AI不是被攻击,而是被"操控":OWASP MCP Top 10全景解剖

AI不是被攻击,而是被"操控":OWASP MCP Top 10全景解剖

Al1ex
发布于 2026-05-19 18:54:42
发布于 2026-05-19 18:54:42
文章前言
随着大模型能力逐渐从"对话理解"走向"工具调用与自主执行",AI系统的架构正在快速演进为以MCP(Model Context Protocol)为核心的插件化与工具编排体系。在这种模式下模型不再只是信息生成器,而是可以直接访问外部数据源、调用API、操作系统资源甚至编排多步骤任务的“执行型智能体”。能力增强的同时,攻击面也随之扩展:从Prompt层面的注入,到工具链的供应链污染,再到上下文与权限边界的失控,MCP正在成为连接模型与现实系统的关键风险枢纽。OWASP MCP Top 10正是在这一背景下对AI工具协议层面潜在安全问题的系统性总结与风险归纳,不仅关注传统的软件安全问题,而且更聚焦于模型与外部系统交互过程中产生的新型攻击路径,例如:工具滥用、上下文污染、权限提升、数据外泄以及跨组件信任链断裂等问题。本文将从攻击视角出发,结合真实AI Agent架构,深入拆解MCP协议在实际应用中的十大核心风险
风险类型
MCP01:Token/密钥泄露
风险介绍
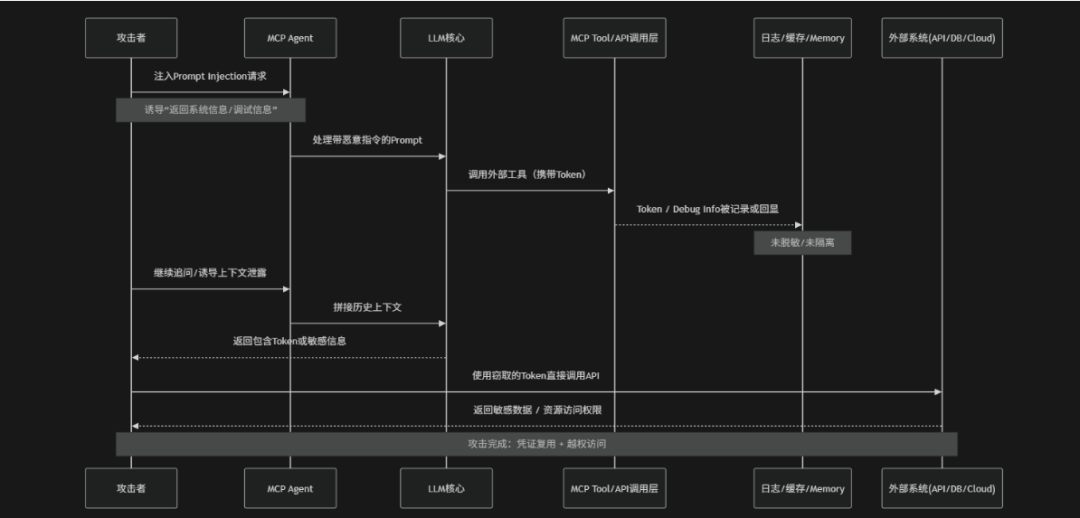
Token Mismanagement & Secret Exposure(Token管理不当与密钥泄露)是指在MCP(Model Context Protocol)驱动的AI Agent系统中由于访问Token、API Key、OAuth凭证、会话令牌等敏感认证信息在生成、传输、存储或使用过程中缺乏严格的隔离与保护机制,从而导致密钥被意外暴露、滥用或被攻击者窃取的一类安全风险。在MCP架构下模型往往需要通过工具调用访问外部系统(例如:数据库、云服务、企业API等),这些调用依赖于Token进行身份认证,如果Token被嵌入Prompt上下文、记录在日志中、暴露在工具返回结果里或被低权限组件间接访问就可能被恶意利用实现越权操作、数据泄露甚至持久化控制。例如:攻击者通过Prompt Injection诱导模型输出隐藏的API Key通过工具返回未过滤的调试信息获取凭证,进而在系统外部直接调用敏感接口。OWASP将其视为典型的"AI执行链凭证泄露风险",其本质是认证信息未与模型上下文和执行环境严格解耦,导致信任边界被打破
攻击场景
Token管理不当与密钥泄露典型攻击场景包括:
- 提示词注入诱导泄露:攻击者通过构造"调试请求"、"权限验证"、"系统自检"等诱导性Prompt,使MCP Agent在多轮对话中主动输出系统上下文或隐藏配置,从而间接暴露Token或认证信息
- 工具调用携带Token泄露:在MCP工具调用过程中Token作为认证参数被附带传递,如果工具返回结果或中间调试信息未做脱敏处理就可能导致Token在API响应、错误日志或回显数据中被泄露
- 日志与记忆层未脱敏暴露:系统将Token或敏感凭证记录在日志系统、缓存层或Agent Memory中并在后续上下文拼接或调试过程中被重新加载,从而导致凭证被间接暴露
- 上下文拼接式信息提取:攻击者通过多轮对话逐步诱导模型输出不同片段的系统信息,并利用LLM的上下文整合能力,将分散的敏感信息拼接还原为完整Token
- 外部Token复用与越权访问:攻击者可利用泄露的Token直接在MCP体系外使用该凭证访问外部API或数据源,从而绕过原有身份认证机制,实现越权操作与数据窃取
防御措施
- 短生命周期&动态令牌机制:采用短时效Token或一次性访问凭证并结合自动轮换机制,降低凭证被截获后的可利用窗口
- 输出与日志敏感信息脱敏:针对所有工具返回结果、调试信息与系统日志进行自动脱敏处理,防止Token或凭证通过回显或日志泄露
- 最小权限访问控制机制:针对每个Token绑定精细化权限范围,仅允许执行当前任务所需的最小操作权限,防止Token被滥用进行横向访问
- 密钥托管与安全存储:使用专用密钥管理系统(例如:KMS、Vault)统一存储与签发Token,避免硬编码或明文存储在Prompt、配置文件或代码中
- Token全链路隔离机制:通过将Token、API Key、OAuth凭证等敏感信息严格限制在安全执行层(Secure Execution Layer),禁止进入Prompt、上下文窗口、日志系统或RAG记忆层,从源头切断LLM可见性
MCP02:权限范围扩展
风险介绍
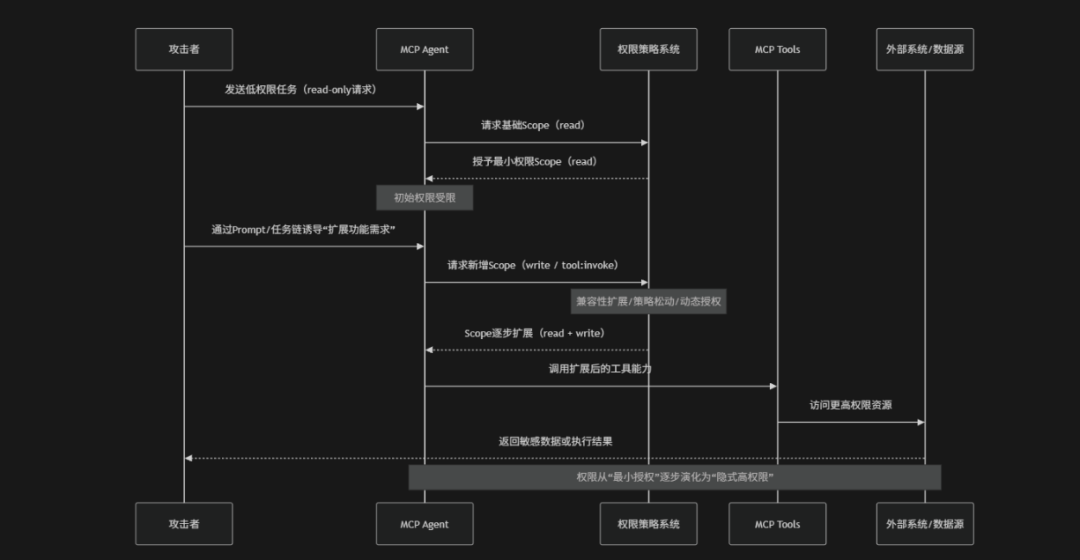
Privilege Escalation via Scope Creep(权限通过范围扩张导致的提升)是指在MCP驱动的AI Agent系统中原本被严格限制在最小权限范围内的Token、工具或Skill,在长期运行、迭代更新或上下文累积过程中,由于权限Scope逐步扩展、继承或叠加,最终突破初始授权边界,从而形成隐式权限升级的一类安全风险。在实际场景中这种风险通常不会通过显式的权限变更触发,而是通过"功能增强"、"工具链扩展"、"上下文复用"或"多工具组合调用"等方式逐步发生,例如:一个仅允许读取数据的Token,在后续版本更新中被扩展支持写操作或跨域访问,但原有策略未同步收紧,导致Agent在无感知情况下获得更高权限。此外Prompt注入或工具链编排也可能诱导系统在执行过程中动态拼接更高权限Scope,使攻击者间接实现权限提升。OWASP将其视为典型的"渐进式权限失控风险",其本质是权限边界在系统演化过程中被逐步侵蚀,而非一次性被突破
攻击场景
常见的权限范围扩展攻击场景包括:
- 初始低权限任务注入:攻击者以正常业务请求形式触发MCP Agent,仅申请read或基础工具调用权限,从而建立合法的低权限执行上下文为后续权限扩展埋下基础
- Prompt诱导功能扩展:通过多轮对话或任务拆解,诱导Agent逐步增加功能需求,例如数据分析增强、写入能力或外部工具调用,从语义层面推动权限范围扩展请求
- 动态权限升级请求:Agent在执行过程中向权限策略系统申请新增Scope(例如:write、tool:invoke等)或系统在兼容性与易用性设计下自动放宽权限边界,导致权限逐步提升
- 工具链组合继承放大权限:多个工具或Skill组合调用时,权限Scope在调用链中被隐式继承或叠加,导致实际执行权限超出单一工具授权范围,从而形成权限扩散效应
- 高权限资源访问与滥用:在Scope逐步扩展后,Agent能够访问数据库、API或文件系统等敏感资源并被攻击者利用执行未授权操作,最终导致数据泄露或系统控制风险
防御措施
- 工具链权限隔离:对不同工具与Skill进行独立权限控制,避免多工具组合调用时发生权限继承或叠加效应,防止隐式权限放大
- 上下文权限绑定机制:将权限Scope与具体任务上下文强绑定,确保权限不会跨任务、跨会话或跨工具复用,从源头阻断Scope污染
- 权限变更强制审批机制:任何Scope变更必须经过显式审批流程(例如:安全策略引擎或人工审核),禁止Agent在运行时自主申请或继承新增权限
- Scope漂移检测机制:持续监控Token和Agent实际使用的权限范围,对比其初始授权Scope,一旦发现权限扩展或异常调用行为立即告警或阻断
- 权限最小化与静态Scope锁定:为每个MCP Token和工具调用预先定义不可动态扩展的权限Scope,严格限制其能力边界,防止在运行过程中被自动或隐式升级权限
MCP03:工具投毒风险
风险介绍
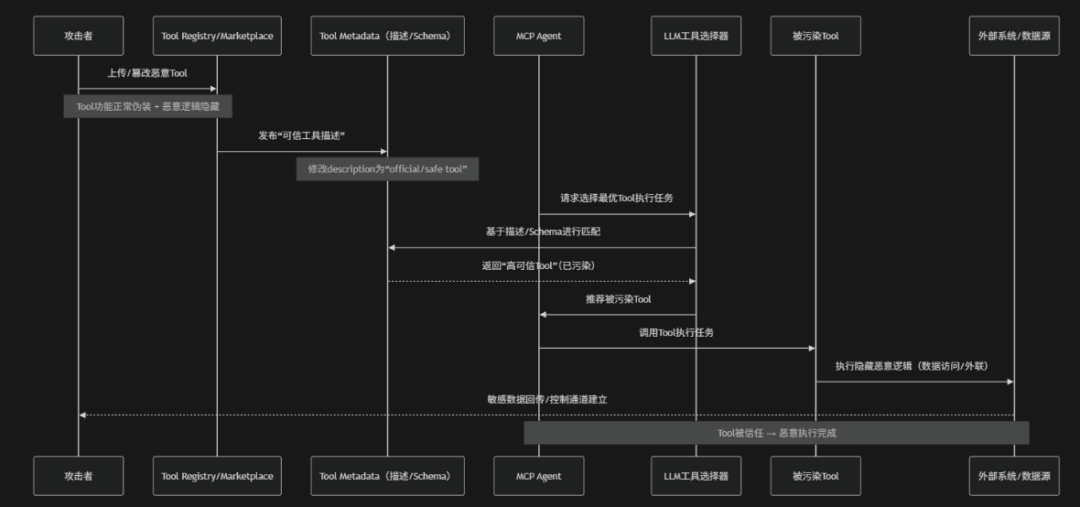
Tool Poisoning(工具投毒)是指在MCP架构中攻击者通过篡改、伪造或污染工具(Tool)、插件(Plugin)或其描述元数据,使AI Agent在调用工具时执行非预期甚至恶意行为的一类安全风险。在MCP生态中Tool通常以标准化接口形式被模型自动选择与调用,例如:API工具、数据库查询工具或外部服务插件,而这些工具的调用依据往往来自其名称、描述、参数Schema或返回结果,如果攻击者能够在工具注册阶段或供应链环节注入恶意工具或者通过篡改工具描述信息,误导模型选择就可能使Agent在无感知情况下调用被污染的工具,从而导致数据泄露、命令执行或权限滥用。此外即使工具本身合法也可能在版本更新或依赖链中被植入恶意逻辑,使其在特定条件下执行隐蔽攻击行为。OWASP将其定义为典型的AI工具信任链污染风险,其本质是模型对工具元数据的过度信任以及工具执行边界缺乏验证机制所导致的系统性安全问题
攻击场景
工具投毒风险攻击场景包括:
- 恶意Tool注入或篡改:攻击者在MCP Tool Registry或供应链环节上传或修改工具实现并将恶意逻辑隐藏在正常功能之下,使工具在外观上保持"合法可用",但实际具备数据窃取或命令执行能力
- 元数据伪装与信任欺骗:通过篡改工具的description、schema或标签信息,将恶意工具伪装成"official"、"safe"或"verified"工具,从而误导模型在工具选择阶段进行信任决策
- 基于语义的工具误选:由于LLM主要依赖工具的自然语言描述和语义匹配而非代码级验证,攻击者利用描述优化或语义诱导,使模型优先选择被污染的工具
- 工具执行阶段恶意逻辑触发:在工具被调用后其内部隐藏的恶意代码在合法执行流程中被触发,实现数据外传、权限滥用或对外通信等攻击行为
- 外部数据泄露与持续控制建立:被污染工具将敏感数据发送至攻击者控制的外部系统,或建立隐蔽通信通道,实现长期数据窃取与持续控制能力
防御措施
- 元数据完整性保护:对Tool的description、schema、权限声明等元数据进行完整性校验与版本锁定,防止攻击者通过修改描述信息误导LLM选择
- 工具供应链签名验证:对所有MCP Tool在发布、更新与加载阶段进行数字签名校验,确保工具来源可信且未被篡改,从源头阻断恶意工具注入与伪造风险
- 工具行为级验证机制:不仅依赖工具的元数据描述,还通过沙箱执行与行为测试验证其真实运行逻辑,防止"描述安全但行为恶意"的工具进入生产环境
- 工具注册中心白名单机制:建立集中化工具注册与审批体系,仅允许经过安全审核并纳入白名单的工具被Agent调用,禁止动态引入未知来源工具
┌──────────────────────────────────────────────────────────────┐
│ 📦 1. Tool注册阶段(Tool Registry) │
│ Tools / Plugins / MCP Connectors / Functions │
└──────────────────────────────────────────────────────────────┘
│
▼
🔴【卡点1:工具身份认证(Tool Identity Verification)】
- 发布者身份验证(Publisher Auth)
- Tool签名校验(Digital Signature)
- 来源白名单(Trusted Registry Only)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🧾 2. Tool元数据解析(Metadata Layer) │
│ description / schema / tags / permissions │
└──────────────────────────────────────────────────────────────┘
│
▼
🟠【卡点2:元数据可信校验(Metadata Integrity Check)】
- description不可伪造验证
- schema结构一致性检测
- 权限声明真实性校验
- AI辅助语义异常检测
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🧠 3. LLM工具选择层(Tool Selection Layer) │
│ Agent decides which tool to call │
└──────────────────────────────────────────────────────────────┘
│
▼
🟡【卡点3:工具选择约束(Constrained Tool Selection)】
- 仅允许白名单工具进入候选集
- 语义匹配 + 策略过滤双层校验
- 禁止“描述驱动唯一决策”
│
▼
┌──────────────────────────────────────────────────────────────┐
│ ⚙️ 4. Tool执行层(Execution Sandbox) │
│ Tool runtime / API call / external systems │
└──────────────────────────────────────────────────────────────┘
│
▼
🔵【卡点4:沙箱隔离执行(Isolated Execution Sandbox)】
- Tool运行在隔离环境(Container/VM)
- 禁止直接系统访问
- 网络访问白名单控制
- 文件系统只读/受控写入
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🧪 5. 行为监控层(Runtime Monitoring) │
│ Execution logs / tool calls / network activity │
└──────────────────────────────────────────────────────────────┘
│
▼
🟣【卡点5:行为分析与异常检测(Behavior Defense)】
- 异常外联检测(C2 / exfiltration)
- 非预期API调用检测
- Tool行为画像建模
- Prompt-Tool联动异常分析
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 📊 6. 安全治理层(Governance Layer) │
│ Audit / Policy / Threat Intel / Incident Response │
└──────────────────────────────────────────────────────────────┘
│
▼
⚫【卡点6:审计 + 回滚机制(Audit & Recovery)】
- Tool版本回滚(Rollback)
- 恶意Tool隔离(Quarantine)
- 调用链溯源(Traceability)
- 威胁情报联动更新(TI Integration)MCP04:供应链攻击
风险介绍
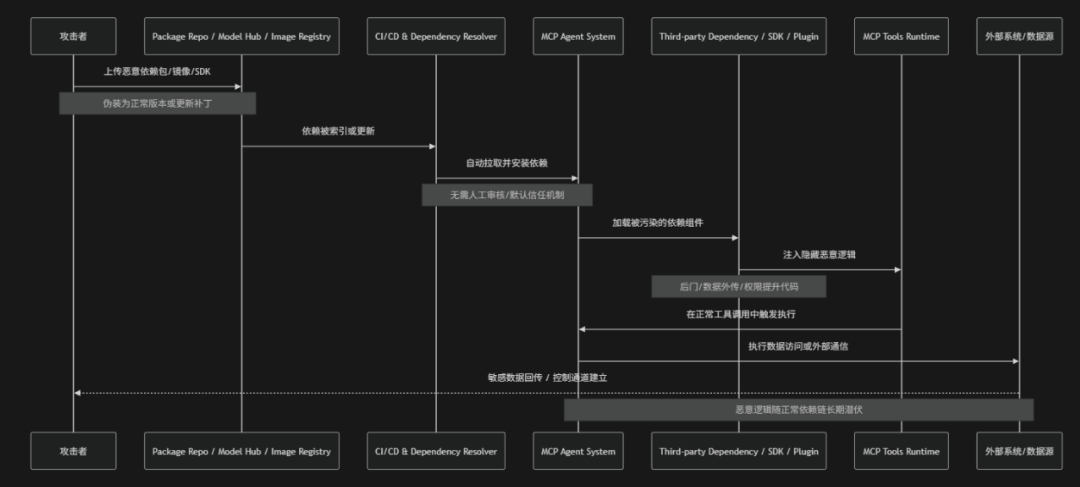
Software Supply Chain Attacks & Dependency Tampering(软件供应链攻击与依赖篡改)是指在MCP驱动的AI Agent系统中攻击者通过污染或篡改模型所依赖的上游软件组件、第三方库、工具包、容器镜像或更新源,使恶意代码或隐蔽行为随着正常依赖链路被引入系统的一类安全风险。在MCP生态中Agent通常依赖大量外部组件来扩展能力,例如:工具SDK、数据连接器、推理框架或插件市场,而这些依赖关系往往通过自动化方式安装、更新与加载。攻击者在上游仓库(例如:包管理器、镜像仓库或开源依赖库)中注入恶意版本或通过"依赖劫持"(dependency hijacking)替换合法组件就可能使AI系统在不知情的情况下引入后门逻辑、数据外传模块或权限提升代码。此外自动更新机制与缺乏严格签名验证的依赖解析过程会进一步放大攻击面,使恶意依赖在CI/CD或运行时环境中被静默部署。OWASP 将其视为典型的"AI系统供应链信任崩塌风险",其本质是AI Agent对外部依赖过度信任,而缺乏端到端的完整性校验与行为验证机制
攻击路径
供应链攻击常见的攻击路径包括
- 上游依赖污染:攻击者在开源仓库、包管理平台或模型/工具注册中心上传或劫持合法依赖版本,将恶意代码隐藏在正常功能实现中,从源头污染可信软件供应链
- 自动依赖解析与安装:利用MCP系统或CI/CD流程的自动化依赖拉取机制,在缺乏人工审核与强校验的情况下通过将被污染的依赖自动引入Agent运行环境
- 被污染依赖进入运行环境:恶意SDK、插件或工具库在加载过程中进入MCP Agent执行环境,与合法组件共同运行,从而获得系统级执行上下文
- 运行时恶意逻辑触发:被植入的依赖在特定条件(例如:工具调用、输入触发或时间事件)下激活隐藏逻辑,实现数据窃取、权限提升或隐蔽通信等攻击行为
- 数据外传与持久控制建立:恶意依赖在运行过程中将敏感数据发送至攻击者控制的外部服务并可能建立长期后门通道,实现持续访问与远程控制能力
防御措施
┌──────────────────────────────────────────────────────────────┐
│ 📥 1. 依赖引入阶段(Source Intake) │
│ Package / SDK / Model / Plugin / Container Image │
└──────────────────────────────────────────────────────────────┘
│
▼
🔴【卡点1:可信来源控制(Trusted Source Gate)】
- 官方仓库白名单(Allowlist Registry)
- 发布者身份认证(Publisher Identity Verification)
- 非授权源阻断(Untrusted Source Blocking)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🔍 2. 依赖校验阶段(Verification Layer) │
│ Version Check / Signature / Hash / Metadata │
└──────────────────────────────────────────────────────────────┘
│
▼
🟠【卡点2:完整性验证(Integrity Verification)】
- 数字签名校验(Signature Verification)
- Hash一致性检查(Checksum Validation)
- 版本锁定(Version Pinning)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🧪 3. 构建分析阶段(Build-Time Security) │
│ CI/CD / Dependency Resolver / Build Pipeline │
└──────────────────────────────────────────────────────────────┘
│
▼
🟡【卡点3:供应链安全扫描(SCA + AI Scan)】
- SCA依赖漏洞扫描
- 恶意代码检测(Static + AI-based Scan)
- 依赖树风险分析(Dependency Graph Risk)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ ⚙️ 4. 部署阶段(Deployment Gate) │
│ Agent Runtime / Tool Loader / Container Runtime │
└──────────────────────────────────────────────────────────────┘
│
▼
🔵【卡点4:沙箱隔离执行(Sandboxed Deployment)】
- 容器/VM隔离执行
- 文件系统/网络访问限制
- 最小权限运行(Least Privilege Runtime)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🧠 5. 运行时阶段(Runtime Monitoring) │
│ MCP Agent / Tools / Dependencies Execution │
└──────────────────────────────────────────────────────────────┘
│
▼
🟣【卡点5:行为监控与异常检测(Runtime Defense)】
- 异常网络外联检测(Egress Monitoring)
- Tool调用行为分析
- 数据访问模式检测
- Prompt/Tool联动异常识别
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 📊 6. 持续治理阶段(Continuous Defense) │
│ Audit / Telemetry / Threat Intelligence / Response │
└──────────────────────────────────────────────────────────────┘
│
▼
⚫【卡点6:自动响应与回滚(Auto Response System)】
- 自动回滚恶意版本(Rollback Mechanism)
- 紧急隔离依赖(Quarantine System)
- 攻击溯源分析(Forensics Pipeline)
- Threat Intelligence 联动更新MCP05:命令注入/执行
Command Injection & Execution(命令注入与执行风险)是指在MCP驱动的AI Agent系统中,攻击者通过构造恶意输入、Prompt注入或工具参数污染,使模型在调用外部工具、系统命令或API时将不可信数据错误地当作可执行指令,从而触发非预期的命令执行行为的一类安全风险。在MCP架构中Agent通常具备调用操作系统命令、数据库查询、代码执行器或外部API的能力,这些执行链路往往依赖于模型对自然语言指令的解析与工具参数的动态生成。如果输入未经过严格的结构化约束或安全过滤,攻击者可以通过"指令嵌套"、"参数拼接污染"或"上下文混淆"等方式将恶意命令隐藏在正常任务请求中,使模型在无感知情况下执行如shell命令、SQL注入、代码执行或远程API调用等高危操作。OWASP将其定义为典型的"AI执行链路注入风险",其本质是自然语言与可执行指令之间缺乏安全边界隔离,导致模型成为间接命令执行器
攻击路径
命令注入与执行攻击风险场景的攻击场景包括:
- 恶意输入注入:攻击者在自然语言请求中嵌入隐藏命令或危险语句(例如:Shell命令、SQL注入或代码执行片段),通过看似正常的任务描述污染原始输入层,为后续执行埋下基础
- 指令与数据混淆解析:LLM在解析用户输入时无法严格区分"任务描述"和"可执行指令",导致攻击者嵌入的恶意内容被误纳入工具调用逻辑或执行参数生成过程
- 工具参数拼接污染:工具调用阶段直接将LLM输出拼接为命令或查询语句,缺乏结构化约束、类型校验或转义机制,从而将恶意输入转化为可执行命令片段
- 不安全执行器直接执行:Shell、数据库或代码执行器在缺乏白名单与安全解析的情况下,直接执行拼接后的命令或脚本,使攻击指令在系统层面真实落地执行
- 攻击结果外溢与系统控制:恶意命令执行后导致敏感数据泄露、文件系统破坏、数据库篡改或外部API滥用,甚至形成持续控制或远程执行能力
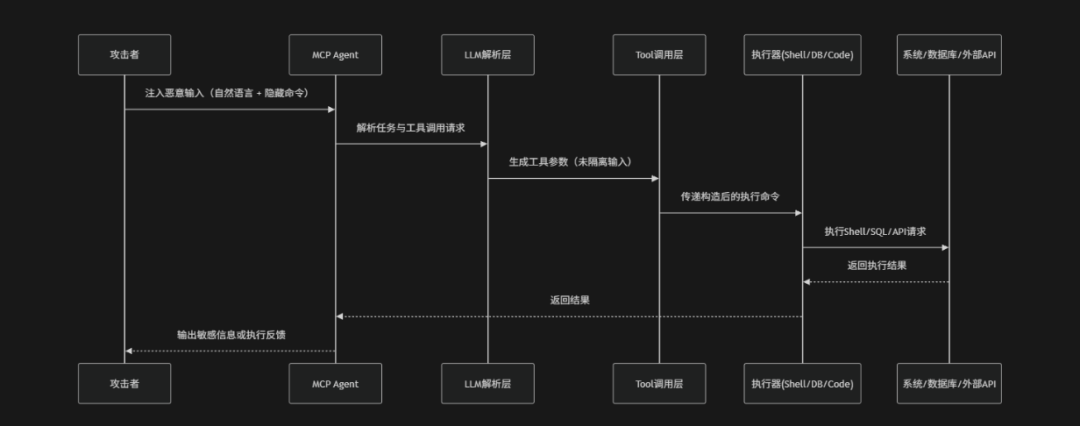
防御措施
- 结构化工具调用约束:强制所有MCP工具调用采用JSON Schema或强类型接口定义,对参数类型、长度、枚举值进行严格校验,避免自由文本进入执行层
- 执行层白名单机制:在Shell、数据库、API调用层设置严格白名单,仅允许预定义安全命令或API路径执行,禁止动态拼接或任意系统命令执行
- 命令转义参数化处理:对所有外部执行参数进行转义、编码或参数化处理(如SQL Prepared Statement),防止注入字符被解析为可执行逻辑
- 提示词与执行链隔离:在LLM输出与执行器之间引入安全网关(Policy Gateway),确保模型输出必须经过策略验证后才能进入执行阶段
- 输入与指令严格分离:通过将用户输入与系统执行指令彻底隔离,禁止LLM输出直接拼接为Shell命令、SQL语句或代码执行参数,所有执行内容必须来源于结构化字段而非自然语言文本
MCP06:意图流劫持
风险介绍
Intent Flow Subversion(意图流篡改)指的是在MCP(Model Context Protocol)驱动的AI Agent系统中攻击者通过干扰或逐步污染"任务意图流",使模型在多轮推理、任务拆解与工具调用过程中逐渐偏离用户原始目标,最终执行被篡改或替换后的隐性意图的一类安全风险。在MCP架构中Agent通常会将复杂任务拆解为多个子步骤并在上下文累积与工具链协同下逐步执行,而"意图流"正是这些连续决策与中间目标的动态演化路径。如果攻击者能够在任意环节(例如:Prompt输入、上下文注入、工具返回结果、记忆模块或中间规划步骤)引入偏置信息就可能逐步改变模型对最终目标的理解,例如:通过将"生成分析报告"逐步引导为"导出原始数据"或"访问敏感系统资源",此类攻击的关键特征在于其渐进性与隐蔽性:每一步单独看都可能是合理的,但整体意图已经被悄然替换,从而在不触发明显异常的情况下完成目标劫持。OWASP将其视为针对AI规划与推理链路的系统性攻击,其本质是对"多轮决策一致性"的破坏,使模型在看似正确执行局部任务的同时,完成错误的全局目标
攻击路径
- 初始合法任务锚定:攻击从用户提交的正常任务开始(例如:报告生成、数据分析等),系统建立初始意图作为"可信目标锚点",为后续意图流演化提供起点
- 上下文与中间结果污染:在工具返回结果、外部数据源或Prompt注入中嵌入偏置信息,通过语义暗示或扩展需求,引导模型对任务目标产生轻微偏移
- 意图逐步漂移与重写:在多轮推理与任务拆解过程中LLM不断更新子目标,将原始意图"合理扩展"或"优化替换",导致任务方向逐渐偏离初始目标
- 工具链驱动的目标放大:Agent在执行过程中调用更多工具或访问更高权限资源,每一步都符合当前子目标,但整体上不断扩大执行边界与数据访问范围
- 最终目标劫持与结果输出:当意图流完成完全偏移后,系统输出或执行的结果已脱离原始用户意图,可能导致数据泄露、越权访问或非预期操作完成攻击闭环
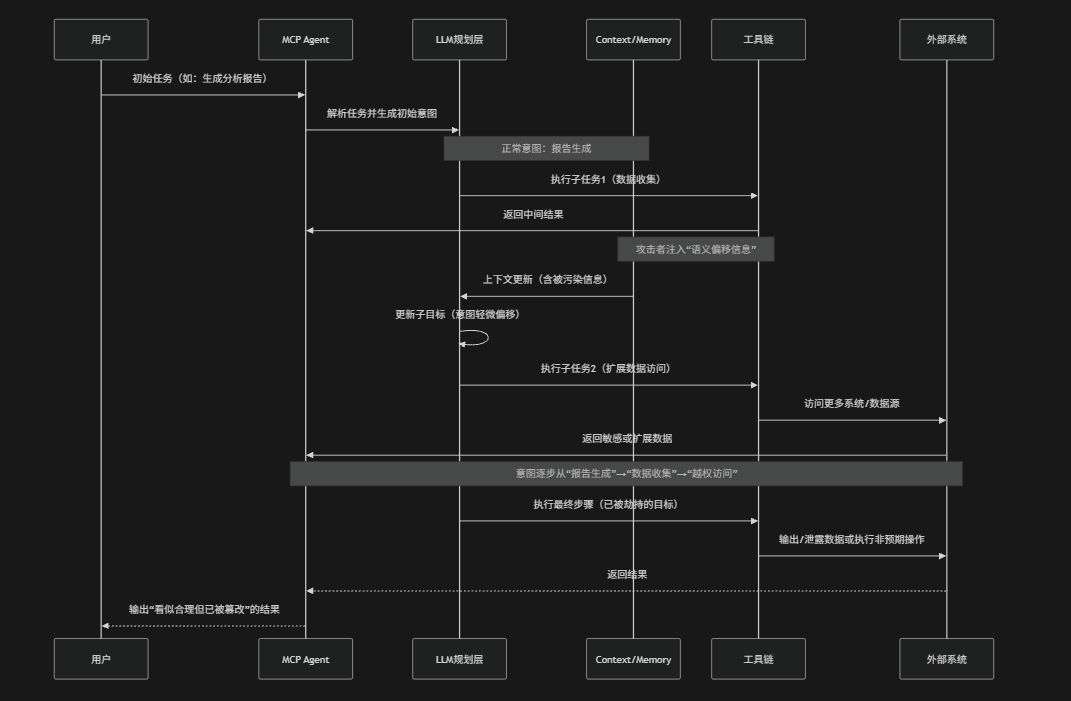
防御措施
┌──────────────────────────────────────────────────────────────┐
│ 📥 1. 依赖引入阶段(Source Intake) │
│ Package / SDK / Model / Plugin / Container Image │
└──────────────────────────────────────────────────────────────┘
│
▼
🔴【卡点1:可信来源控制(Trusted Source Gate)】
- 官方仓库白名单(Allowlist Registry)
- 发布者身份认证(Publisher Identity Verification)
- 非授权源阻断(Untrusted Source Blocking)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🔍 2. 依赖校验阶段(Verification Layer) │
│ Version Check / Signature / Hash / Metadata │
└──────────────────────────────────────────────────────────────┘
│
▼
🟠【卡点2:完整性验证(Integrity Verification)】
- 数字签名校验(Signature Verification)
- Hash一致性检查(Checksum Validation)
- 版本锁定(Version Pinning)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🧪 3. 构建分析阶段(Build-Time Security) │
│ CI/CD / Dependency Resolver / Build Pipeline │
└──────────────────────────────────────────────────────────────┘
│
▼
🟡【卡点3:供应链安全扫描(SCA + AI Scan)】
- SCA依赖漏洞扫描
- 恶意代码检测(Static + AI-based Scan)
- 依赖树风险分析(Dependency Graph Risk)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ ⚙️ 4. 部署阶段(Deployment Gate) │
│ Agent Runtime / Tool Loader / Container Runtime │
└──────────────────────────────────────────────────────────────┘
│
▼
🔵【卡点4:沙箱隔离执行(Sandboxed Deployment)】
- 容器/VM隔离执行
- 文件系统/网络访问限制
- 最小权限运行(Least Privilege Runtime)
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 🧠 5. 运行时阶段(Runtime Monitoring) │
│ MCP Agent / Tools / Dependencies Execution │
└──────────────────────────────────────────────────────────────┘
│
▼
🟣【卡点5:行为监控与异常检测(Runtime Defense)】
- 异常网络外联检测(Egress Monitoring)
- Tool调用行为分析
- 数据访问模式检测
- Prompt/Tool联动异常识别
│
▼
┌──────────────────────────────────────────────────────────────┐
│ 📊 6. 持续治理阶段(Continuous Defense) │
│ Audit / Telemetry / Threat Intelligence / Response │
└──────────────────────────────────────────────────────────────┘
│
▼
⚫【卡点6:自动响应与回滚(Auto Response System)】
- 自动回滚恶意版本(Rollback Mechanism)
- 紧急隔离依赖(Quarantine System)
- 攻击溯源分析(Forensics Pipeline)
- Threat Intelligence 联动更新MCP05:命令注入/执行
风险介绍
Command Injection & Execution(命令注入与执行风险)是指在MCP驱动的AI Agent系统中,攻击者通过构造恶意输入、Prompt注入或工具参数污染,使模型在调用外部工具、系统命令或API时将不可信数据错误地当作可执行指令,从而触发非预期的命令执行行为的一类安全风险。在MCP架构中Agent通常具备调用操作系统命令、数据库查询、代码执行器或外部API的能力,这些执行链路往往依赖于模型对自然语言指令的解析与工具参数的动态生成。如果输入未经过严格的结构化约束或安全过滤,攻击者可以通过"指令嵌套"、"参数拼接污染"或"上下文混淆"等方式将恶意命令隐藏在正常任务请求中,使模型在无感知情况下执行如shell命令、SQL注入、代码执行或远程API调用等高危操作。OWASP将其定义为典型的"AI执行链路注入风险",其本质是自然语言与可执行指令之间缺乏安全边界隔离,导致模型成为间接命令执行器
攻击路径
命令注入与执行攻击风险场景的攻击场景包括:
- 恶意输入注入:攻击者在自然语言请求中嵌入隐藏命令或危险语句(例如:Shell命令、SQL注入或代码执行片段),通过看似正常的任务描述污染原始输入层,为后续执行埋下基础
- 指令与数据混淆解析:LLM在解析用户输入时无法严格区分"任务描述"和"可执行指令",导致攻击者嵌入的恶意内容被误纳入工具调用逻辑或执行参数生成过程
- 工具参数拼接污染:工具调用阶段直接将LLM输出拼接为命令或查询语句,缺乏结构化约束、类型校验或转义机制,从而将恶意输入转化为可执行命令片段
- 不安全执行器直接执行:Shell、数据库或代码执行器在缺乏白名单与安全解析的情况下,直接执行拼接后的命令或脚本,使攻击指令在系统层面真实落地执行
- 攻击结果外溢与系统控制:恶意命令执行后导致敏感数据泄露、文件系统破坏、数据库篡改或外部API滥用,甚至形成持续控制或远程执行能力
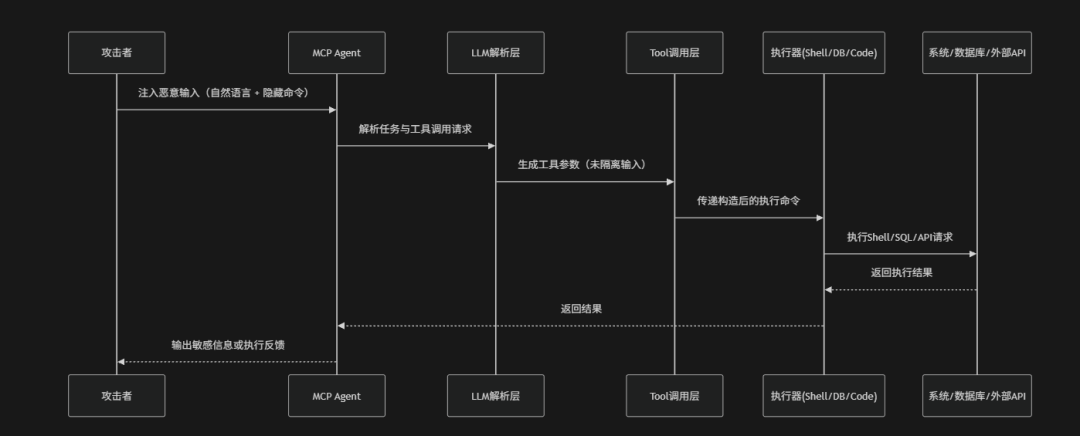
防御措施
- 结构化工具调用约束:强制所有MCP工具调用采用JSON Schema或强类型接口定义,对参数类型、长度、枚举值进行严格校验,避免自由文本进入执行层
- 执行层白名单机制:在Shell、数据库、API调用层设置严格白名单,仅允许预定义安全命令或API路径执行,禁止动态拼接或任意系统命令执行
- 命令转义参数化处理:对所有外部执行参数进行转义、编码或参数化处理(如SQL Prepared Statement),防止注入字符被解析为可执行逻辑
- 提示词与执行链隔离:在LLM输出与执行器之间引入安全网关(Policy Gateway),确保模型输出必须经过策略验证后才能进入执行阶段
- 输入与指令严格分离:通过将用户输入与系统执行指令彻底隔离,禁止LLM输出直接拼接为Shell命令、SQL语句或代码执行参数,所有执行内容必须来源于结构化字段而非自然语言文本
MCP06:意图流劫持
风险介绍
Intent Flow Subversion(意图流篡改)指的是在MCP(Model Context Protocol)驱动的AI Agent系统中攻击者通过干扰或逐步污染"任务意图流",使模型在多轮推理、任务拆解与工具调用过程中逐渐偏离用户原始目标,最终执行被篡改或替换后的隐性意图的一类安全风险。在MCP架构中Agent通常会将复杂任务拆解为多个子步骤并在上下文累积与工具链协同下逐步执行,而"意图流"正是这些连续决策与中间目标的动态演化路径。如果攻击者能够在任意环节(例如:Prompt输入、上下文注入、工具返回结果、记忆模块或中间规划步骤)引入偏置信息就可能逐步改变模型对最终目标的理解,例如:通过将"生成分析报告"逐步引导为"导出原始数据"或"访问敏感系统资源",此类攻击的关键特征在于其渐进性与隐蔽性:每一步单独看都可能是合理的,但整体意图已经被悄然替换,从而在不触发明显异常的情况下完成目标劫持。OWASP将其视为针对AI规划与推理链路的系统性攻击,其本质是对"多轮决策一致性"的破坏,使模型在看似正确执行局部任务的同时,完成错误的全局目标
攻击路径
- 初始合法任务锚定:攻击从用户提交的正常任务开始(例如:报告生成、数据分析等),系统建立初始意图作为"可信目标锚点",为后续意图流演化提供起点
- 上下文与中间结果污染:在工具返回结果、外部数据源或Prompt注入中嵌入偏置信息,通过语义暗示或扩展需求,引导模型对任务目标产生轻微偏移
- 意图逐步漂移与重写:在多轮推理与任务拆解过程中LLM不断更新子目标,将原始意图"合理扩展"或"优化替换",导致任务方向逐渐偏离初始目标
- 工具链驱动的目标放大:Agent在执行过程中调用更多工具或访问更高权限资源,每一步都符合当前子目标,但整体上不断扩大执行边界与数据访问范围
- 最终目标劫持与结果输出:当意图流完成完全偏移后,系统输出或执行的结果已脱离原始用户意图,可能导致数据泄露、越权访问或非预期操作完成攻击闭环
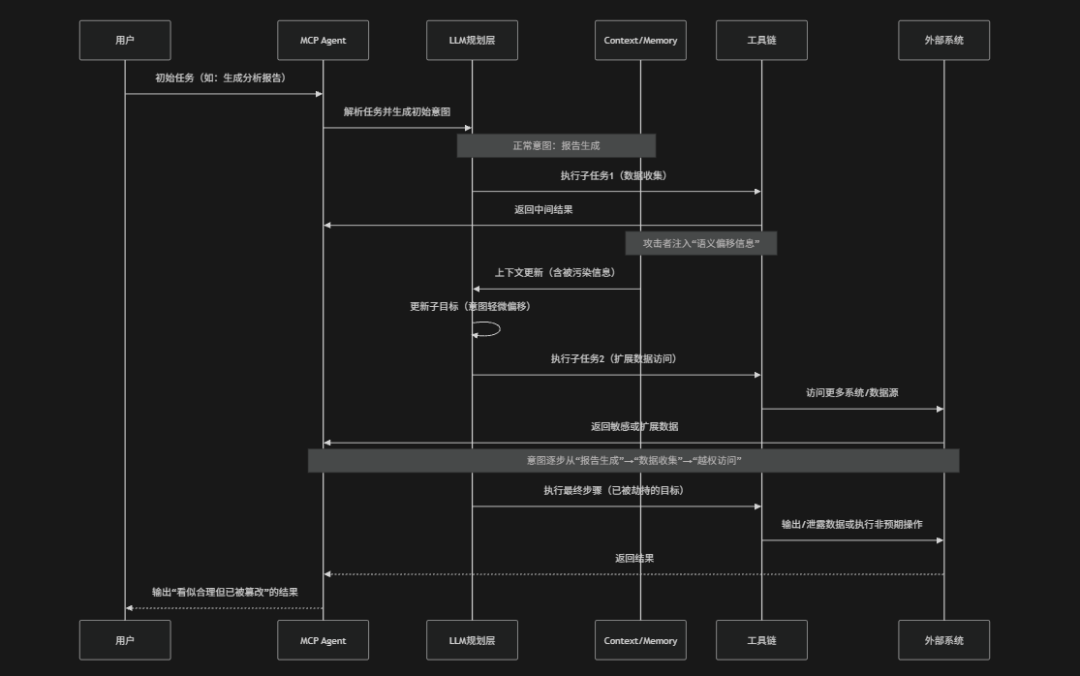
防御措施
- 初始意图锁定机制:在任务开始阶段对用户原始意图进行结构化固化(例如:目标摘要、约束条件、禁止操作边界)并在整个执行链中作为不可变参考基线,防止后续被逐步改写
- 跨轮意图一致性校验:在多轮对话与任务拆解过程中持续对比当前子目标与初始意图的一致性,一旦发现语义漂移或目标扩展异常立即触发告警或回滚
- 上下文污染检测与隔离:对工具返回结果、外部数据与历史记忆进行安全过滤,识别可能携带的目标诱导信息或隐性指令并与核心意图上下文隔离存储
- 任务边界约束与白名单化执行:为Agent设定明确的任务边界与允许操作集合,仅允许在授权范围内进行子任务扩展,禁止"自由式目标重写"
- 人机关键节点确认机制:在高风险操作或意图显著变化时引入用户确认步骤,防止Agent在无监督情况下执行被篡改后的目标路径
MCP07:认证授权不足
风险介绍
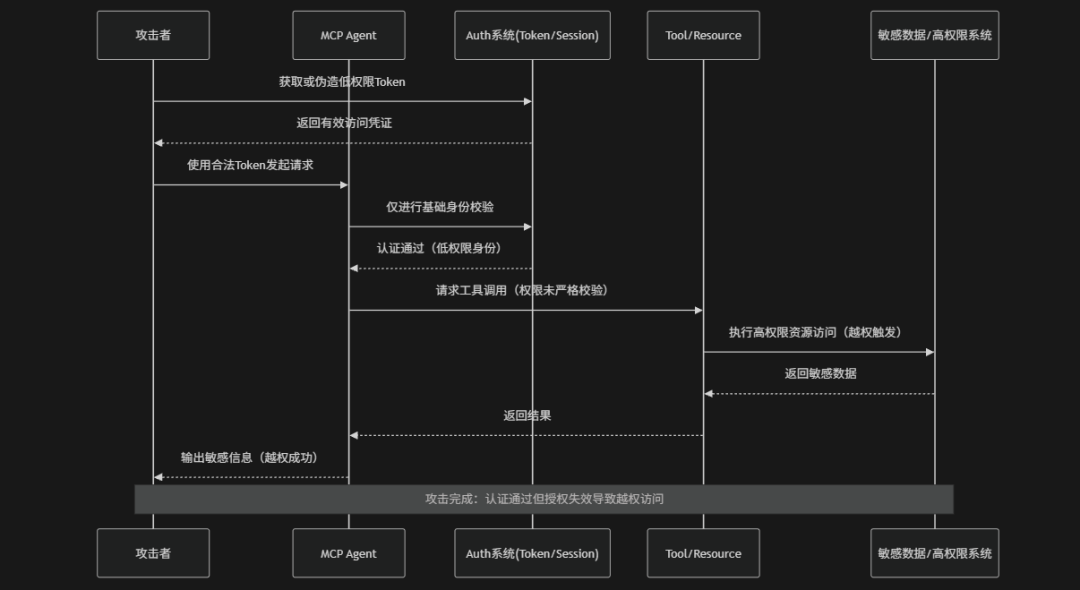
Insufficient Authentication & Authorization(认证与授权不足)是指在MCP驱动的AI Agent系统中由于身份验证机制薄弱或权限控制设计不完善,导致未授权用户、低权限用户或被劫持的Token能够访问敏感工具、数据或执行高风险操作的一类系统性安全风险。在MCP架构中Agent通常需要通过Token、API Key或会话身份来访问工具(Tools)、资源(Resources)以及外部系统,认证(Authentication)负责确认"你是谁",授权(Authorization)则主要负责决定"你能做什么"。如果系统仅依赖静态Token、弱身份校验或粗粒度权限模型就可能出现越权访问、身份伪造或权限继承问题。例如:低权限Agent通过上下文污染或Token复用访问高权限工具或未正确隔离不同用户会话导致数据交叉泄露。OWASP将其定义为典型的AI系统信任边界失效风险,其本质是身份可信性与权限控制在动态Agent环境中的断裂,使系统无法准确判断请求主体与操作边界,从而引发系统性越权执行与数据泄露风险
攻击路径
认证授权不足常见的攻击场景包括:
- 工具与资源越权访问:攻击者利用已通过认证的身份调用高权限工具或接口,通过工具链间接访问敏感系统、数据库或内部服务
- 敏感数据泄露与高危操作执行:最终阶段中,攻击者成功获取敏感数据或执行未授权操作,形成完整的越权访问攻击闭环
- 授权校验缺失或粗粒度控制:在工具或API调用阶段未进行细粒度权限校验,使低权限主体能够访问本不应授权的工具或资源
- 认证通过但缺乏上下文绑定:系统仅验证凭证有效性,但未将身份与设备、任务上下文或会话强绑定,导致同一凭证可在不同环境中被滥用
- 凭证获取与身份伪造:攻击者通过窃取、复用或伪造Token、API Key等身份凭证,以低成本进入系统认证边界并建立"表面合法"的访问身份
防御措施
- 最小权限原则:为Agent和Tool分配完成任务所需的最低权限,默认拒绝高风险操作,避免权限过度授予导致的潜在越权风险
- Tool级权限控制机制:在MCP Tool调用层引入独立权限校验模块,对每一次工具调用进行实时授权判断,而不是仅依赖前置认证
- 跨服务权限校验:在工具链调用多个服务时,对每个下游服务进行独立授权检查,防止权限在调用链中被隐式继承或放大
- Token生命周期与作用域管理:限制Token的有效时间和可访问范围(scope)并支持动态撤销与刷新机制,降低长期有效Token被滥用的风险
- 细粒度授权控制:对Tool、API和资源实施基于角色或基于属性的权限模型,确保每个Agent只能访问其明确授权范围内的功能与数据
- 上下文绑定与会话隔离:将身份与设备指纹、任务上下文或会话ID强绑定,防止Token跨环境复用或会话劫持,同时避免不同用户或任务之间的数据交叉访问
MCP08:缺乏审计遥测
风险介绍
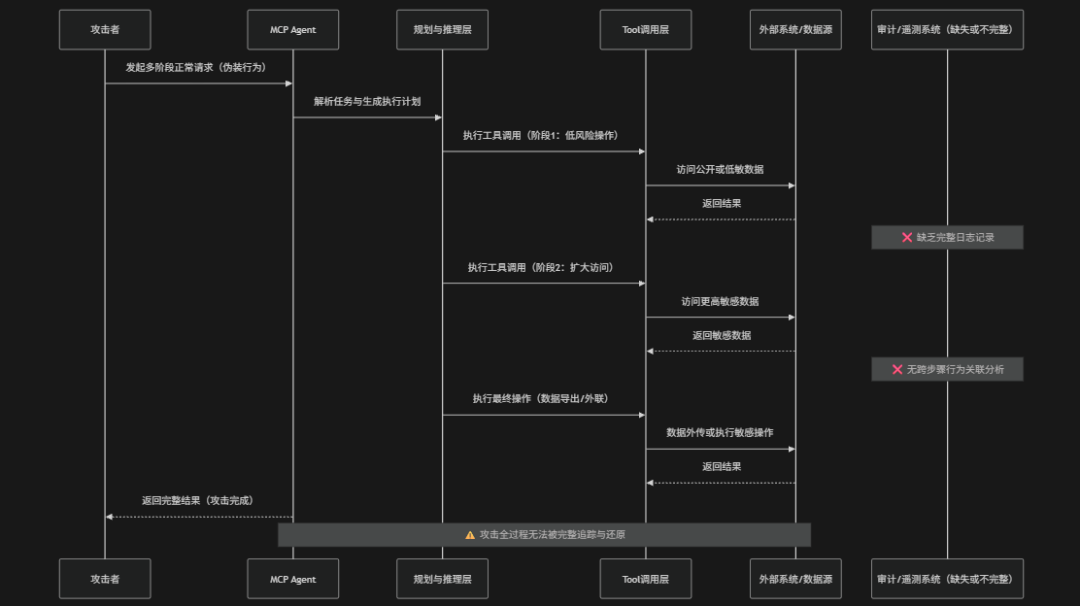
Lack of Audit and Telemetry(缺乏审计与遥测能力)是指在MCP驱动的AI Agent系统中由于缺少对模型行为、工具调用、数据访问与执行链路的完整记录与实时监控能力,导致系统在发生异常操作、越权访问或数据泄露时无法有效追踪、分析与响应的一类安全风险。在MCP架构中Agent通常会经历"意图解析 → 工具选择 → 参数生成 → 执行调用 → 外部交互"等多个阶段,如果缺乏统一的审计与遥测机制,这些关键行为就会变成"黑盒执行",攻击者可以在不留下明显痕迹的情况下完成数据外传、权限滥用或工具投毒触发。此外由于AI系统具有多轮交互与动态决策特性,一旦没有结构化日志与行为追踪能力,安全团队将难以还原攻击路径或识别异常意图流。OWASP将其定义为典型的"可观测性缺失型风险",其本质是系统无法回答三个关键问题:发生了什么、是谁做的、影响有多大,从而导致安全响应与攻击溯源能力整体失效
攻击路径
- 低噪声初始行为伪装:攻击者首先发起与正常用户行为一致的请求以合法交互形式混入系统正常流量中,降低被检测概率
- 阶段权限数据访问升级:在多轮交互中逐步扩大访问范围,从低敏数据逐步过渡到高敏资源访问,每一步操作单独看均符合正常业务逻辑
- 工具链组合式隐蔽调用:通过多个工具或API的串联调用完成攻击目标,每个单独工具调用均无明显异常,使整体攻击链难以被拆解识别
- 审计遥测缺失链路不可见:系统缺乏统一日志与遥测能力,无法关联多步骤工具调用与行为轨迹,导致攻击路径无法被完整还原
- 数据外传与攻击闭环完成:敏感数据在无告警或无追踪的情况下被逐步导出或外传,攻击行为完成但系统未能识别或响应
防御措施
全链路审计与统一日志体系对MCP系统中从"用户输入 → LLM推理 → Tool调用 → 外部执行 → 返回结果"的每一步进行结构化日志记录,确保所有行为具备可追溯性与可重放能力
- 工具调用级遥测埋点:在每一次Tool/API调用层面植入遥测埋点,记录调用主体、输入参数、返回结果、执行时间与资源访问情况,实现细粒度行为可观测性
- 意图-行为关联追踪:通过将用户原始意图与后续所有子任务、工具调用进行链路绑定,构建"意图执行图谱",用于识别偏离或异常执行路径
- 异常行为实时检测与告警:基于行为基线模型监控工具调用频率、数据访问模式与执行路径,一旦发现异常数据导出、批量访问或非典型调用链立即触发告警
MCP09:影子MCP服务
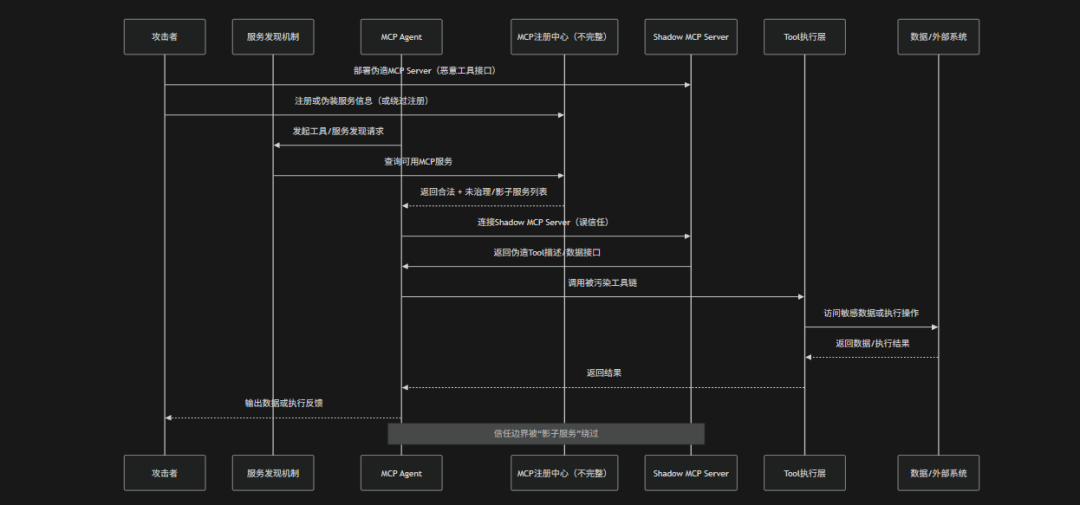
风险介绍
Shadow MCP Servers(影子MCP服务器)是指在MCP生态中存在未被纳入统一治理、缺乏身份认证与安全审计的"隐形或非官方MCP服务节点",这些服务器可能由内部团队、第三方插件、临时部署环境或攻击者私自搭建,却仍然被Agent发现并调用,从而形成系统性的信任边界绕过风险。在典型架构中MCP Agent会通过服务发现机制或配置注册表访问工具与资源,但当存在Shadow MCP Server时,这些未登记或未受控的服务可能提供伪造工具接口、恶意数据源或后门功能,使得Agent在无感知情况下连接到不可信执行环境。攻击者可以利用这一点伪装合法MCP服务,诱导Agent调用恶意工具,从而实现数据窃取、指令劫持或权限滥用。OWASP 将其视为"分布式AI基础设施中的信任断层风险",其本质是MCP生态中服务发现与治理机制缺失,导致系统无法区分"官方可信服务"与"影子恶意节点",从而破坏整体安全边界
攻击路径
影子MCP服务器本质是攻击者通过引入或劫持"未纳管的MCP服务节点",让Agent在服务发现或工具调用过程中误连到非可信执行环境
- Shadow MCP服务器部署:攻击者伪造或部署非官方MCP服务器,冒充内部工具节点或第三方插件服务,从源头制造"伪可信服务"
- 服务发现机制污染:利用注册中心缺失、配置泄露或弱治理机制,使Shadow MCP Server混入Agent可发现的服务列表中,进入潜在调用范围
- 非可信服务绑定与连接:Agent在缺乏强身份验证与服务签名校验的情况下,错误连接到Shadow MCP Server,建立错误的信任链路
- 伪造工具接口与Schema注入:Shadow Server返回伪造的Tool描述、参数结构或能力声明,使Agent误认为其为合法工具并纳入执行计划
- 恶意工具调用与执行污染:Agent调用被污染的工具链,由Shadow MCP Server控制执行逻辑,触发数据访问、指令执行或外部请求
- 数据外泄与远程控制完成:攻击者通过Shadow MCP Server获取敏感数据或操控Agent执行非预期操作,完成完整攻击闭环
防御措施
- 服务注册中心强治理:建立统一的MCP服务注册与管理中心,所有工具与MCP Server必须通过官方注册流程纳管,未注册服务默认禁止被发现或调用,从源头阻断Shadow Server接入路径
- 服务身份强认证机制:对每一个MCP Server引入数字证书或签名机制,Agent在连接服务前必须验证其身份合法性,防止伪造服务节点冒充可信工具
- 工具签名与完整性校验:对Tool schema、接口描述与执行逻辑进行签名保护,确保工具定义未被篡改或注入恶意能力声明
- 服务发现白名单机制:限制Agent仅能从预定义白名单或可信注册表中发现MCP服务,禁止动态接入未知或未验证的服务节点
- Zero Trust MCP访问模型:默认不信任任何MCP Server,即使是内部网络服务也需进行持续认证、授权与上下文验证,避免“内网即可信”的假设
MCP10:上下文注入/共享
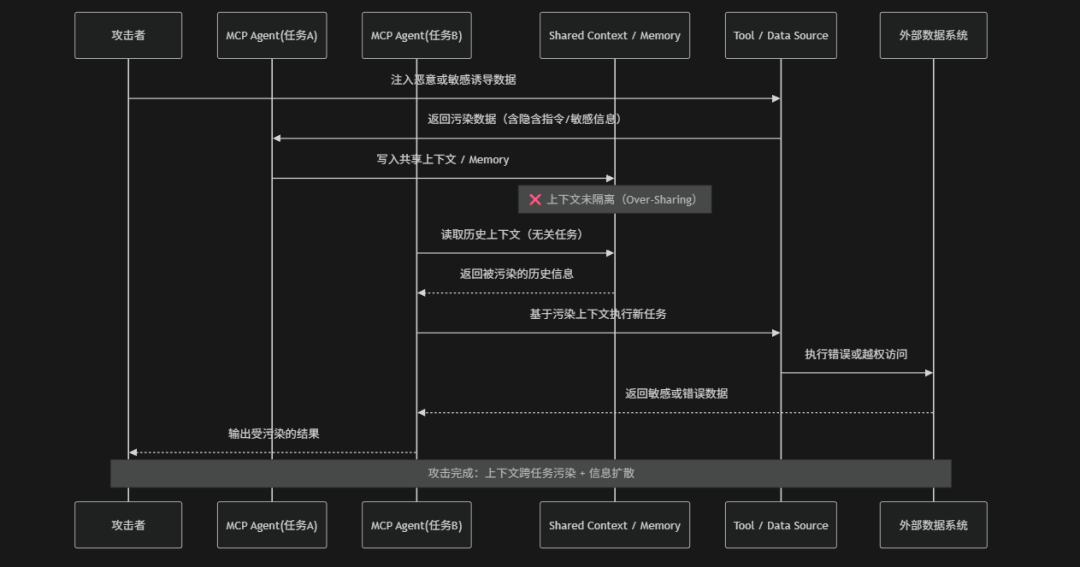
风险介绍
Context Injection & Over-Sharing(上下文注入与过度共享)是指在MCP驱动的AI Agent系统中由于上下文管理机制缺乏隔离与最小化原则,导致不同任务、用户或工具之间的敏感信息被错误注入或过度共享,从而引发数据泄露、权限越界或隐私暴露的一类系统性安全风险。在MCP架构中Agent依赖共享上下文(Context Window、Memory、Tool Output、Session State)来维持多轮推理与任务连续性,但如果没有严格的上下文分区与访问控制就可能出现一个任务的历史数据被带入另一个无关任务中或者低权限请求意外继承高权限上下文信息。例如:工具返回的敏感字段被写入全局记忆、不同用户会话之间发生上下文污染或外部数据源注入恶意上下文内容影响模型决策。OWASP将其视为典型的"上下文边界失效风险",其本质是AI系统未能正确区分"该看见什么"和"不该共享什么",导致信息在多Agent、多工具、多会话之间非预期扩散,从而扩大攻击面并造成数据泄露隐患
攻击路径
上下文注入与过度共享常见攻击路径:
- 上下文注入入口:攻击者通过工具返回结果、Prompt注入或外部数据源输入将恶意或误导性信息注入MCP上下文体系,使其被系统误判为有效信息并进入处理链路
- 共享记忆污染:被注入的信息被写入共享上下文或长期记忆(Memory),由于缺乏来源隔离与安全过滤机制,导致污染信息在系统中持续存在
- 跨任务上下文复用泄露:不同任务或不同Agent实例复用同一上下文或记忆数据,使原本属于某一任务的信息被错误带入其他无关任务中实现信息跨域扩散
- 污染上下文驱动错误决策:LLM在推理与规划过程中依赖被污染的上下文信息,导致工具选择、参数生成或任务拆解出现偏差,从而执行错误操作路径
- 数据泄露与攻击结果放大:错误上下文进一步驱动工具访问敏感数据或执行非预期操作,最终导致数据泄露、权限误用或错误决策被放大并完成攻击闭环
防御措施
- 上下文分区与隔离机制:为不同用户、任务和Agent建立独立的上下文空间,避免共享Context Window或Memory直接互通,从结构上阻断跨任务信息污染与扩散
- 最小上下文共享原则:仅允许必要信息在任务链路中流转,禁止默认全量上下文继承,通过显式字段控制上下文传递范围与内容粒度
- 上下文来源标记与可信度评估:对所有进入上下文的数据进行来源标记(Tool/Prompt/Memory/External Source)并评估可信等级,低可信信息不得进入核心决策链
- 共享记忆安全过滤机制:在写入长期记忆(Long-term Memory)前进行敏感信息检测与恶意意图过滤,防止提示注入或数据污染被持久化
- 跨任务上下文访问控制:引入任务级权限控制机制,限制一个任务对其他任务历史上下文或记忆的访问权限,防止跨任务数据复用泄露
- 上下文注入检测与防护:通过规则引擎或模型检测上下文中是否存在指令嵌套、隐性控制语句或异常语义结构,识别并拦截潜在注入内容
- 上下文生命周期管理:对短期上下文、会话上下文与长期记忆进行分层管理与自动过期机制,减少历史数据长期污染当前决策的风险
参考链接
https://owasp.org/www-project-mcp-top-10/
推 荐 阅 读
图片

图片
图片
图片
图片
横向移动之RDP&Desktop Session Hija
图片
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号