GitHub 上已有 1400+ Claude Code Skills,真正在用的就这几个

GitHub 上已有 1400+ Claude Code Skills,真正在用的就这几个

码哥字节
发布于 2026-05-20 13:19:25
发布于 2026-05-20 13:19:25
三个月前,我第一次看到 superpowers 的时候,立刻觉得这东西有点厉害——14 个 skill 装进去,Claude Code 直接变成一套完整的软件工程流水线,TDD、代码审查、brainstorming 全覆盖。
GitHub 上已经 187K star 了,Medium 上的测评文章写"生产力提升 100 倍",HN 置顶帖里工程师们在疯狂点赞。
我装上用了三个月,结论是:它确实有价值,但不是对所有人、所有场景。而且整个 Claude Code Skills 生态里,有太多东西是包装远比内容强的。
截至 2026 年 5 月,GitHub 上已有 1400+ 个 Claude Code Skills,官方 marketplace 里收录的也超过 658 个。
我自己用过 40+ 个,帮团队里几个人清理过他们的 skill 列表,得出的结论很清楚:真正能在日常工作里留下来的,不超过 10 个。
这篇是我的筛选过程和结论,不是 skill 广告。
先给你一个懒人版结论
如果你不想看完这 4000 字,这张表直接拿走:
场景 | 推荐 Skill | 核心价值 | 要注意的地方 |
|---|---|---|---|
中大型功能开发 | superpowers | 强制规划,减少走弯路 | 简单任务会多花 15 分钟 |
多天项目协作 | claude-mem | 跨会话记忆,不用反复交代背景 | 记忆噪声多了会搞乱 |
浏览器自动化 | agent-browser | Token 效率最高,日常够用 | 复杂 DOM 操作需搭 Playwright |
前端 UI 生成 | frontend-design | 避免千篇一律的 AI 风格 | 只是风格约束,不能替代设计稿 |
构建自定义 Skill | skill-creator | 官方工具,评测指标可量化 | 需要花时间写评测用例 |
其余 1390+ 个 skill?大部分你装上后一周内就会忘了它的存在。下面说为什么。
为什么大多数 Skill 是噱头
Claude Code Skills 的技术原理并不复杂:一个 SKILL.md 文件,YAML frontmatter 里写 name 和 description,正文是 Markdown 格式的指令,放到 ~/.claude/skills/ 目录下就能用。
每次 Claude 处理请求时,会用约 100 tokens 扫描所有已安装 skill 的 name 和 description,判断是否激活。激活后才加载完整 skill 内容(通常 < 5k tokens)。所以理论上,装 50 个 skill 的额外 token 开销只有 5000 左右,代价不高。
但这也意味着任何人都可以在下午写出一个 skill,发到 GitHub 上,起个响亮的名字,获得一堆 star。
有人专门测试过 100 个社区 skill,结果是 70% 不合格。失败原因高度集中:
- SKILL.md 太臃肿(4000+ tokens),每次无关任务都在白白消耗上下文
- description 写的是营销文案,不是路由规则,导致 Claude 不知道何时该激活
- Single-file 包揽一切,把五件事塞进一个 skill,结果哪件都做不精
- 没有 reference 文件分层,关键逻辑直接堆在 SKILL.md 里,激活一次就吃掉大量上下文
好的 skill 是精准的:description 读起来像路由规则,不是宣传语;核心 SKILL.md 精简,细节推到 references/ 目录里,按需加载;一个 skill 只做一件事。

Claude Code Skills 价值分层:哪些值得装,哪些是噱头
图:Claude Code Skills 五层价值分层——从必装到直接跳过
判断一个 skill 值不值得装,先看 SKILL.md 文件的前 50 行。如果前 50 行读完你还不清楚它干什么,扔掉。
superpowers:真实体验是什么
superpowers 是整个生态里最成功的 skill 集合,没有之一。从 2025 年 10 月发布,到现在 187K GitHub star,v5.1.0(2026 年 5 月 4 日更新),实打实的快速成长。
它把 Claude Code 的工作方式重组成一条流水线:
brainstorming → 确认方向 → writing-plans → 生成实施计划
→ executing-plans → 实现 → requesting-code-review → 质量审查
→ verification-before-completion → 收尾验证
14 个 skill,覆盖完整软件开发生命周期。
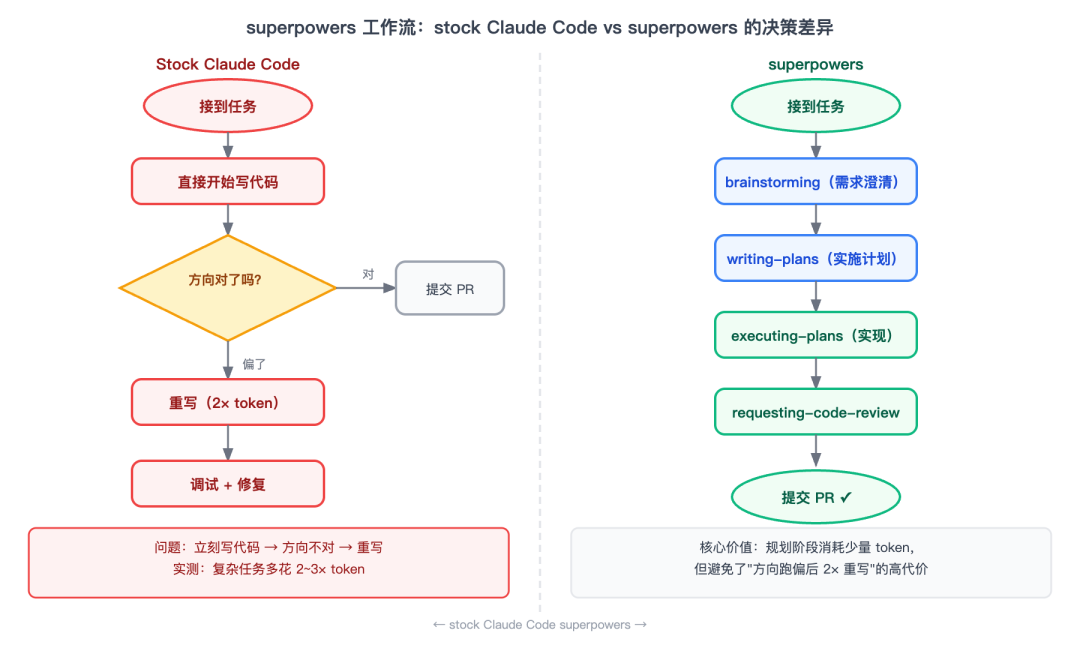
superpowers 工作流:stock Claude Code vs superpowers 的决策差异
图:左侧是 stock Claude Code 的常见失败路径,右侧是 superpowers 的结构化流程
它真正改变了什么?
用 stock Claude Code 做一个新功能,典型的失败模式是:Claude 对着模糊需求直接开始写,写完之后你发现方向不对,然后花 2 倍时间重写。superpowers 的 brainstorming skill 强制你在动代码之前把需求想清楚——不是催你写文档,是用一系列问题把"你其实想要什么"问出来。
有人做过对照实验:12 个 Claude Code 会话,一半用 superpowers,一半不用,同等复杂度任务。结果是 superpowers 组 token 用量降低 14%,代码质量(以 PR review 问题数量计)提升明显。原因很直觉:规划阶段的 token 消耗,远比因为方向跑偏而重写的 token 省。
对于复杂的、多文件的、需要跨模块协作的功能,superpowers 的收益是真实的。
但它也有明显的局限:
第一,简单任务会被拖慢。"帮我写个正则表达式"、"帮我加一个 console.log"——这类任务被 brainstorming 拦截之后,会花掉 10-20 分钟的前置流程,完全不值。有 HN 的工程师反馈说用了 superpowers 之后"Claude 做一件简单事情变得超级啰嗦",这是真实存在的问题。
第二,计划修改体验很差。superpowers 生成了多页实施计划之后,如果你想改一小部分,它会整个重新生成。一个开发者的原话是:"你给它反馈,它会返回一个全新版本的多页计划,而不是只修改你提到的那部分。"
第三,TDD 规则有时候对模型来说太过强制。superpowers 要求先写测试再写实现,如果没有失败的测试,它会删除已写的代码。这个机制本身是对的,但在探索性阶段,"先跑起来再说"的需求是真实存在的。
我自己的用法:
我最终的策略是有选择地激活。做新功能、重构、有明确边界的模块,用 superpowers 完整流程。修 bug、加小功能、写一次性脚本,直接用 stock Claude Code,不经过这套流水线。
using-superpowers skill 提供了这种灵活性——你可以只装部分 skill,比如只装 brainstorming + systematic-debugging,不装全套。
claude-mem:被低估的那个
superpowers 是生态里讨论最多的,但 claude-mem 是我觉得被讨论得最不够的。
它解决一个很具体的问题:Claude Code 每个会话是独立的,你在昨天的会话里和 Claude 讨论了某个模块的设计决策、踩了一个坑、确认了一个命名规范——今天新开一个会话,这些全没了。你要么重新交代背景,要么接受 Claude 在不了解上下文的情况下工作。
claude-mem 的方案是:在会话结束时,把有价值的内容压缩成"记忆片段",存到本地(SQLite + Chroma 向量数据库)。下次会话开始时,自动检索相关记忆,注入到 system prompt 里。
目前 72.4K GitHub star,v12.6.4(发布于 2026 年 5 月),259 个 release,109 个贡献者。2026 年 2 月曾经单日涨 1474 star,是 GitHub Trending 第一。
它在哪里最有价值:
- 多天迭代的项目:第二天不用重新交代"我们用的是 PostgreSQL 而不是 MySQL,因为……"
- 踩坑记录:之前踩过的坑、找过的解决方案,自动在遇到类似问题时浮现
- 团队规范:一次告诉 Claude"我们的函数命名用动词+名词",之后不用反复说
它的真实局限:
claude-mem 的最大风险是记忆噪声。它会记住一切,包括你在某次会话里说的错误假设、临时决策、后来被推翻的方案。如果不定期清理,检索到的"相关记忆"可能反而会误导 Claude。
坦白说,我踩过这个坑。某次我在会话里临时测试了一个方案,说"先这样试试",claude-mem 把这条记住了,之后几次会话里 Claude 都参照这个"临时方案"工作,搞了我很久才发现问题在哪里。
另外,它不能替代代码注释和文档。那些稳定的架构决策,应该写进 CLAUDE.md,写进代码注释,不应该只活在 claude-mem 的记忆库里——因为记忆库会过期、会被覆盖、会产生歧义,代码里的注释不会。
正确的用法:
把 claude-mem 当作"对话记录的增强索引",不是"架构知识库的替代品"。真正重要的决策,同时也要写进 CLAUDE.md;不确定的、临时的内容,会话结束时主动告诉 Claude 不要记住这条。
agent-browser:做浏览器自动化就用这个
这是一个逻辑更直接的评测:你需要让 Claude Code 操作浏览器,有几个选项,应该选哪个?
2026 年的主流选项:
工具 | Token 消耗/页 | 适用场景 | 安装复杂度 |
|---|---|---|---|
agent-browser | 200-400 tokens | 日常浏览、表单、导航 | 低 |
Playwright MCP | 2000-6000 tokens | 复杂 DOM 交互 | 中 |
Playwright CLI | 约 Playwright MCP 的 1/4 | coding agent 优化版 | 中 |
Chrome DevTools MCP | 中等 | 截图、调试 | 低 |
agent-browser 的优势只有一个,但这一个很关键:token 效率最高。它用精简的 YAML 摘要表示页面状态,而不是把完整的 DOM 树 dump 到上下文里,每页只需要 200-400 tokens。对于"导航到某个页面,找到某个元素,提取数据"这类日常任务,它够用,且便宜。
安装量 253K+(在 skills 生态里排前五),用户群体的反馈也很一致:日常任务首选,复杂 DOM 操作降级到 Playwright。
如果你的浏览器自动化任务涉及复杂的 JavaScript 交互、动态渲染内容、多步骤表单,Playwright CLI 是更合适的选择——微软 2026 年初专门为 coding agent 场景重新设计了这个工具,token 消耗是 Playwright MCP 的 1/4,且把快照存到磁盘而不是塞进上下文。

Claude Code 浏览器自动化工具横向对比(2026)
图:四款浏览器自动化工具对比——agent-browser 在 token 效率上有压倒性优势
frontend-design:解决一个真实问题
让 Claude 生成 UI 代码,结果总是差不多的样子:蓝白配色,Tailwind 默认类,圆角 Card 组件,Hero Section,样式上毫无特色。
这个现象有个专业名词叫"distributional convergence"——模型倾向于生成训练数据里最常见的输出,而"最常见的前端 UI"就是千篇一律的 SaaS 风格。
frontend-design 这个 skill 的做法很直接:它携带了 50 种具体的视觉风格方向(工业风、新表现主义、Glitch 美学……),每次生成 UI 时强制模型向其中某个方向偏移,而不是往"平均"方向走。
它解决的问题是真实的,564K+ 的安装量也说明这个需求很广泛。
需要说清楚的是: 它能给你一个"风格上有特色的 UI",但不能给你一个"符合你们产品设计系统的 UI"。如果你的产品有成熟的设计语言,还是要靠 brand-guidelines skill + 设计 token,前者是补 Claude 的能力短板,后者是对齐你的设计系统,这两个问题不一样。
你不需要装那些"技术栈专项" Skill
这是我观察到的一个规律,想单独说一下。
Skills 市场里有大量针对特定技术栈的 skill,比如"React 19 最佳实践"、"Vue 3 + TypeScript"、"Go 微服务规范"等等。这类 skill 的逻辑是:把某个技术栈的规范固化成 skill,Claude 自动遵守。
问题是:Claude Sonnet 4 及以上的版本,已经具备了主流技术栈最佳实践的内置知识。你加一个 900 token 的"React hooks 规范"skill,大概率是在告诉 Claude 它已经知道的事情。
真正有价值的是:针对你们团队的具体规范——你们的命名约定、你们的 PR 流程、你们特有的代码结构、你们踩过的特有的坑。这些东西模型不知道,写进 CLAUDE.md 或者自定义 skill 才有价值。
skill-creator 这个官方工具在这里是有意义的:它帮你构建自己的 skill,并且能做 A/B 测试,测量你的 skill description 激活率(经过优化后,激活率可以从 20% 提升到 90%)。
避坑清单:装之前先看这 4 件事
装任何一个 skill 之前,检查这四点:
1. description 是路由规则还是营销文案?
好的 description:"Use when user needs to interact with websites: navigate pages, fill forms, click buttons, take screenshots"
差的 description:"A powerful skill that supercharges your Claude Code workflow with AI-powered productivity"
前者 Claude 知道什么时候激活,后者会在不该激活的时候乱激活。
2. SKILL.md 有没有 reference 文件分层?
打开 skill 目录,看有没有 references/ 子目录。有分层的 skill 说明作者考虑过 token 效率——核心逻辑在 SKILL.md,细节按需加载。全都堆在 SKILL.md 里的,装了是在浪费上下文。
3. GitHub 的更新频率
这是 2026 年一个特别重要的指标:模型在快速迭代,好的 skill 需要跟上模型能力的变化。一个半年没有更新的 skill,可能在用老版本模型的行为假设指导新模型,效果打折扣。
4. 先用 7 天再决定保留
装一个 skill,用一周。如果一周之内你没有主动用过它,说明你的工作场景不需要它,卸载。Skills 不是装饰,不用的占着 token 扫描空间,长期是负担。
常见问题
Q:superpowers 和 claude-mem 可以一起用吗?
可以,而且组合效果不错。superpowers 负责当次会话内的结构化工作流,claude-mem 负责跨会话的记忆沉淀。两者不冲突,只是 brainstorming 阶段 claude-mem 可能会注入旧的记忆,偶尔产生干扰,注意观察。
Q:用了这些 skills,Claude Code 的 API 费用会增加多少?
有测试数据:superpowers 用于复杂多文件任务时,token 用量减少 14%(因为减少了走偏后的返工);但简单任务上,因为流程开销,用量会增加。综合来看,对于一个混合工作负载的开发者,整体 token 用量大致持平,差异不大。
agent-browser 相比 Playwright MCP,每次浏览器交互可以省 2000-5600 tokens,累积起来节省相当可观。
Q:社区 skill 和官方 skill 有什么区别,该优先选哪个?
官方 skill(Anthropic 出品)的优势是有质量保证和持续维护,但覆盖场景有限。社区 skill 的优势是覆盖长尾场景,但质量参差不齐。我的建议是:官方 skill 无脑装,社区 skill 按照上面的 4 条检查标准筛选。
Q:如果只能选一个 skill,选哪个?
对大多数后端/全栈工程师来说:superpowers 的 brainstorming skill 单独装(不装全套),或者 claude-mem。前者改变工作方式,后者积累复利。选哪个取决于你更缺哪个——是"做任务时少走弯路"还是"下次不用重复交代背景"。
总结
说到底,1400+ 个 skills 里绝大多数是为了蹭生态热度写出来的,这没什么可奇怪的——任何新生态都会经历这个阶段。真正有价值的 skill,标准很简单:它解决一个 Claude Code 原生无法解决的问题,且 description 精准到 Claude 能正确路由。
按这个标准,我现在日常在用的是 superpowers(部分 skill)+ claude-mem + agent-browser。其他的,要么对我的工作场景没覆盖,要么装了之后发现 Claude 本身已经能做。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号