你的电脑能不能跑大模型?这个本地测评神器,直接给答案

你的电脑能不能跑大模型?这个本地测评神器,直接给答案

Ai学习的老章
发布于 2026-05-19 18:25:15
发布于 2026-05-19 18:25:15
之前写本地部署相关的文章
Qwen3.6 MTP加速,本地部署加速1.5倍,驱动 Claude Code
DeepSeek-V4 蒸馏 Qwen3.5,只有 9B,本地能跑
Unsloth 给 Qwen3.6 上了MTP,本地推理速度起飞,消费级显卡轻松跑
Claude Opus 蒸馏Qwen3.6-35B-A3B,开源了,消费级显卡轻松跑
大模型推理,加速王者:DFlash,即将支持 DeepSeek-V4
留言区经常有人问我一个问题:老章,我这个设备能不能跑某某模型
这个问题看起来简单,真回答起来很麻烦
同一个模型,换显卡、换量化、换推理框架、换 prompt 模板,速度和效果都可能不一样
所以今天聊一个特别对症的工具:BenchLoop
它的目标很明确:把本地大模型评测这件事,做成可以复现、可以留档、可以发榜的工具
简单说,你也可以拥有一个跑在自己机器上的 Leaderboard
BenchLoop 简介
BenchLoop 是一个本地优先的 CLI + Web App,用来评测跑在自己硬件上的 LLM
官方给它的定位是:Benchmark local LLMs by what actually matters
这句话很准
很多托管榜单回答的是「哪个模型在别人家的服务器上跑得最好」
BenchLoop 更关心的是:
模型 + 推理服务 + prompting harness + 我的硬件,这个组合今天到底能不能用
这才是本地部署玩家真正要的答案
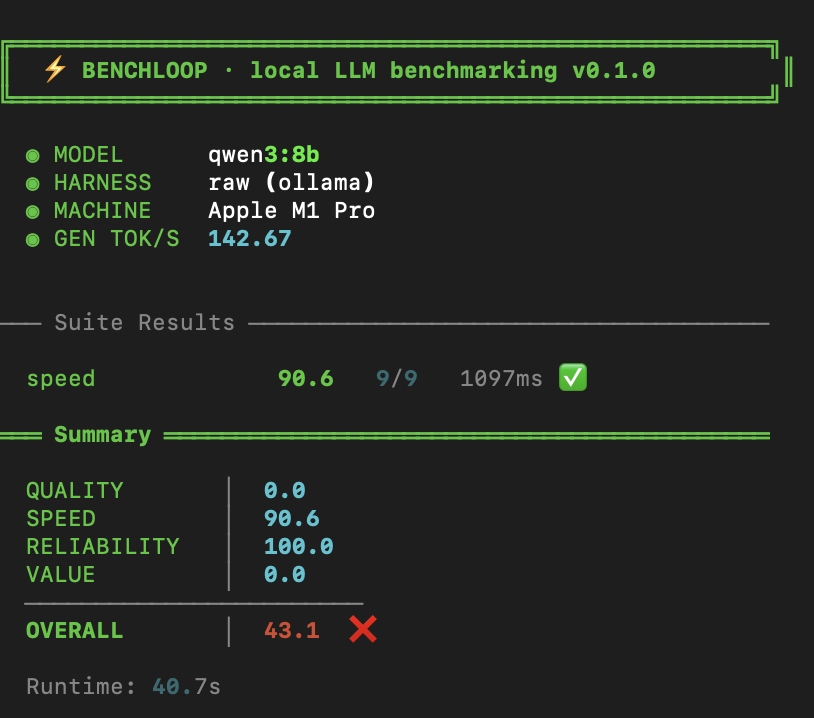
BenchLoop 跑分截图
BenchLoop 跑分截图
它的核心特点我总结成 4 个:
- 本地优先:无需账号、无需 API key,模型跑在你自己的机器上
- 可复现:任务集冻结,scorer 确定性,每次跑完都有记录
- 指标完整:输出、延迟、token 数、机器信息、suite 得分都会落盘
- 带公开榜单:完成后的 benchmark 默认会提交到 bench-loop.com/leaderboard
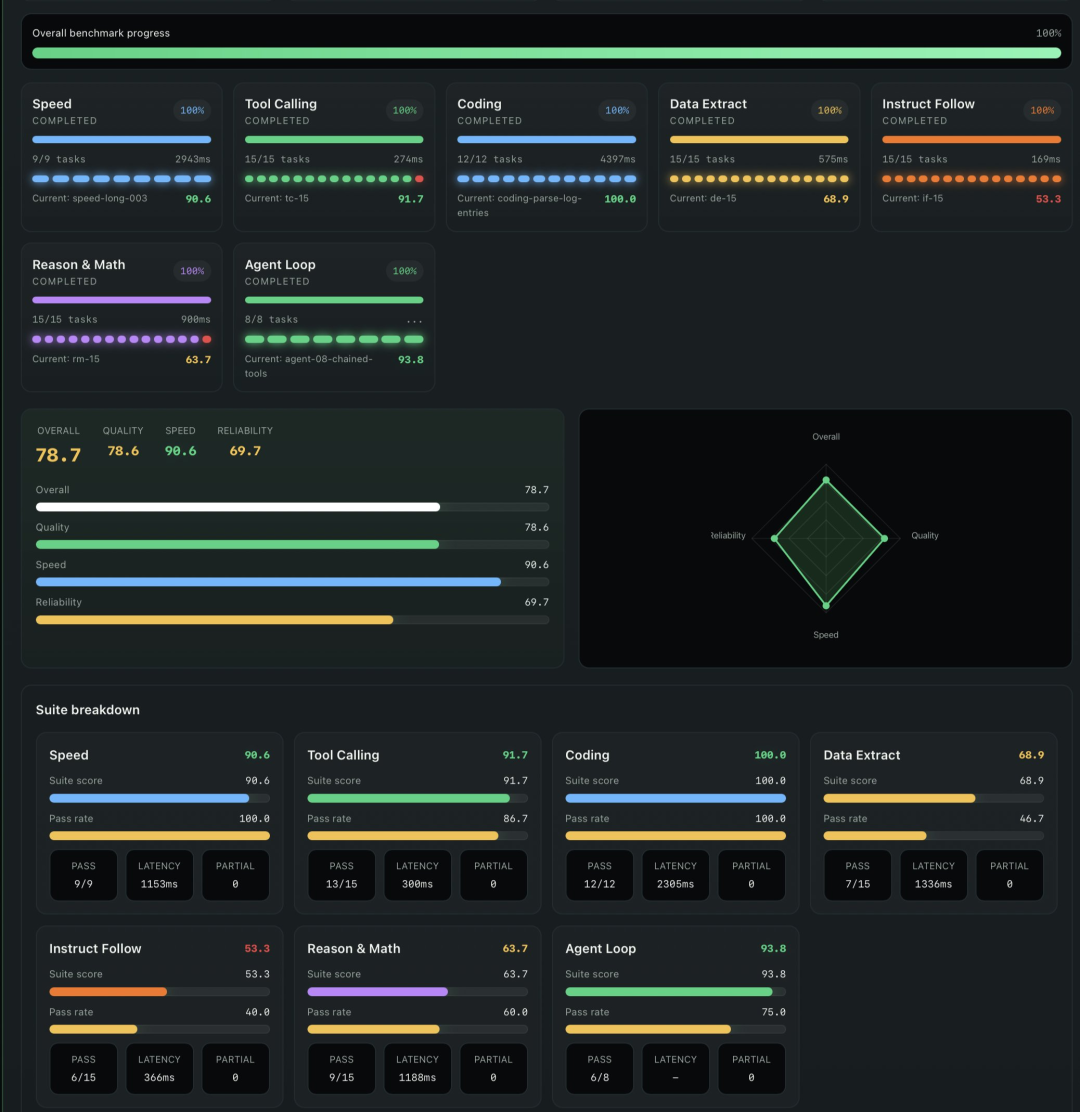
目前它覆盖 7 套 suite:
speed:延迟、吞吐、TTFT、生成速度toolcall:结构化工具调用正确性,包含天气、股票、邮件、搜索等任务coding:Python 可执行任务,放到沙盒子进程里验证dataextract:从混乱自然语言里抽取 JSON / 结构化信息instructfollow:约束跟随、格式控制、精确输出reasonmath:小型推理和数学任务agent:多轮 Agent 工具调用,模型发工具调用,BenchLoop 本地执行,再把结果喂回模型
我比较喜欢 agent 这一项
很多模型聊天看着挺聪明,一到工具调用就开始放飞自我
BenchLoop 这里会看最终答案是否正确、调用是否高效、有没有乱编工具、要求调用的工具有没有都调用到
这比单纯跑一个 tok/s 有用多了
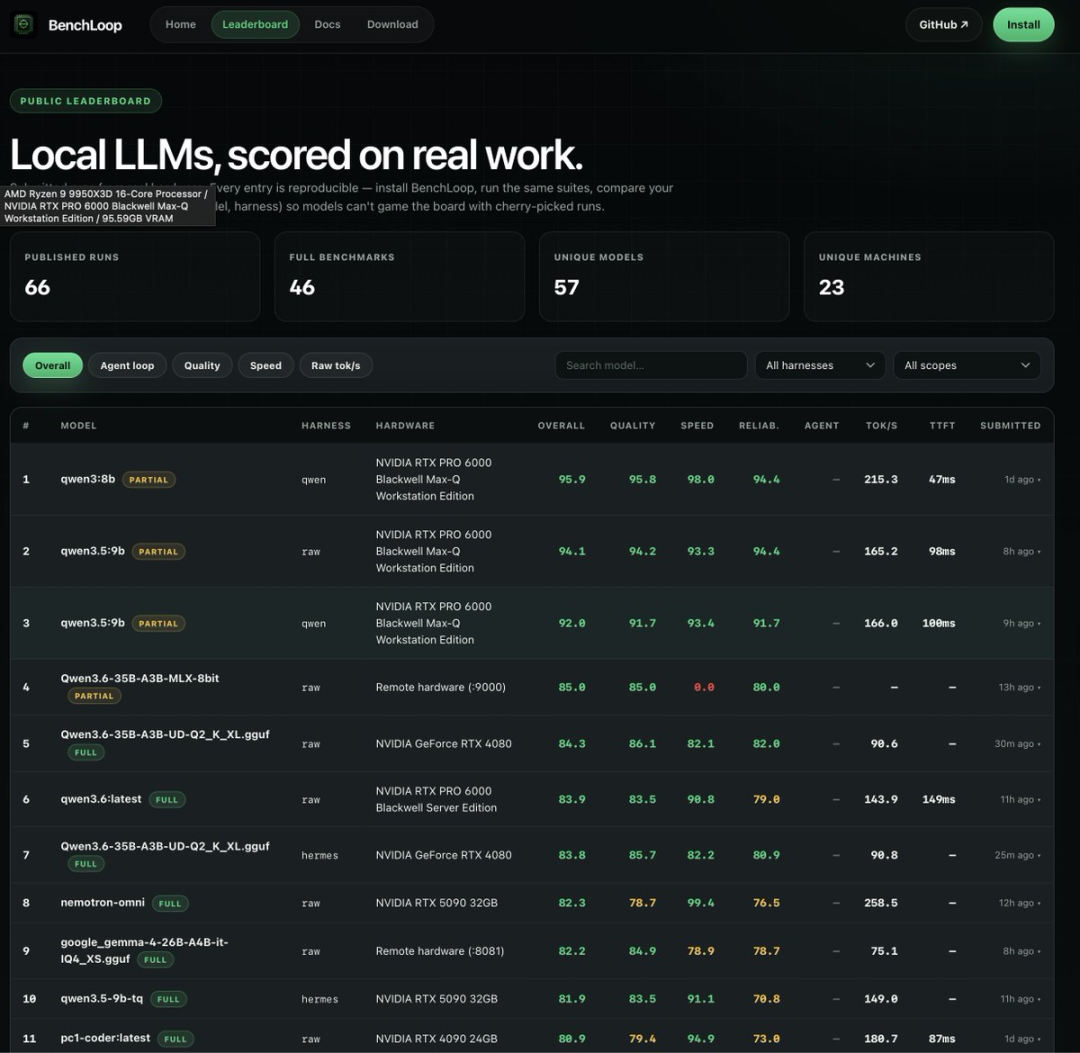
看榜单
我看官方 leaderboard 的公开 API 时,已经有 126 条提交
前排数据大概长这样:
qwen3:8b / qwen harness
Overall 95.9,RTX PRO 6000 Blackwell,215.3 tok/s
qwen3.5:9b / raw harness
Overall 94.1,RTX PRO 6000 Blackwell,165.2 tok/s
google_gemma-4-26B-A4B-it-IQ4_XS.gguf / raw harness
Overall 86.1,RTX 4080,90.3 tok/s,Full benchmark
Qwen3.6-35B-A3B-UD-Q2_K_XL.gguf / raw harness
Overall 85.7,RTX 4080,154.7 tok/s,Full benchmark
qwen3.6:latest / raw harness
Overall 83.9,RTX PRO 6000 Blackwell,143.9 tok/s,Full benchmark
这里有两个细节很关键
第一,榜单会标注 FULL 和 PARTIAL
只跑一部分 suite 的成绩,和完整 benchmark 的成绩混在一起看,容易误判
第二,harness 也会影响成绩
同一个模型走 raw、hermes、qwen、pi,工具调用格式和思考标签处理不一样,最终分数可能明显变化
这也是 BenchLoop 的价值:它把「模型怎么被调用」这件事摆上了台面
安装
推荐用 pipx 安装
pipx install benchloop-cli
benchloop --version
也可以直接用 pip
pip install benchloop-cli
写稿时 PyPI 最新版本是 0.2.3,需要 Python 3.10+
这里有个小坑:PyPI 包名叫 benchloop-cli
因为裸的 benchloop 包名已经被一个无关的数据集库占了
但安装后的命令还是这两个:
benchloop
bench-loop
如果想从源码安装:
git clone https://github.com/outsourc-e/bench-loop
cd bench-loop
pip install -e .
使用
先确保你本地有模型服务在跑
Ollama 最简单:
ollama pull qwen3:8b
ollama serve
然后跑一遍默认 benchmark:
benchloop run \
--model qwen3:8b \
--endpoint http://localhost:11434 \
--provider ollama
它会跑默认 suite,输出控制台报告,并把完整结果保存到:
~/.bench-loop/runs/
如果只是想快速试试,可以跑子集:
benchloop run --model qwen3:8b --suites speed,agent
本地推理服务支持这些常见形态:
- Ollama:
http://localhost:11434 - LM Studio:
http://localhost:1234 - MLX / Osaurus:
http://localhost:8000 - vLLM、Jan、llama-server 等 OpenAI-compatible endpoint
新版本对一部分常见端口做了自动识别,比如 LM Studio 的 1234、Jan 的 1337
我个人还是建议把 --provider 写清楚,排查问题时省心
LM Studio 这类 OpenAI 兼容服务可以这样跑:
benchloop run \
--model qwen3:8b \
--endpoint http://localhost:1234 \
--provider openai_compat
Harness 很重要
BenchLoop 支持 4 种 prompting harness
benchloop run --model qwen3:8b --harness raw
benchloop run --model qwen3:8b --harness hermes
benchloop run --model qwen3:8b --harness qwen
benchloop run --model qwen3:8b --harness pi
大概可以这样理解:
raw:原生工具调用hermes:<tool_call>{...}</tool_call>格式qwen:<function_call>{...}</function_call>格式pi:<think>...</think>+ Hermes 标签
为什么这东西重要
因为很多本地模型的能力差异,出在调用格式、工具协议和模板适配上
同一个底座模型,换一种 harness,Agent 任务的通过率可能就变了
这也是我觉得 BenchLoop 比普通测速脚本更有意思的地方
评分逻辑
BenchLoop 的总分公式是:
Overall = 0.55 × quality + 0.20 × speed + 0.25 × reliability
几个分项含义:
Quality:非 speed suite 的平均分Speed:根据 tok/s 用12.54 × log2(tok/s) + 0.9转成 0-100 分Reliability:所有任务的通过率Agent:最终答案、效率、工具幻觉、必需工具覆盖,各 25 分
这个权重我觉得挺合理
本地大模型不能只看快
一个模型 200 tok/s,但是工具调用经常乱来,实际做 Agent 也很难放心
反过来,一个模型质量很好,速度慢到等得心焦,也很难日常使用
BenchLoop 至少把这个权衡摊开了
本地 Dashboard
v0.2.0+ 开始,BenchLoop 把 FastAPI + React dashboard 打包进 wheel 里
安装完之后直接运行:
benchloop dashboard
终端会提示本地访问地址,README 里新命令提示常见是:
http://127.0.0.1:8877
dashboard 里有 Models、Benchmark、Leaderboard、Compare、Chat、agent trace viewer 这些页面
对比不同模型、不同 harness、不同硬件时,比盯着控制台舒服很多
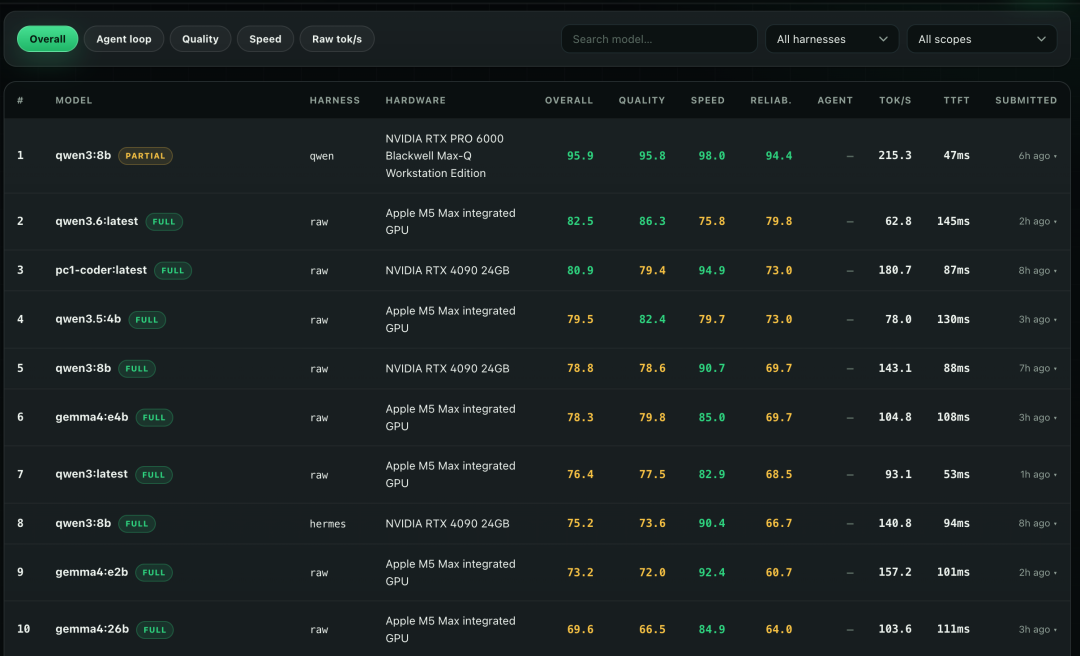
BenchLoop 详细页面
BenchLoop 详细页面
如果想让 dashboard 脱离当前终端,也能直接打印服务模板:
benchloop dashboard --service-template launchd
benchloop dashboard --service-template systemd
benchloop dashboard --service-template windows-task
自动发布要注意
BenchLoop 默认会把完成的 benchmark 发到公开 leaderboard
提交接口是:
https://api.bench-loop.com/submit
这点我觉得有利有弊
好处是社区榜单能不断积累真实硬件数据
注意点是,公开数据里会带模型名、provider、harness、机器信息、GPU、显存、系统、endpoint 等元信息
如果你在公司内网、客户机器、私有模型上测试,建议先关掉自动提交:
export BENCHLOOP_NO_SUBMIT=1
也可以只导出本地快照:
benchloop export --output my-runs.json
通过隧道跑远程机器时,还建议手动写清楚硬件信息:
benchloop run \
--model qwen3:8b \
--endpoint http://localhost:11435 \
--hardware "NVIDIA RTX 4090 24GB" \
--gpu "NVIDIA RTX 4090" \
--gpu-memory-gb 24
否则榜单里可能显示的是发起 benchmark 那台机器的硬件信息,读者看起来会有点迷糊
我怎么看
我挺喜欢 BenchLoop 的方向
它解决的是本地大模型圈一个长期痛点:大家都在晒跑分,但跑法经常对不齐
有人只测速度,有人测首 token,有人测固定 prompt,有人测一堆主观题
最后就变成一堆很热闹的数字,很难横向比较
BenchLoop 至少给了一个统一框架:
- 同一批任务
- 同一套 scorer
- 同一份机器信息
- 同一套结果收据
- 同一个公开榜单入口
我尤其建议这几类人试试:
- 本地部署玩家:换模型、换量化、换推理框架时,跑一遍心里有数
- 显卡 / 工作站用户:4090、5090、Mac Studio、RTX PRO,别只看显存,直接跑数据
- 模型量化作者:同一个模型不同量化包,速度和质量可以一起展示
- MaaS / 私有化团队:内部选型时,比只看宣传页靠谱
- Agent 开发者:重点看
toolcall和agent,这两个更接近真实工作流
当然,它现在仍然是 beta 阶段
README 里也写了几个路线图:OpenAI-compatible provider 的 streaming TTFT 还在完善,任务 fixtures 目前偏小,后续 provider adapter 也会继续扩展
所以我的建议是:把它当成本地选型和横向对比工具,非常合适
如果要得出严肃结论,最好自己固定模型、固定硬件、固定 harness,多跑几轮再看
总结
BenchLoop 这类工具会越来越重要
未来本地大模型的争论,光说「这个模型能跑」「那个模型很快」已经不够了
更有价值的问题是:
- 在我的硬件上快不快
- 在我的推理框架里稳不稳
- 工具调用靠不靠谱
- 同一个模型换 harness 会不会崩
- 这个量化包到底有没有损失能力
BenchLoop 刚好把这些问题放到一个可以复现的框架里
本地部署大模型的兄弟,值得装一个
#BenchLoop #本地大模型 #Benchmark #Ollama #开源
制作不易,如果这篇文章觉得对你有用,可否点个关注,给我个三连击:点赞、转发和在看,若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号