Karpathy的LLM-Wiki结合AI大模型-分层知识萃取和概念语义提取

Karpathy的LLM-Wiki结合AI大模型-分层知识萃取和概念语义提取

人月聊IT
发布于 2026-05-19 18:43:06
发布于 2026-05-19 18:43:06
大家好,我是人月聊IT。今天继续结合Karpathy的LLM Wiki来聊下AI大模型知识库方面的话题。
在讲我今天内容前,我们还是先看下Graphify的一个开源实现,即对于一个Raw的原始资料目录进行Ingest的知识萃取,最终提取核心的文章摘要和主题信息,然后建立知识点之间的关联构建可视化知识图谱。
当然我同意是讲我个人公众号的Markdown格式文章作为输入。对于不同的AI工具,Github上给出了不同的一键安装方法,比如我使用Codex,具体执行如下命令graphify install --platform codex,即完成安装。
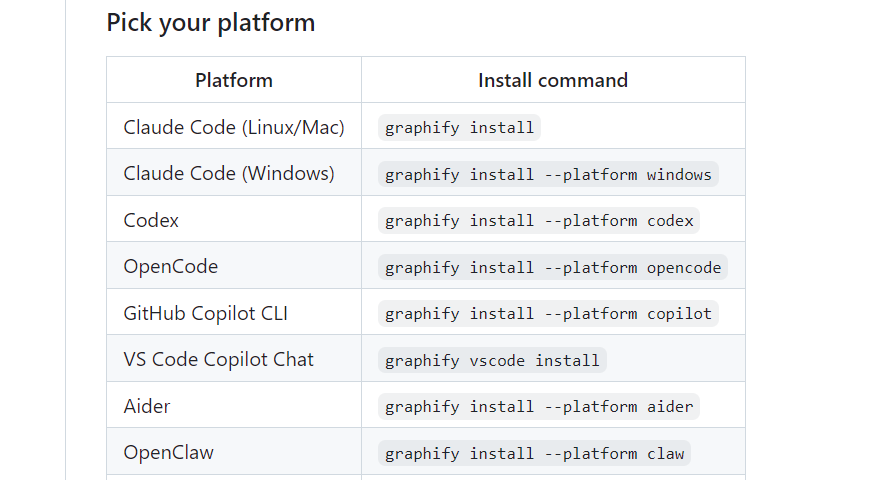
如果我们将准备好历史文章放到raw目录下面,那么直接运行
/graphify .raw
如果需要额外生成Obsidian的知识仓库,那么参考如下:
/graphify .raw --obsidian
在运行完成后,输出的目录结构如下:
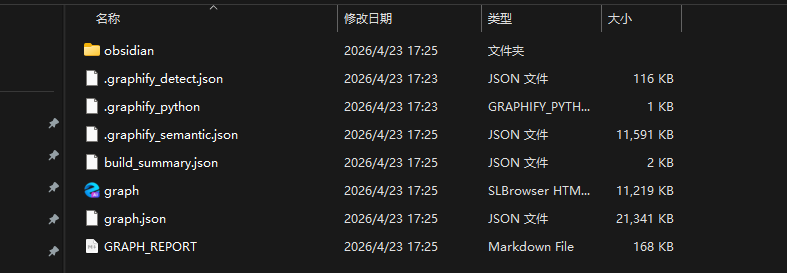
注意graph.json是完整的知识图谱数据存储。Graph_report是一个总结性的报告输出,而具体的知识萃取和切片在Obsidian目录下面,如下:
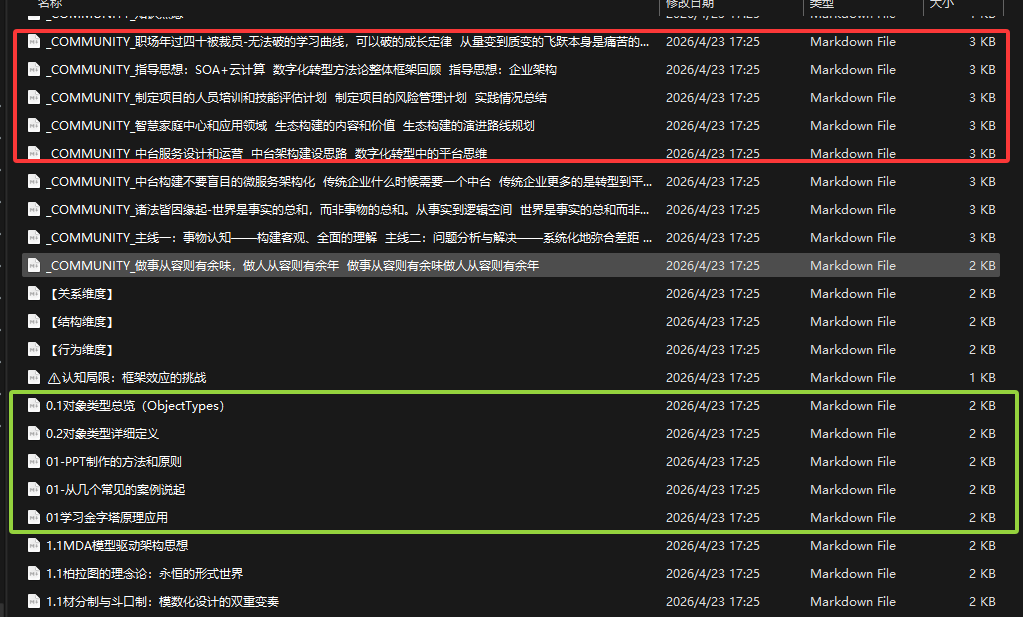
大家注意,实际这里做了两类抽取,一个文章本身的摘要和知识点提取。一个是对于核心概念知识点单独再建立一张Wiki知识卡片。在最终输出完成后,我们打开Graph html可以看到完整的可视化知识图谱展示。
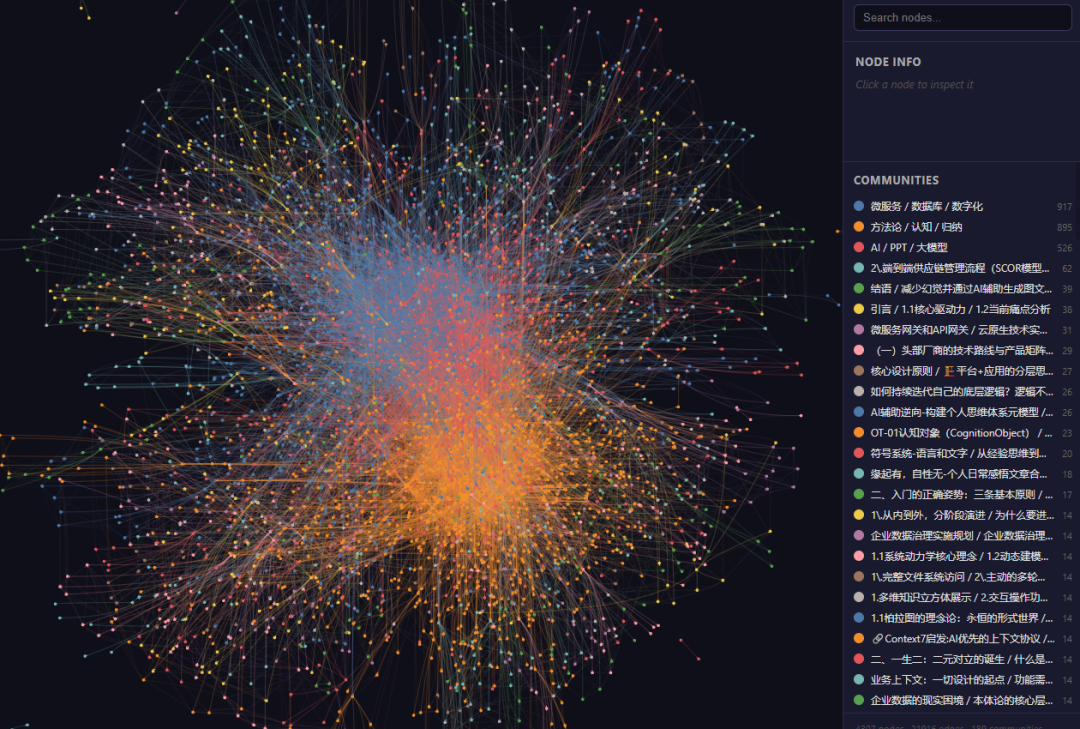
实际最终输出的这个知识图谱虽然可视化效果不错,但是可读性一般。当然能够明显体现出来的还是我个人知识库里面数字化+思维这两类知识体系占比还是最大。当然也可以用 /graphify Query对于知识连接和路径进行进一步的查询。
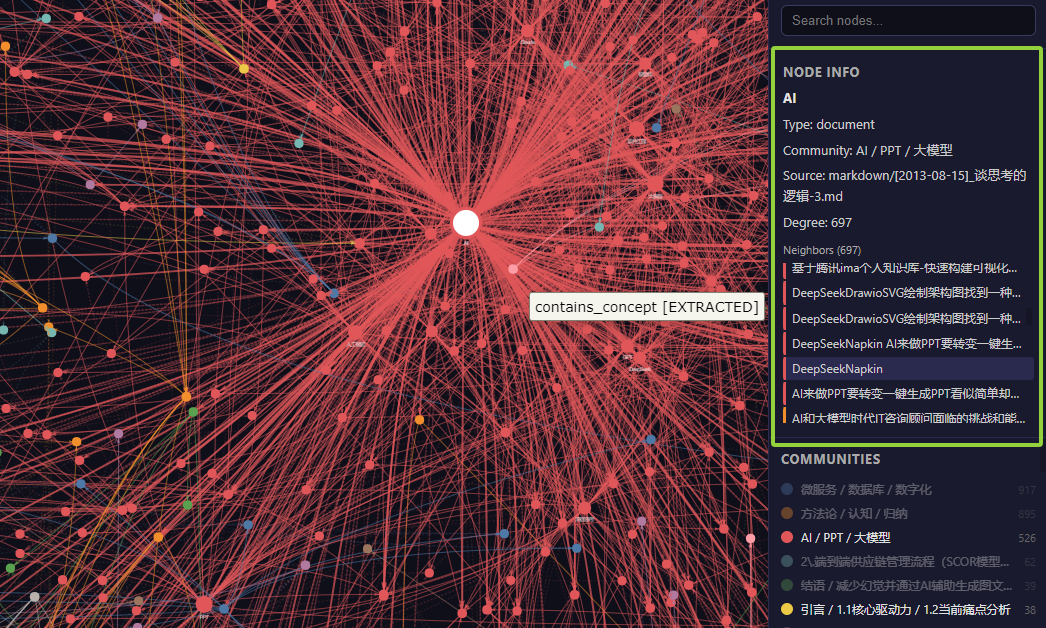
由于对接的Codex+GPT5,最终实际切片的概念主题Wiki个人感觉效果一般。里面很多琐碎没必要提取的知识点也进行了提取,同时有些知识点提取出来出现了明显的重复也没有处理。
好了,言归正传,还是聊下对Karpathy的LLM Wiki落地实践的一些关键优化和改进。供大家参考。
文章的分层萃取-主条目和子条目
如果把整个LLM Wiki投给Claude大模型,再给出需要Ingest的思维文章资料。实际AI在处理的时候分为了主条目和子条目两层的Wiki。即主条目是完全和文章1对1匹配的知识卡片,即对文章本身的摘要精华提取,包括关键的概念提取。而对于子条目则是对单独的概念构建Wiki卡片。
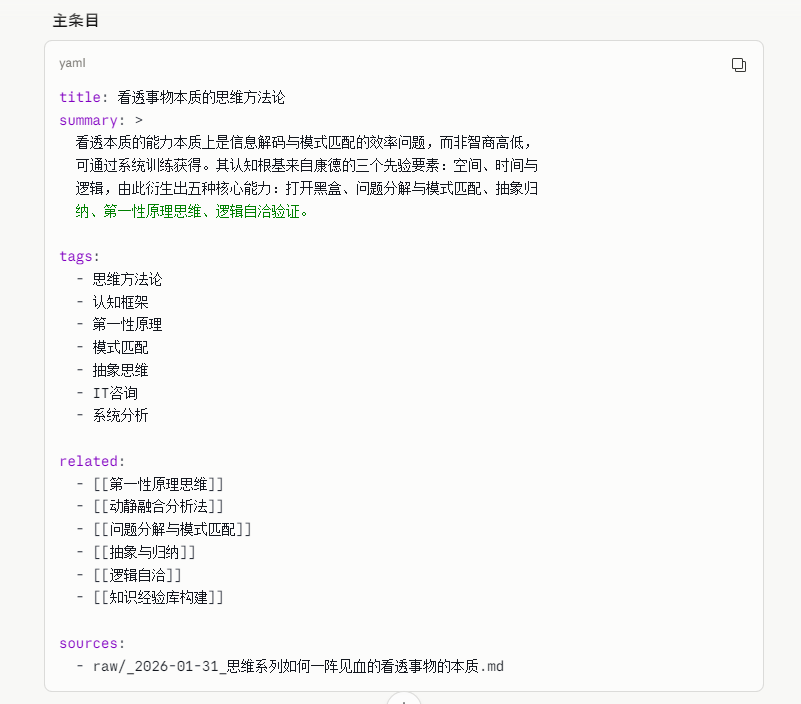
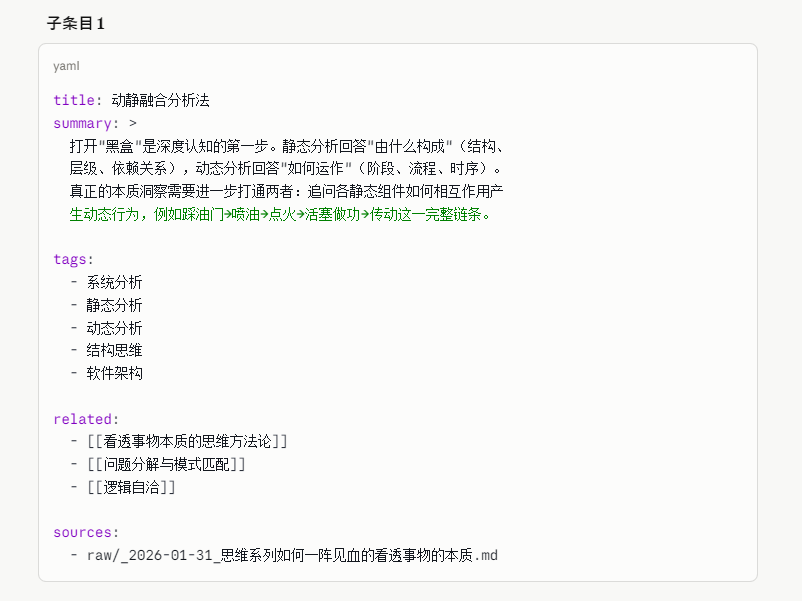
这和我前面一篇文章思路完全一致,就是对于历史资料的抽取一定要分层。我原来一直强调很难区分清楚Karpathy谈到的概念和实体两个概念,我在这里也不去强行区分这两个概念。
但是当前能做的就是历史资料要分层抽取。第一层就是完全和历史文章1对1映射的知识卡片。接着才是对知识卡片里面出现的关键词条,核心关键词概念单独抽取构建独立的Wiki。当然如果你是几百页这种方案类文档,直接第一层的分层还需要进一步拆分,比如拆分到单独一个章节一个摘要卡片保持和文章资料的1对1映射。
Tag标签,概念和实体

我这里不想区分概念和实体两个词,在这里后续我都只用概念这一个词进行说明。概念简单来说就是核心关键字的词条。注意这个概念有可能是一个静态的名词,也可能是一个动态行为抽象。类似知识库就是一个静态的概念名称,但是对于归纳演绎就是一个动态行为抽象。
那么对于Tag标签和概念如何区别?
实际在我前期让AI自动抽取Wiki的时候发现Tag和概念两个地方出现大量的重复。因此在这里给出进一步明确的提示词语义。即当抽象出了大量的概念的时候,实际你会发现概念本身是一种类似知识树的树状展开结构。类似思维里面包括了事物认知,问题解决,知识库,学习实践。学习实践里面又包括了学习,实践,复盘几个子概念。而我们的Tag标签可以理解为知识分组,或者顶层概念。因为Tag标签作用就是知识分组,因此不能最底层的所有概念都去构建一个Tag标签,那么实际意义已经不大。
Ingest摄取和动态演进
大家要注意,LLM Wiki的本质就是一个知识编译系统,将你的历史资料通过预设的Schema规则,通过Ingest方式来构建一个wiki系统,这个wiki可以理解为历史资料的一个知识元模型。
对于整个Ingest的过程是一个动态的自我进化的过程。因此让AI做这个事情的时候本身也需要一篇一篇历史文章的处理。
比如在处理完第1篇文章后,构建了基本的文章知识卡片和概念知识卡片。那么在处理第2篇文章的时候,文章知识卡片本身没有任何问题。但是你进一步提取的概念,很可能在第1篇文章已经提取过,那么这个时候就应该是对已有的概念Wiki进行融合,增加相应的标签,重新更新相应的Link连接。也就是我谈到的历史文章间本身没有构建关系,但是历史文章通过里面的概念实体间接构建了关联依赖关系。

越对你的历史文章处理到后面,越发现一个关键变化:就是每篇文章的知识卡片在不断增加,但是后面增加的独立概念wiki越来越少,更多都是对已有的概念wiki进行重构和融合。这就和我前面讲过的基于场景进行的知识组装相对类似了。底层的概念实体和逻辑就那么多,但是这种概念Wiki却可以基于场景组装出千变万化的文章出来。
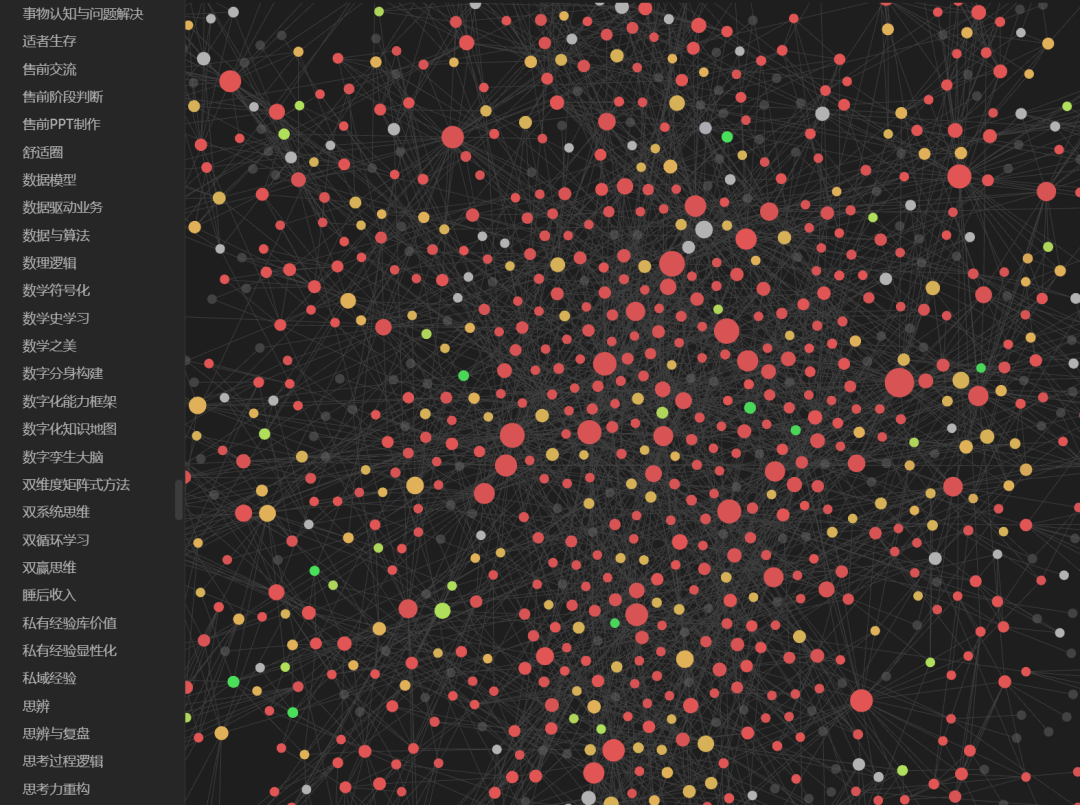
所以我们看到,当我们处理一篇新文章的时候,不仅仅是提取概念实体,而是要回溯所有已有的概念wiki,对概念的描述定义进行整合,对相关的Tag和Link关系,对Source引用来源进行整合等。
从方法论到Skills技能
在理解了前面的内容后,我们引入一个关键方法论。
在我原来做基于本体建模思想对我的思维历史文章进行抽象建模的时候,就一直在谈一个关键概念即问题场景,不同的问题场景下究竟应该如何更好的组装类似wiki这种知识块,形成一个完整的文章。
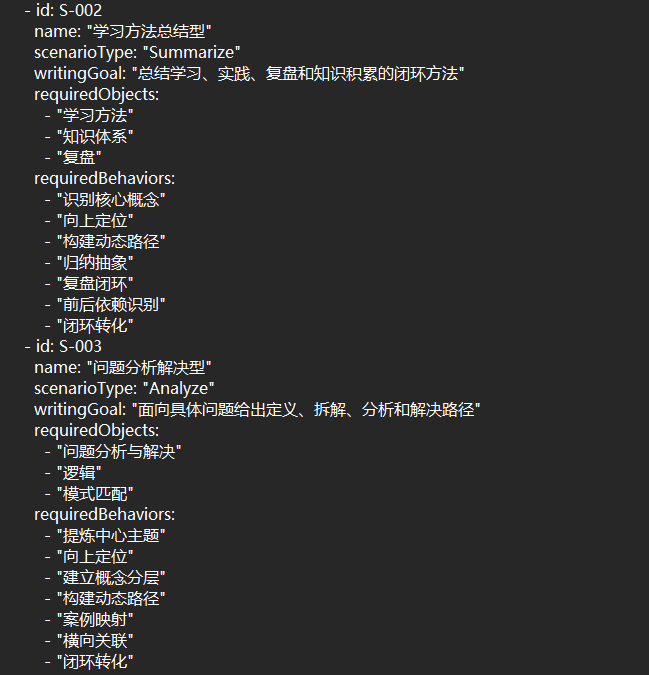
那么我们已经有了各个概念wiki,是否就一定能够基于问题很好的进行回答,或基于主题很好的进行写作了?你如何确保AI能够完全理解的问题,做好意图识别,然后转去调用底层知识块进行能力组装?
这里面有一个关键就是方法论,这个方法论就是我们平常写作输出的隐性经验,在我们自己脑子里面有一套基于不同的问题应该如何回答,如何调取我们历史知识经验整合为一个完整文章的经验。这个经验可以理解为写作方法论。那么这个写作方法论是可以浓缩为具体的Skills方式提供给AI参考的。
在这里我的构建思路分AI辅助+人工审核两个关键步骤。
步骤1:首先应该是AI对写过的历史文章进行分析和归类,抽象出关键的问题场景点,形成相应的场景或知识体系需求。
步骤2:人工介入,针对每一个场景点你回答问题的方法论或通用套路进行总结。比如对于问题分析和解决类的场景,你一般如何回答,你需要引用哪些概念和知识点,这些概念知识点又应该按什么样的先后顺序进行组装,形成一篇完整的文章。

有了上面两步,我们最终形成了第三类的Wiki,即对已有历史文章进行大量归类分析后形成的知识体系或方法论Wiki。方法论Wiki里面包括了引用的概念实体,也包括了这些概念实体应该如何组装,还包括了具体可以参考的历史文章案例。那么AI下次在回答问题或输出文章的时候,我们就应该优先参考方法论。
Query回写和自我进化
注意LLM Wiki不仅仅是一个知识编译系统,更加重要的是一个动态自我进化的知识库,是真正理解了你核心知识框架和知识元模型的知识库。关键是其还可以通过查询,回写不断的自我进化。
比如当我们应用知识库回答新问题的时候,AI给出我们一个回答或答案。但是我们对输出内容进行调整,比如新增加了一个Wiki里面已有的概念知识点,那么这个时候AI Wiki应该明白,需要去进化我们的方法论wiki,调整知识组装逻辑。再比如我们对输出内容进一步优化,新增加了一个大的新段落,体现了思维意识方面的内容。但是思维意识原来在我们的Wiki里面没有,那么这个时候AI应该明白需要去新增加概念wiki,同时优化方法论Wiki。
这个才是我们真正需要的AI智能知识库的自我进化逻辑。
新的文章写作提示词供参考:
好了,当前项目已经形成了一个完整的知识库。
我希望你基于知识库来回答问题,具体的回答思路如下
1. 首先查找wiki目录下的method,看是否有合同问题匹配的场景,如果有优先选择method里面的方法来组装知识块形成文章。
2. 如果没有合适的method,那么需要你自己思考如何基于场景问题分解来组装wiki目录下的concepts概念来组装知识。
3. 任何新文章都涉及到wiki目录下concepts概念知识块的组装,因此需要先构建一个完整的写作知识框架目录结构
4. 在构建了写作文章框架结构后,对于涉及到的concepts知识块wiki,你可以查找到里面的sources下面有原始文章索引,你可以继续深入探索原始文章找到文章的文章段落片段
5. 将这些完整段落片段进一步组装形成一篇完整的文章
6. 再进一步检查文章,让其逻辑清晰,结构完整,承上启下
7. 注意整个文章2500到3500字左右,分6到8个小标题段落进行文章组装
具体需要你回答的问题是:具体怎么做才能真正提升认知?希望以上分享对你构建个人持续进化知识库有所启发。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号