哈哈哈哈哈打不过我吧,没有办法我(vllm)就是这么强大!


文本(Text)是离散的,由词元(Token)组成;而图像、视频是连续的像素或信号。 扩散模型天生擅长处理连续数据, 文生图和文生视频的是当前扩散模型的主战场。
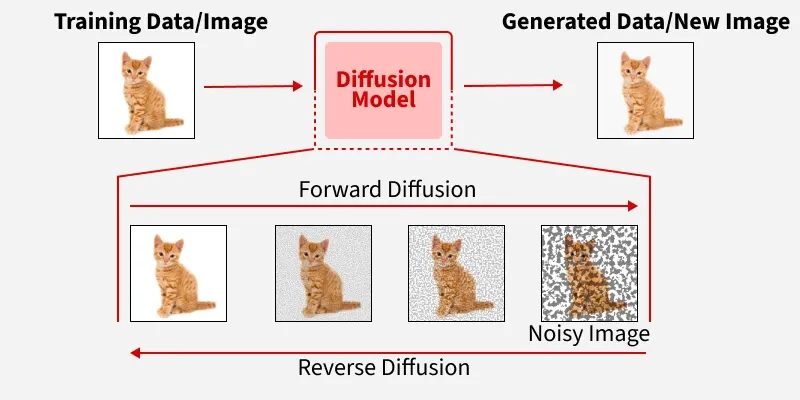
什么是扩散模型diffusion models?
使用文生图工具时,内部真实发生的“魔法”:
起点:你看到的完全随机的噪声图,这相当于前向过程走到了终点。
反向去噪第一步:
模型看着这张纯噪声图,结合你的提示词,预测出“这张图上现在应该被加上了什么噪声”。
然后,从当前图片中减去这个预测出的噪声。
结果得到一张噪声少了一点点的、略微能看出模糊轮廓的图片。
循环往复:把上一步得到的、稍微清晰一点的图片作为新的输入,再次让模型预测并减去噪声。
终点:重复几十步后,噪声被逐步移除干净,一张清晰的、符合你描述的图片就诞生了。
这个一步步预测并减去噪声的循环,从方向上看是前向加噪的“反向”,从动作上看就是在“去噪”。
vllm旗下的子项目vllm-omni[1]提供了简单、快速且低成本的多模态模型服务。
Z-Image[2]是阿里开源的完整版本、未经蒸馏的的 Transformer 文生图模型, 10.26B权重参数, 20.55GB GPU显存, 专为高质量、强生成多样性、广泛的风格覆盖能力以及精准的提示词遵循而设计。
启动推理服务器:
vllm serve Tongyi-MAI/Z-Image --omni --port 8000 --tensor-parallel-size 2
注意: 不是原生vllm(对应的docker镜像是vllm-openai[3])带omni参数, 而是一个包含omni扩展的多模态vllm (对应的docker镜像是vllm-omni[4])。
支持两种接口, 都是兼容openai的接口
- Diffusion Chat Completions API[5]: 希望在类似聊天机器人的多模态、多轮对话中集成图像生成能力
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": "A beautiful landscape painting"}
],
"extra_body": {
"num_inference_steps": 50,
"seed": 42
}
}'
- Image Generation API[6] : 稳定、专注于图像生成
输出的二进制图片被base64 编码,解码可得图片。
curl -X POST http://localhost:8000/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"prompt": "a dragon laying over the spine of the Green Mountains of Vermont",
"size": "1024x1024",
"seed": 42
}' | jq -r '.data[0].b64_json' | base64 -d > dragon.png
参考资料
[1]
vllm-omni: https://github.com/vllm-project/vllm-omni
[2]
Z-Image: https://www.modelscope.cn/models/Tongyi-MAI/Z-Image
[3]
vllm-openai: https://hub.docker.com/r/vllm/vllm-openai
[4]
vllm-omni: https://hub.docker.com/r/vllm/vllm-omni
[5]
Diffusion Chat Completions API: https://docs.vllm.ai/projects/vllm-omni/en/latest/serving/diffusion_chat_api/
[6]
Image Generation API: https://docs.vllm.ai/projects/vllm-omni/en/latest/serving/image_generation_api/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号