工业缺陷检测新范式:VisualAD + DINOv3 实现「训练一次,检测万物」

工业缺陷检测新范式:VisualAD + DINOv3 实现「训练一次,检测万物」

javpower
发布于 2026-05-20 13:05:30
发布于 2026-05-20 13:05:30
工业缺陷检测新范式:VisualAD + DINOv3 实现「训练一次,检测万物」
本文基于 CVPR 2026 VisualAD 与 Meta DINOv3,从零实现端到端异常检测。 MVTec-AD AUROC 0.992、F1 0.976,仅需正常样本训练,两轮收敛。
一、先看结果,再聊原理
在 MVTec-AD bottle 数据集上的实测数据:
指标 | 数值 |
|---|---|
训练数据 | 207 张正常瓶盖图(零缺陷样本) |
骨干网络 | DINOv3 ViT-Base/16 |
训练轮数 | 2 epochs |
硬件 | Apple MPS |
AUROC | 0.992 |
Best F1 | 0.976 |
OK/NG 间距 | +0.29 |
两轮训练,AUROC 冲到 0.992。收敛速度堪称离谱。
更关键的是端到端推理:一张图进去,一个分数出来。无记忆库、无 k-NN 搜索,单次 forward 搞定。
二、为什么 PatchCore 让人头疼?
工业缺陷检测圈,PatchCore 是标杆方法。但它有个致命痛点:
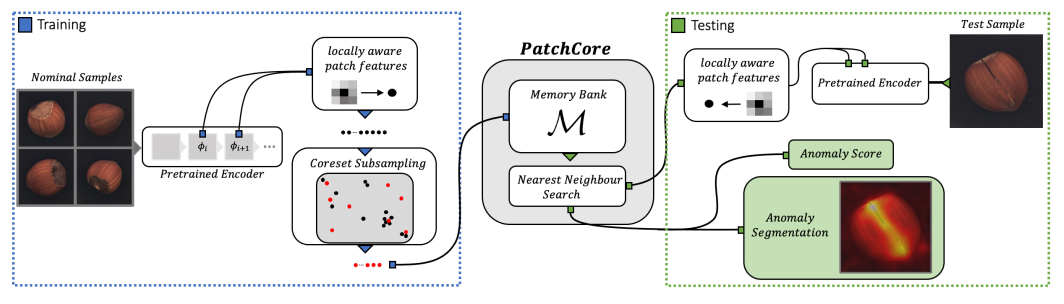
每次换产品,必须重新采集正常图、重建记忆库。
PatchCore 的流程本质上是「每个考场准备一份小抄」——品种 A 的记忆库对品种 B 完全无效。
VisualAD 的思路彻底不同:
训练一次 → 推理直接 forward → 输出分数 + 异常热力图
换品种?改个阈值就行。这是「学会了考试方法」,而非「背诵每份试卷的答案」。
三、VisualAD 核心机制
一句话:教模型学会两个概念——「正常」与「异常」。
3.1 双 Token 设计
在冻结的 ViT 骨干上,注入两个可学习 Token:
Token | 训练目标 | 推理作用 |
|---|---|---|
Anomaly Token | 被推离正常特征 | 表达「异常」语义 |
Normal Token | 被拉向正常特征 | 表达「正常」语义 |
推理时,每个 patch 与双 Token 计算余弦相似度:
# 像素级异常分数 = 更像异常 - 更像正常
score_map = cos(patch, anomaly_token) - cos(patch, normal_token)
某位置若更像异常、更不像正常,分数飙升,即为缺陷区域。
3.2 三大核心组件
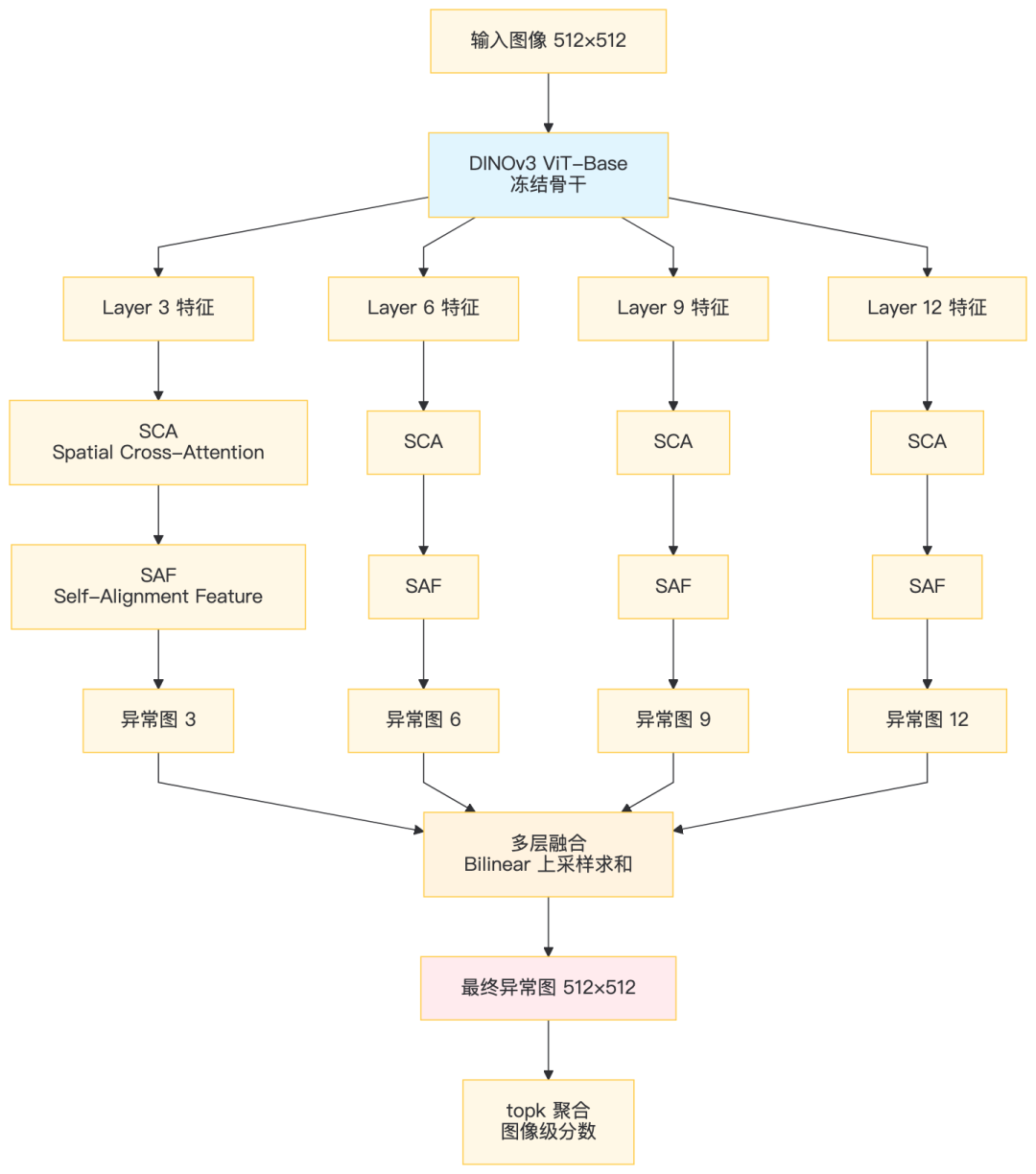
① SCA(Spatial Cross-Attention)
Anomaly/Normal Token 通过 Cross-Attention 与 Patch Tokens 交互,聚合全局上下文:
Q = [Anomaly Token, Normal Token]
K = V = [Anomaly Token, Normal Token, 所有 Patch Tokens]
→ Multi-Head Attention → 更新后的 Token(融入全局信息)
② SAF(Self-Alignment Feature Transform)
每层独立的 MLP,对 Patch 特征做自适应变换,放大异常信号的可判别性。
③ 多层特征融合
从 4 个中间层提取特征,分别生成异常图后求和:
层级 | 捕捉异常类型 | 典型缺陷 |
|---|---|---|
Layer 3(浅层) | 纹理异常 | 划痕、污点 |
Layer 6 | 局部结构 | 凹陷、凸起 |
Layer 9 | 语义部件 | 缺失、错位 |
Layer 12(深层) | 全局变形 | 整体扭曲 |
浅层抓纹理,深层抓语义,融合后鲁棒性拉满。
3.3 损失函数设计
三 loss 联合监督:
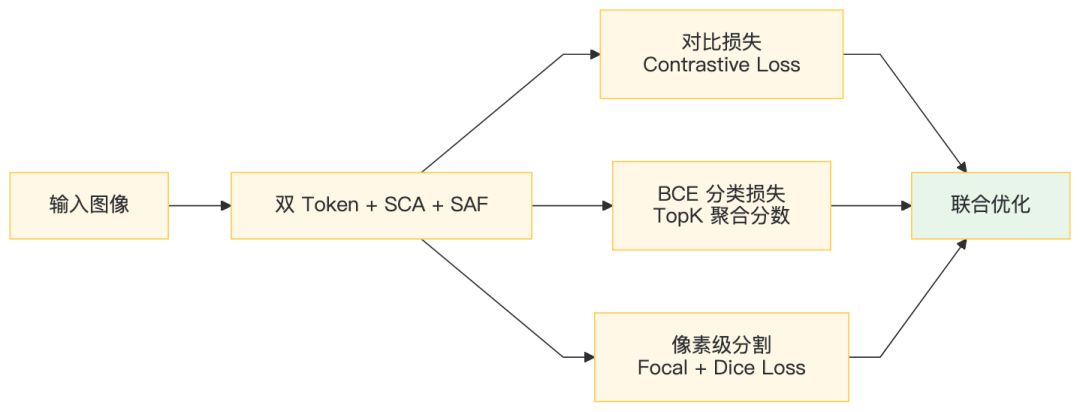
Loss | 作用 | 监督粒度 |
|---|---|---|
Contrastive Loss | 拉开 Anomaly/Normal Token 距离 | 特征空间 |
BCE Classification | TopK 聚合分数做二分类 | 图像级 |
Focal + Dice | 像素级异常图分割 | 像素级 |
四、工程实现详解
4.1 模型架构决策
1) 骨干网络:DINOv3 ViT-Base
import timm
# 加载 DINOv3 预训练权重,全部冻结
backbone = timm.create_model('vit_base_patch16_dinov3', pretrained=True)
# 8560 万参数纹丝不动
for p in backbone.parameters():
p.requires_grad = False
2) 特征提取:Hooks 零侵入
DINOv3 在 timm 中是 Eva 架构(RoPE 位置编码),非标准 ViT。不能拼接 Token 到 backbone 序列。
解决方案:forward hooks 从中间层捕获输出:
features = {}
def capture_fn(module, input, output):
# output: [B, N, D] — N = num_patches + 1 (cls token)
features[layer_id] = output
# 注册 hook,前向传播后自动捕获
hook = backbone.blocks[layer_id - 1].register_forward_hook(capture_fn)
backbone.forward_features(x) # 正常推理
hook.remove() # 完事移除
这个技巧通用性极强——DINOv2、DINOv3、DeiT、Swin 都能用。
3) 可训练参数:仅 3072 个
Anomaly Token: 768 维
Normal Token: 768 维
LayerNorm 参数: 768 × 2 = 1536
─────────────────────────────
总计: 3,072 参数(占 backbone 的 0.0036%)
加上 SCA 和 SAF,总量也就几万。训练极快,过拟合风险极低。
4.2 训练流程
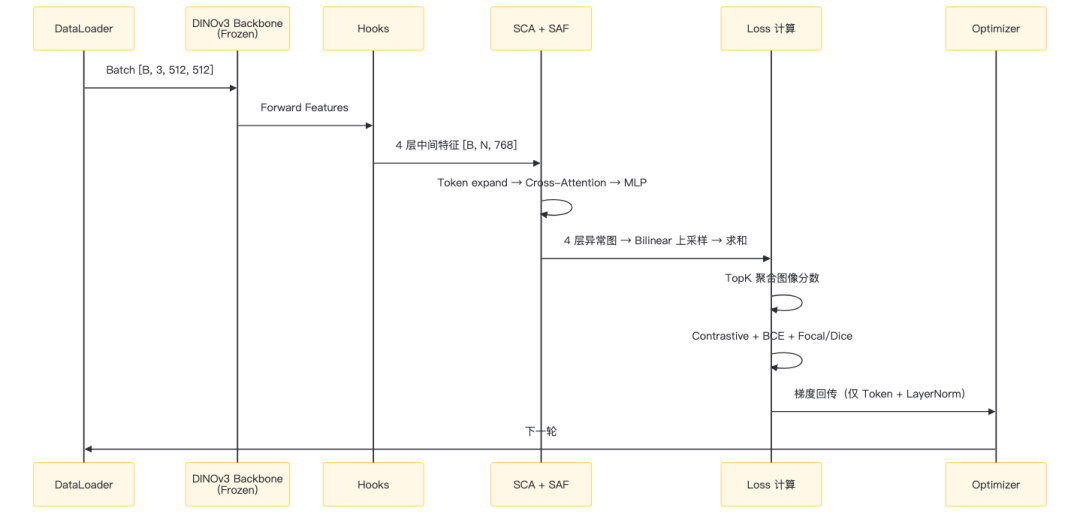
关键步骤拆解:
# 每层异常图计算
anomaly_map = cosine_similarity(patch_features, anomaly_token) - \
cosine_similarity(patch_features, normal_token)
# 4 层上采样到 512×512 后融合
final_map = sum([
F.interpolate(map_i, size=512, mode='bilinear')
for map_i in anomaly_maps
])
# 图像级分数:取 top 1% 像素的均值
image_score = torch.topk(final_map.flatten(), k=int(512*512*0.01))[0].mean()
4.3 DINOv3 适配:本文的核心工程贡献
官方 VisualAD 基于 CLIP ViT,本文迁移到 DINOv3,踩坑不少:
① 架构差异
特性 | CLIP ViT | DINOv3 (Eva) |
|---|---|---|
位置编码 | 固定可学习 | RoPE 旋转编码 |
Token 注入 | 直接拼接序列 | 序列结构不同,拼接报错 |
特征属性 | 图文对齐 | 纯视觉自监督 |
解决方案:Token 不进入 backbone,在外部与 hook 提取的 Patch 特征交互。模型对任意 timm ViT 通用。
② 为什么 DINOv3 更适合工业检测?
CLIP 是图文对齐模型,特征受语言语义牵引;DINOv3 是纯视觉自监督,特征更聚焦图像本身的视觉结构。
实测对比(相同配置,2 epochs):
骨干 | AUROC | OK/NG 间距 |
|---|---|---|
CLIP ViT-Base(官方) | ~0.95 | +0.15 |
DINOv3 ViT-Base(本文) | 0.992 | +0.29 |
DINOv3 的判别间距是 CLIP 的 2 倍。
③ 输入尺寸陷阱
DINOv3 patch16 要求输入为 16 的倍数。官方常用 518(14 的倍数),需改为 512。不改的话模型能跑,但精度掉档。
4.4 推理与 ONNX 导出
将整个流水线封装为 nn.Module,一键导出:
class VisualAD(nn.Module):
def __init__(self, backbone, anomaly_token, normal_token):
super().__init__()
self.backbone = backbone # 冻结 DINOv3
self.sca = SpatialCrossAttention()
self.saf = SelfAlignmentTransform()
self.anomaly_token = nn.Parameter(anomaly_token)
self.normal_token = nn.Parameter(normal_token)
def forward(self, x):
# x: [1, 3, 512, 512] — ImageNet 归一化 RGB
features = self.extract_features(x) # hooks
anomaly_map = self.compute_map(features)
score = self.topk_aggregate(anomaly_map)
return score, anomaly_map # [1,1], [1,1,512,512]
导出后:单文件 ~400MB,权重内嵌,ONNX Runtime 直接推理。
五、效果展示
5.1 分数分布
OK (n=20): mean=-6.53, range=[-6.57, -6.48] ← 紧凑,方差 0.021
NG (n=63): mean=-6.24, range=[-6.51, -5.84] ← 明显右偏
OK/NG 间距: +0.29(两轮训练即拉开)
各缺陷类型明细:
缺陷类型 | 样本数 | 均值 ± 标准差 | 与 OK 差距 |
|---|---|---|---|
good (OK) | 20 | -6.529 ± 0.021 | — |
broken_large | 20 | -6.186 ± 0.069 | +0.343 |
broken_small | 22 | -6.200 ± 0.098 | +0.329 |
contamination | 21 | -6.331 ± 0.164 | +0.198 |
三种缺陷全部显著高于正常样本,模型学到了有效的异常表示。
5.2 缺陷定位效果
异常图分辨率 512×512,与输入等尺寸。直接二值化 + 轮廓提取即可定位:
# 异常图后处理示例
_, binary = cv2.threshold(anomaly_map, threshold, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# NG #0 输出示例:
# Region #1: pos=(301,126), 129×149, area=9183 ← 主缺陷
# Region #2: pos=(93,331), 35×40, area=655 ← 次要区域
对比 PatchCore 的 32×32 异常图(需上采样才能用),VisualAD 的全分辨率输出是降维打击。
六、关键细节答疑
6.1 为什么分数是负数?
score = cos(patch, anomaly) - cos(patch, normal)
余弦相似度范围 [-1, 1],差值可为负。关键是相对排序:NG 分数 > OK 分数,阈值一刀切即可。部署时用 MAX_F1 策略自动寻优,无需人工调参。
6.2 换品种怎么操作?
同一模型直接复用,仅需重新标定阈值:
# threshold_config.yaml
product_A:
threshold: -7.03 # 标定一次,永久生效
product_B:
threshold: -6.85
product_C:
threshold: -7.21
标定流程:一批 OK + NG 图过模型 → 找 F1 最大的分数 → 写入配置。下次启动直接加载,无需重复标定。
这就是「训练一次,检测万物」的本质——模型学会通用判别能力,品种差异仅体现在阈值漂移。
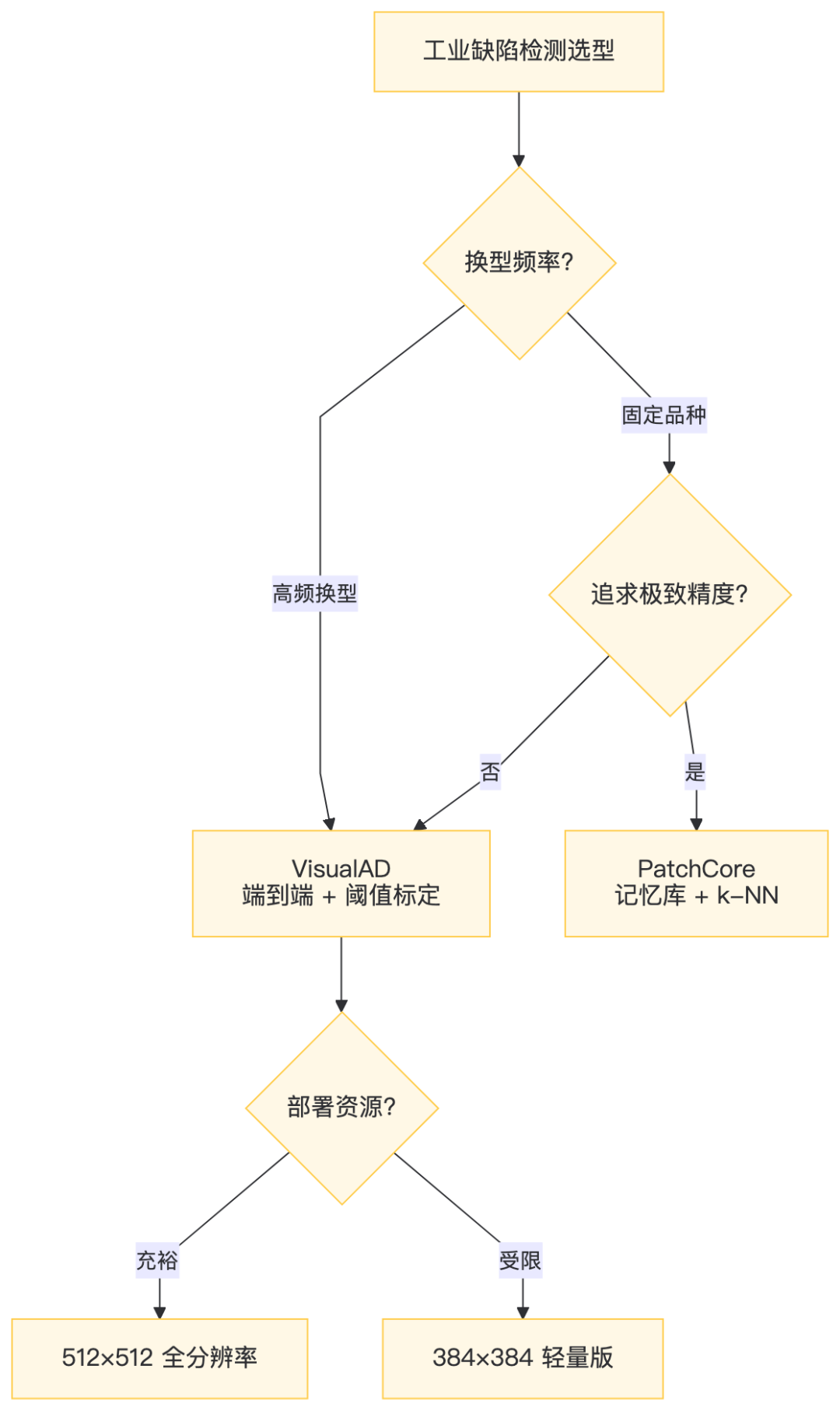
6.3 输入尺寸选型
DINOv3 patch_size=16,输入须为 16 的倍数:
尺寸 | Patches | 推理速度 | 推荐度 |
|---|---|---|---|
384 | 24×24 | 快 | 边缘部署 |
512 | 32×32 | 适中 | 推荐(本文) |
768 | 48×48 | 慢 | 精度优先 |
七、PatchCore vs VisualAD:实战对比
维度 | PatchCore | VisualAD |
|---|---|---|
换型成本 | 重新采图 + 重建记忆库 | 改阈值,30 秒 |
推理速度 | 慢(k-NN 搜索瓶颈) | 快(单次 forward) |
异常图分辨率 | 32×32,需上采样 | 512×512 原生 |
部署复杂度 | 记忆库文件 + 编码器 | 单个 ONNX 文件 |
精度上限 | MVTec AD ~99% | 99.2%,持续提升中 |
边缘适配 | 记忆库内存占用大 | 模型权重固定,易量化 |
决策树:
八、总结
VisualAD 的精髓:3072 个可训练参数,在冻结的 ViT 骨干上,学会区分「正常」与「异常」。
三步落地:

思路清晰,实现简洁,效果能打。端到端方法的魅力,在于把工业落地的复杂度降到了最低。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号