集合理解等任务的一个有吸引力的范式。
尽管浏览长期以来一直受到信息检索和网络社区中许多人的关注(例如见[6–8, 10, 11, 19, 25, 26, 34]),但与支持搜索和问答的技术相比,在支持浏览的通用技术方面的研究进展相对较少。浏览与搜索或问答之间的一个关键区别在于,虽然搜索和问答已经享有统一的数学框架和直观的定量指标,但浏览却没有。因此,尽管许多先前的研究都主张需要支持浏览(例如见[7, 19, 34]),并且在浏览方面已经做了大量工作,但仍然缺乏一种通用工具来组织任意的文本集合并实现整个空间的导航;今天的用户大多只能通过手动创建的链接进行导航,例如网络上的众多超链接。
最近,文本超图(HoT)[4]被提出作为一种数学结构,用于将任意文本文档集合组织成超图语义结构并使其可导航。其直观想法是,超边提供了一种定义任何语义邻域的通用方法,这是实现语义导航的关键概念。HoT可以作为构建通用导航系统的理论框架,其意义在于可以将任何可浏览的文档集合表示为HoT,并且任何HoT都可以在统一界面上进行可视化浏览。事实上,文本信息导航工具包[5]可用于可视化任何HoT,并使用户能够导航由HoT表示的信息空间。
然而,如何构建HoT以及如何评估HoT为用户提供的浏览支持的实用性,仍然是未被充分研究的开放性挑战问题;原始工作[4]仅介绍了一种单一方法,且仅进行了定性评估。在本文中,我们试图通过研究如何应对这两个挑战来解决这一知识空白。具体而言,我们研究了几种HoT构建方法,例如LLM、嵌入和TF-IDF过滤。我们通过提出一种新指标来解决评估挑战,该指标量化了HoT超边对浏览的实用性。使用所提出的评估方法,我们在一个网络数据集上系统比较了多种HoT构建方法。实验结果表明,虽然各种方法都能创建有效的链接,但每种方法都涉及不同的权衡,并且在结构导航方面,基于LLM的方法并不总是优于更简单的统计方法。
总之,本文的贡献包括: (1)我们提出并研究了三种方法(TF-IDF过滤、LLM主题提取和两步“相似度-后接LLM”)来解决HoT构建问题。 (2)我们提出了一种新指标,它使得能够对HoT构建算法进行定量评估。 (3)我们进行实验以评估HoT构建算法,发现LLM-doc实现了最低的努力比率,但代价是38%的相关对未连接,而基于TF-IDF的All-Words方法尽管成本低几个数量级,但在结构上仍具有竞争力。
总体而言,我们的工作展示了基于HoT构建开发支持浏览的通用技术的巨大潜力。
2 相关工作
信息抽取: 信息抽取[38]已被广泛研究数十年,近期的一些工作侧重于抽取实体和关系以构建知识图谱[42]。传统方法依赖于监督学习,特别是条件随机场方法[16, 28],并且更侧重于预定义的实体和关系类型。后来的方法探索了如何使用开放实体和关系进行信息抽取[21]。 近期,大语言模型已被用于知识图谱构建[23, 36]。尽管知识图谱可用于组织文本数据,但其对文本内容的覆盖仅限于知识图谱中包含的实体和关系;相比之下,为HoT构建生成的链接覆盖整个信息空间,并使用户能够导航到信息空间中潜在的任何区域。就所抽取的信息而言,HoT构建旨在抽取主题信息,而信息抽取更侧重于抽取实体和关系。HoT构建中抽取的信息对支持用户导航更有用,而抽取的实体和关系往往对构建知识图谱更有用,以进一步支持自然语言处理中的各种下游应用。
主题模型: 概率主题模型[1, 31]是发现和分析文本数据中所涵盖主题的通用技术。抽取出的主题通常表示为词分布。发现的主题及其在文档中的覆盖范围有许多应用,尤其是意见分析、时空主题趋势分析以及基于主题的文档表示。与我们工作最相关的是,使用主题模型从文本中发现的主题结构也可用于组织文本。然而,这种结构在支持用户导航方面存在各种局限性[4](例如,只能很好地覆盖主要主题)。HoT中的超边可以覆盖所有类型的语义链接,并在文本片段级别进行覆盖。因此,它们在支持导航方面比主题模型更有用。
文本聚类: HoT构建也可以与文本聚类[2, 3]和分段[22]相关联。尽管这两项任务都专注于对文本集合进行分组,但传统的聚类方法将对象划分到非重叠的集合中。这使得传统文本聚类方法不适合HoT构建,因为具有非重叠超边的HoT仅能实现簇内导航。相比之下,HoT允许超边重叠,这意味着节点可以是多个集合的成员。这实现了更广泛的连接性,使其成为支持浏览的更合适框架。
语义匹配、超链接生成与语义标注: 在文本语义匹配方面已开展了大量工作[17, 18],主要用于信息检索、问答、文本聚类和抄袭检测等应用[13]。一些近期方法基于大语言模型[39]。一些工作(例如[27])也使用相似度度量来创建链接,从而将线性文本转换为超文本。实际上,超文本和超链接的自动生成也得到了广泛研究[35, 37]。虽然语义文本匹配和自动超链接生成实现的文档点对点链接确实可以促进浏览,但它们无法实现主题浏览。由于HoT既能实现点对点浏览(通过大小为2的超边)又能实现主题浏览,它是一个比旧范式更通用的框架。 一些近期工作也探索了使用大语言模型对文本数据进行语义标注(例如[9, 32],其中可以将层次结构中的语义标签分配给文本文档,实质上实现了层次化文本分类。与文本聚类类似,该任务的目标与HoT构建相似。事实上,语义标注与HoT更为接近,因为各组具有自然语言标签。然而,与文本聚类一样,语义标注/标记通常专注于将文本分类到互不相交的组中。尽管我们可以从其方法中汲取灵感,但由于HoT构建专注于浏览,要求节点属于多个组,HoT与语义标注的计算任务最终是不同的。
大语言模型(LLMs): 近年来,大语言模型在许多自然语言处理[20]和信息检索任务[40]中的应用工作呈爆炸式增长,例如文本摘要[41]、信息抽取[36]和问答[29]。我们的工作引入了大语言模型用于HoT构建的新应用,这在此前尚未被探索,并直接支持大型文档空间中的语义浏览。
3 文本超图
如前所述,尽管用户在信息搜寻中同时使用查询和浏览,但对查询的支持远比对浏览的支持成熟。尽管搜索引擎技术已取得巨大进步,但我们尚无任何类似的通用技术,能将任意分散内容集合转化为组织良好的链接内容以提供通用浏览支持。这里的一个主要障碍是将浏览形式化为计算问题的困难;如果没有为浏览定义明确的计算问题,就很难研究或评估任何算法。 一项近期研究表明,可浏览的集合可以正式表示为文本超图(HoT)[4]。这项工作为如何消除这一长期存在的障碍提供了一些思路,因为我们现在可以将支持浏览的问题正式定义为一个计算问题,其中输入是任意文档集合,输出是以每个文档为节点的HoT。因此,HoT可以作为组织分散内容的通用数学结构。以这种方式构建浏览问题的一个显著好处是,一旦构建了HoT,就可以使用通用系统(如TINK系统[5])将其可视化显示给用户进行浏览。这意味着同一个浏览系统可用于支持浏览任何HoT。因此,如何提供通用浏览支持的整个问题现在可以归结为如何为任意文档集合构建HoT。本文的一个主要目标是开发用于构建HoT的算法,并且关键的是,开发一种评估已构建HoT的方法。
作为背景,我们首先简要介绍文献 [4] 中提出的文本超图(Hypergraph of Text, HoT)结构。我们从其定义开始:
定义 3.1(文本超图)。

这一定义可以看作是文本图(textual graph)的泛化,当应用于文本集合时,它为导航和各种类型的分析提供了基础。
持怀疑态度的读者可能会问:超越图(graphs)进行泛化有什么好处?为了回答这个问题,我们可以回顾浏览方面的基础性工作。在阐述信息系统“采莓模型”(berrypicking model)的开创性著作 [7] 中,Bates 阐述了六种浏览技术:
(1) 脚注追踪(Footnote chasing)
(2) 引用搜索(Citation searching)
(3) 期刊浏览(Journal run)
(4) 区域扫描(Area scanning)
(5) 主题搜索(Subject searching)
(6) 作者搜索(Author searching)
我们对 Bates 的这六种方法有以下观察:在这六种方法中,只有脚注追踪和引用搜索是点对点的。在另外四种方法中,用户感兴趣的是文档组(在作者搜索中是作者组,在其余方法中是主题组)。因此,为了最好地支持所有浏览模式,我们需要一种既能支持点对点连接(如同标准图那样)又能支持 N 元连接(n-ary connections)的结构。超图正是这种结构。
4 方法
在本节中,我们讨论三种 HoT 构建方法及其相应的实现。第一种方法“All-Words”(全词法)将文档中的所有单词视为一个超边,然后使用 TF-IDF 分数对超边进行加权和剪枝。第二种方法“LLM-Doc”和“LLM-Sentence”利用大语言模型(LLMs)在句子和文档两个层面提取主题。最后,我们要提出的基于相似度的两步法结合了语义相似度测量与 LLM 引导的主题提取,试图解决前述方法的弱点。
在讨论这些方法时,我们会提到使用 LLM 和句子转换器(sentence transformer)。在我们的实现中,我们使用 llama3-8b-instruct [12] 作为我们的 LLM。对于句子转换器,我们利用 sentence transformers 包 [24],并选用 All-MiniLM-L6-v2 作为我们的特定模型 [33]。这些方法的完整代码,包括 LLM 提示词(prompts),将在 GitHub 上公开。
4.1 All-Words(全词法)
这种方法背后的核心思想是将文档之间共享的“所有单词”(All words)视为一个潜在的超边。自然地,包含所有单词对于导航或分析来说是多余的。因此,我们只包含那些具有较高平均 TF-IDF 分数的单词(即按平均 TF-IDF 衡量的前 n% 的超边)。

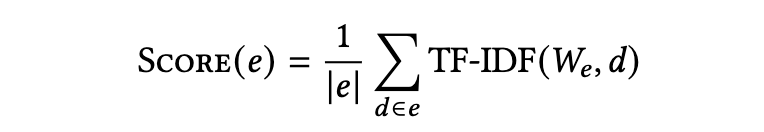
4.2 LLM-Doc 和 LLM-Sentence
先前的工作表明 LLM 可用于创建 HoT [4]。具体而言,他们将每个文档拆分为句子,并提示 LLM 提取每个句子的主题并将其输出为列表。先前的工作指出,这种方法产生的主题数量比文档数量多出两个数量级。为了避免这种情况,我们提出了一种额外的基于 LLM 的 HoT 构建方法。该方法与先前的方法大体相似,不同之处在于主题是在文档级别而非句子级别提取的。
4.3 两步相似度(Two-Step Similarity)
对先前方法的初步调查表明,虽然 LLM 显示出前景,但也并非没有问题。具体而言,句子级别的方法倾向于产生过多的超边,而文档级别的方法则倾向于产生过少的超边。为了使 LLM 专注于提取既具有细粒度细节又与集合相关的主题,我们建议首先选取句子对,然后使用 LLM 提取这些预定句子之间的语义链接。
为了确保我们只考虑最具信息量的句子,我们使用了一个结合 TF-IDF 分数和嵌入余弦相似度的两步过滤过程。我们计算每个句子的平均 TF-IDF 分数,从而可以用一个单一的数字来表示句子的重要性。平均 TF-IDF 分数如下所示,其中

的缓存 TF-IDF 向量表示:
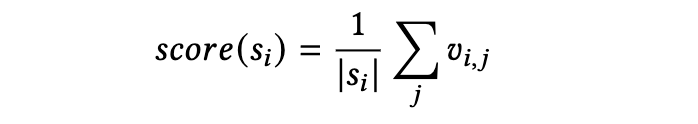
我们计算每个文档中每个句子的上述分数。然后,我们按文档对分数进行排序,并仅保留每个文档中排名前 k 的句子。
在过滤步骤之后,我们接下来希望利用句子嵌入来为每个句子寻找最相似的句子。尽管由于先前的过滤步骤该方法已经提速,但我们仍使用 FAISS 的 GPU 版本 [15] 以确保高效执行。最后,根据以下逻辑选择前 k 个句子对:首先尝试选择余弦相似度最高的句子对,且不重复句子或文档;如果无法做到,则允许重复以填补剩余的句子对。选择这种方法而不是简单地按余弦相似度选择前 k 个对,是为了促进连接的多样性。
对于每一对句子,我们使用 LLM 提取共同主题。每个共同主题成为一个超边,包含来自该对的文档。任何后续被发现也共享此主题的文档都会相应地添加到该超边中。与“All-Words”方法不同,该方法在无需任何额外剪枝的情况下就相当可用。然而,该方法确实会产生大量基于仅由两个文档共享的主题的语义链接。虽然超边拥有两个成员是明确定义的,但人们也可能希望剪枝这些大小为 2 的超边,以聚焦于更实质性的主题组。我们在结果中探讨了剪枝版本和未剪枝版本。
5 评估 HoT 构建
如何评估 HoT 构建是一个具有挑战性的问题。确实,目前尚无先前的定量指标能够表明用于浏览目的的 HoT 的质量。这一挑战因存在许多潜在有用的创建超边的方法而变得更加复杂。为了缓解这一问题,我们引入了一种通用方法论,用于定量评估 HoT 结构的质量。

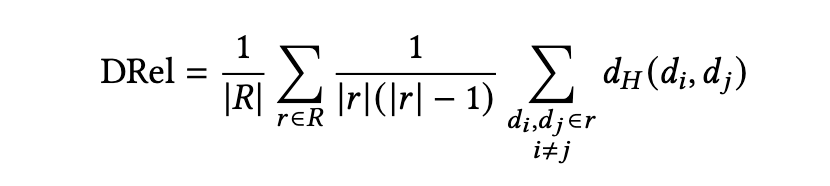

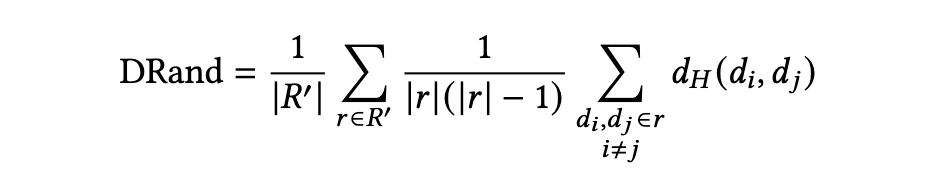

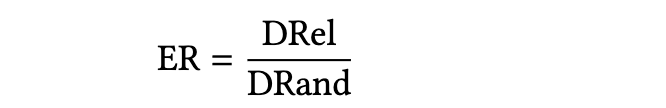
努力比为 1 表示相对于随机导航没有优势;低于 1 的值表示相关文档比随机文档距离更近;高于 1 的值则表明相关文档之间的距离反常地比随机集合更远。直观地说,如果 DRel = 2 且 DRand = 5,那么 ER = 0.4,这意味着在相关节点之间导航所需的平均跳数仅为在随机节点对之间导航所需跳数的 40%。
这个努力比将是我们用于评估的主要指标。值得重申的是,这种评估方法和这些指标对于评估 HoT 构建是非常通用的。虽然我们在实验中选择了一类特定的数据集,但有许多方法可以找到具有已知相关性的文档。一些例子包括网络日志、综述论文和问答数据集。
5.1 努力比的属性
努力比具有若干关键特性,使其非常适用于评估超文本(HoT)的构建。在本节中,我们将花一些时间逐一探讨这些特性。我们首先从几个有用的定义开始。

换句话说,如果超边中至少有 α 比例的(无序)文档对彼此相关,则该超边是 α-相关性对齐的。同样地,如果少于 β 比例的文档对彼此相关,则该超边是 β-非相关性对齐的。请注意,分子和分母计算的都是无序对,因此该比率位于 [0,1] 之间。
定义 5.3(饱和度度量)。 对于超图 H,我们定义以下两个饱和度度量:
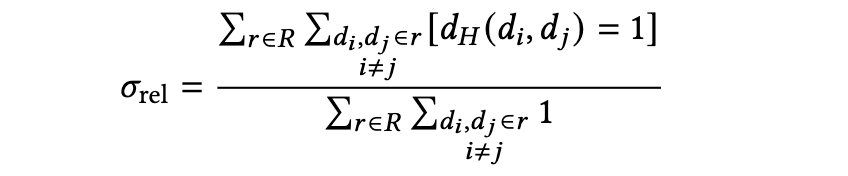
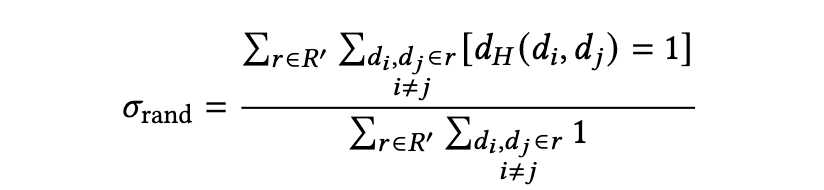




这里的关键见解在于,除了在超图结构高度不平衡且随机节点比相关节点连接得更紧密的异常情况下,努力比会对添加那些连接了更多不相关文档(而非相关文档)的超边进行惩罚。这正是我们在导航指标中所期望的行为。
导航指标的另一个理想特性是能够惩罚过载。也就是说,我们不想给那些仅仅通过滥加边来实现良好连接的方法打高分。我们需要一个能对超图中边的总数产生一定正则化作用的指标。这就引出了我们的下一个结果。

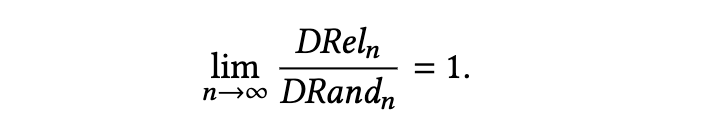

5.1.3 努力比的局限性。 虽然努力比允许对 HoT(超文本主题)进行定量评估,但它确实有两个关键的局限性。首先,如果超图包含不连通的组件,它的定义就不明确(或无法良好定义)。这是该指标基于节点间距离这一事实的直接结果。因此,在考虑努力比时,应始终结合考虑项目不连通的严重程度。出于这个原因,我们提出了另一个指标:相关断开比例(Relevant Disconnect Proportion, RDP)。这个指标仅仅是指彼此不连通的相关文档对的比例。结合努力比来看,RDP 让我们能够知道 HoT 构建方法是否本质上是通过选择偏差来“欺骗”该指标。

6 实验结果
在我们的实验中,我们在一个 MultiHop-RAG 问答数据集 [30] 上使用了第 5 节提出的指标。该数据集包含 609 篇文章和 2556 个多跳查询,这些查询分布在 2 到 4 篇文档之间。虽然 MultiHop-RAG 论文未指明任何主题分布,但人工检查显示其主题包括时事、金融市场与股票、体育赛事以及电子游戏。出于实验目的,我们将每个与文档关联的查询视为一组彼此相关的文档集合。这意味着我们的集合 RR(如第 5 节所述)是一个包含 2556 个元素的集合族,其中每个成员集合的大小为 2 到 4。
我们的实验揭示了不同 HoT 构建方法在性能上的有趣差异。结果总结于表 1。在深入结果之前,首先值得注意每种方法的相对计算需求。两种"全词"(All-Words)方法相当轻量,不需要任何具备机器学习能力的硬件。而基于 LLM 的方法计算需求则高得多,需要大量的 LLM 调用。两步式 LLM 方法同样需要 LLM 调用,但由于存在过滤步骤,其调用量显著减少。
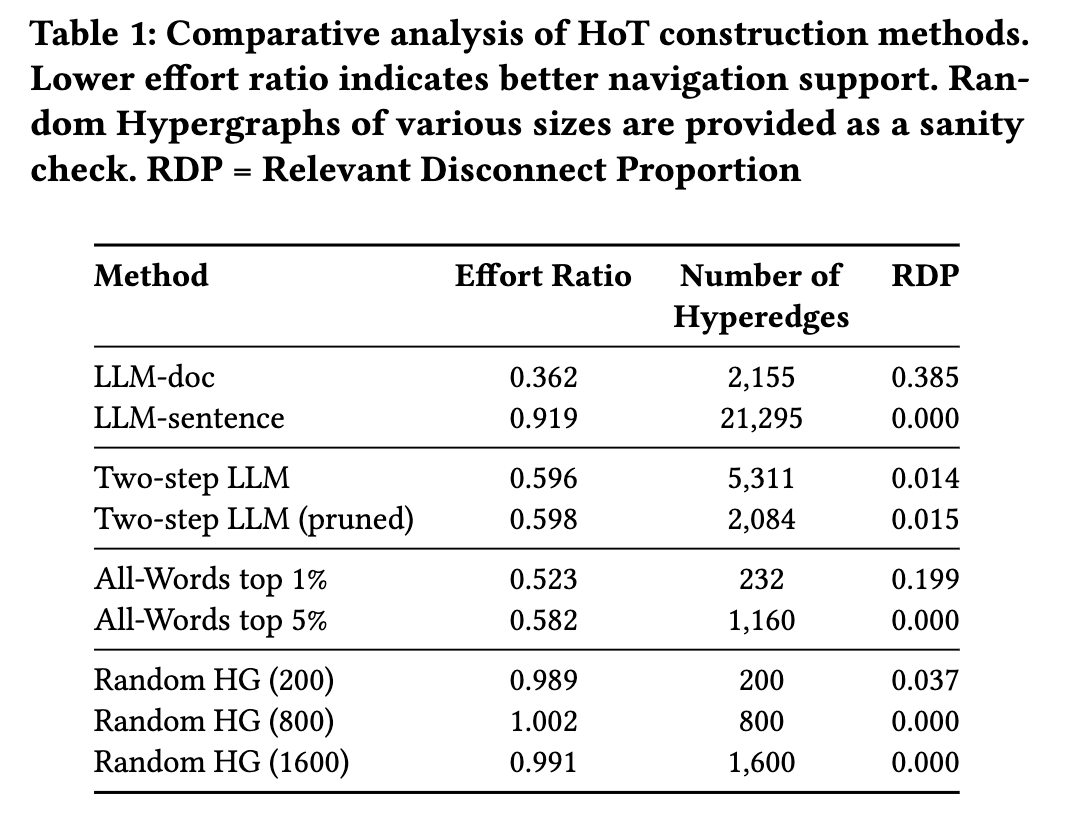
LLM 类方法表现出最大的方差:其中句子级方法和文档级方法分别获得了最高(非随机)和最低的努力比。这或许并不令人意外,因为这两种方法在超边数量上也显示出最大差异——句子级方法的超边数量比文档级方法高出一个数量级。虽然文档级方法在所有提出的方法中实现了最低的努力比,但值得注意的是,近 40% 的相关文档对处于断开状态。由于断开的文档无法计入平均距离(否则会使平均距离变为无穷大),该方法具有最低的努力比可能表明它仅能建立那些"容易"的连接。断开率较低的方法必须处理这些"困难"的连接,而这些连接通常相距更远,因此会对其平均相关距离造成惩罚。
相比之下,"全词"方法和"两步"方法均取得了努力比在 0.50 至 0.60 范围内的结果。尽管"全词"方法的超边数量较少,但两种变体均表现良好。需要注意的是,"全词"方法创建的语义链接是单词主题,这是其语义链接的质量局限。例如,除非一个人能轻易通过单个名字被识别(如柏拉图),否则该方法无法很好地捕捉与该人物相关的主题。"两步"方法则没有这一缺点。由于"两步"方法的运行时间远比"全词"方法长,最佳方法的选择可能取决于用户的限制条件和使用场景,因为每种方法各有优劣。在预算受限的场景下,或在主题细微差别不太重要的场景中,top-5% 的"全词"方法在努力比上仅比"两步"方法高出 0.02,但其超边数量仅为后者的五分之一,且无需调用 LLM。
7 局限性
作为对超文本主题(HoT)构建的初步研究,我们仅在一个数据集上研究了 HoT 构建。在未来,重要的是通过使用所提出的模拟评估策略在更多数据集上进行实验,以进一步验证我们的发现。一旦构建了 HoT,就可以应用多种算法(例如随机游走、路径发现、异常发现)对 HoT 进行后处理,以揭示文本数据中许多有趣的潜在语义模式(例如争议分析、对比分析或关联分析)。此外,虽然定量评估使我们能够比较多种 HoT 构建方法,但从用户角度来看,HoT 构建的实际效用仍需通过用户研究进行进一步评估。
8 结论与未来工作
在本文中,我们研究了如何构建文本超图(Hypergraph of Text, HoT),以语义化地组织任意文本集合,从而支持导航。我们研究了三种执行 HoT 构建的方法,包括利用大语言模型(LLM)的方法。为了定量评估浏览效果,我们提出了一种新颖的评估指标:努力比(effort ratio)。我们的实验结果表明,虽然各种方法都能够生成潜在有用的链接,但每种方法各有优劣。以 HoT 为基础,我们的工作朝着开发一种通用技术迈出了一步,该技术旨在支持用户浏览任意文档集合,具有广泛的应用前景。一个重要的下一步是通过真实的用户研究进一步验证这些指标和算法。另一个有前景的未来方向是将所提出的算法应用于特定的应用场景,例如构建 HoT 来组织搜索结果、研究论文集合、组织由一群人创建的任何共享数字图书馆(例如班级中的学生论文),或组织任何个人内容文件夹。
原文链接:https://arxiv.org/pdf/2604.25906
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号