疑难杂症(1):踩过 100 次存储 IO 坑后我发现:90%无法解决问题,都是 DMC 问题

疑难杂症(1):踩过 100 次存储 IO 坑后我发现:90%无法解决问题,都是 DMC 问题

早起的鸟儿有虫吃
发布于 2026-05-20 13:14:32
发布于 2026-05-20 13:14:32
序言
DMC对应的英文通常是:
- dm-cache data inconsistency
- 或者更具体地描述为 metadata inconsistency in dm-cache(块) / data corruption due to dm-cache
先定核心结论:DMC(Dirty脏缓存 / Metadata元数据缓存 / Cache Coherence缓存一致性) 不是 Ceph 分布式专属问题;
只要是 Linux + Ext4/XFS 本地文件系统,
依赖 Linux 标准 IO 缓存架构,天生自带 DMC 三大问题。
根源不在分布式, 而在于 Linux 为了性能,强行引入的页缓存(Page Cache)、延迟写、元数据缓存机制。
同样基于缓存架构, 数据库不仅会遇到 DMC 问题,而且比普通文件系统更严重。
因为数据库在操作系统 PageCache 之上, 又构建了自己的专属缓存层, 形成了双层缓存架构,让问题叠加放大。
- MySQL(InnoDB) 将所有数据页和索引页缓存在 Buffer Pool 中,写操作先改内存页(标记脏页),再由后台线程异步批量刷盘。这与 Linux PageCache 的延迟写如出一辙,继承了同样的隐患。
- TiKV 作为分布式键值存储,底层基于 RocksDB(LSM-Tree),上层通过 Raft 协议保证多副本一致。它的 DMC 问题,既有单机 RocksDB 的特性,又叠加了分布式环境的独特挑战。
MySQL(InnoDB)和 TiKV 作为两种典型的单机 / 分布式存储引擎,都面临 DMC 三大挑战,但由于底层架构(B + 树 vs LSM-Tree、单机 vs 分布式)不同,问题表现和解决方式有本质区别
- MySQL 解决的是 单机如何用好缓存 的问题,
- TiKV 解决的是 分布式系统如何保证缓存一致性 的问题
基于循序渐进的原则,本文先将目光聚焦于文件系统层的 DMC 问题。
实在是不能在截至日期完成同时一次解决三个问题,不 同时支持多个项目,这样反人性安排谁设计的?
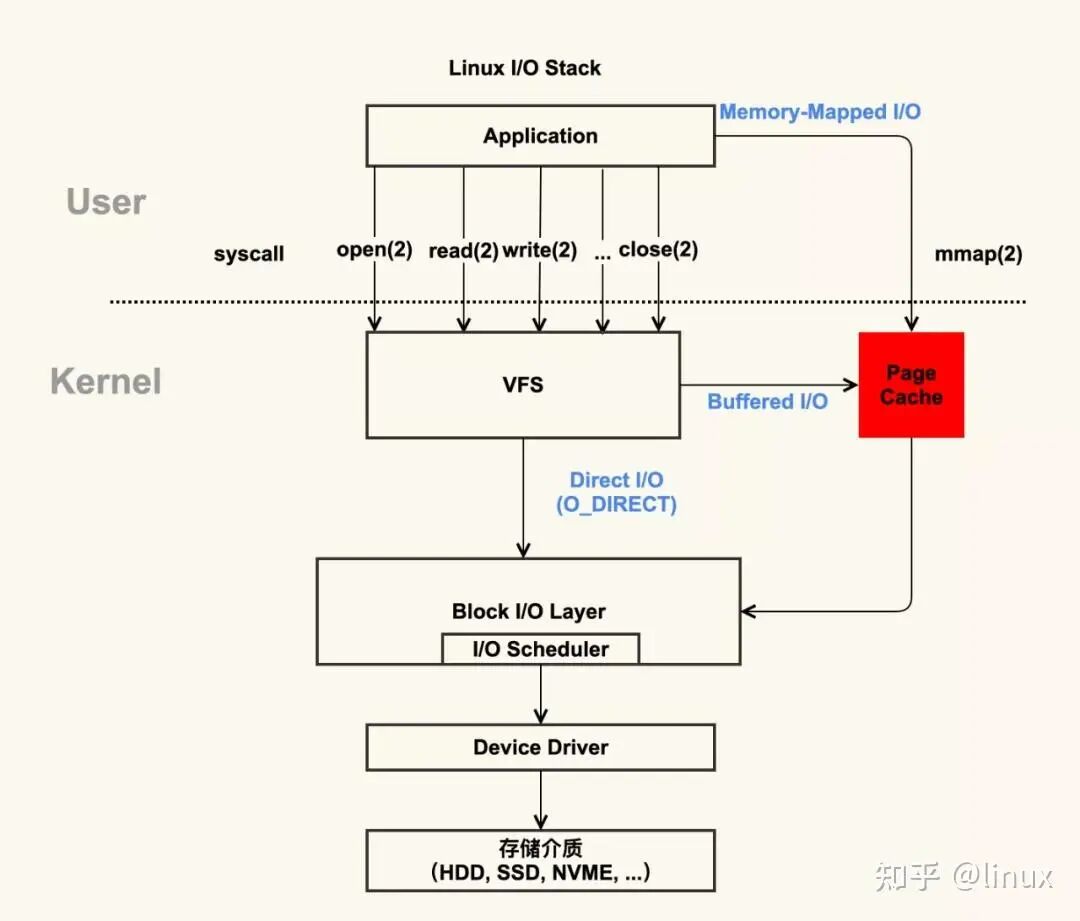
一、先铺垫:Linux 为什么要搞 IO 缓存(DMC 的总根源)
硬件天然速度鸿沟:
- 内存:纳秒级
- SSD:微秒级
- 机械硬盘:毫秒级,还有寻道延迟
Linux 为了不让慢速磁盘拖垮应用性能,设计一套强制 IO 优化架构:
所有文件读写不直接读写磁盘,全部先过 PageCache 页缓存
- 读:先读内存缓存,命中就不走磁盘
- 写:先写内存,不立刻落盘,内核后台慢慢刷到 Ext4 磁盘
这套「内存缓存 + 延迟落盘」的 IO 优化机制,直接催生了 D、M、C 全部问题。
二、问题:Dirty Cache 脏缓存 —— Ext4 + Linux 延迟写自带
1. 什么是脏页
应用写文件(非O_DIRECT) → 数据仅写入 Linux PageCache(脏页)→ 内核未同步到磁盘 → 系统异常崩溃 → 内存数据丢失[返回用户写入成功] → 磁盘数据为旧数据【实际没有写入成功】 → 数据不一致
Vdbench 开启 data_validation=yes 后, 会给每个数据块写入全局唯一签名,读取时自动校验, 精准识别 Dirty Cache 导致的不一致。
# 基础配置
sd=sd1,lun=/test/disk_1.img,size=10G,openflags=async
# openflags=async:走PageCache,禁用DirectIO
wd=wd1,sd=sd1,rdpct=0,rhpct=0,whpct=100
# 100% 随机写
rd=rd1,wd=wd1,iorate=max,elapsed=60,interval=1 # 运行60秒
# 【核心】开启数据一致性校验
data_validation=yes
validate=yes
核心错误类型:数据校验失败(Data Validation miscompare),包含 4 类不匹配:
- 校验密钥(Key)不匹配(期望 0x2d,实际 0x52);
- 逻辑字节地址(Logical byte address)不匹配(期望 0x40b34000,实际 0x177166000);
- 存储设备名称(SD/FSD name)不匹配(期望 sd7,实际 sd5);
- 压缩模式(Compression pattern)不匹配。
2. Linux 为什么故意制造脏缓存
- 合并大量小IO,减少磁盘随机写、减少寻道
- 延迟刷盘,提升应用写吞吐
- 后台平滑落盘,避免每次写都阻塞业务
3.常见故障类型
- 脏页堆积过多,内核集中批量刷盘 瞬间打满磁盘IO,业务延迟抖动 【抖动】
- 达到内核水位阈值
dirty_ratio,应用被阻塞等待刷盘 - 机器突然断电/崩溃,内存脏页没落地 → 数据丢失 【断电】
- Ext4 有日志(Journal),刷脏还要写日志,进一步放大IO压力 【IO压力大】
👉 结论:只要 Linux 用延迟写 + PageCache,Ext4 必然有 D 脏缓存问题。
三、M 问题: Ext4 元数据缓存 Metadata
1. Ext4 元数据包含什么
inode、目录项 dentry、文件大小、权限、时间戳、块位图、超级块。
2. Linux 为什么要缓存元数据
业务 70% 操作都是元数据操作:ls、stat、open、mkdir、rm、遍历目录
如果每次都从 Ext4 磁盘读 inode/目录:
- 磁盘随机读暴增
- 性能直接垮掉
所以 Linux 把 Ext4 元数据全部缓存到内存:Dentry Cache + Inode Cache
3. 带来的 M 类问题(Ext4 本地也会遇到)
- 元数据缓存占用大量系统内存
- 海量小文件新建/删除 → 元数据剧烈变更 → 元数据刷盘突发IO尖峰
- 内存元数据与磁盘元数据存在时间窗口不一致
- Ext4 日志要持久化元数据,进一步放大元数据IO开销】
某日志服务器每小时切割 10 万个 1KB 日志文件 → 切割瞬间,元数据刷盘导致 IO 利用率 100% → 日志写入延迟从 1ms 飙升到 500ms → 应用日志堆积、报警触发。
- 应用执行
rm test.txt后,ls看不到文件(内存缓存已更新),但此时断电 → 重启后文件又「复活」(磁盘元数据未刷盘); cp test.txt new.txt后,ls能看到 new.txt,但断电后 new.txt 变成空文件(文件内容刷盘了,但元数据没刷) 👉 结论:只要有文件系统、只要要性能,就必须缓存元数据,M 问题躲不开。
四、C 问题:Cache Coherence 缓存一致性 —— 多进程共享必然产生
1. 场景
同一台 Linux 上,多进程/多线程 同时读写同一个 Ext4 文件。
2. 为什么要有缓存一致性
每个进程都依赖内核同一个 PageCache:
- 进程A 修改了文件缓存
- 进程B 必须读到最新内容
- 不能各自持有旧缓存、互相看不见
PageCache 和普通malloc 分配内存有什么区别?
- PageCache 是内核为所有磁盘文件分配的全局共享内存
- PageCache:进程 A 读
test.txt加载到 PageCache,进程 B 再读test.txt直接复用,节省内存 + 提升速度; - malloc:进程 A
malloc(1GB),进程 B 也malloc(1GB),系统会分配 2GB 内存(互不共享)
内核管 PageCache,进程管 malloc
- PageCache:你无法直接
freePageCache,只能通过sync触发刷盘,或通过echo 3 > /proc/sys/vm/drop_caches让内核回收; - malloc:进程必须自己管理,比如 `char *p = malloc(1024); free(p);
3. Linux + Ext4 如何解决、带来什么代价
内核必须做:
- 页缓存加锁
- 页失效、回收、mmap 同步
- 读写争抢页锁
4. 带来的 C 类问题
- 多进程争抢页缓存锁,产生阻塞、吞吐下降
- mmap 共享文件场景,一致性逻辑更复杂
- 缓存失效、页回收带来额外 CPU + IO 开销
问题 2:mmap 共享文件场景
具体表现:
- mmap 映射文件后,进程 A 修改映射内存,进程 B 看不到最新内容(一致性同步延迟);
- 强制 msync 同步后,CPU 占用飙升(同步逻辑消耗大量 CPU);
mmap原理:
- 进程读写 mmap 映射的内存,本质就是读写全局共享的 PageCache 页;mmap 绕开了用户态→内核态的数据拷贝
- mmap 修改后,写磁盘的完整流程:``` 进程A修改虚拟内存 → 修改内核PageCache页(标记为「脏页」)→ 内核异步刷盘 → 写入磁盘文件块
- 内核延迟刷盘(和普通 PageCache 共用一套策略)
只有满足以下被动条件才会刷盘:
- 脏页占总内存比例达到
vm.dirty_background_ratio(默认 10%):后台异步刷盘,不阻塞进程; - 脏页占比达到
vm.dirty_ratio(默认 20%):强制刷盘,阻塞写进程; - 脏页超时(
vm.dirty_expire_centisecs,默认 3000=30 秒):超时未刷的脏页会被刷盘; - 内存不足:内核回收 PageCache 时,会先刷脏页到磁盘;
- 系统关机 / 进程退出(仅 MAP_SHARED 模式)。
dirty_background_ratio 是 Linux 内核中控制脏页异步刷盘触发阈值的核心参数,直接决定了 mmap / 普通写产生的脏页何时被 flusher 线程异步刷盘
方法1:sysctl 查看(推荐) sysctl vm.dirty_background_ratio 方法2:直接读 proc 文件 cat /proc/sys/vm/dirty_background_ratio 10%
👉 结论:只要多进程共享文件,单机 Ext4 就天然存在缓存一致性 C 问题。
五、关键:Ext4 有 DMC,为什么平时感知不明显?
- 所有缓存由本机 Linux 内核统一管理,不用跨机器协商
- 元数据就在本地磁盘,没有独立 MDS 节点瓶颈
- 脏页刷的是本地盘,无网络延迟、无网络IO开销
- 缓存一致性是本机内存间同步,不用 RPC、不用跨网络作废缓存
不是没有 DMC,是单机代价小、不放大。
一句话终极总结(从普通文件系统角度)
- DMC 不是分布式存储发明的,是 Linux 内核 IO 缓存架构 + Ext4 文件系统机制 天生自带;
- 为了抹平内存与磁盘速度差,Linux 必须用 PageCache延迟写、元数据内存缓存,直接制造 D、M;
- 多进程共享文件的场景,必然要求 缓存一致性,天生带来 C;
- Ext4 只是单机 DMC 代价小;Ceph 只是把这套单机固有 DMC 问题,放大到网络和集群级别
参考
- https://zhuanlan.zhihu.com/p/436313908
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号