异步拷贝与 CUDA Stream(计算与数据传输重叠)

异步拷贝与 CUDA Stream(计算与数据传输重叠)

Michael阿明
发布于 2026-05-13 17:36:05
发布于 2026-05-13 17:36:05
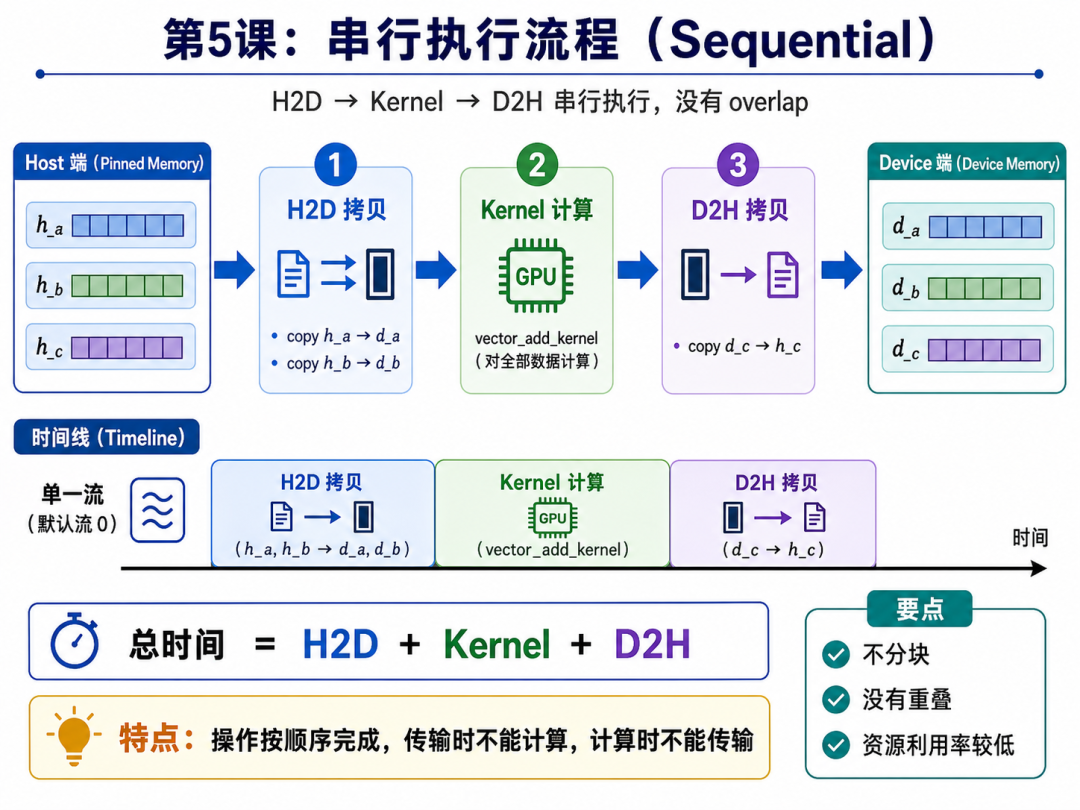
第五课的核心是 CUDA Stream 与异步拷贝如何实现计算和数据传输重叠。
在串行执行模式下,程序按照 H2D → Kernel → D2H 顺序运行,数据传输时 GPU 计算单元空闲,kernel 计算时 copy engine 又可能空闲,资源利用率不高。
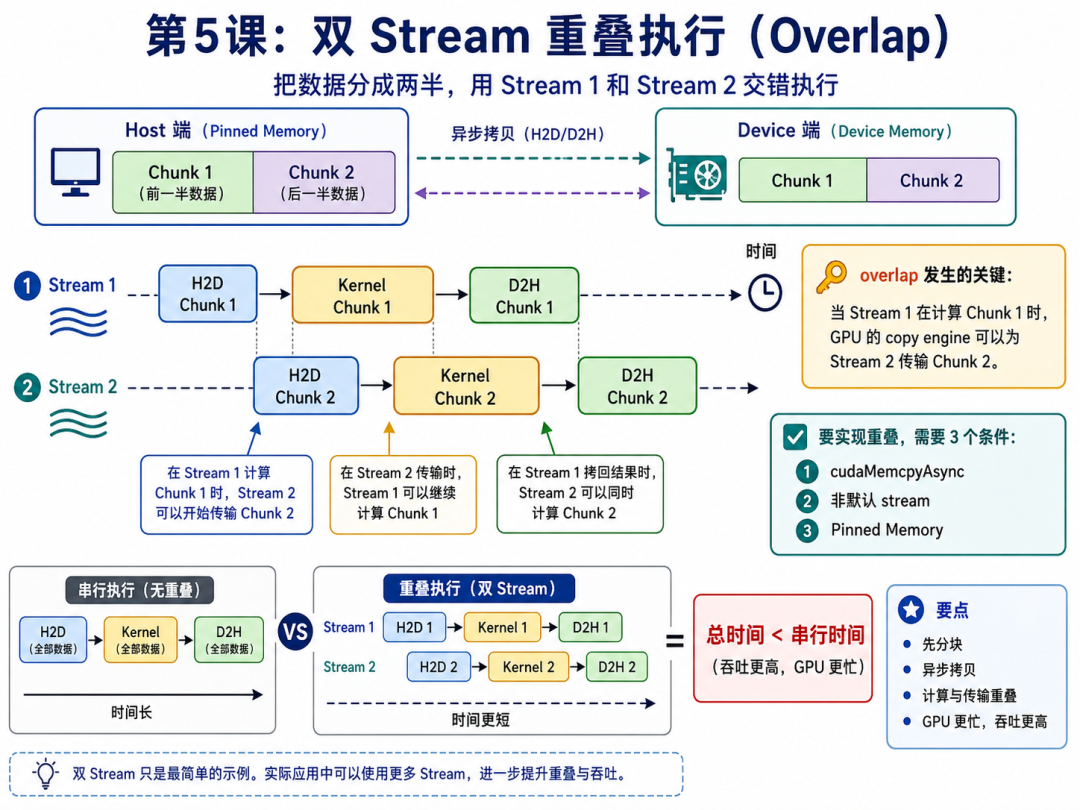
通过把数据切分成多个 chunk,并使用非默认 stream、cudaMemcpyAsync 和 Pinned Memory,可以让不同 chunk 的数据传输与计算交错执行。
例如 Stream 1 正在计算 chunk 1 时,Stream 2 可以同时传输 chunk 2,从而让 copy engine 和 SM(Streaming Multiprocessor) 并行工作,降低总耗时、提升吞吐。
在这里插入图片描述
做对比实验:
在这里插入图片描述
编写代码:
%%writefile stream_overlap.cu
#include <cuda_runtime.h>
#include <iostream>
#include <cstdlib>
#include <vector>
#include <chrono>
#define CUDA_CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
std::cerr << "CUDA Error: " << cudaGetErrorString(err) << std::endl; \
exit(1); \
} \
} while (0)
__global__ void vector_add_kernel(const float* a,
const float* b,
float* c,
int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
// 增加一点计算量,方便观察 overlap
float x = a[idx];
float y = b[idx];
float z = 0;
for (int i = 0; i < 50; ++i) {
z += x + y;
}
c[idx] = z;
}
}
void run_sequential(float* h_a, float* h_b, float* h_c,
float* d_a, float* d_b, float* d_c,
int n, size_t bytes) {
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, bytes, cudaMemcpyHostToDevice);
int block = 256;
int grid = (n + block - 1) / block;
vector_add_kernel<<<grid, block>>>(d_a, d_b, d_c, n);
cudaMemcpy(h_c, d_c, bytes, cudaMemcpyDeviceToHost);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float ms;
cudaEventElapsedTime(&ms, start, stop);
std::cout << "Sequential time: " << ms << " ms\n";
cudaEventDestroy(start);
cudaEventDestroy(stop);
}
void run_overlap(float* h_a, float* h_b, float* h_c,
float* d_a, float* d_b, float* d_c,
int n, int stream_count) {
if (stream_count < 1) {
stream_count = 1;
}
if (stream_count > n) {
stream_count = n;
}
std::vector<cudaStream_t> streams(stream_count);
for (int i = 0; i < stream_count; ++i) {
cudaStreamCreate(&streams[i]);
}
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
for (int i = 0; i < stream_count; ++i) {
int offset = static_cast<int>((static_cast<long long>(i) * n) / stream_count);
int next_offset = static_cast<int>((static_cast<long long>(i + 1) * n) / stream_count);
int chunk_n = next_offset - offset;
size_t chunk_bytes = chunk_n * sizeof(float);
cudaStream_t stream = streams[i];
cudaMemcpyAsync(d_a + offset, h_a + offset, chunk_bytes, cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(d_b + offset, h_b + offset, chunk_bytes, cudaMemcpyHostToDevice, stream);
vector_add_kernel<<<(chunk_n + 255) / 256, 256, 0, stream>>>(
d_a + offset, d_b + offset, d_c + offset, chunk_n);
cudaMemcpyAsync(h_c + offset, d_c + offset, chunk_bytes, cudaMemcpyDeviceToHost, stream);
}
for (int i = 0; i < stream_count; ++i) {
cudaStreamSynchronize(streams[i]);
}
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float ms;
cudaEventElapsedTime(&ms, start, stop);
std::cout << "Overlap time (" << stream_count << " streams): " << ms << " ms\n";
for (int i = 0; i < stream_count; ++i) {
cudaStreamDestroy(streams[i]);
}
cudaEventDestroy(start);
cudaEventDestroy(stop);
}
int main(int argc, char** argv) {
int stream_count = 2;
if (argc > 1) {
stream_count = std::atoi(argv[1]);
}
const int n = 1 << 28;
const size_t bytes = n * sizeof(float);
std::cout << "Data size: " << bytes / 1024.0 / 1024.0 << " MB\n";
float *h_a, *h_b, *h_c;
// 必须使用 pinned memory
cudaMallocHost(&h_a, bytes);
cudaMallocHost(&h_b, bytes);
cudaMallocHost(&h_c, bytes);
for (int i = 0; i < n; ++i) {
h_a[i] = i * 0.001f;
h_b[i] = i * 0.002f;
}
float *d_a, *d_b, *d_c;
cudaMalloc(&d_a, bytes);
cudaMalloc(&d_b, bytes);
cudaMalloc(&d_c, bytes);
run_sequential(h_a, h_b, h_c, d_a, d_b, d_c, n, bytes);
run_overlap(h_a, h_b, h_c, d_a, d_b, d_c, n, stream_count);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
return 0;
}
注意:<<<grid, block>>> 是 kernel 启动的简写形式,默认使用 sharedMemBytes=0 和默认 stream;
而 <<<grid, block, 0, stream>>> 是完整形式,显式指定该 kernel 在某个 CUDA stream 中执行。
实验结果:
!./stream_overlap 1
!./stream_overlap 2
!./stream_overlap 4
!./stream_overlap 8
!./stream_overlap 16
!./stream_overlap 32
!./stream_overlap 64
!./stream_overlap 128
Data size: 1024 MB
Sequential time: 267.818 ms
Overlap time (1 streams): 268.029 ms
Data size: 1024 MB
Sequential time: 269.675 ms
Overlap time (2 streams): 230.98 ms
Data size: 1024 MB
Sequential time: 269.215 ms
Overlap time (4 streams): 215.363 ms
Data size: 1024 MB
Sequential time: 270.218 ms
Overlap time (8 streams): 210.165 ms
Data size: 1024 MB
Sequential time: 268.516 ms
Overlap time (16 streams): 208.749 ms
Data size: 1024 MB
Sequential time: 270.236 ms
Overlap time (32 streams): 212.979 ms
Data size: 1024 MB
Sequential time: 267.791 ms
Overlap time (64 streams): 222.178 ms
Data size: 1024 MB
Sequential time: 267.783 ms
Overlap time (128 streams): 226.213 ms
在这里插入图片描述
在这里插入图片描述
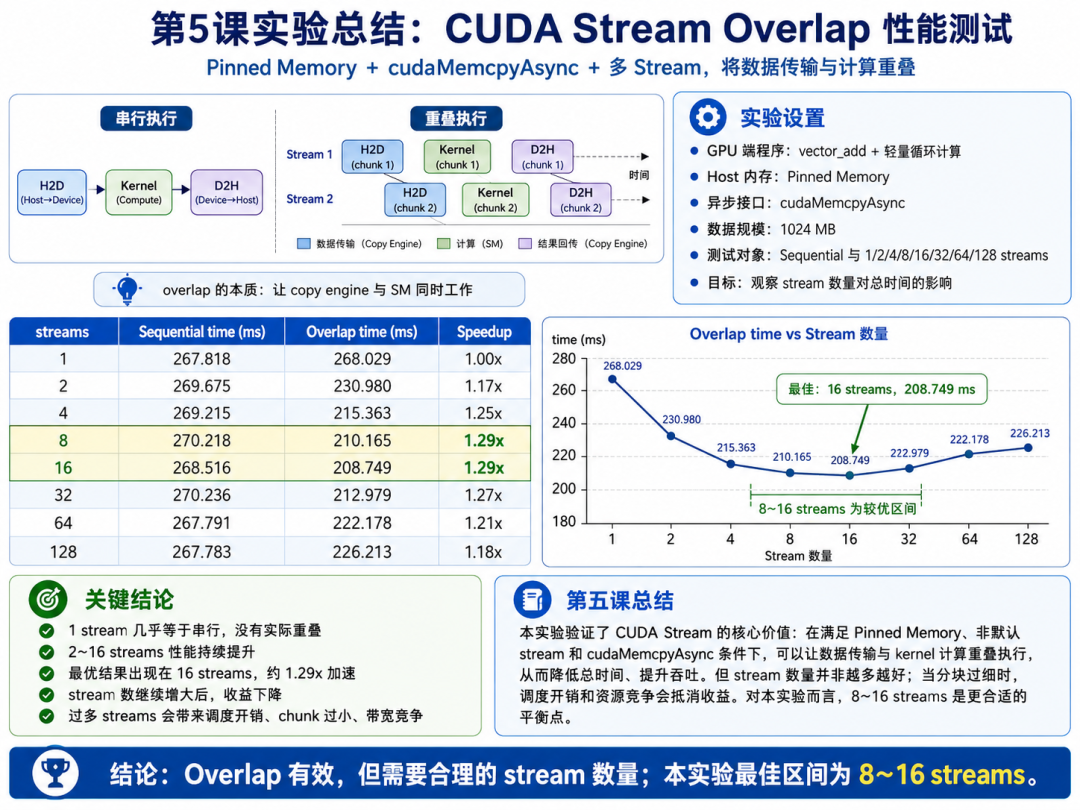
实验很好地验证了这一点:
- 1 个 stream 几乎等于串行执行,没有明显重叠;
- 随着 stream 数量从 2 增加到 16,总时间从约 231 ms 下降到约 209 ms,性能持续改善,最佳加速约为 1.29 倍。
- 但 stream 不是越多越好,当增加到 32、64、128 时,性能反而下降,说明过多 stream 会带来调度开销、chunk 过小、带宽竞争和资源争用。
- 最重要的结论是:Overlap 是有效的,但必须合理控制 stream 数量;在本实验中,8~16 个 stream 是更合适的平衡区间。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号