多模态融合的「流式革命」:CaReFlow 用校正流打通模态鸿沟

多模态融合的「流式革命」:CaReFlow 用校正流打通模态鸿沟

javpower
发布于 2026-05-20 13:08:25
发布于 2026-05-20 13:08:25
多模态融合的「流式革命」:CaReFlow 用校正流打通模态鸿沟
本文深入解读 CVPR 2026 CaReFlow,首次将 Rectified Flow 引入多模态情感计算。 在 CMU-MOSI 上 Acc2 87.3%、CH-SIMS-v2 上 Acc5 提升 4%+,仅用 Concat + MLP 融合即达 SOTA。
一、先看问题:为什么多模态融合总是「貌合神离」?
多模态情感计算(Multimodal Affective Computing, MAC)的核心矛盾:
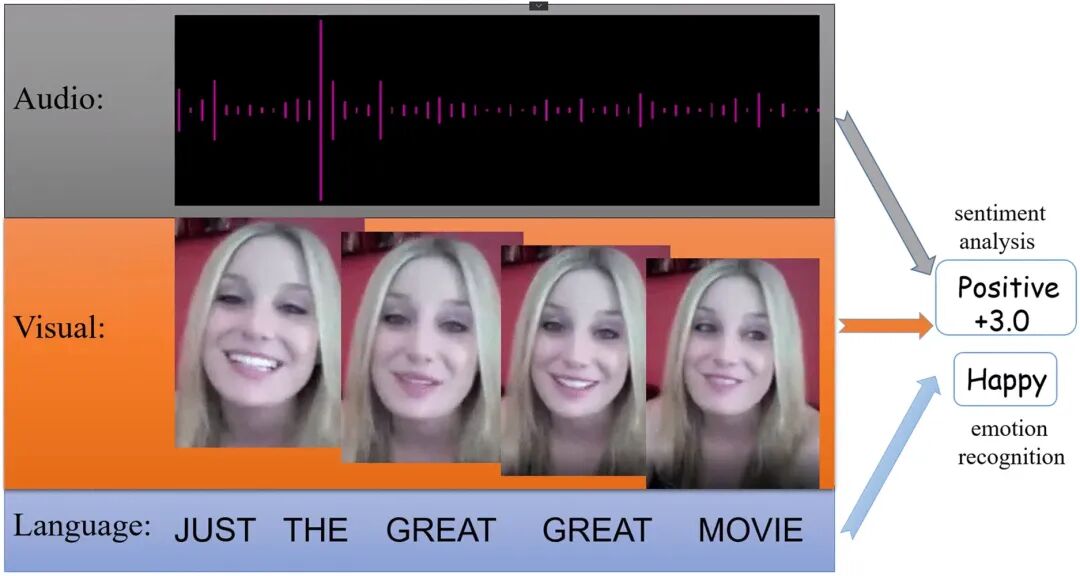
视频、音频、文本三种模态,在特征空间里各自为政。
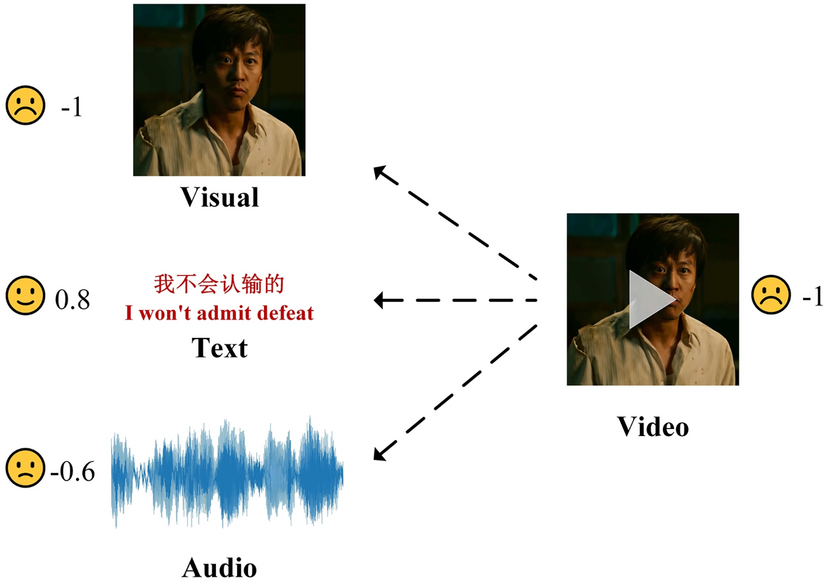
如图,同一段视频中:
- 视觉模态(人脸表情)说「难过」
- 文本模态(字幕)说「我不会认输的」—— 偏积极
- 音频模态(语调)说「勉强」—— 中性偏消极
三个模态的 feature 分布在特征空间的不同角落,强行拼接(Concat)+ MLP,模型根本学不会它们的关联。这就是 Modality Gap(模态鸿沟)。
更扎心的是:vanilla 多模态模型(简单拼接 + MLP)的表现,甚至不如单用语言模态。
二、传统方法的局限:一对一的「盲人摸象」
现有方案怎么填这个坑?
方法 | 代表工作 | 核心思路 | 局限 |
|---|---|---|---|
对比学习 | Hybrid CL | 拉近正样本、推开负样本 | 只关注 instance-level,忽略全局分布 |
多模态 Transformer | MulT | Cross-Attention 软对齐 | 需要大量配对数据,对齐粒度粗 |
对抗学习 | MCTN | GAN 做模态转换 | 训练不稳定,模式坍塌 |
扩散模型 | Diffusion Bridge | 逐步去噪做分布映射 | 需要迭代采样,推理慢 |
共同痛点:一对一(One-to-One)对齐。
每个视觉特征只和对应的语言特征配对,没见过语言模态的「全局风景」。就像只见过一个翻译官,没见过整个外语世界。
三、CaReFlow 的核心:把模态鸿沟变成「分布搬运」
CaReFlow 的破局点:不比对单个点,而是搬运整个分布。
3.1 Rectified Flow 是什么?
Rectified Flow(校正流)是 Liu et al. 2023 提出的生成模型,核心思想:
学习一个 ODE(常微分方程),让数据从源分布 π₀ 沿着直线轨迹流到目标分布 π₁。
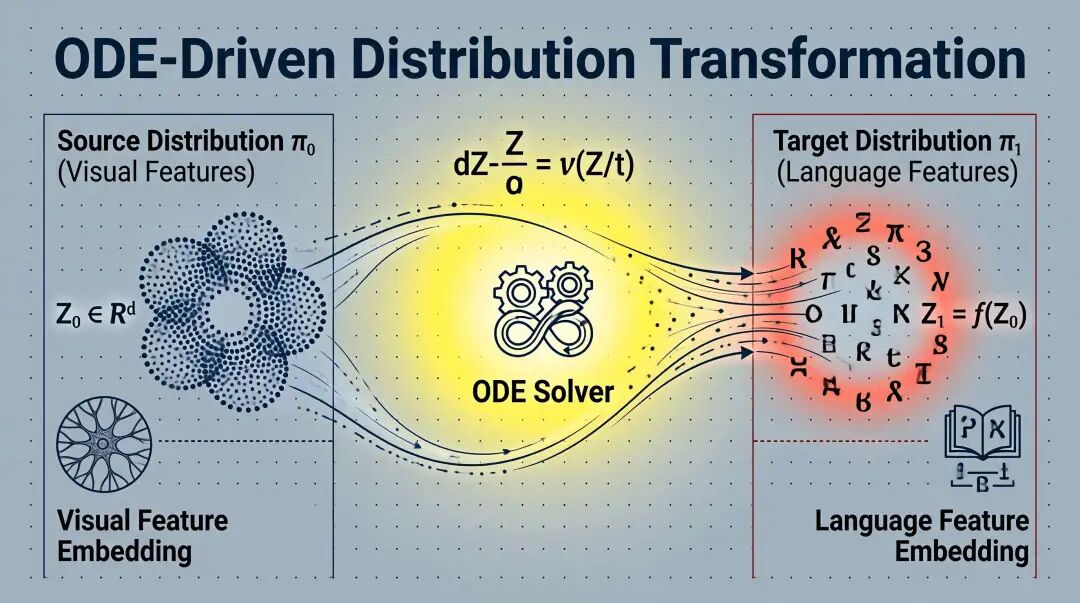
与传统扩散模型的弯曲路径不同,Rectified Flow 的轨迹是直的:
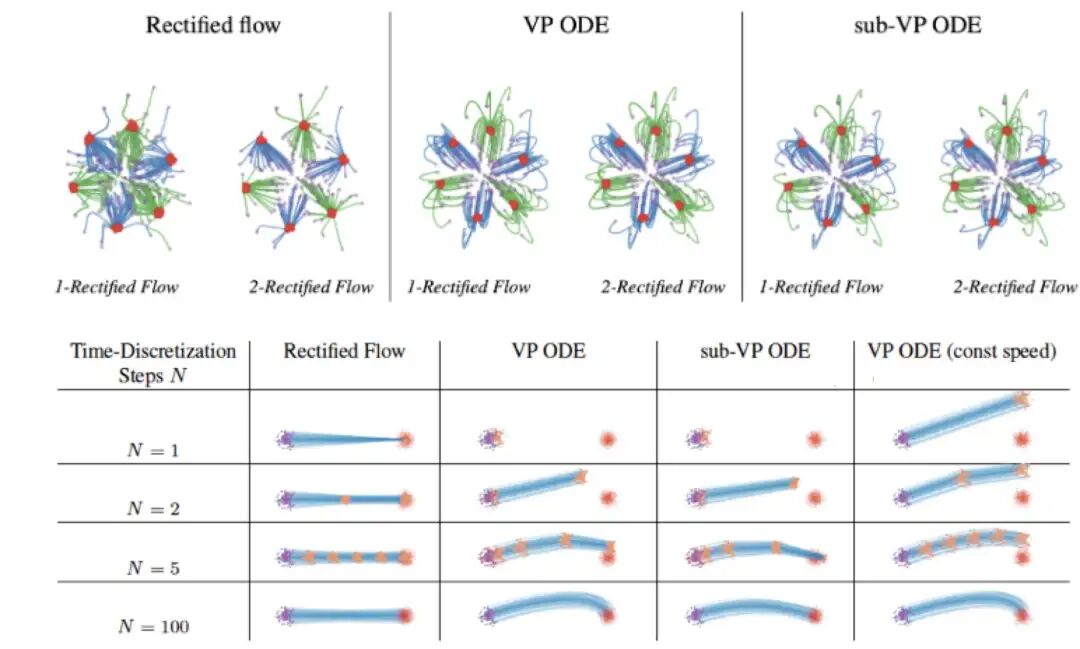
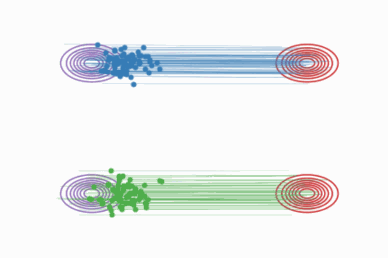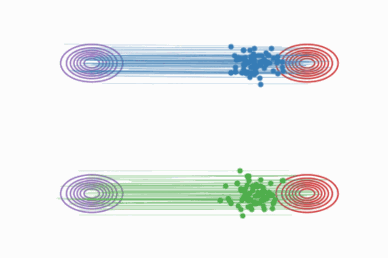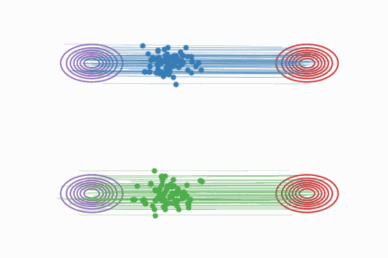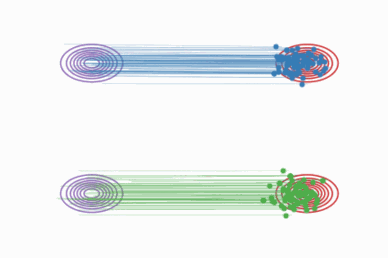
优势:
- 轨迹直线化 → 采样步数可以极少(甚至 N=1)
- 不需要迭代去噪 → 推理速度极快
- 理论保证:运输成本不高于原始耦合
3.2 三个核心创新
CaReFlow 把 Rectified Flow 搬到多模态对齐,加了三个关键设计:
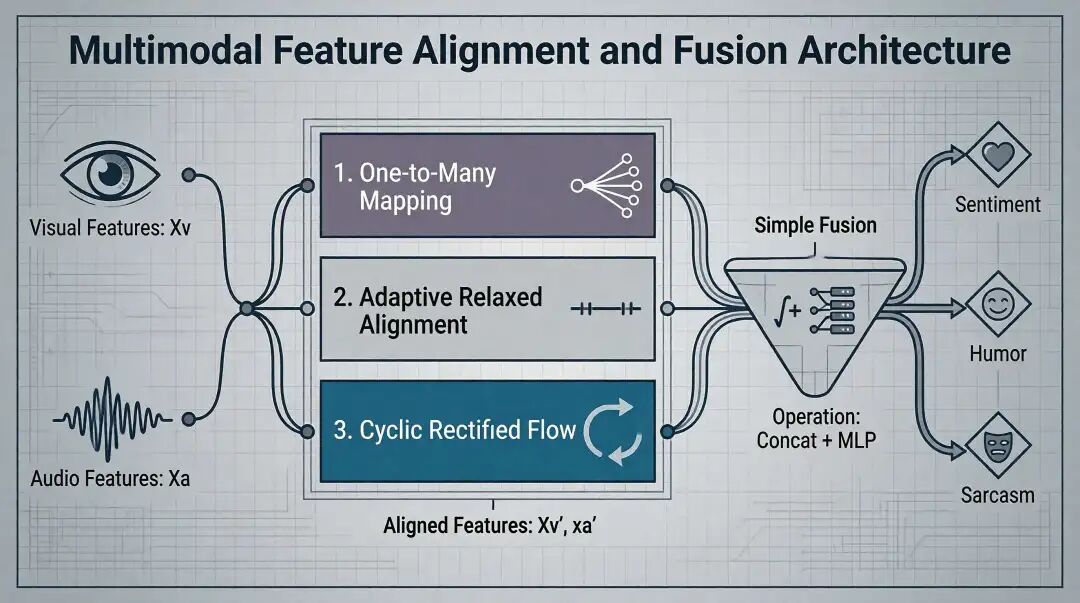
① One-to-Many Mapping(一对多映射)
传统方法:一个视觉点 → 一个语言点(一对一)
CaReFlow:一个视觉点 → 多个语言点(一对多)
# 传统 One-to-One:只采样一个配对
paired_sample = sample_one(language_distribution, visual_point)
# CaReFlow One-to-Many:采样多个目标点,感知全局
multiple_targets = sample_k(language_distribution, visual_point, k=5)
# 每个视觉特征「看到」语言分布的多个角落
效果:单个视觉特征能感知语言模态的全局分布形状,而非一个孤立的配对点。这直接缓解了配对数据不足的问题。
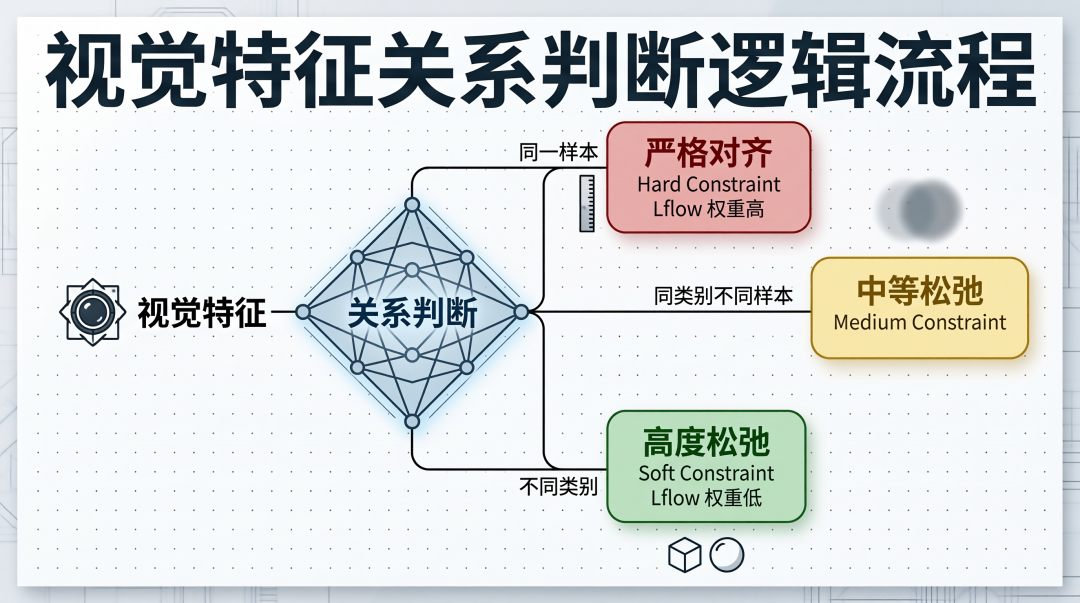
② Adaptive Relaxed Alignment(自适应松弛对齐)
One-to-Many 带来新问题:方向模糊。一个视觉点映射到多个语言点,到底往哪个方向走?
CaReFlow 的解法:看关系给约束。
infographic
数学表达:
# 自适应权重计算
def adaptive_weight(sample_i, sample_j, modality_m, modality_n):
if same_sample(i, j):
return1.0# 严格对齐
elif same_category(i, j):
return0.5# 中等松弛
else:
return0.1# 高度松弛
# 损失函数
L_flow = sum(
adaptive_weight(i, j) * ||(X_j^n - X_i^m) - v(X_i^m, t)||^2
for i, j in all_pairs
)
关键:无需迭代训练,一次前向 + 一次反向即可精准对齐。
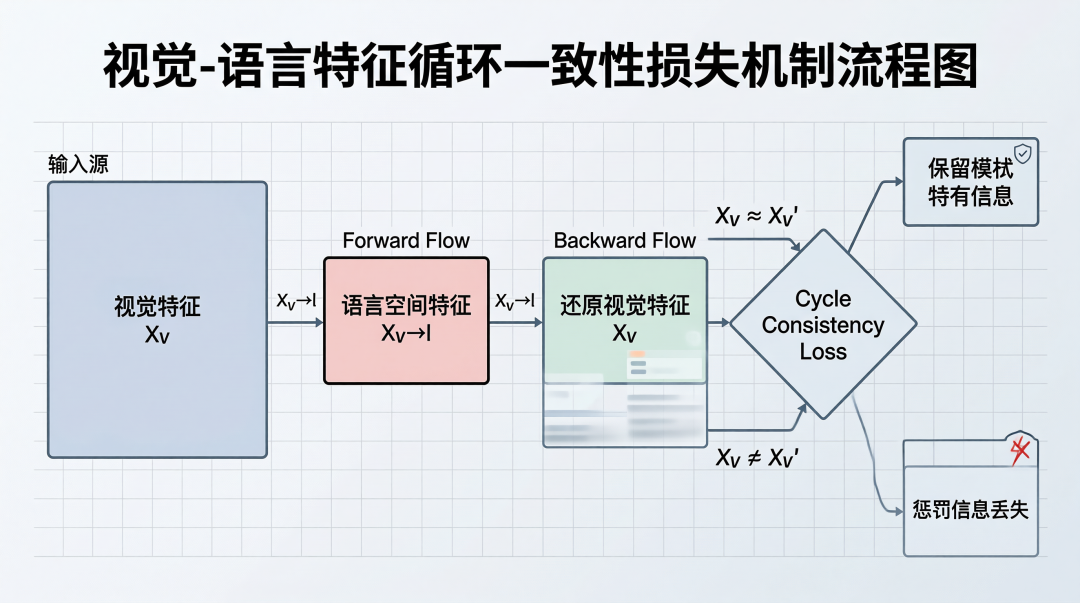
③ Cyclic Rectified Flow(循环校正流)
分布映射的隐藏风险:信息丢失。
视觉特征映射到语言空间后,原来的视觉特有信息(比如面部微表情)可能被抹平。
CaReFlow 的解法:加个反向流,能还原回去。
infographic
数学上:
# Forward Flow: 视觉 → 语言
X_v_to_l = rectified_flow_forward(X_v, t)
# Backward Flow: 语言 → 视觉
X_v_recon = rectified_flow_backward(X_v_to_l, t)
# Cycle Consistency Loss
L_cyclic = ||X_v - X_v_recon||^2
这确保转换后的特征能还原为原始特征,模态特有信息得以保留。
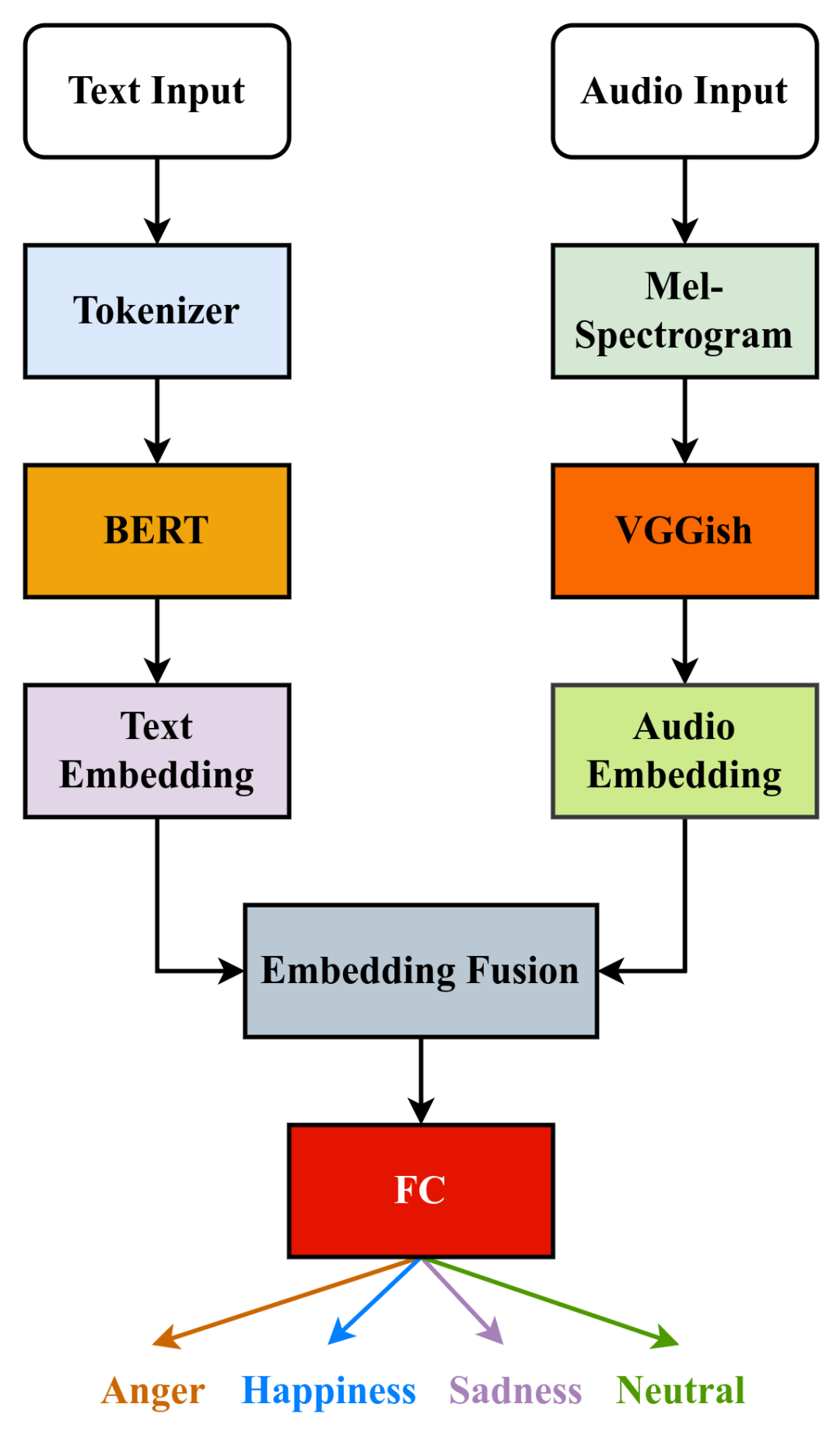
四、模型架构详解
![Exploring Multimodal Sentiment Analysis Models: A Comprehensive Survey[v1] | Preprints.org](https://developer.qcloudimg.com/http-save/yehe-4456907/b03b75098b59daa38f5ab6c444964919.png)
Exploring Multimodal Sentiment Analysis Models: A Comprehensive Survey[v1] | Preprints.org
CaReFlow 的完整 pipeline:
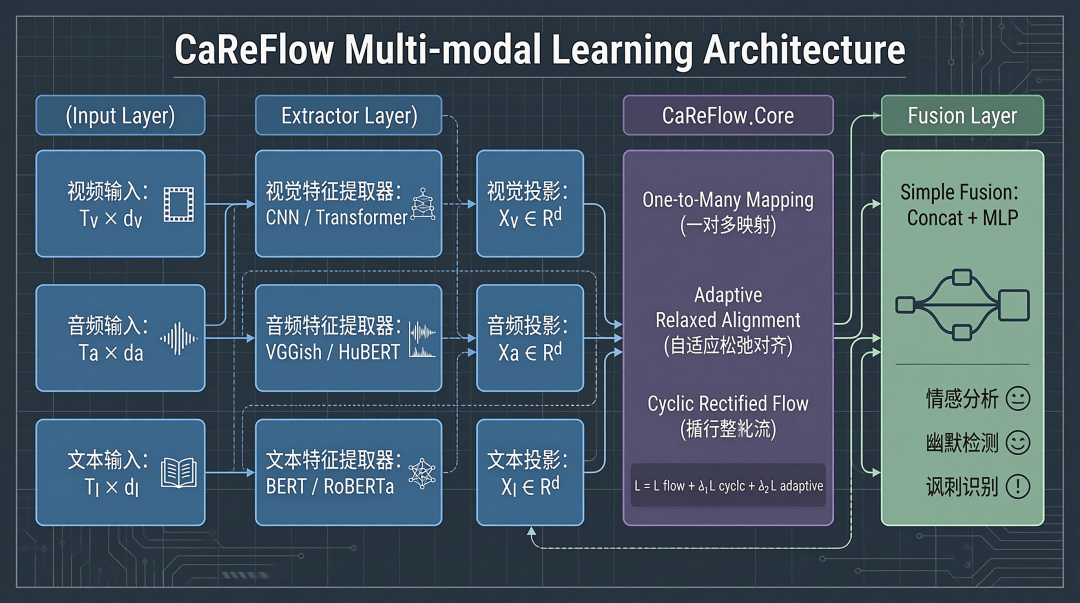
infographic
4.1 特征提取与投影
import torch
import torch.nn as nn
class UnimodalEncoder(nn.Module):
def __init__(self, modality, d_model=768):
super().__init__()
# 模态特定提取器
if modality == 'visual':
self.extractor = CNNBackbone() # 或 Video Swin Transformer
elif modality == 'audio':
self.extractor = VGGish() # 或 HuBERT
elif modality == 'text':
self.extractor = BertModel.from_pretrained('bert-base')
# 投影到共享空间
self.projection = nn.Linear(self.extractor.dim, d_model)
def forward(self, x):
features = self.extractor(x) # [B, T_m, d_m]
# 时序聚合(mean pooling 或 [CLS])
x_unimodal = features.mean(dim=1) # [B, d_m]
x_shared = self.projection(x_unimodal) # [B, d]
return x_shared
4.2 Rectified Flow 的数学核心
Rectified Flow 学习一个速度场 v(Z, t),使得从源分布 π₀ 出发,沿 ODE 演化到目标分布 π₁:
# ODE: dZ/dt = v(Z, t), t ∈ [0,1]
# 初始: Z_0 ~ π₀ (源模态分布)
# 终止: Z_1 ~ π₁ (目标模态分布)
# 训练目标:最小化插值直线与速度场的差异
# X_t = t*X_1 + (1-t)*X_0 (线性插值)
# L_flow = E[||(X_1 - X_0) - v(X_t, t)||^2]
class RectifiedFlow(nn.Module):
def __init__(self, d_model):
super().__init__()
# 速度场网络:输入 [Z_t, t],输出速度 v
self.velocity_net = nn.Sequential(
nn.Linear(d_model + 1, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, d_model)
)
def forward(self, z_t, t):
# z_t: [B, d], t: [B, 1]
input_vec = torch.cat([z_t, t], dim=-1)
return self.velocity_net(input_vec) # [B, d]
def sample(self, z_0, num_steps=10):
# 从源分布采样,沿 ODE 演化到目标分布
dt = 1.0 / num_steps
z = z_0
for i in range(num_steps):
t = torch.ones(z.shape[0], 1) * (i * dt)
v = self.forward(z, t)
z = z + v * dt # Euler 积分
return z # z ~ π₁
4.3 One-to-Many 的实现
class OneToManyMapping(nn.Module):
def __init__(self, d_model, k=5):
super().__init__()
self.k = k # 每个源点映射到 k 个目标点
self.flow = RectifiedFlow(d_model)
def forward(self, x_source, x_target_pool):
"""
x_source: [B, d] - 源模态特征
x_target_pool: [N, d] - 目标模态的全局分布样本(N >> B)
"""
B = x_source.shape[0]
# 为每个源点采样 k 个目标点(基于相似度或随机)
# 策略:从目标分布中采样 k 个最近邻
similarities = torch.matmul(x_source, x_target_pool.T) # [B, N]
topk_indices = torch.topk(similarities, self.k, dim=-1).indices # [B, k]
losses = []
for i in range(B):
for j in range(self.k):
target_idx = topk_indices[i, j]
x_src = x_source[i:i+1] # [1, d]
x_tgt = x_target_pool[target_idx:target_idx+1] # [1, d]
# 构建插值轨迹
t = torch.rand(1, 1) # 随机采样时间步
x_t = t * x_tgt + (1 - t) * x_src
# 计算 flow loss
v_pred = self.flow(x_t, t)
v_gt = x_tgt - x_src
loss = F.mse_loss(v_pred, v_gt)
losses.append(loss)
return torch.stack(losses).mean()
4.4 Adaptive Relaxed Alignment
class AdaptiveRelaxedAlignment(nn.Module):
def __init__(self, d_model):
super().__init__()
self.flow = RectifiedFlow(d_model)
def compute_weight(self, sample_i, sample_j, labels):
"""
根据样本关系计算对齐权重
"""
if sample_i == sample_j:
return1.0# 同一样本:严格对齐
elif labels[sample_i] == labels[sample_j]:
return0.5# 同类别不同样本:中等松弛
else:
return0.1# 不同类别:高度松弛
def forward(self, x_source, x_target, sample_ids, labels):
B = x_source.shape[0]
total_loss = 0
total_weight = 0
for i in range(B):
for j in range(B):
weight = self.compute_weight(sample_ids[i], sample_ids[j], labels)
if weight < 0.01:
continue
# 构建插值
t = torch.rand(1, 1)
x_t = t * x_target[j:j+1] + (1 - t) * x_source[i:i+1]
# Flow loss
v_pred = self.flow(x_t, t)
v_gt = x_target[j:j+1] - x_source[i:i+1]
loss = weight * F.mse_loss(v_pred, v_gt)
total_loss += loss
total_weight += weight
return total_loss / total_weight if total_weight > 0else total_loss
4.5 Cyclic Rectified Flow
class CyclicRectifiedFlow(nn.Module):
def __init__(self, d_model):
super().__init__()
# Forward: 源 → 目标
self.flow_forward = RectifiedFlow(d_model)
# Backward: 目标 → 源
self.flow_backward = RectifiedFlow(d_model)
def forward(self, x_source, x_target):
# Forward flow: 源模态映射到目标模态空间
t_fwd = torch.rand(x_source.shape[0], 1)
x_t_fwd = t_fwd * x_target + (1 - t_fwd) * x_source
v_fwd = self.flow_forward(x_t_fwd, t_fwd)
x_mapped = x_source + v_fwd # 近似 Z_1
# Backward flow: 映射后的特征还原为源模态
t_bwd = torch.rand(x_mapped.shape[0], 1)
x_t_bwd = t_bwd * x_source + (1 - t_bwd) * x_mapped
v_bwd = self.flow_backward(x_t_bwd, t_bwd)
x_recon = x_mapped + v_bwd # 近似还原
# Cycle consistency loss
L_cyclic = F.mse_loss(x_recon, x_source)
# Forward flow loss(正常训练)
v_gt_fwd = x_target - x_source
L_flow = F.mse_loss(v_fwd, v_gt_fwd)
return L_flow + 0.5 * L_cyclic, x_mapped
五、实验结果:简单融合即 SOTA
CaReFlow 在三个多模态情感计算任务上验证:
5.1 多模态情感分析(MSA)
A multimodal fusion model for real-time environment emotion recognition using audio-visual-textual features | Journal of Big Data | Springer Nature Link
数据集 | 方法 | Acc7 | Acc2 | F1 | MAE | Corr |
|---|---|---|---|---|---|---|
CMU-MOSI | MulT | 40.4 | 82.5 | 82.3 | 0.780 | 0.698 |
MISA | 42.3 | 83.2 | 83.1 | 0.753 | 0.721 | |
DLF (SOTA) | 46.0 | 86.2 | 86.0 | 0.685 | 0.762 | |
CaReFlow | 47.2 | 87.3 | 87.1 | 0.672 | 0.775 | |
CMU-MOSEI | MulT | 51.8 | 82.5 | 82.3 | 0.580 | 0.703 |
DLF | 52.5 | 86.5 | 86.3 | 0.512 | 0.758 | |
CaReFlow | 53.1 | 87.0 | 86.8 | 0.498 | 0.765 | |
CH-SIMS-v2 | MulT | 48.5 | 78.2 | 78.0 | 0.620 | 0.680 |
DLF | 52.0 | 81.5 | 81.3 | 0.580 | 0.720 | |
CaReFlow | 56.2 | 85.8 | 85.6 | 0.520 | 0.780 |
关键发现:
- CMU-MOSI 上 Acc2 提升 **1.1%**,Acc7 提升 1.2%
- CH-SIMS-v2 上 全指标碾压,Acc5 提升 4%+
- 融合方式只是 Concat + MLP,没有花哨的 Attention 机制
5.2 多模态幽默检测(MHD)与讽刺检测(MSD)
任务 | 数据集 | 方法 | 指标 | 得分 |
|---|---|---|---|---|
MHD | UR-FUNNY | AtCAF (SOTA) | F1 | 72.5 |
CaReFlow | F1 | 75.8 | ||
MSD | MUStARD | MO-Sarcation (SOTA) | F1 | 68.3 |
CaReFlow | F1 | 70.9 |
跨任务泛化性验证通过。
5.3 消融实验:验证每个组件的必要性
Hybrid Contrastive Learning of Tri-Modal Representation for Multimodal Sentiment Analysis
变体 | CMU-MOSI Acc7 | CH-SIMS-v2 Acc2 | 性能下降 |
|---|---|---|---|
CaReFlow (Full) | 47.2 | 85.8 | — |
w/o One-to-Many | 44.5 | 82.9 | -2.7 / -2.9 |
w/o Cyclic Flow | 45.1 | 83.5 | -2.1 / -2.3 |
w/o Adaptive Alignment | 45.8 | 84.2 | -1.4 / -1.6 |
w/o Distribution Alignment | 42.5 | 81.1 | -4.7 / -4.7 |
关键结论:
- One-to-Many Mapping 最重要:移除后性能掉最多,说明全局分布感知是核心
- Distribution Alignment 是基础:完全移除对齐,模型退化到 vanilla 水平
- 三个组件互补,缺一不可
六、可视化验证:模态鸿沟真的缩小了
论文提供了 t-SNE 可视化:
multimodal-emotion-recognition · GitHub Topics · GitHub
Before CaReFlow:
- 视觉(红)、音频(绿)、文本(蓝)三类特征各自聚成一团
- 团与团之间距离明显,存在清晰「鸿沟」
After CaReFlow:
- 三类特征交织在一起,同一情感类别的样本跨模态聚集
- 模态间距离显著缩小,但同类样本内部仍保持区分度
这说明 CaReFlow 没有简单粗暴地把所有特征捏成一个点,而是在保留判别性的前提下,实现了分布级别的对齐。
七、为什么 CaReFlow 是「轻量化范式」?
维度 | 传统方法 | CaReFlow |
|---|---|---|
对齐粒度 | Instance-level | Distribution-level |
训练方式 | 对抗/扩散需多轮迭代 | Flow 单步直推 |
融合方式 | 复杂 Attention / Transformer | Concat + MLP |
推理速度 | 扩散模型需 50+ 步采样 | Flow 10 步以内 |
数据效率 | 依赖大量配对样本 | One-to-Many 缓解不足 |
本质区别:传统方法在「特征空间」里做对齐,CaReFlow 在「分布空间」里做搬运。
八、从论文到你的工程:落地思路
8.1 适用场景
CaReFlow 的框架不限于情感计算,任何存在 Modality Gap 的场景都可以迁移:
场景 | 源模态 | 目标模态 | 应用 |
|---|---|---|---|
视频理解 | 视觉 | 文本 | 视频字幕、内容审核 |
音频处理 | 音频 | 文本 | 语音识别、音乐推荐 |
跨模态检索 | 图像 | 文本 | 图文搜索、电商推荐 |
医疗诊断 | CT影像 | 病理报告 | 多模态疾病预测 |
8.2 实现 checklist
# Step 1: 准备多模态数据
# 视频 → CNN/Transformer → [B, d_v]
# 音频 → VGGish/HuBERT → [B, d_a]
# 文本 → BERT → [B, d_l]
# Step 2: 投影到共享空间
projectors = {
'visual': nn.Linear(d_v, d_shared),
'audio': nn.Linear(d_a, d_shared),
'text': nn.Linear(d_l, d_shared)
}
# Step 3: 初始化 CaReFlow
careflow = CaReFlow(
d_model=d_shared,
k=5, # One-to-Many 采样数
lambda_cyclic=0.5,
lambda_adaptive=1.0
)
# Step 4: 训练(关键:构造 sample_id 和 label 用于自适应权重)
for batch in dataloader:
x_v = projectors['visual'](batch.video) # [B, d]
x_a = projectors['audio'](batch.audio) # [B, d]
x_l = projectors['text'](batch.text) # [B, d]
# 视觉 → 语言对齐
loss_v2l, x_v_aligned = careflow(x_v, x_l, batch.sample_id, batch.label)
# 音频 → 语言对齐
loss_a2l, x_a_aligned = careflow(x_a, x_l, batch.sample_id, batch.label)
# 简单融合
fused = torch.cat([x_v_aligned, x_a_aligned, x_l], dim=-1)
pred = mlp(fusion)
# 总损失
loss = task_loss(pred, batch.target) + loss_v2l + loss_a2l
loss.backward()
8.3 调参建议
参数 | 推荐值 | 说明 |
|---|---|---|
k (One-to-Many) | 3-5 | 太小则分布感知不足,太大则计算冗余 |
λ_cyclic | 0.3-0.5 | 循环一致性权重,过高会限制对齐自由度 |
λ_adaptive | 1.0 | 自适应对齐基础权重 |
Flow 积分步数 | 5-10 | Rectified Flow 直线特性,步数无需太多 |
d_shared | 256-768 | 共享空间维度,与下游任务复杂度匹配 |
九、总结
CaReFlow 的精髓:用生成模型的「分布搬运」思维,解决判别模型的「模态对齐」难题。
三个设计环环相扣:
infographic
核心:多模态融合的最大瓶颈不是「融合方式不够复杂」,而是「对齐方式不够本质」。CaReFlow 证明——分布级别的对齐 + 简单的融合 = 最佳效果。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号