越早发现越便宜:企业级AI Coding的7道代码分层质量拦截防线

越早发现越便宜:企业级AI Coding的7道代码分层质量拦截防线

用户5602664
发布于 2026-05-15 14:16:20
发布于 2026-05-15 14:16:20
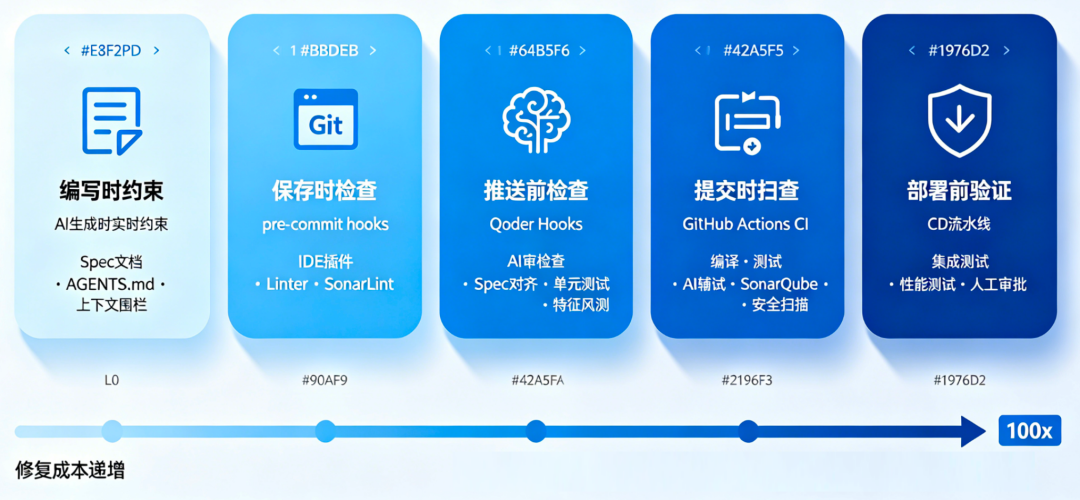
从代码编写到生产部署,构建多层质量防护网,确保AI生成代码符合企业标准。
一、体系设计全景
1.1 为什么需要分层拦截?
AI生成代码虽然快,但质量不稳定。单层检查要么太松(漏掉问题),要么太严(影响效率)。分层拦截的核心思想是:
- 问题左移:越早发现问题,修复成本越低
- 层层递进:从松到严,不把所有压力集中在一个点
- 职责明确:每层专注特定类型的检查,避免重复
1.2 7层拦截架构
质量拦截层级(从近到远)
L0 编写时 → AI生成时实时约束(Spec、Rules、Context)
L1 保存时 → 编辑器即时检查(IDE Plugin、Linter)
L2 提交前 → pre-commit hooks拦截
L3 推送前 → Qoder Hooks检查
L4 提交时 → GitHub Actions CI扫描
L5 合并前 → Code Review + 质量门禁
L6 部署前 → 自动化测试 + 安全扫描1.3 分层设计原则
层级 | 执行时机 | 响应时间 | 拦截强度 | 主要使用者 |
|---|---|---|---|---|
L0-L1 | 实时 | <1秒 | 预防/提示 | 开发者 |
L2-L3 | 提交/推送 | <10秒 | 警告/拦截 | 开发者 |
L4-L6 | 后台 | <5分钟 | 强制门禁 | 团队/管理者 |
二、各层级详细设计
L0:编写时约束(AI生成时)
定位:预防层,在AI生成代码时就进行约束
核心工具
1. Spec文档约束
- 业务规则定义(验收标准AC)
- 接口契约(API规格)
- 数据模型(数据库规格)
- 异常处理策略
2. AGENTS.md约束
- 技术栈版本锁定
- 编码规范(命名、日志、异常)
- 永久红线(禁止修改的模块)
- AI行为约束(不臆造接口)
3. 上下文6层围栏
- L1 项目级:架构约束
- L2 模块级:依赖关系
- L3 文件级:职责划分
- L4 函数级:输入输出
- L5 变量级:命名规范
- L6 测试级:验证标准
注意事项
优势:
- 问题预防优于事后检查,效率最高
- AI生成时直接符合规范,无需返工
局限:
- L0是"引导"而非"强制拦截",AI不一定完全遵守
- 需要配合L2+的硬性拦截层才能形成完整保障
最佳实践:
- AGENTS.md要具体明确,避免模糊描述
- 提供充足的Reference参考代码
- Spec文档必须经过Checklist审查
L1:保存时检查(编辑器即时)
定位:即时反馈层,代码保存时发现问题
核心工具
1. IDE插件
- IntelliJ IDEA + SonarLint
- Qoder / VS Code + ESLint/Pylint
检查项:
- 语法错误
- 代码异味(Code Smell)
- 潜在Bug
- 安全漏洞
- 性能问题
2. Linter配置
- Java - Checkstyle
- Python - Pylint/Flake8
- JavaScript - ESLint
注意事项
优势:
- 秒级反馈,开发者体验好
- 问题可视化,直接定位到行
局限:
- 只能检查单文件,无法做跨文件分析
- 依赖开发者主动安装和配置
最佳实践:
- 团队统一IDE插件配置,避免个人差异
- 规则分级:ERROR(必须改)、WARNING(建议改)、INFO(参考)
- 定期更新规则库,跟随语言演进
L2:提交前拦截(pre-commit hooks)
定位:本地拦截层,不合格代码无法commit
核心配置
pre-commit框架:
repos:
# Java代码检查
- repo: local
hooks:
- id: maven-compile
name: Maven编译检查
entry: mvn compile -q
language: system
types: [java]
pass_filenames: false
- id: maven-test
name: 单元测试检查
entry: mvn test -q
language: system
types: [java]
pass_filenames: false
- id: checkstyle
name: 代码规范检查
entry: mvn checkstyle:check -q
language: system
types: [java]
pass_filenames: false
# 通用检查
- repo: https://github.com/pre-commit/pre-commit-hooks
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-json
- id: detect-private-key # 检测私钥泄露注意事项
优势:
- 问题在本地就解决,不影响团队
- 强制性好,无法绕过(除非--no-verify)
局限:
- 首次配置有一定门槛
- 检查时间过长会影响提交体验
最佳实践:
- 检查项控制在5个以内,执行时间<10秒
- 只检查变更文件,不全量扫描
- 提供清晰的错误提示和修复建议
L3:推送前检查(Qoder Hooks)
定位:AI辅助审查层,发现人眼容易忽略的问题
核心功能
1. AI代码审查
hooks:
pre-push:
- name: AI代码审查
command: qoder review --since=HEAD~1
description: 使用AI审查最近一次提交
- name: Spec对齐检查
command: qoder check-spec --spec-dir=spec-docs
description: 检查代码是否与Spec文档对齐2. AI审查清单
- 业务逻辑是否符合Spec定义
- 是否覆盖所有AC验收标准
- 是否有安全漏洞
- 是否有性能问题
- 代码是否可维护
注意事项
优势:
- AI能发现人眼容易忽略的问题
- 可以检查业务逻辑和Spec对齐度
局限:
- 与L4(GitHub Actions)功能可能重叠
- AI审查可能有误报
最佳实践:
- L3专注AI特色检查(Spec对齐、AI特征检测)
- L4专注工程化检查(编译、测试、安全)
- 明确分工,避免重复
L4:提交时扫描(GitHub Actions CI)
定位:团队门禁层,不合格代码无法合并
核心配置
CI流水线:
jobs:
# 1. 编译检查
compile:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Compile
run: mvn compile -q
# 2. 单元测试
test:
runs-on: ubuntu-latest
needs: compile
steps:
- uses: actions/checkout@v3
- name: Run Tests
run: mvn test
- name: Upload Coverage
uses: codecov/codecov-action@v3
# 3. 代码规范检查
checkstyle:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Checkstyle
run: mvn checkstyle:check
# 4. 静态代码分析
sonarqube:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: SonarQube Scan
uses: SonarSource/sonarqube-scan-action@master
# 5. 安全扫描
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Dependency Check
run: mvn org.owasp:dependency-check-maven:check质量门禁
SonarQube质量门禁:
- 代码覆盖率 ≥ 80%
- Bug数量 = 0
- 安全漏洞 = 0
- 代码异味 ≤ 10
- 重复代码率 ≤ 3%
注意事项
优势:
- 强制性好,无法绕过
- 全量检查,不局限于变更文件
- 可追溯,有完整历史记录
局限:
- 执行时间较长(5-10分钟)
- 依赖CI服务器资源
最佳实践:
- 并行执行多个检查任务,缩短总时间
- 失败时提供清晰的错误日志
- 定期检查CI配置,移除过时的检查项
L5:合并前审查(Code Review)
定位:人工+AI双重审查,确保代码质量
核心流程
1. PR模板
## 📋 变更说明
- 关联的Spec文档:[ ] 05-用户故事 [ ] 09-API接口
- 关联的需求编号:REQ-XXX
## ✅ 自检清单
- [ ] 代码符合编码规范
- [ ] 单元测试覆盖率 ≥ 80%
- [ ] 所有AC验收标准已实现
- [ ] 异常处理完善
- [ ] 日志记录完整2. AI辅助审查
/qoder-review --focus=business-logic,security,performance
请审查这个PR,重点关注:
1. 业务逻辑是否符合Spec定义
2. 是否有安全漏洞
3. 是否有性能问题注意事项
优势:
- 人工审查能理解业务上下文
- AI辅助能发现遗漏
- 知识传递的好机会
局限:
- 依赖审查者的经验和时间
- 可能成为瓶颈(等待审查)
最佳实践:
- PR控制在200行以内,便于审查
- 明确审查SLA(如24小时内完成)
- 建立审查清单,避免遗漏
- 定期轮换审查者,避免知识孤岛
L6:部署前验证(CD流水线)
定位:最后一道防线,只有验证通过才能上线
核心配置
jobs:
deploy-staging:
runs-on: ubuntu-latest
steps:
- name: 部署到预发布环境
run: ./scripts/deploy-staging.sh
- name: 集成测试
run: mvn verify -P integration-test
- name: 性能测试
run: ./scripts/performance-test.sh
- name: 健康检查
run: curl -f http://staging-api/health || exit 1
- name: 人工审批
uses: manual-approval@v1
- name: 部署到生产环境
run: ./scripts/deploy-production.sh注意事项
优势:
- 在真实环境验证,发现测试环境问题
- 人工审批提供最后把关
局限:
- 成本高(需要预发布环境)
- 流程长,影响发布频率
最佳实践:
- 自动化一切可自动化的检查
- 预发布环境尽量与生产一致
- 建立快速回滚机制
三、AI Coding特色检查
3.1 AI生成代码特征检测
#!/bin/bash
# 检测AI生成代码的常见问题
echo "🤖 AI代码质量检查..."
# 1. 检查过度注释(AI经常过度注释)
COMMENT_RATIO=$(grep -r "//" --include="*.java" . | wc -l)
CODE_LINES=$(find . -name "*.java" | xargs wc -l | tail -1 | awk '{print $1}')
RATIO=$((COMMENT_RATIO * 100 / CODE_LINES))
if [ $RATIO -gt 40 ]; then
echo "⚠️ 注释比例过高($RATIO%),AI可能过度注释"
fi
# 2. 检查魔法Prompt残留
if grep -r "请帮我实现\|请生成" --include="*.java" .; then
echo "❌ 发现Prompt残留,请清理"
exit 1
fi
# 3. 检查未实现的TODO
if grep -r "TODO\|FIXME" --include="*.java" . | grep -v "test"; then
echo "❌ 发现未实现的TODO,请完善"
exit 1
fi
# 4. 检查异常吞掉
if grep -rB2 -A2 "catch.*Exception.*{" --include="*.java" . | grep -A2 "}" | grep -v "log\|throw"; then
echo "❌ 发现吞异常,必须记录日志或抛出"
exit 1
fi
echo "✅ AI代码检查通过"3.2 Spec对齐检查
#!/bin/bash
# 检查代码与Spec文档对齐
echo "📋 Spec对齐检查..."
# 1. 检查API接口是否都在09-API接口规格中定义
for api_file in src/main/java/*/controller/*.java; do
apis=$(grep -oP '@(Get|Post|Put|Delete)Mapping\("([^"]+)"\)' $api_file)
for api in $apis; do
if ! grep -q "$api" spec-docs/09-API接口规格.md; then
echo "❌ API未在Spec中定义: $api"
exit 1
fi
done
done
# 2. 检查数据模型是否对齐10-数据模型
for entity in src/main/java/*/entity/*.java; do
table_name=$(basename $entity .java | sed 's/\([A-Z]\)/_\l\1/g' | sed 's/^_//')
if ! grep -q "$table_name" spec-docs/10-数据模型.md; then
echo "❌ 数据表未在Spec中定义: $table_name"
exit 1
fi
done
echo "✅ Spec对齐检查通过"3.3 Skill应用检查
#!/bin/bash
# 检查是否应用了团队Skill
echo "🔧 Skill应用检查..."
# 1. 检查是否使用统一的ResultVO
if grep -r "public.*ResponseEntity\|public.*Map<" --include="*.java" src/main; then
echo "❌ 未使用ResultVO包装返回值"
exit 1
fi
# 2. 检查是否使用BizException
if grep -r "throw new Exception\|throw new RuntimeException" --include="*.java" src/main; then
echo "❌ 未使用BizException"
exit 1
fi
# 3. 检查是否使用@Slf4j
if grep -r "LoggerFactory.getLogger\|System.out" --include="*.java" src/main; then
echo "❌ 未使用@Slf4j或使用了System.out"
exit 1
fi
echo "✅ Skill应用检查通过"四、质量Dashboard
4.1 技术层指标
## AI Coding质量指标
### 代码质量
- 代码覆盖率:85% ✅
- 代码异味:3个 ⚠️
- 技术债务:2小时 ✅
### Spec对齐
- API实现率:100% ✅
- 数据模型对齐:100% ✅
- AC覆盖率:95% ⚠️
### AI生成质量
- 一次通过率:78% ⚠️
- 平均修改次数:2.3次 ✅
- 幻觉率:5% ✅
### 安全指标
- 高危漏洞:0 ✅
- 依赖漏洞:2个 ⚠️
- 私钥泄露:0 ✅4.2 业务层指标
## 管理层视图:AI Coding效能看板
### 投入产出
- AI工具投入:¥50万/年
- 节省人力成本:¥120万/年
- ROI:140%
### 交付效能
- 平均交付周期:从14天缩短到8天(-43%)
- 需求吞吐量:从20个/月提升到35个/月(+75%)
- 紧急插单响应:从3天缩短到1天(-67%)
### 质量指标
- 生产缺陷率:从3.2%降低到1.1%(-66%)
- 返工率:从25%降低到8%(-68%)
- 客户投诉:从15次/月降低到5次/月(-67%)
### 团队效能
- 开发者满意度:7.8/10(调研)
- 新人上手时间:从4周缩短到1.5周(-63%)
- 代码审查时间:从2小时/PR降低到30分钟/PR(-75%)4.3 质量趋势监控
质量趋势(最近30天)
一次通过率
80% ┤ ╭─╮
│ ╭──╯ ╰──╮
70% ┤ ╭──╯ ╰─╮
│╭─╯ ╰──╮
60% ┤ ╰─
└─────────────────────
W1 W2 W3 W4 W5五、实施路径与最佳实践
5.1 分阶段实施
阶段1:基础拦截(1-2周)
目标:建立最小可行质量体系,快速见效
必须项:
L0:完善AGENTS.md(技术栈+编码规范+红线)
L0:准备核心Spec文档(05/09/10/13)
L2:配置pre-commit hooks(编译+测试+checkstyle)
L4:配置GitHub Actions基础CI(编译+测试)
验证标准:
- 编译失败率 < 5%
- 单元测试覆盖率 ≥ 60%
- 开发者无明显效率下降
投入:1人×1周
阶段2:AI增强(2-3周)
目标:引入AI辅助检查,提升拦截智能化
建议项:
L1:配置IDE插件(SonarLint)
L3:配置Qoder Hooks(AI代码审查+Spec对齐)
特色:部署AI代码特征检测脚本
特色:部署Spec对齐检查脚本
验证标准:
- AI生成代码一次通过率 ≥ 70%
- Spec对齐率 ≥ 90%
- 误报率 < 10%
投入:1人×2周
阶段3:全面覆盖(3-4周)
目标:形成完整质量闭环,数据驱动改进
完善项:
L5:建立AI辅助Code Review流程
L6:完善CD流水线(集成测试+性能测试)
看板:搭建质量Dashboard
闭环:建立质量反馈环(拦截→分析→优化)
验证标准:
- 生产缺陷率 < 2%
- 平均交付周期缩短 ≥ 30%
- 开发者满意度 ≥ 7/10
投入:2人×3周
5.2 不同规模团队的差异化方案
团队规模 | 推荐层级 | 核心关注 | 投入周期 | 典型场景 |
|---|---|---|---|---|
<10人 | L0+L2+L4 | 快速见效,最小干扰 | 2周 | 创业团队、小项目 |
10-50人 | L0-L5 | 质量与效率平衡 | 4周 | 中型团队、核心产品 |
50-200人 | L0-L6 | 完整体系,数据驱动 | 6周 | 大型企业、多产品线 |
>200人 | L0-L6+L7 | 全链路+事后审计 | 8周 | 集团级、合规要求高 |
5.3 ROI分析
项目 | 投入 | 产出 | 说明 |
|---|---|---|---|
工具成本 | ¥5万/年 | - | AI工具+CI/CD服务 |
人力投入 | ¥8万 | - | 2人×4周配置 |
质量提升 | - | ¥30万/年 | 减少返工成本 |
效率提升 | - | ¥50万/年 | 节省人力成本 |
总计 | ¥13万 | ¥80万/年 | ROI: 515% |
5.4 常见陷阱与规避策略
陷阱 | 表现 | 规避策略 |
|---|---|---|
过度拦截 | 开发者抱怨,效率下降 | 分层配置强度,L0-L2只警告 |
规则过时 | 误报率高,被忽略 | 定期review规则,移除过时项 |
一刀切 | 小团队负担重 | 按规模选择层级,逐步演进 |
缺乏反馈 | 同样错误反复出现 | 建立质量反馈环,根因分析 |
性能瓶颈 | CI执行时间长 | 并行执行,只检查变更文件 |
六、AI Coding成熟度模型
6.1 五级成熟度
级别 | 名称 | 特征 | 典型企业 | 关键指标 |
|---|---|---|---|---|
L1 | 初始级 | 无规范,AI生成代码直接使用 | 刚开始尝试AI Coding | 一次通过率<50% |
L2 | 可重复级 | 有pre-commit hooks,基础CI | 试点团队(1-2个) | 一次通过率60-70% |
L3 | 已定义级 | Spec体系完整,编码规范沉淀 | 推广期(3-5个团队) | 一次通过率70-80% |
L4 | 已管理级 | 7层拦截完整,质量Dashboard上线 | 规模应用(10+团队) | 一次通过率80-90% |
L5 | 优化级 | AI自动优化拦截规则,自愈能力 | 行业标杆(头部企业) | 一次通过率>90% |
6.2 升级路径
L1 → L2:配置pre-commit + 基础CI(2周)
L2 → L3:完善Spec体系 + 编码规范(4周)
L3 → L4:完整7层拦截 + Dashboard(6周)
L4 → L5:AI自动优化 + 持续改进(持续)七、风险管理与应对
7.1 风险矩阵
风险 | 概率 | 影响 | 应对策略 |
|---|---|---|---|
过度拦截 | 中 | 高 | 分层配置,灰度上线 |
AI工具依赖 | 低 | 高 | 保持人工审查能力 |
技能断层 | 中 | 中 | 定期编码培训 |
规则过时 | 高 | 中 | 建立规则review机制 |
性能瓶颈 | 中 | 中 | 优化CI配置,并行执行 |
7.2 质量反馈环
拦截记录 → 根因分析 → 更新L0约束 → 预防再犯
↑ ↓
└────────── 持续改进 ←─────────────────┘实施步骤:
- 1. 每周统计拦截数据(次数、类型、分布)
- 2. 分析Top 3高频问题
- 3. 更新AGENTS.md或Spec文档
- 4. 在团队内同步改进措施
- 5. 跟踪改进效果
八、总结与建议
8.1 核心价值
这套质量分层拦截体系的核心价值在于:
- 1. 对开发者:问题早发现早解决,减少返工,提升代码质量
- 2. 对企业:降低生产缺陷率,提升交付效率,保障代码质量
- 3. 对管理者:数据驱动决策,ROI清晰可见,风险可控
8.2 关键成功因素
- 渐进式实施:不要一次性全上,分阶段逐步推进
- 数据驱动:用数据说话,持续优化拦截规则
- 团队参与:让开发者参与规则制定,减少抵触
- 持续改进:建立质量反馈环,不断优化体系
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号