Meta 做了个实验:让 AI 从零重建软件,结果全军覆没

Meta 做了个实验:让 AI 从零重建软件,结果全军覆没

梯度不陡
发布于 2026-05-18 20:43:29
发布于 2026-05-18 20:43:29
Info Meta 最新论文 ProgramBench 提出了一个极具挑战性的 AI Coding Benchmark: 不给源码,只给程序和文档,让模型从零重建完整软件系统。 结果是:200 个真实项目、9 个顶级模型、完整解决率 0%。 AI Coding 的问题,开始从“代码生成”进入“系统重建”。
最近关于 AI Coding 的讨论,越来越乐观。
Anthropic 在讲 Claude Code 如何重构研发流程; OpenAI 在讲 Agent 如何接管软件工程; 各种“90%+ 出码率”“端到端自动化”“AI 自主开发”的故事,也越来越多。
需要说明的是: ProgramBench 测的并不是 Claude Code、Codex、Cursor 这些具体产品本身, 而是在统一 SWE-agent 执行框架下,不同顶级模型作为“Agent 大脑”时,是否具备从零重建软件系统的能力。
但就在这个时间点,Meta 放出了一个很“泼冷水”的 Benchmark。
他们让模型做一件听起来很合理的事: 给你一个软件、给你文档,不给源码。 你能不能把它重新做出来?
结果是: 200 个真实开源项目。 9 个顶级模型。 完整解决率:0%。
论文叫: 《ProgramBench: Can Language Models Rebuild Programs From Scratch?[1]》
来自 Meta FAIR、Stanford、Harvard 等机构。
它测试的已经不是:
- • “会不会补代码”
- • “会不会修 bug”
- • “会不会通过 unit test”
而是:AI 是否已经具备“完整软件工程重建能力”。
而结果,其实非常值得行业重新冷静一下。
不是“写代码”,而是“重建软件”
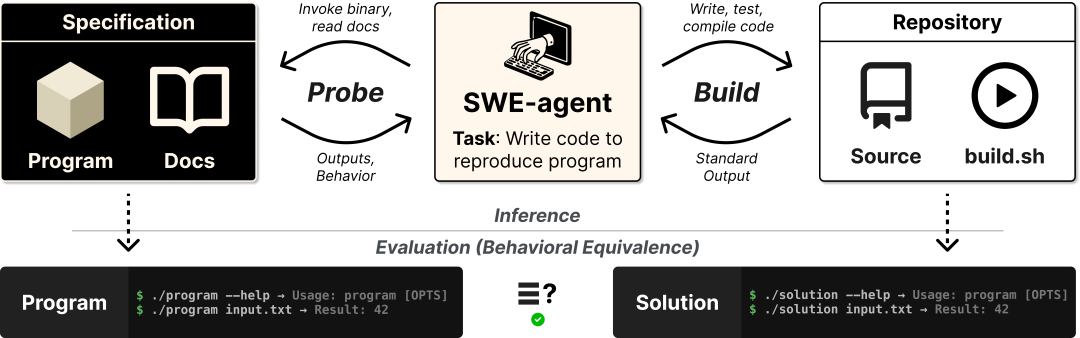
图 1:ProgramBench 要求 SWE-agent 根据程序和文档重建源码,并通过行为等价测试进行评估
图 1:ProgramBench 要求 SWE-agent 根据程序和文档重建源码,并通过行为等价测试进行评估
ProgramBench 的任务设定很简单,但非常狠。
研究者给模型的,不是源码仓库。
而是:
- • 一个可运行程序(reference executable)
- • 使用文档
- • help 信息
- • 必要运行环境
然后让 Agent:
- • 自己理解行为
- • 自己设计架构
- • 自己决定语言
- • 自己组织模块
- • 自己生成构建脚本
- • 最终实现一个“行为等价”的新程序
也就是说: 它不是 repo patching。 不是 issue fixing。 不是 code completion。
而是: 从黑盒行为,重新构建一个完整软件系统。
这里最重要的一点是: ProgramBench 并不要求模型复刻原始源码。
你可以:
- • 用不同语言
- • 用不同架构
- • 用不同算法
只要最终行为一致即可。
所以它真正测的,其实是:
- • 行为理解能力
- • 系统拆解能力
- • 软件架构能力
- • 长链路工程组织能力
而不仅仅是:“会不会生成代码”。
它和 SWE-bench,不是一回事
过去大家熟悉的代码评测,比如 SWE-bench,本质上还是:
- • 给已有代码仓库
- • 给 issue
- • 在既有结构上修 bug 或补功能
模型很多时候是在: “继续编辑一个已经存在的软件系统”。
但 ProgramBench 更进一步。
它不给源码。 不给已有架构。 不给模块边界。
模型需要自己:
- • 理解行为
- • 推断规格
- • 设计系统
- • 重建工程结构
也就是说:
SWE-bench 更像: “在已有软件上继续开发”。
而 ProgramBench 开始变成: “从黑盒行为重新构建软件系统”。
这其实已经是完全不同的问题层级。
为什么这件事突然变重要了?
因为 AI Coding 正在发生一个变化:
过去很多任务,其实都还是:
- • 局部生成
- • IDE Copilot
- • 函数补全
- • repo 内修改
- • 在既有结构中继续实现
但现在行业开始越来越多讨论:
- • autonomous agent
- • self-improving coding system
- • end-to-end automation
- • AI software engineer
也就是大家正在讨论的:自主 Agent、自我改进系统、端到端自动化、AI 软件工程师。
问题已经变成: 如果没有一个人类提前组织好的系统, 模型自己还能不能把软件真正做出来?
ProgramBench 本质上,就是第一次把这个问题系统化了。
200 个真实项目,难度不低
这不是玩具 Benchmark。
论文选的都是真实项目,包括:
- • SQLite
- • DuckDB
- • FFmpeg
- • ripgrep
- • jq
- • Lua
- • PHP interpreter
- • fzf
- • zstd
- • xz
等等。
覆盖:
- • 数据库
- • 编译器
- • CLI 工具
- • 文本处理
- • 媒体处理
- • 系统工具
项目规模也不小:
- • 代码行数中位数:8635 行
- • 最大:270 万行
- • 测试函数总数:248,853
评测方式也不是“看代码像不像”。
而是:看行为是否一致。
测试会比较:
- • stdout
- • stderr
- • exit code
- • 文件输出
- • CLI 行为
- • 副作用
等等。
本质上:这是一个“黑盒行为复现”任务。
结果:没有任何模型真正完成任务
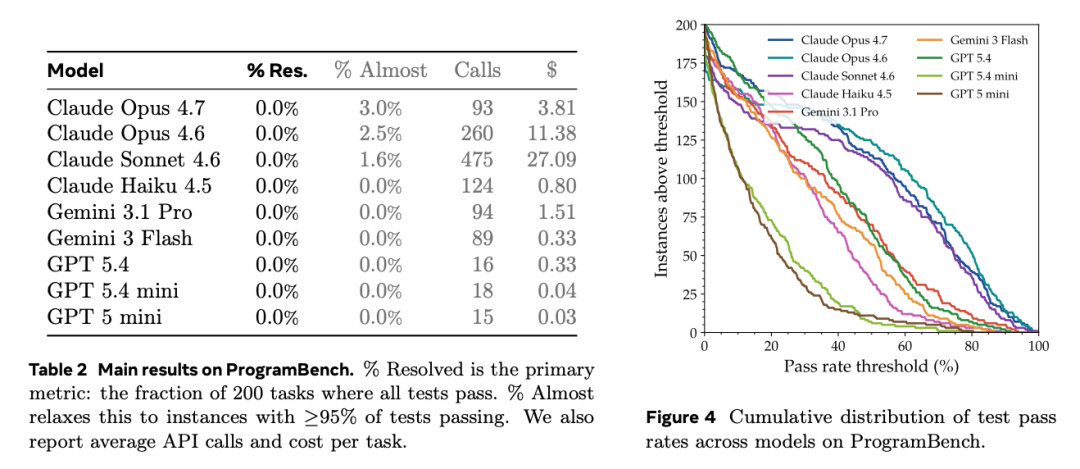
图 2:ProgramBench 验证结果及测试通过率累积分布
图 2:ProgramBench 验证结果及测试通过率累积分布
论文评测了 9 个模型:
- • Claude Opus 4.7
- • Claude Sonnet 4.6
- • GPT 5.4
- • Gemini 3.1 Pro
- • GPT 5 mini
- • Claude Haiku
- • Gemini Flash ……
主指标叫 % Resolved。
定义是: 所有测试全部通过, 且没有作弊绕过评测。
结果是:全部为 0%。
没有任何模型完整解决任何任务。
即便最好的 Claude Opus 4.7: 也只有 3% 的任务通过了 95% 以上测试。
这其实是一个很重要的信号。
因为它说明:
“能写出一些功能” 和 “能真正交付完整软件” 之间, 还隔着非常远的距离。
ProgramBench 真正打到的,不是代码生成
我觉得这篇论文真正重要的地方,其实不是排行榜。
而是它第一次把 AI Coding 里的一个核心问题,彻底暴露出来: “会写功能”,不等于“会重建系统”。
当前很多 Coding Agent 的成功,本质上仍然建立在人类已经提前完成:
- • 架构设计
- • 模块边界
- • 工程约束
- • 接口定义
- • 验证体系
之后。
模型很多时候是在:“继续填充”。
但 ProgramBench 做了一件很狠的事: 它把这些“人类提前组织好的结构”拿掉了。
结果模型很快就开始暴露问题:
- • 一次性生成大量代码
- • 缺少稳定模块边界
- • 长链路行为容易崩
- • 架构逐渐失控
- • 难以持续重构
- • 边界条件大量遗漏
论文甚至专门分析了模型生成代码的形态。
一个很典型的现象是:模型特别喜欢“一次性大生成”。
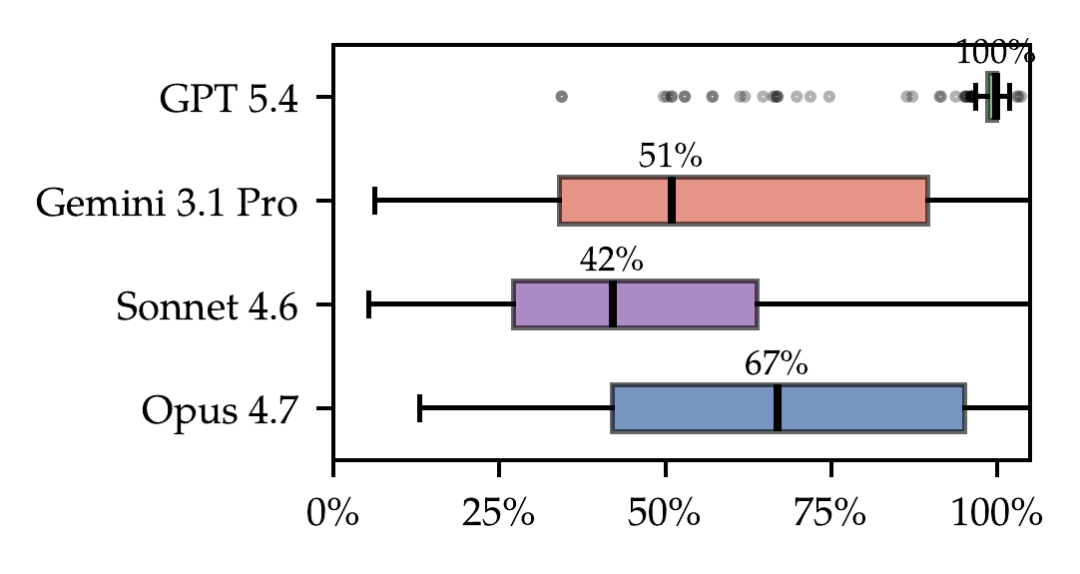
图 3:单次最大编辑在最终代码库中的占比。模型常常不是持续重构,而是一次性写出大量代码
图 3:单次最大编辑在最终代码库中的占比。模型常常不是持续重构,而是一次性写出大量代码
很多最终代码,90% 以上来自一次超大编辑。
也就是说:
模型更像是在:“直接堆一个大实现”。
而不是像真实工程团队那样:
- • 持续拆分
- • 小步验证
- • 模块重构
- • 长期维护
这其实也是当前 AI Coding 的真实边界
今天很多 AI Coding 的“惊艳效果”,其实都发生在:
- • 已有 repo
- • 已有架构
- • 已有组件库
- • 已有规范
- • 已有测试
- • 已有接口
的前提下。
也就是说:
真正复杂的东西, 很多时候已经被人类提前组织好了。
模型接手的是:“局部执行”。
所以: Claude Code、Codex、Cursor、Copilot 很强。
这件事本身并没有错。
但: 这不等于模型已经具备完整软件系统的自主构建能力。
ProgramBench 最大的价值,就是把这两个阶段明确分开了。
这篇论文为什么很重要?
因为它开始把 AI Coding 的问题: 从“代码生成”,推进到“系统重建”。
而这背后真正缺少的东西,已经不只是模型能力。
而是:
- • 如何理解系统
- • 如何表达结构
- • 如何组织任务
- • 如何持续执行
- • 如何建立验证闭环
- • 如何进行长期维护
也就是说: AI 软件工程真正困难的部分, 正在从:“生成代码”,转向:“组织软件系统”。
对工程团队,其实是个提醒
如果你正在把 Coding Agent 接入真实研发流程,这篇论文其实很有参考价值。
第一,不要把 benchmark 高分直接等同于“能够独立完成项目”。 修 bug、补功能、通过单测,和从零构建完整系统,是完全不同的能力层级。
第二,任务边界需要更小、更明确、更可验证。 当前模型更适合:
- • 明确输入
- • 明确接口
- • 明确约束
- • 明确验收
之后的执行。
第三,验证会越来越重要。 ProgramBench 本质上就在说明: AI Coding 的核心问题,
最终会变成:“行为是否真的成立”。
而不是:“代码看起来像不像”。
最后
ProgramBench 很像一次提醒。
AI Coding 的下一阶段,可能已经不是: “生成更多代码”。
而是:
- • 如何理解系统
- • 如何表达结构
- • 如何组织执行
- • 如何建立验证闭环
当任务从“补一个函数”,变成“重建一个软件”时, 真正缺失的,已经不只是模型能力。 而是软件工程本身。
引用链接
[1] ProgramBench: Can Language Models Rebuild Programs From Scratch?: https://arxiv.org/abs/2605.03546
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号