三无项目导致MongoDB 持续1406% CPU 问题解决

三无项目导致MongoDB 持续1406% CPU 问题解决

AustinDatabases
发布于 2026-05-12 10:42:13
发布于 2026-05-12 10:42:13
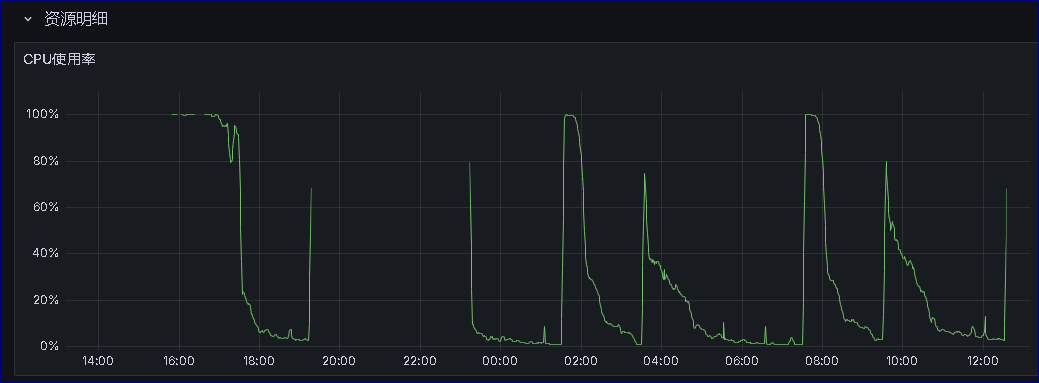
问题库CPU监控
这是一个MongoDB数据库版本是3.2,我也是从项目的新负责人了解到还有这样一个MongoDB,自建,单点,现在的情况就是CPU高,其他的项目的负责人也是不清楚,这是一个很老的项目,当时负责这个项目的所有人都离开了,所以也无法去问任何的问题,只能靠自己来摸索。
处理这样的问题,首先先看系统和MongoDB的详细信息。
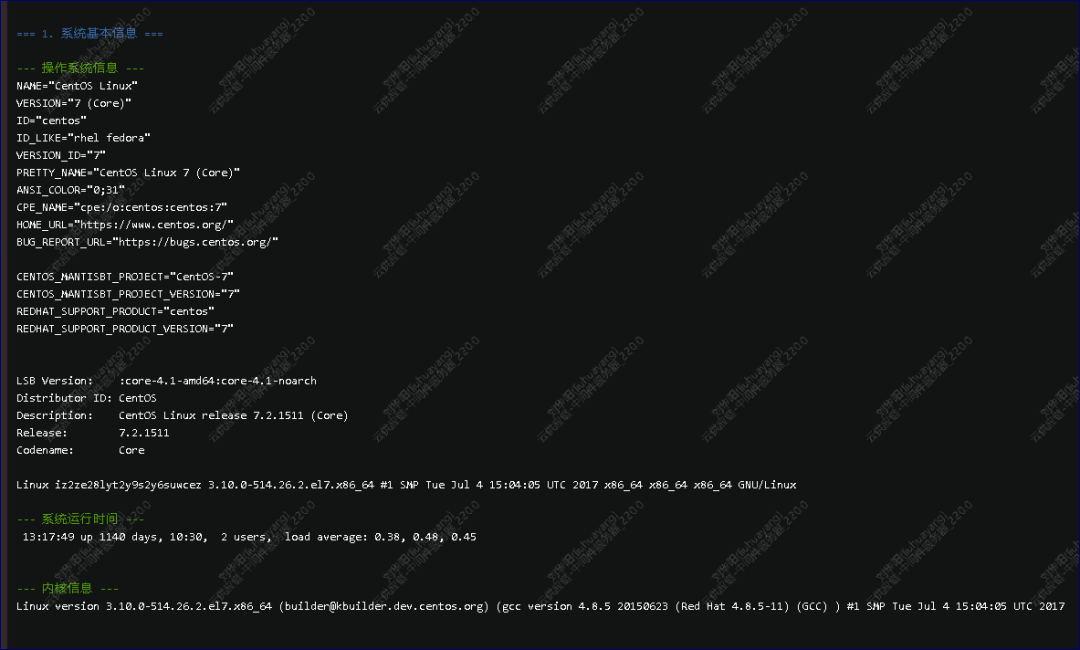
系统信息
通过操作系统信息收集的脚本
获得了操作系统的版本信息CPU的信息
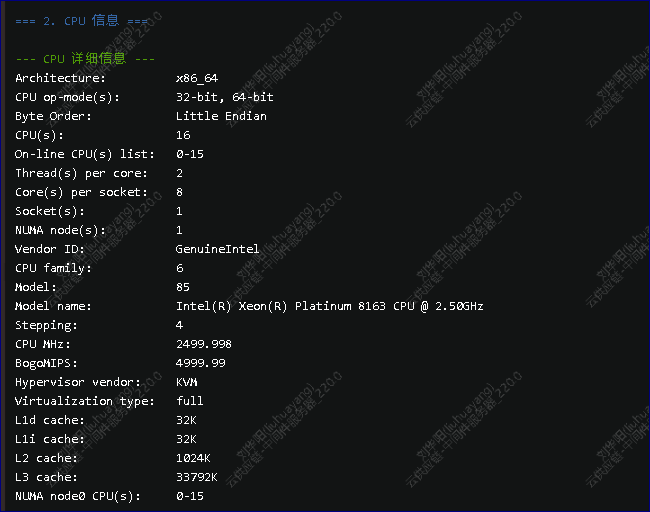
CPU
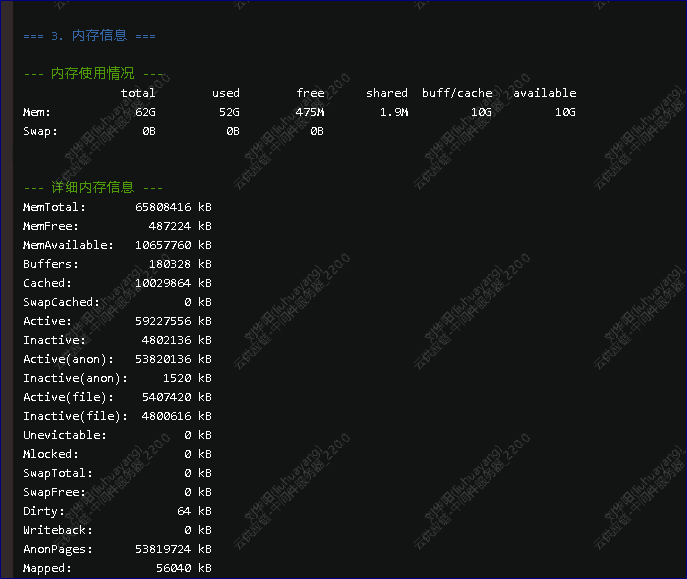
内存信息

磁盘信息
从脚本中的其他信息中获得了防火墙,TOP PROCESSES TOP MEM USERD 等信息,从中可以看到整体是最消耗CPU和内存资源的是MongoDB,配合之前的监控图CPU 基本打到100% 大概率也是这个mongodb所为。
dbpath=/usr/local/mongodb-linux-x86_64-3.2.0/db
logpath=/usr/local/mongolog
logappend=true
fork=false
#fork=true
port=27017
directoryperdb=true
journal=true
#storageEngine=wiredTiger
#wiredTigerJournalCompressor=snappy
wiredTigerCollectionBlockCompressor=zlib
wiredTigerCacheSizeGB=40
看完配置文件,我就在想为什么fork=true被禁止了,同时还有存储引擎和日志压缩都注释掉了。
我比较怕配置文件和实际的数据库内部的配置文件之间是有区别的,遇到这样的问题不是一次两次了,所以还的对数据库内部的配置进行扫描,确认和外部的配置文件是否一致。
结果如下

参数信息
这里先小结一下 1 单机 2 mongodb 3.2 3 没有开慢查询 4 系统16C CPU 64G内存 给MOGNODB 分配了约40G的缓存 5 系统的CPU 经常超高
信息基本上齐了,那么我们第一个问题就是先看慢查询,通过命令打开系统的慢查询这个系统还是比较简单,只有一个业务库。
打开对应的库,注意MONGODB的慢查询是根据库来的,你要查那个慢查询就去那个库,里面通过命令临时打开慢查询系统进行语句的记录。
// 查看当前状态
var status = db.getProfilingStatus();
print("当前状态: 级别=" + status.was + ", 阈值=" + status.slowms + "ms");
// 开启慢查询(级别1),并设置阈值(例如 500ms)
db.setProfilingLevel(1, 500);
如你要查看超过500毫秒的语句,对应的数据库运行即可,
然后通过查询 profile表中的记录进行查询 db.system.profile.find().sort({ ts: -1 }).limit(10).pretty();
剩下的就是分析查询语句的问题,果然里面很多remove的语句,在进行全表扫描后,进行删除。
同时还有一个大表在通过 or进行查询
db.Jk_Xs.find({
"sdd": "Eedc",
"$or": [
{ "mddd": "53" }
],
"$or": [
{ "d44q": 0 },
{ "d44q": { "$exists": false } }
]
})
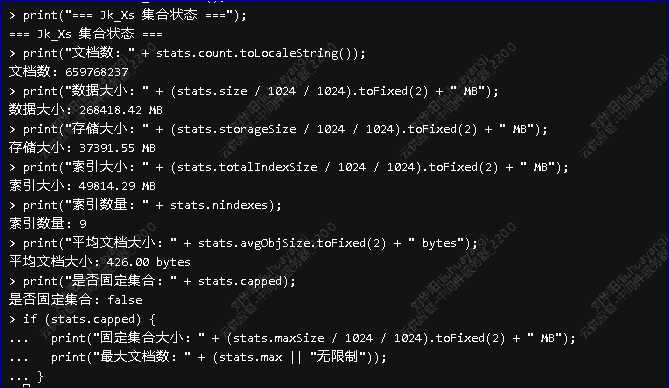
大表
实际上这个查询拆出来,是result1 + result 2 两个OR 结果后再进行 FINNALrESULT = union(result1 + result2)
其实这样的查询可以将两个结果分开执行然后在应用层进行合并
最后我们有一个分析表信息的脚本可以从阅读原文中下载这个脚本。
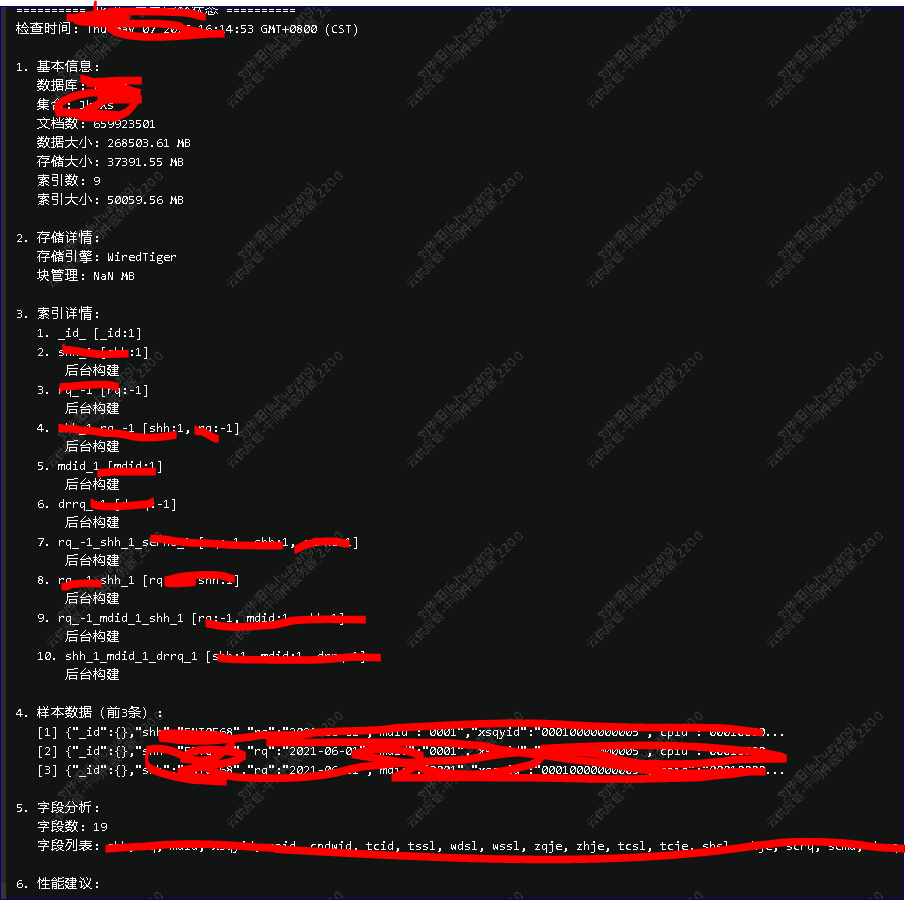
分析表状态的脚本

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-08,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 AustinDatabases 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号