网络的动态处理 Dynamic Treatment on Networks

网络的动态处理 Dynamic Treatment on Networks

CreateAMind
发布于 2026-05-11 20:14:01
发布于 2026-05-11 20:14:01
Dynamic Treatment on Networks
网络的动态处理
https://arxiv.org/pdf/2605.06564
《Dynamic Treatment on Networks》论文重点概述
在网络环境中,有效的动态干预分配不仅需决定对谁干预(whom),还需决定何时干预(when),以通过网络溢出效应放大政策影响。早期对高连接度节点的干预可能触发传播级联,从而改变后续周期值得定向的目标节点。现有网络干扰下的干预策略多为静态,而动态干预框架通常忽略网络结构,本文旨在整合这两个视角。
方法论:Q-Ising 三阶段框架
论文提出Q-Ising方法,包含三个核心阶段:
- 动态伊辛模型推断(Stage 1)
- 采用贝叶斯动态伊辛模型(Bayesian dynamic Ising model),从单一观测面板数据估计网络采纳动态
- 模型允许非对称交互和时序依赖,避免传统平衡态伊辛模型中难处理的配分函数问题
- 通过连续尖峰-平板先验(spike-and-slab prior)实现交互参数稀疏性,支持不确定性量化
- 状态构建与增强(Stage 2)
- 将估计的条件采纳概率作为潜在状态,构建低维的Q-Ising状态表示
- 状态包含两部分:前向模型驱动的"无干预采纳概率"与后向观测驱动的"历史采纳概况"
- 在"箱"(bin)级别聚合节点信息,平衡统计覆盖度与目标粒度
- 离线强化学习策略学习(Stage 3)
- 采用保守Q学习(Conservative Q-Learning, CQL)从历史数据中学习动态箱级策略
- 通过后验采样构建集成策略,实现决策不确定性量化
- 支持可解释的溢出效应估计与置信评估
理论贡献
- 为有限样本下的Q-Ising方法提供遗憾上界(regret upper bound),该界可分解为三部分:
- 标准离线强化学习的不确定性
- 网络抽象误差(聚合与分箱引入)
- 第一阶段伊辛状态估计误差
- 证明贪心策略(仅最大化即时奖励)在网络动态下不一定最优,凸显动态规划的必要性
实验验证
- 合成数据:在随机块模型(SBM)上模拟异质SIS(Susceptible-Infected-Susceptible)传播动态
- 设计对抗性场景:高影响力节点聚集于小社区,无法仅凭度中心性识别
- Q-Ising能从离线数据中识别高影响力群体,并随有机传播自持性自适应调整干预预算
- 真实数据:印度卡纳塔克邦村庄小额信贷网络(Banerjee et al., 2013)
- 在实证邻接矩阵上模拟SIS动态
- 结果:在夏普比率等指标上优于静态中心性基准方法
主要优势与局限
优势:
- 首次将贝叶斯动态网络建模与离线强化学习统一,解决"单轨迹、无实验"的现实约束
- 提供可解释的参数估计(直接效应、持久性、邻居溢出、跨箱影响)
- 通过后验集成实现决策不确定性量化,支持审慎策略部署
局限:
- 计算复杂度较高(高斯过程拟合成本为
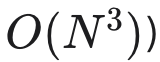
- 方法略偏向探索,可通过增加利用阶段子迭代次数缓解
- 当前聚焦二值结果与单干预设定,多目标、连续干预等扩展留待未来工作
核心结论
在网络干扰下,时序策略与目标选择同等重要。Q-Ising通过"模型推断→状态抽象→策略学习"的三阶段设计,在有限观测数据下实现动态、自适应、可解释的网络干预,为公共健康、营销推广、平台运营等领域的序列化决策提供了新范式。


摘要
在网络中,有效的动态干预分配不仅需要决定对谁进行干预,还需要决定何时干预,以便通过溢出效应放大政策影响。在连接良好的节点上进行早期干预可触发级联反应,从而改变下一周期值得定向的目标节点。现有的网络干扰下的干预策略大多是静态的,而动态干预框架通常完全忽略网络结构。我们整合了这两种视角,提出 Q-Ising 方法,这是一个三阶段流程:(i) 通过贝叶斯动态伊辛模型从单一观测面板数据估计网络采纳动态;(ii) 用连续的后验潜在状态增强干预采纳历史;(iii) 通过离线强化学习学习动态策略。贝叶斯机制实现了对动态决策的不确定性量化,生成了具有可解释溢出估计的后验集成策略。我们提供了一个有限样本遗憾上界,该上界可分解为标准离线强化学习不确定性、网络抽象误差以及伊辛状态估计的第一阶段误差。我们将该方法应用于印度村庄小额信贷网络数据,以及在模拟异质易感-感染-易感(SIS)动态下的合成随机块模型,并证明自适应定向策略优于静态中心性基准。
1 引言
当决策者在网络上制定动态干预策略时,核心问题不仅是对谁进行干预,还包括何时干预。在网络干扰下,单元接受干预的顺序决定了哪些节点将首先传播溢出效应,以及这些效应将如何随时间累积放大。一项选择了正确干预节点但忽略其顺序的策略,其表现可能严格劣于进行战略性排序的策略。
为了理解顺序为何重要,请考虑一个在社交网络上推广产品的营销活动,其有限预算被分配在多个周期中。如果决策者首先干预有影响力的用户,第二周期的行动就会改变:决策者现在可以定向那些已暴露但尚未采纳的邻居,或者可以在网络的其他区域重新开始布局。第二周期的最优行动取决于第一周期所取得的成果。类似的排序问题也出现在病毒式营销 [Kempe et al., 2003, Domingos and Richardson, 2001]、平台用户参与活动以及公共卫生干预 [Bubar et al., 2021, Buckner et al., 2021] 中。
该设定中的核心困难在于,决策者无法进行受控实验,且仅限于在历史策略下的一条单一观测轨迹。这排除了需要能够直接访问(oracle access)扩散机制的在线影响力最大化(IM)[Kempe et al., 2003] 算法 [Singh et al., 2022]。同时,由于动态决策的特性,静态策略通常并非最优。为解决此问题,决策者需要两样东西:首先,一个描述网络行为演化的自适应模型;其次,一种利用该模型按顺序选择干预措施的方法。
对于第一部分,我们使用动态伊辛模型 [Yang, 1992]。该模型旨在根据节点自身、其邻居及过去干预的当前状态,估计每个节点下一状态的条件概率。与需要难以处理的配分函数的平衡态伊辛模型不同,动态公式允许使用易于处理的逐节点似然函数。对于第二部分,我们使用离线强化学习(RL),这是一种从历史数据中学习动态决策规则的方法,无需进行实验 [Levine et al., 2020]。作为一项关键贡献,我们将估计的条件概率视为离线强化学习的潜在状态。最后,为了评估这些动态决策的不确定性,我们提供了一个用于不确定性量化的集成框架。这一三阶段过程为网络干扰下的动态策略提供了一个统一框架。
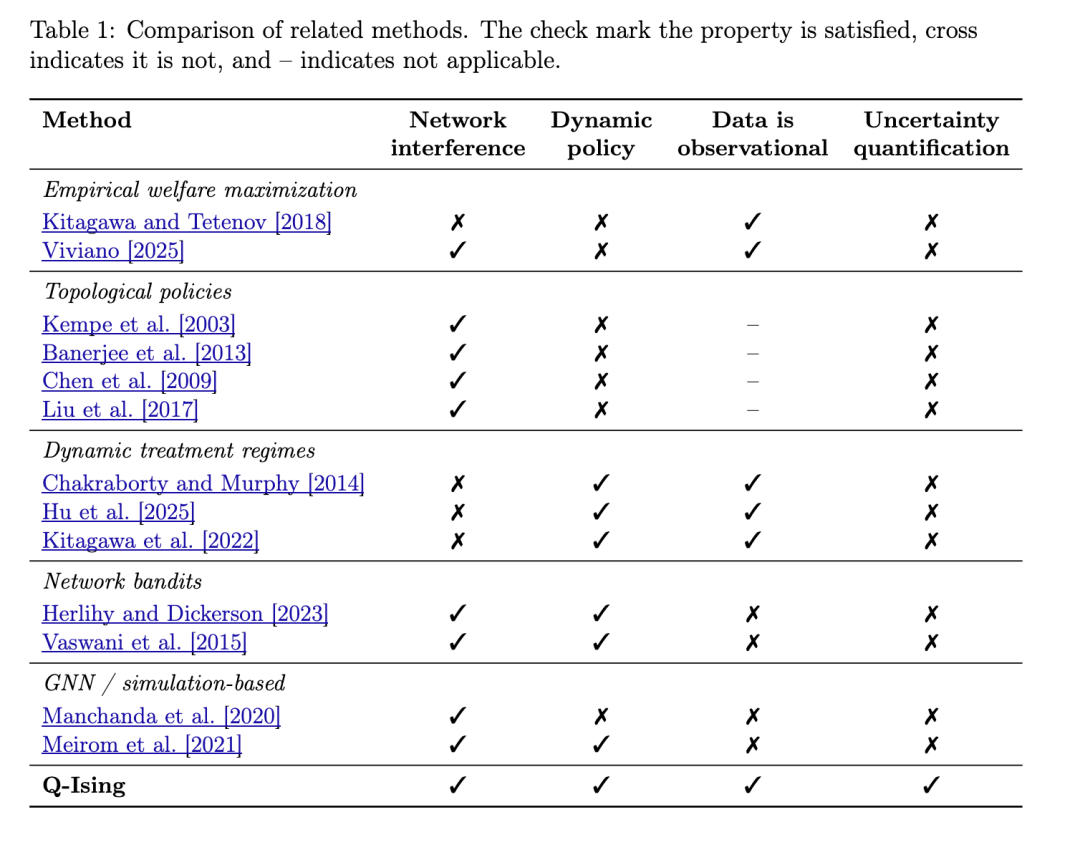
相关工作跨越多个领域。一些方法为单周期干预学习福利最大化策略 [Kitagawa and Tetenov, 2018, Viviano, 2025],以及基于中心性和友谊悖论等网络拓扑结构的网络感知定向方法 [Banerjee et al., 2013, Kempe et al., 2003, Christakis and Fowler, 2010, Kim et al., 2015, Chen et al., 2009, Liu et al., 2017]。动态治疗方案方法 [Murphy et al., 2001, Chakraborty and Murphy, 2014, Hu et al., 2025, Adusumilli et al., 2019, Kitagawa et al., 2022] 为动态决策提供了工具,但未利用网络结构。Restless 多臂老虎机为预算约束下的动态策略提供了框架 [Whittle, 1988, Weber and Weiss, 1990, Mate et al., 2020],但假设单元独立演化。最近的扩展将臂嵌入网络中,允许干预使其邻居受益 [Herlihy and Dickerson, 2023, Ou et al., 2022, Vaswani et al., 2015, Gleich et al., 2025],但这些方法假设溢出机制已知或需要重复实验。类似地,一些工作需要纳什均衡和已知动态 [Kitagawa and Wang, 2023a]。最近的图神经网络(GNN)方法取得了较强的实证性能,但也需要在线实验或已知动态 [Manchanda et al., 2020, Sun et al., 2018, Meirom et al., 2021, Feng et al., 2024]。附录 A 的表 1 提供了其中一些方法的对比。
我们提出 Q-Ising 方法,将贝叶斯动态伊辛推断与离线强化学习相结合,用于网络干扰下的序列决策。在方法论上,我们通过将估计的网络动态视为潜在状态,将网络干扰下策略学习的难题转化为标准的离线强化学习问题。在理论上,我们给出了悲观型离线学习下有限时间视界(finite-horizon)Q-Ising 的遗憾上界,并表明该上界可分解为标准离线强化学习不确定性、网络抽象误差和第一阶段误差。
我们在两种实验设定下将 Q-Ising 应用于易感-感染-易感(SIS)动态 [Kermack and McKendrick, 1927, Hethcote, 2000],这是一种广泛使用的复发性传染模型 [Bass, 1969, Jackson and Rogers, 2007, Bohner and Streipert, 2016]。其一为随机块模型(SBM),其中最具影响力的节点构成一个较小的社区,仅凭节点度无法将其识别出来,这使得该设定对基于中心性的方法构成了挑战。在该设定中,Q-Ising 仅凭离线数据即可识别出高影响力群体,并随着自发传播达到自我维持状态而自适应地调整干预预算。其二,我们在来自印度卡纳塔克邦的真实小额信贷网络 [Banerjee et al., 2013] 上验证了 Q-Ising 的实际价值,并在实证邻接矩阵上模拟了 SIS 动态。在这两种设定下,Q-Ising 的表现均达到或优于最佳基线方法,提供可解释的系数估计以揭示底层动态机制,并量化了在每个决策点上推荐干预措施的不确定性。基于图神经网络(GNN)的影响力最大化方法均不具备上述特性 [Manchanda et al., 2020, Sun et al., 2018, Meirom et al., 2021, Feng et al., 2024]。
本文其余部分结构如下:首先,在第 2 节中正式定义问题。接着,在第 3 节介绍我们的方法论。在第 4 节中,我们给出推导悲观型次优性所需的假设,并呈现遗憾上界。最后,在第 5 节进行实验验证。
2 框架与问题表述
我们研究固定网络上具有二元结果的动态干预问题。全文中,
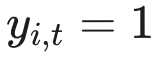
表示节点 i 在时期 t 采纳了某种产品或行为;已采纳的单元后续可能会退出,因此决策者不仅必须决定对谁进行干预,还必须决定何时干预。

这是在历史策略下收集的。这是来自一个真实网络的单一长面板这一具有重要实践意义的设定,其中 M 和 X 全程固定且已知。我们保留节点级行动,因为第一阶段估计直接干预和邻居溢出效应。



3 方法论
Q-Ising 方法分三个阶段进行。首先,我们从面板数据 DD 估计一个动态伊辛模型。其次,我们使用拟合好的模型构建低维的 Q-Ising 状态。第三,我们应用离线强化学习(RL)在这些状态上学习一个动态的箱级策略。
3.1 第一阶段:动态伊辛推断
标准的平衡态伊辛模型需要计算难以处理的配分函数并要求对称的相互作用。我们转而使用一个动态条件模型,类似于伊辛模型的逻辑伪似然估计 [Ravikumar et al., 2010],该模型允许非对称影响和时间依赖性。定义在时间 tt 位于箱 Bk 中的节点 ii 的线性预测因子:
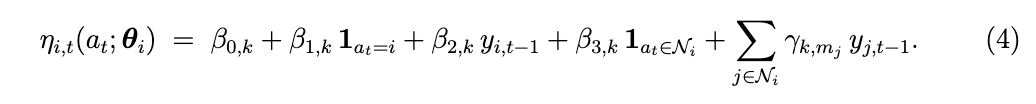


先验与稀疏性。 对于交互参数,我们施加一种连续的尖峰-平板先验,以促进同辈效应中的稀疏性 [Ročková and George, 2014, George and McCulloch, 1993]:
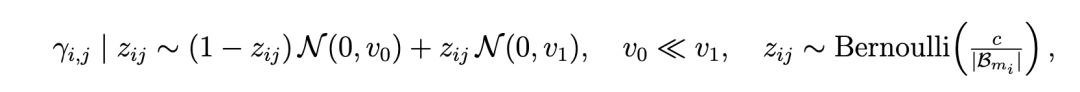

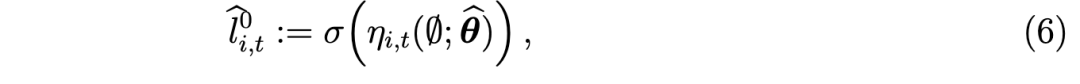

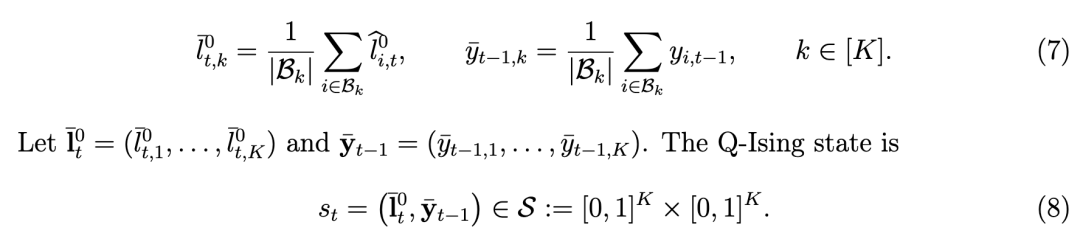
第一个分量是前瞻性的且基于模型;第二个分量是当前决策之前已实现的箱级采纳概况。
3.2 第二阶段:离线 Q 学习


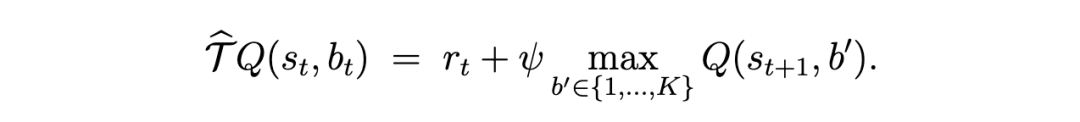

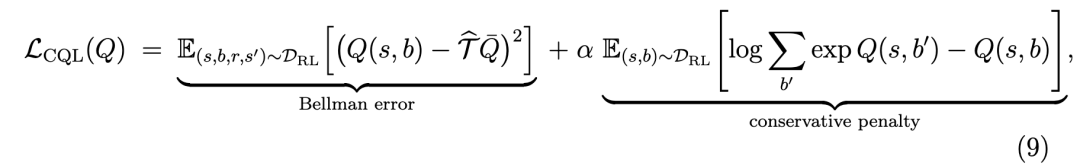

3.3 第三阶段:通过后验采样的集成策略与不确定性量化

4 理论
我们为 Q-Ising 的一种理想化有限视界 PEVI(悲观价值迭代)版本提供了有限样本遗憾保证。第 3.2 节中的经验算法采用 CQL 作为同一悲观主义原则的可扩展实现;以下定理分析了该 PEVI 对应算法 [Jin et al., 2021]。





5 实验
我们在两种网络机制下评估 Q-Ising:5.1 小节中的随机块模型(SBM)以及 5.2 小节中来自印度卡纳塔克邦 [Banerjee et al., 2013] 的小额信贷网络。在这两种情况下,我们都基于异质的、合成的 SIS(易感 - 感染 - 易感)动态模拟观测数据。这些动态的设计旨在对基于度数的方法构成挑战(adversarial)。最优策略要求尽早干预高度易感节点所在的社区,从而引发自然的组内传播,然后在饱和消除高度易感组中进一步干预的边际收益之前,将资源重新分配到其他社区。一个按度数对节点排序的排名器会将其预算集中在中心节点上,但这些节点未必是易感节点。无论是“干预谁”还是“何时干预”,仅凭度数统计量都无法复原,这需要自适应决策。

5.1 随机块模型中的实验

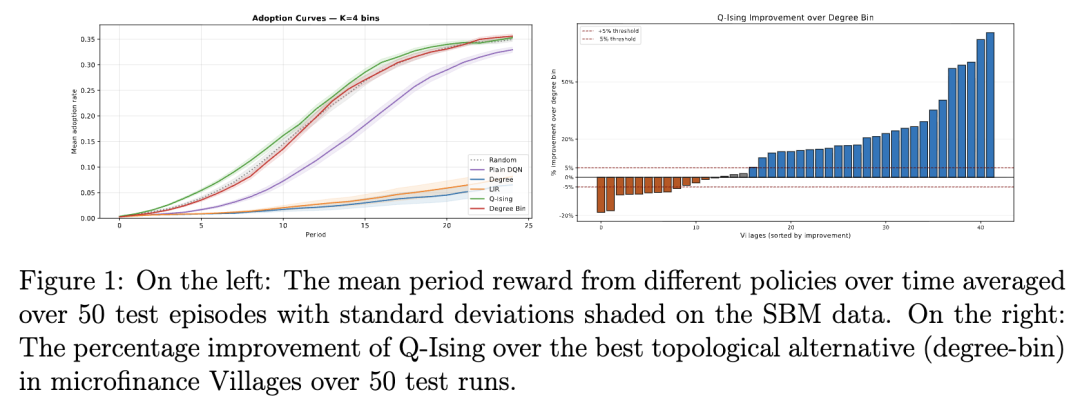
在该设置中,随机策略优于大多数拓扑启发式方法,因为它偶尔会碰巧向高度易感的区块进行播种。因此,与确定性承诺于错误目标的方法相比,它更频繁地匹配到正确的目标。Plain DQN 学习到的种子优先排序与 Q-Ising 在定性上相似,但初始上升速度较慢。这表明伊辛增强在早期活动窗口期最具价值,此外还能提供后验集成策略、可解释的参数和不确定性量化。
5.2 印度小额信贷村庄中的实验

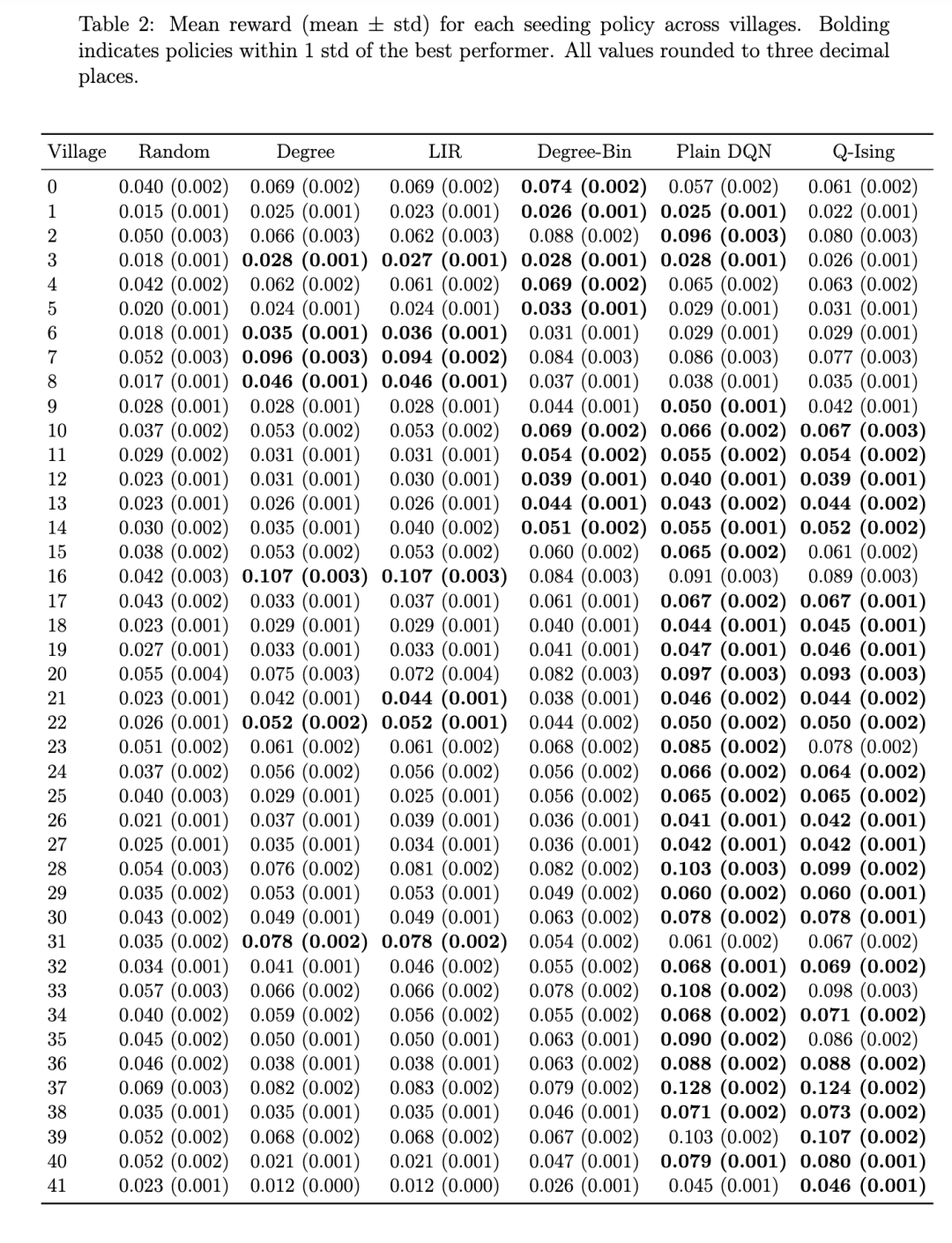
附录 A 中的表 2 报告了结果。Q-Ising 相较于最佳非自适应策略(即 Degree-bin)的性能提升的描述性图表可在图 1 中找到。Q-Ising 有效地学会了将其初始干预集中在具有高传播率的社区以及与其他社区连接良好的社区上,从而产生叠加的自然传播。然后,它根据活动水平自适应地干预其他社区。在模块度较低的村庄中,其性能提升更为显著,因为 Q-Ising 依赖于识别有影响力的社区并自适应地定向剩余社区。在高度模块化的网络中,溢出效应叠加较少,削弱了 Q-Ising 的优势。

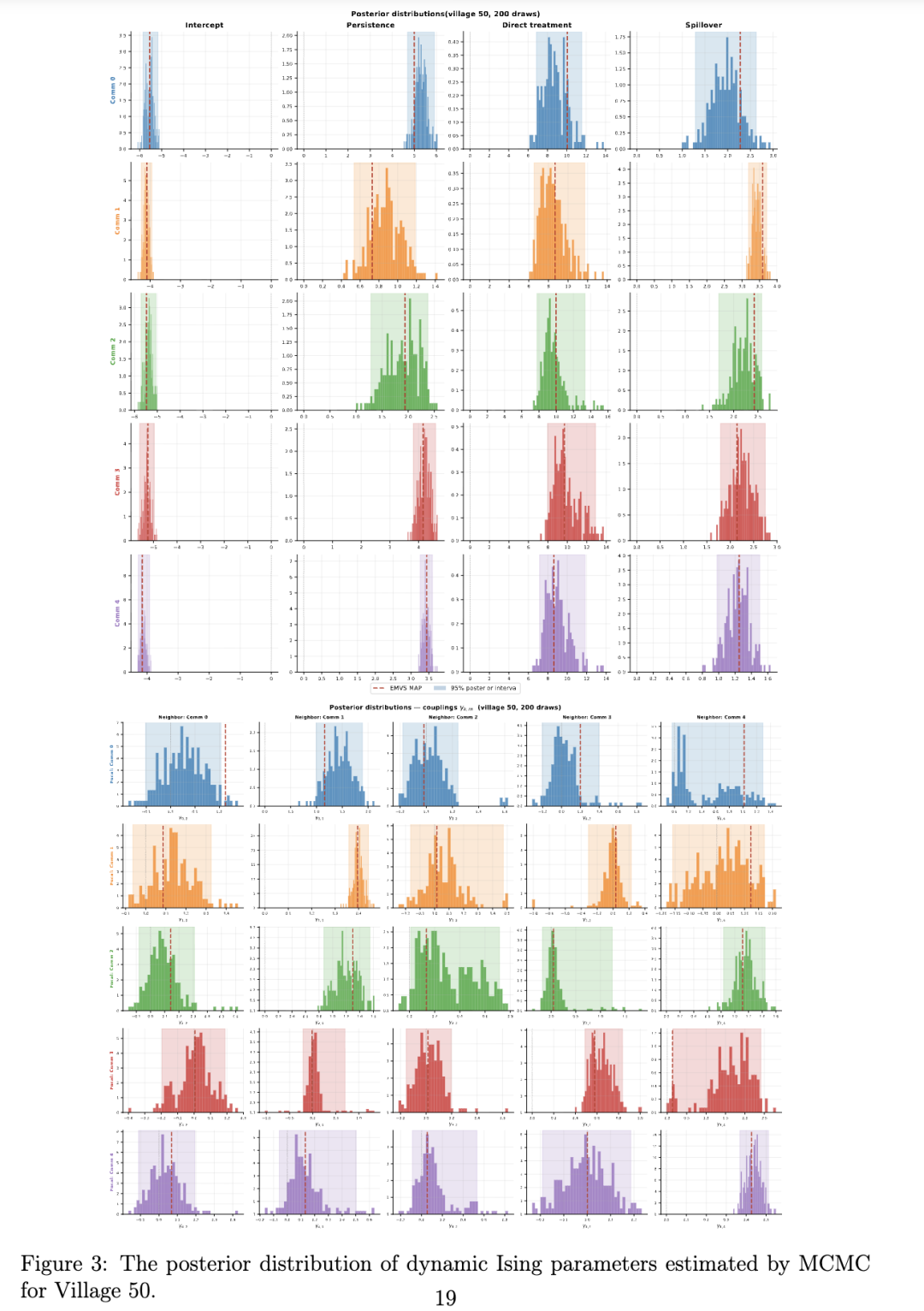
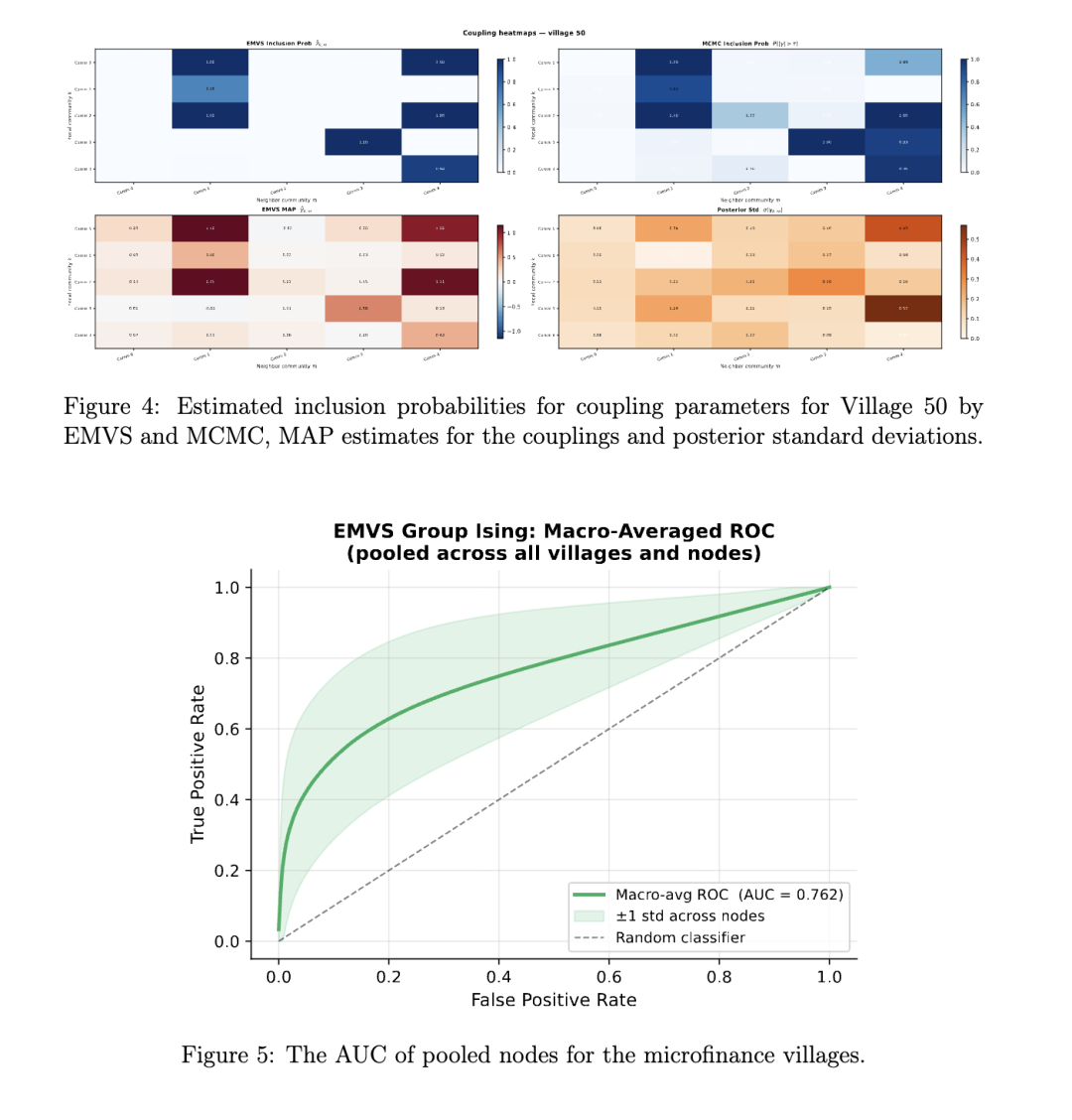
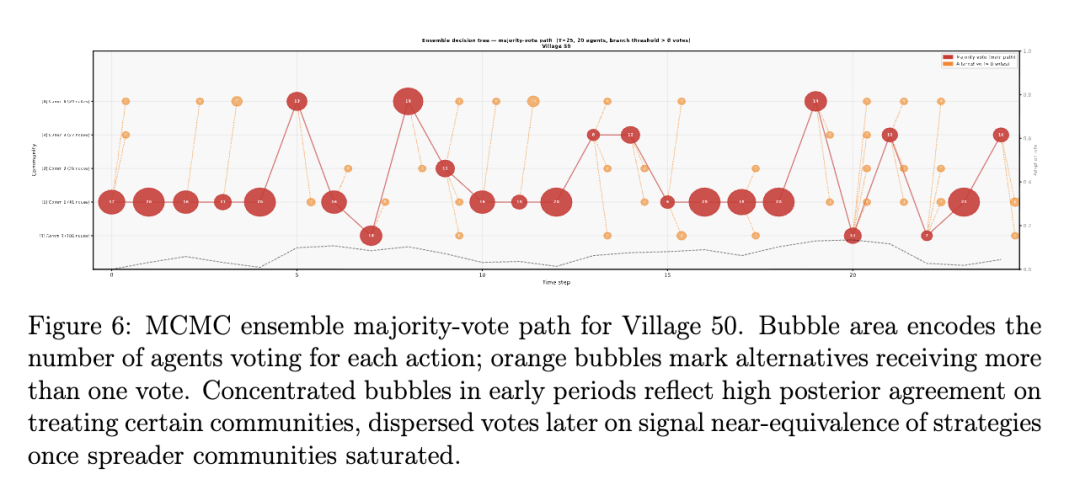
借助集成策略方法,Q-Ising 还能学习策略的不确定性。参数估计(500 次迭代)大约需要 1 分钟的挂钟时间。对应 20 个后验抽样的 20 个智能体的训练大约需要 20 分钟。通常,多数投票路径始于对高传播率社区的近乎一致认同。在传播者社区基本饱和后,多数票转向多个替代选项。这种分散性识别了接近临界阈值的时期,并作为一种战略性不确定性的度量,而点估计策略往往会无形中掩盖这种不确定性。展示示例村庄集成策略轨迹的图表可在附录 B 中找到。

6 结论
本文提出了 Q-Ising,这是一个基于观测面板数据、在网络干扰下进行动态干预分配的框架。这是网络中离线动态策略学习的首批尝试之一,尽管该方法对于公共卫生、小额信贷以及其他实验成本高昂或不可行的场景具有重要的现实意义。我们的方法将网络动态的贝叶斯伊辛模型与保守 Q 学习相结合,所得策略不仅包含结构参数估计和后验不确定性,而且在性能上能与无模型离线强化学习相媲美。
该框架还有许多可改进之处。目前该框架每个时期仅对单个节点进行干预(播种);多节点预算扩展是未来的开放研究方向。该方法还需要足够长的观测面板数据以实现充分的状态 - 动作覆盖,且当行为策略与目标策略之间存在严重的分布偏移时,其行为表现需要进一步研究。对于结合网络信息的状态增强,当数据充足时,可以使用高阶伊辛相互作用或其他网络表示形式(例如图神经网络)。我们的实验在 SIS(易感 - 感染 - 易感)动态上展示了该框架,但该流程也适用于其他采用同步更新的传染模型。其积极的应用场景包括公共卫生干预、小额信贷推广以及低资源环境下的信息宣传活动。同样的框架也可被用于利用社会影响力以达到商业或政治目的,我们要鼓励从业者据此反思其部署背景。
原文链接:https://arxiv.org/pdf/2605.06564
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号